Descripción general
El Asistente de Wikipedia RIG (Retrieval Interleaved Generator) es un flujo de trabajo automatizado diseñado para responder consultas de usuarios generando respuestas iniciales, identificando datos factuales necesarios, recuperando información de Wikipedia y refinando sus respuestas con citas precisas para cada sección. Su objetivo principal es proporcionar respuestas fundamentadas en fuentes verificables y especificar exactamente qué secciones y fuentes se usaron, lo que lo hace especialmente útil para investigación, verificación de hechos y propósitos educativos.
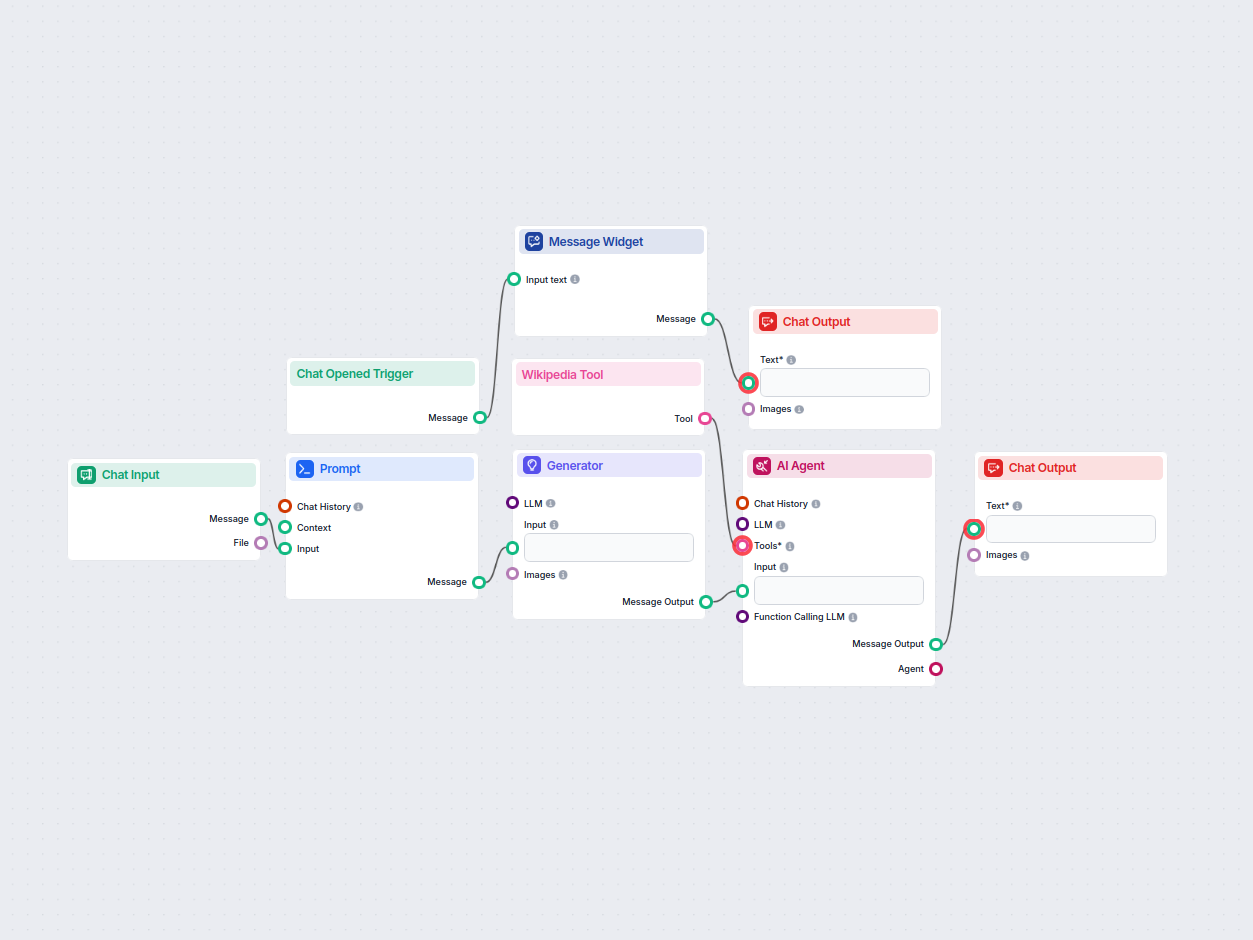
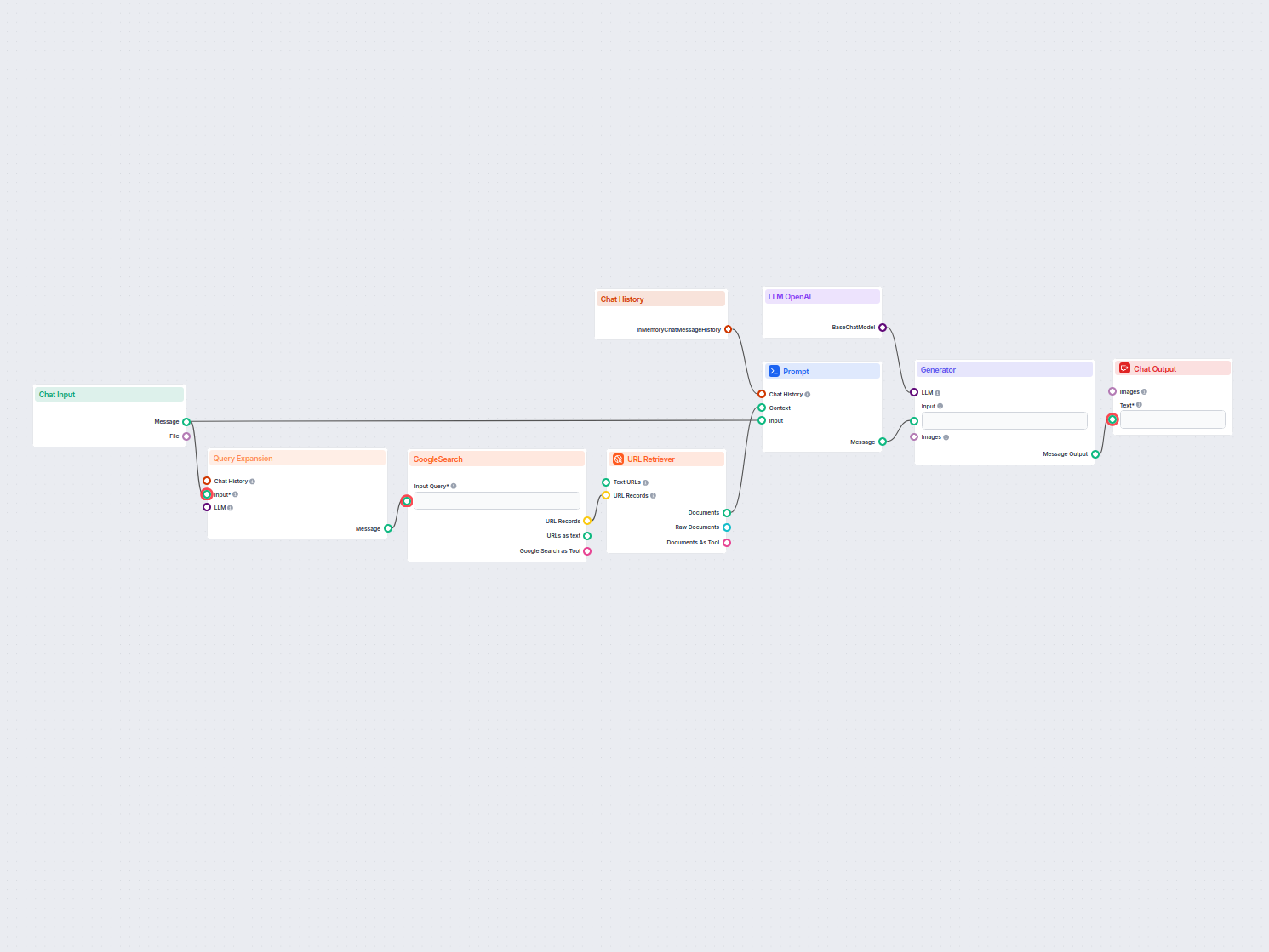
Cómo funciona el flujo de trabajo
Inicio del chat y bienvenida
- Cuando se abre una sesión de chat, el usuario recibe un mensaje de bienvenida que explica el propósito del flujo: proporcionar respuestas confiables y respaldadas por fuentes. Esto ayuda a establecer expectativas sobre la calidad y transparencia de las respuestas.
Recepción de la consulta del usuario
- El usuario envía una pregunta a través de la entrada de chat. Esta entrada se captura y se envía para su procesamiento.
Generación del prompt
- El flujo de trabajo incluye una Plantilla de Prompt que toma la pregunta del usuario y construye un prompt detallado. Este prompt instruye al sistema para:
- Generar una respuesta preliminar, aunque use datos ficticios.
- Para cada sección de la respuesta, especificar qué fuente externa (como Wikipedia) o base de conocimiento interna se debe usar para verificar y refinar esa sección.
- Incluir consultas de búsqueda para Wikipedia para obtener la información correcta para cada sección.
Ejemplo:
Entrada del usuario: ¿Qué países lideran en energía renovable?
Salida de borrador: Los países principales son Noruega, Suecia, Portugal [Buscar en Wikipedia: "Top Countries in renewable Energy"]...
Generación de la respuesta inicial
- Utilizando un generador de modelos de lenguaje, el sistema crea un borrador de respuesta basado en el prompt, destacando dónde se deben insertar los datos factuales y qué fuentes se deben usar para la verificación.
Recuperación de datos y refinamiento de la respuesta
- Un Agente de IA recibe el borrador de respuesta y utiliza la Herramienta de Wikipedia para buscar en Wikipedia las consultas especificadas.
- Para cada sección de la respuesta, el agente recupera los datos factuales relevantes de Wikipedia y reemplaza el contenido preliminar o ficticio.
- Cada sección se refina para incluir un enlace directo al artículo o sección exacta de Wikipedia utilizada, asegurando transparencia y fácil verificación.
El agente tiene instrucciones de evitar frases genéricas o de relleno, enfocándose solo en contenido conciso y factual.
Salida final
- La respuesta completamente refinada, con cada sección fundamentada en una fuente específica de Wikipedia (y enlaces incluidos en línea), se muestra al usuario en la interfaz de chat.
Estructura del flujo de trabajo
| Paso | Componente | Propósito |
|---|
| 1 | Disparador de Chat Abierto | Detecta una nueva sesión de chat y lanza el mensaje de bienvenida |
| 2 | Widget de Mensajes | Muestra el saludo inicial e instrucciones |
| 3 | Entrada de Chat | Acepta la pregunta del usuario |
| 4 | Plantilla de Prompt | Da formato al prompt con instrucciones para la respuesta y fuentes |
| 5 | Generador | Produce el borrador inicial de la respuesta (con marcadores) |
| 6 | Herramienta de Wikipedia | Permite la recuperación de datos de Wikipedia |
| 7 | Agente de IA | Refina el borrador, busca hechos, inserta citas/enlaces |
| 8 | Salida de Chat | Presenta la respuesta final y fundamentada al usuario |
Características y beneficios clave
- Transparencia de fuentes: Cada sección de la respuesta especifica claramente qué página o sección de Wikipedia se utilizó, incluyendo enlaces directos para la verificación del usuario.
- Automatización y escalabilidad: El flujo automatiza el proceso de redacción, verificación y refinamiento de respuestas, siendo adecuado para manejar muchas consultas de manera eficiente.
- Resultado de calidad investigativa: Al fundamentar cada afirmación en una fuente externa verificable, el sistema produce respuestas aptas para contextos académicos, empresariales y profesionales.
- Personalización: Si es necesario, se pueden integrar fuentes internas de conocimiento junto con Wikipedia, haciendo el sistema adaptable para la recuperación de datos específicos de la empresa.
Casos de uso
- Asistentes educativos: Proporcionan respuestas a estudiantes que siempre citan sus fuentes.
- Bots de verificación de hechos: Verifican información al instante y presentan fuentes sin investigación manual.
- Soporte al cliente: Ofrecen información sobre la empresa o productos con clara procedencia de los datos.
- Creación de contenido: Escritores y periodistas pueden obtener borradores con referencias embebidas para su posterior desarrollo.
Resumen
Este flujo de trabajo empodera a los usuarios con respuestas confiables y bien referenciadas intercalando pasos de generación y recuperación. Es especialmente útil donde la precisión factual, la transparencia y la atribución de fuentes son cruciales. Su diseño modular y automatizado lo hace altamente escalable para organizaciones que buscan automatizar tareas de investigación y preguntas y respuestas a gran escala.