Zeitpläne
Die Funktion Zeitpläne in FlowHunt ermöglicht es Ihnen, Domains und YouTube-Kanäle regelmäßig zu durchsuchen, sodass Ihre Chatbots und Flows stets mit den neues...
3 Min. Lesezeit
AI
Schedules
+4
Erfahren Sie, wie Sie automatisierte Zeitpläne für das Crawlen von Websites, Sitemaps, Domains und YouTube-Kanälen einrichten, um die Wissensdatenbank Ihres KI-Agenten stets aktuell zu halten.
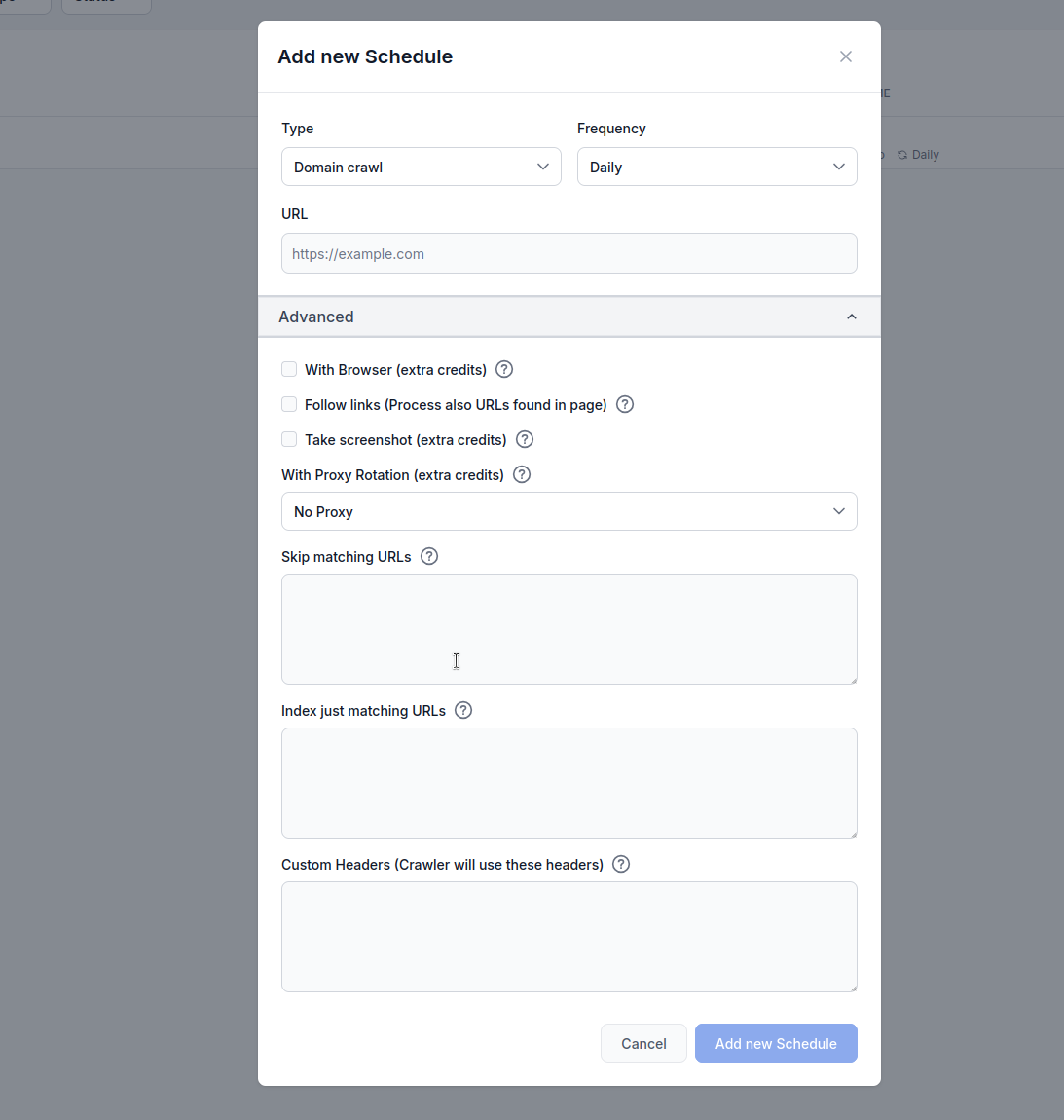
Mit der Zeitplan-Funktion von FlowHunt können Sie das Crawlen und Indexieren von Websites, Sitemaps, Domains und YouTube-Kanälen automatisieren. So bleibt die Wissensdatenbank Ihres KI-Agenten ohne manuellen Aufwand stets mit aktuellen Inhalten versorgt.
Automatisiertes Crawling:
Richten Sie wiederkehrende Crawls ein, die täglich, wöchentlich, monatlich oder jährlich ausgeführt werden, um Ihre Wissensdatenbank aktuell zu halten.
Verschiedene Crawl-Typen:
Wählen Sie je nach Inhaltsquelle zwischen Domain-Crawl, Sitemap-Crawl, URL-Crawl oder YouTube-Kanal-Crawl.
Erweiterte Optionen:
Konfigurieren Sie Browser-Rendering, Link-Following, Screenshots, Proxy-Rotation und URL-Filterung für optimale Ergebnisse.
Typ: Wählen Sie Ihre Crawl-Methode:
Häufigkeit: Legen Sie fest, wie oft der Crawl ausgeführt wird:
URL: Geben Sie die Ziel-URL, Domain oder den YouTube-Kanal zum Crawlen ein
Mit Browser (zusätzliche Credits): Aktivieren Sie dies beim Crawlen von JavaScript-lastigen Websites, die vollständiges Browser-Rendering erfordern. Diese Option ist langsamer und teurer, aber für Seiten notwendig, die Inhalte dynamisch laden.
Links folgen (zusätzliche Credits): Verarbeitet zusätzliche URLs, die auf Seiten gefunden werden. Nützlich, wenn Sitemaps nicht alle URLs enthalten, kann aber viele Credits verbrauchen, da gefundene Links gecrawlt werden.
Screenshot erstellen (zusätzliche Credits): Fertigt während des Crawlings Screenshots an. Hilfreich für Websites ohne og:images oder wenn für die KI-Bearbeitung visueller Kontext benötigt wird.
Mit Proxy-Rotation (zusätzliche Credits): Wechselt für jede Anfrage die IP-Adresse, um der Erkennung durch Web Application Firewalls (WAF) oder Anti-Bot-Systeme zu entgehen.
Übereinstimmende URLs überspringen: Geben Sie Zeichenketten (eine pro Zeile) ein, um URLs mit diesen Mustern vom Crawling auszuschließen. Beispiel:
/admin/
/login
.pdf
Dieses Beispiel erklärt, was passiert, wenn Sie die Zeitplan-Funktion von FlowHunt nutzen, um die Domain flowhunt.io zu crawlen und dabei /blog als übereinstimmende URL im URL-Filter ausschließen.
Konfigurationseinstellungen
flowhunt.io/blogAblauf
Crawl-Start:
flowhunt.io und erfasst alle zugänglichen Seiten der Domain (z. B. flowhunt.io, flowhunt.io/features, flowhunt.io/pricing usw.).Angewandte URL-Filterung:
/blog./blog enthält (z. B. flowhunt.io/blog, flowhunt.io/blog/post1, flowhunt.io/blog/category), wird vom Crawling ausgeschlossen.flowhunt.io/about, flowhunt.io/contact oder flowhunt.io/docs werden gecrawlt, da sie nicht dem /blog-Muster entsprechen.Crawl-Ausführung:
flowhunt.io und indexiert deren Inhalte für die Wissensdatenbank Ihres KI-Agenten.Ergebnis:
flowhunt.io aktualisiert – alles unterhalb des /blog-Pfads bleibt ausgeschlossen./blog) aktuell bleibt.Nur übereinstimmende URLs indexieren: Geben Sie Zeichenketten (eine pro Zeile) ein, um nur URLs mit diesen Mustern zu crawlen. Beispiel:
/blog/
/articles/
/knowledge/
Konfigurationseinstellungen
flowhunt.io/blog/
/articles/
/knowledge/
Crawl-Start:
flowhunt.io und erfasst alle zugänglichen Seiten der Domain (z. B. flowhunt.io, flowhunt.io/blog, flowhunt.io/articles usw.).Angewandte URL-Filterung:
/blog/, /articles/ und /knowledge/.flowhunt.io/blog/post1, flowhunt.io/articles/news, flowhunt.io/knowledge/guide), werden in den Crawl aufgenommen.flowhunt.io/about, flowhunt.io/pricing oder flowhunt.io/contact werden ausgeschlossen, da sie nicht den angegebenen Mustern entsprechen.Crawl-Ausführung:
/blog/, /articles/ oder /knowledge/ übereinstimmen, und indexiert deren Inhalte für die Wissensdatenbank Ihres KI-Agenten.Ergebnis:
flowhunt.io-Seiten unter den Pfaden /blog/, /articles/ und /knowledge/ aktualisiert.Benutzerdefinierte Header:
Fügen Sie benutzerdefinierte HTTP-Header für Crawl-Anfragen hinzu. Format: HEADER=Wert (eine pro Zeile):
Diese Funktion ist besonders nützlich, um Crawls an spezielle Anforderungen von Websites anzupassen. Durch das Aktivieren benutzerdefinierter Header können Nutzer Anfragen authentifizieren, um auf geschützte Inhalte zuzugreifen, bestimmtes Browserverhalten nachahmen oder Vorgaben einer Website-API bzw. Zugriffsrichtlinien erfüllen. Beispielsweise ermöglicht ein Authorization-Header den Zugang zu geschützten Seiten, während ein benutzerdefinierter User-Agent hilft, Bot-Erkennung zu umgehen oder die Kompatibilität mit Seiten sicherzustellen, die bestimmte Crawler ausschließen. Diese Flexibilität sorgt für eine präzisere und umfassendere Datenerfassung und erleichtert das Indexieren relevanter Inhalte in einer KI-Wissensdatenbank unter Einhaltung der Sicherheits- und Zugriffsprotokolle der Website.
MYHEADER=Beliebiger Wert
Authorization=Bearer token123
User-Agent=Custom crawler
Navigieren Sie zu Zeitpläne in Ihrem FlowHunt-Dashboard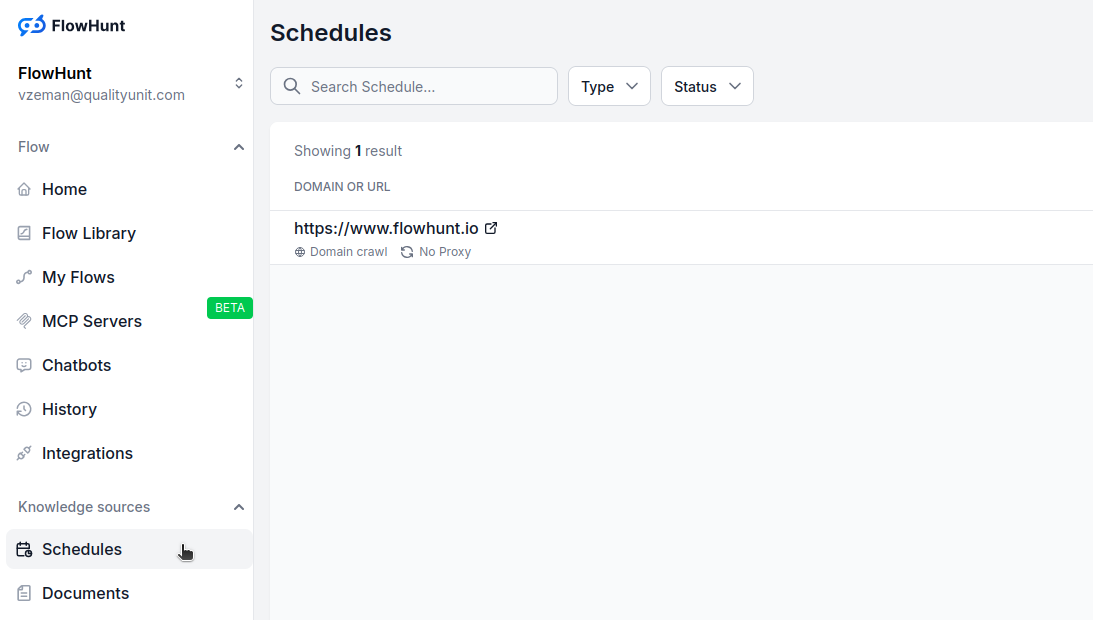
Klicken Sie auf „Neuen Zeitplan hinzufügen“
Konfigurieren Sie die Grundeinstellungen:
Erweiterte Optionen aufklappen falls nötig:
Klicken Sie auf „Neuen Zeitplan hinzufügen“, um zu aktivieren
Für die meisten Websites:
Für JavaScript-lastige Seiten:
Für große Websites:
Für E-Commerce oder dynamische Inhalte:
Erweiterte Funktionen verbrauchen zusätzliche Credits:
Überwachen Sie Ihren Credit-Verbrauch und passen Sie Zeitpläne an Ihre Anforderungen und Ihr Budget an.
Crawl-Fehler:
Zu viele/wenige Seiten:
Fehlende Inhalte:
Die Funktion Zeitpläne in FlowHunt ermöglicht es Ihnen, Domains und YouTube-Kanäle regelmäßig zu durchsuchen, sodass Ihre Chatbots und Flows stets mit den neues...
Transformieren Sie Ihre Content-Strategie mit unserem KI-gestützten Content-Planer, der fortschrittliche KI-Funktionen mit Echtzeit-Google-Recherche kombiniert....

Transformieren Sie Ihren Content-Erstellungsprozess mit unserem KI-gestützten Blog-Einleitungsgenerator & Content-Planer. Durch die Nutzung von Echtzeit-Recherc...