Ingeniería de Contexto: La Guía Definitiva 2025 para Dominar el Diseño de Sistemas de IA
Sumérgete en la ingeniería de contexto para IA. Esta guía aborda principios clave, desde prompt vs. contexto hasta estrategias avanzadas como gestión de memoria, context rot y diseño multiagente.
AI
LLM
System Design
Agents
Context Engineering
Prompt Engineering
RAG
El panorama del desarrollo de IA ha experimentado una transformación profunda. Donde antes nos obsesionábamos con crear el prompt perfecto, ahora nos enfrentamos a un reto mucho más complejo: construir arquitecturas de información completas que rodean y potencian a nuestros modelos de lenguaje.
Este cambio marca la evolución de la ingeniería de prompts a la ingeniería de contexto, y representa nada menos que el futuro del desarrollo de IA práctico. Los sistemas que hoy aportan valor real no dependen de prompts mágicos. Tienen éxito porque sus arquitectos han aprendido a orquestar ecosistemas de información integrales.
Andrej Karpathy capturó esta evolución perfectamente cuando describió la ingeniería de contexto como la práctica cuidadosa de poblar la ventana de contexto con exactamente la información adecuada en el momento preciso. Esta afirmación, en apariencia simple, revela una verdad fundamental: el LLM ya no es la estrella del espectáculo. Es un componente crítico dentro de un sistema cuidadosamente diseñado donde cada fragmento de información—cada memoria, cada descripción de herramienta, cada documento recuperado—ha sido posicionado deliberadamente para maximizar los resultados.
¿Qué es la Ingeniería de Contexto?
Una Perspectiva Histórica
Las raíces de la ingeniería de contexto son más profundas de lo que muchos piensan. Aunque el debate sobre la ingeniería de prompts explotó entre 2022 y 2023, los conceptos fundacionales de la ingeniería de contexto surgieron hace más de dos décadas desde la computación ubicua y la investigación en interacción humano-computadora.
En 2001, Anind K. Dey estableció una definición sorprendentemente visionaria: el contexto incluye cualquier información que ayude a caracterizar la situación de una entidad. Este marco temprano sentó las bases de cómo pensamos la comprensión de entornos por parte de las máquinas.
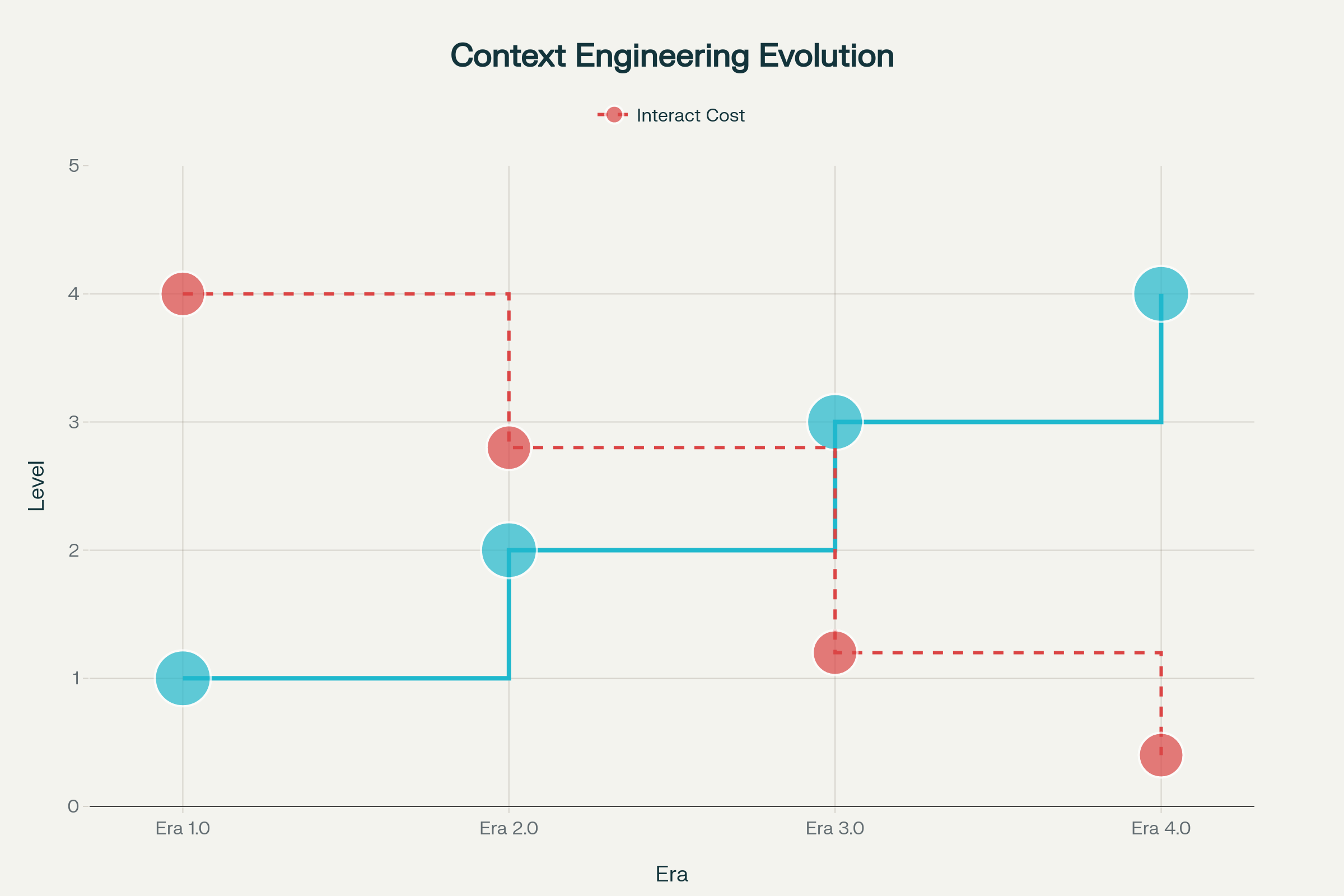
La evolución de la ingeniería de contexto se ha desplegado en fases distintas, cada una moldeada por avances en inteligencia de máquina:
Era 1.0: Computación Primitiva (1990s–2020) — Durante este periodo, las máquinas solo podían manejar entradas estructuradas y señales ambientales básicas. Los humanos soportaban toda la carga de traducir contextos a formatos procesables por máquina. Piensa en aplicaciones de escritorio, apps móviles con sensores y chatbots tempranos con árboles de respuesta rígidos.
Era 2.0: Inteligencia Centrada en el Agente (2020–Presente) — El lanzamiento de GPT-3 en 2020 supuso un cambio de paradigma. Los grandes modelos de lenguaje trajeron comprensión genuina del lenguaje natural y la capacidad de trabajar con intenciones implícitas. Esta era habilitó colaboración auténtica humano-agente, donde la ambigüedad y la información incompleta se volvieron manejables mediante comprensión sofisticada del lenguaje y aprendizaje en contexto.
Eras 3.0 y 4.0: Inteligencia Humana y Sobrehumana (Futuro) — Las próximas olas prometen sistemas capaces de captar y procesar información de alta entropía con fluidez humana, avanzando eventualmente más allá de respuestas reactivas para construir proactivamente contexto y anticipar necesidades no expresadas por los usuarios.
Evolución de la Ingeniería de Contexto a lo Largo de Cuatro Eras: De la Computación Primitiva a la Inteligencia Sobrehumana
Una Definición Formal
En esencia, la ingeniería de contexto es la disciplina sistemática de diseñar y optimizar cómo fluye la información contextual a través de los sistemas de IA—desde la recolección inicial, pasando por el almacenamiento y la gestión, hasta su uso final para mejorar la comprensión y ejecución de tareas por la máquina.
Podemos expresarlo matemáticamente como una función de transformación:
$CE: (C, T) \rightarrow f_{context}$
Donde:
C representa la información contextual cruda (entidades y sus características)
T denota la tarea objetivo o el dominio de aplicación
f_{context} produce la función resultante de procesamiento de contexto
Desglosando en términos prácticos, revela cuatro operaciones fundamentales:
Recolectar señales contextuales relevantes a través de sensores y canales de información diversos
Almacenar esta información eficientemente en sistemas locales, infraestructura de red y plataformas en la nube
Gestionar la complejidad mediante procesamiento inteligente de texto, entradas multimodales y relaciones intrincadas
Usar el contexto estratégicamente filtrando por relevancia, habilitando el intercambio entre sistemas y adaptando según los requisitos del usuario
Por Qué Importa la Ingeniería de Contexto: El Marco de Reducción de Entropía
La ingeniería de contexto aborda una asimetría fundamental en la comunicación humano-máquina. Cuando los humanos conversan, rellenan huecos sin esfuerzo gracias al conocimiento cultural compartido, inteligencia emocional y conciencia situacional. Las máquinas carecen de estas capacidades.
Esta brecha se manifiesta como entropía de información. La comunicación humana es eficiente porque asumimos grandes cantidades de contexto compartido. Las máquinas requieren que todo esté representado explícitamente. La ingeniería de contexto consiste, en esencia, en preprocesar los contextos para las máquinas—comprimir la complejidad de alta entropía de las intenciones y situaciones humanas en representaciones de baja entropía que la máquina pueda procesar.
A medida que avanza la inteligencia de las máquinas, esta reducción de entropía se automatiza cada vez más. Hoy, en la Era 2.0, los ingenieros deben orquestar manualmente gran parte de esta reducción. En la Era 3.0 y más allá, las máquinas asumirán progresivamente más de esta carga de forma independiente. Sin embargo, el reto clave permanece: cerrar la brecha entre la complejidad humana y la comprensión de la máquina.
Ingeniería de Prompts vs. Ingeniería de Contexto: Diferencias Críticas
Un error común es confundir estas dos disciplinas. En realidad, representan enfoques fundamentalmente distintos del diseño de sistemas de IA.
La ingeniería de prompts se centra en crear instrucciones individuales o consultas para moldear el comportamiento del modelo. Consiste en optimizar la estructura lingüística de lo que comunicas al modelo—la redacción, ejemplos y patrones de razonamiento dentro de una interacción.
La ingeniería de contexto es una disciplina sistémica integral que gestiona todo lo que el modelo encuentra durante la inferencia—incluyendo prompts, pero también documentos recuperados, sistemas de memoria, descripciones de herramientas, información de estado y más.
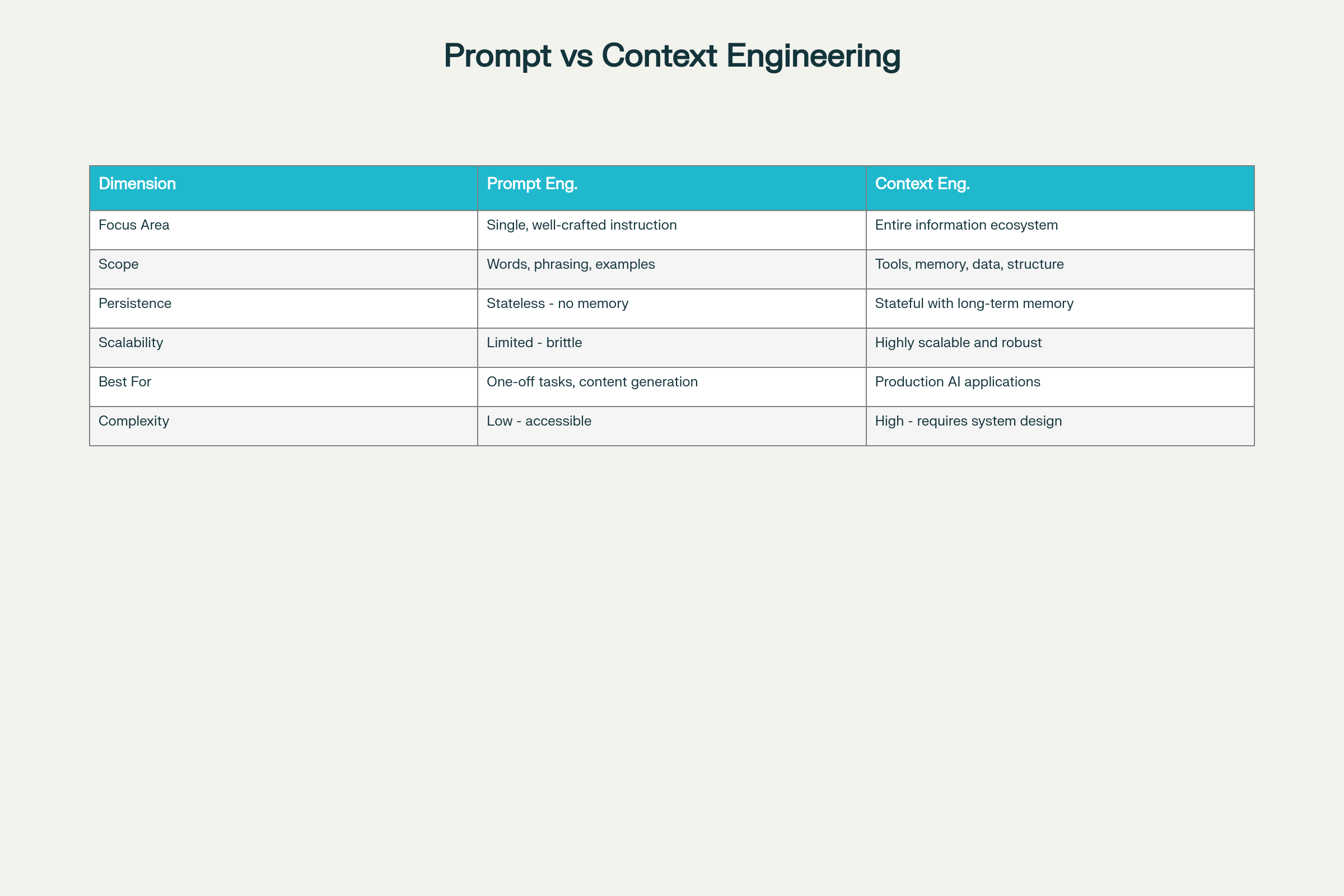
Ingeniería de Prompts vs Ingeniería de Contexto: Diferencias y Equilibrios Clave
Considera esta distinción: Pedir a ChatGPT que redacte un correo profesional es ingeniería de prompts. Construir una plataforma de atención al cliente que mantenga el historial de conversaciones en varias sesiones, acceda a los detalles de la cuenta del usuario y recuerde tickets previos de soporte—eso es ingeniería de contexto.
Diferencias Clave en Ocho Dimensiones:
Dimensión
Ingeniería de Prompts
Ingeniería de Contexto
Área de Enfoque
Optimización de instrucciones individuales
Ecosistema de información integral
Alcance
Palabras, redacción, ejemplos
Herramientas, memoria, arquitectura de datos, estructura
Persistencia
Sin estado—sin retención de memoria
Con estado y memoria a largo plazo
Escalabilidad
Limitada y frágil a escala
Altamente escalable y robusta
Ideal Para
Tareas puntuales, generación de contenido
Aplicaciones de IA de producción
Complejidad
Baja barrera de entrada
Alta—requiere experiencia en diseño de sistemas
Fiabilidad
Impredecible a escala
Consistente y fiable
Mantenimiento
Frágil ante cambios de requisitos
Modular y mantenible
El punto crucial: Las aplicaciones de LLM en producción requieren abrumadoramente ingeniería de contexto, no solo prompts ingeniosos. Como observó Cognition AI, la ingeniería de contexto se ha convertido en la responsabilidad principal de los ingenieros que construyen agentes de IA.
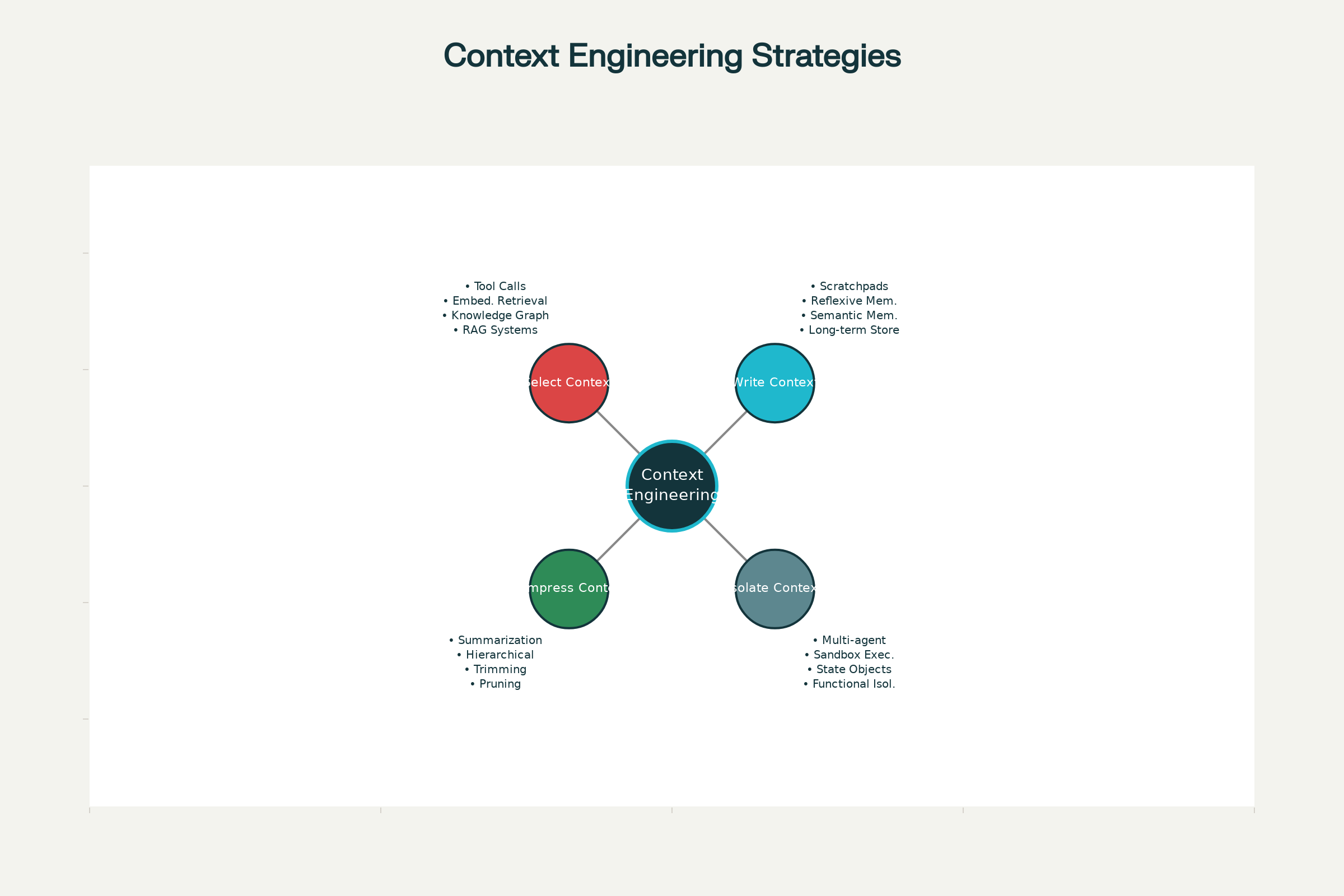
Las Cuatro Estrategias Clave para la Ingeniería de Contexto
En los sistemas de IA líderes—desde Claude y ChatGPT hasta agentes especializados desarrollados por Anthropic y otros laboratorios de vanguardia—han cristalizado cuatro estrategias esenciales para una gestión de contexto efectiva. Pueden implementarse por separado o combinarse para mayor efecto.
1. Escribir Contexto: Persistir Información Fuera de la Ventana de Contexto
El principio fundamental es simple y elegante: no obligues al modelo a recordarlo todo. Mejor, persiste la información clave fuera de la ventana de contexto para que sea accesible cuando se necesite.
Scratchpads ofrecen la implementación más intuitiva. Igual que los humanos anotan ideas para resolver problemas complejos, los agentes de IA usan scratchpads para guardar información para referencia futura. Puede ser tan sencillo como una herramienta para guardar notas, o tan sofisticado como campos en un objeto de estado en tiempo de ejecución que persisten entre pasos de ejecución.
El investigador multiagente de Anthropic lo demuestra perfectamente: el LeadResearcher empieza formulando un plan y guardándolo en Memoria para su persistencia, reconociendo que si la ventana de contexto supera los 200.000 tokens, se producirá truncamiento y el plan debe conservarse.
Memorias extienden el concepto de scratchpad entre sesiones. En lugar de capturar información solo dentro de una tarea (memoria de sesión), los sistemas pueden construir memorias a largo plazo que evolucionan en múltiples interacciones usuario-agente. Este patrón es estándar en productos como ChatGPT, Claude Code, Cursor y Windsurf.
Iniciativas como Reflexion introdujeron memorias reflexivas—haciendo que el agente reflexione sobre cada turno y genere recuerdos para el futuro. Generative Agents extendió esto sintetizando memorias periódicamente a partir de colecciones de retroalimentación pasada.
Tres Tipos de Memorias:
Episódicas: Ejemplos concretos de comportamientos o interacciones pasadas (valiosas para few-shot learning)
Procedurales: Instrucciones o reglas de comportamiento (que aseguran operación consistente)
Semánticas: Hechos y relaciones sobre el mundo (proporcionan conocimiento fundamentado)
2. Seleccionar Contexto: Traer la Información Adecuada
Una vez que la información está preservada, el agente debe recuperar solo lo relevante para la tarea actual. Una mala selección puede ser tan perjudicial como no tener memoria—la información irrelevante confunde al modelo o provoca alucinaciones.
Mecanismos de Selección de Memoria:
Enfoques simples emplean archivos fijos siempre incluidos. Claude Code usa un archivo CLAUDE.md para memorias procedurales, mientras Cursor y Windsurf usan archivos de reglas. Sin embargo, esta táctica no escala si el agente acumula cientos de hechos y relaciones.
Para colecciones de memoria grandes, lo habitual es el recupero por embeddings y gráficos de conocimiento. El sistema convierte memorias y la consulta en vectores, y recupera las memorias más semánticamente similares.
Pero como demostró Simon Willison en la AIEngineer World’s Fair, esto puede fallar espectacularmente. ChatGPT inyectó su ubicación desde memorias en una imagen generada, probando que incluso sistemas sofisticados pueden recuperar memorias inapropiadamente. Subraya la importancia de una ingeniería meticulosa.
Selección de Herramientas presenta su propio reto. Cuando los agentes acceden a decenas o cientos de herramientas, enumerarlas todas puede confundir—las descripciones se solapan y los modelos eligen herramientas inapropiadas. Una solución efectiva: aplicar principios RAG a las descripciones de herramientas. Recuperando solo las relevantes semánticamente, se han logrado mejoras triples en precisión de selección.
Recuperación de Conocimiento es probablemente el espacio de problemas más rico. Los agentes de código lo ejemplifican a escala de producción. Como destacó un ingeniero de Windsurf, indexar código no equivale a recuperar contexto eficaz. Realizan indexado y búsqueda por embeddings con análisis AST y fragmentación en límites semánticamente significativos. Pero la búsqueda por embeddings pierde fiabilidad en grandes bases de código. El éxito requiere combinar técnicas como búsqueda de archivos, recuperación por gráficos de conocimiento y un paso de re-rankeado por relevancia.
3. Comprimir Contexto: Retener Solo lo Necesario
Cuando los agentes abordan tareas de largo horizonte, el contexto se acumula naturalmente. Notas, resultados de herramientas e historial de interacción pueden exceder rápidamente la ventana de contexto. Las estrategias de compresión abordan este reto destilando información inteligentemente y preservando lo esencial.
Resumir es la técnica principal. Claude Code implementa “auto-compact”—cuando el contexto alcanza el 95% de capacidad, resume toda la trayectoria de interacciones usuario-agente. Puede emplear varias estrategias:
Resumen recursivo: Crear resúmenes de resúmenes formando jerarquías compactas
Resumen jerárquico: Generar resúmenes en varios niveles de abstracción
Resumen dirigido: Comprimir componentes específicos (resultados de búsqueda extensos), no todo el contexto
Cognition AI reveló que usan modelos ajustados para resumir en los límites entre agentes y así reducir el uso de tokens en la transferencia de conocimiento—demostrando la profundidad de ingeniería necesaria.
Recorte de Contexto es un enfoque complementario. En vez de usar un LLM para resumir, el recorte elimina partes mediante reglas fijas—removiendo mensajes antiguos, filtrando por importancia o usando podadores entrenados como Provence para tareas de preguntas y respuestas.
El aprendizaje clave: Lo que eliminas importa tanto como lo que mantienes. Un contexto enfocado de 300 tokens suele superar a otro de 113.000 tokens dispersos en tareas conversacionales.
4. Aislar Contexto: Separar Información Entre Sistemas
Finalmente, las estrategias de aislamiento reconocen que tareas diferentes requieren información diferente. En vez de meter todo en una única ventana, el aislamiento reparte contexto entre sistemas especializados.
Arquitecturas Multiagente son lo más frecuente. La biblioteca Swarm de OpenAI fue diseñada explícitamente en torno a la “separación de responsabilidades”, donde subagentes especializados manejan tareas concretas con sus propias herramientas, instrucciones y ventanas de contexto.
La investigación de Anthropic demuestra el poder de este enfoque: muchos agentes con contextos aislados superaron implementaciones monoagente, principalmente porque cada subagente puede dedicar su ventana de contexto a una sub-tarea más acotada. Los subagentes operan en paralelo y exploran aspectos diferentes simultáneamente.
Sin embargo, los sistemas multiagente suponen compromisos. Anthropic reportó hasta quince veces más uso de tokens frente al chat monoagente. Esto requiere orquestación cuidadosa, prompts para planificación y mecanismos de coordinación sofisticados.
Entornos Sandbox son otra estrategia de aislamiento. El CodeAgent de HuggingFace lo muestra: en vez de devolver JSON que el modelo debe interpretar, el agente genera código que se ejecuta en un sandbox. Solo los outputs seleccionados (valores de retorno) se pasan al LLM, manteniendo objetos pesados fuera del contexto. Este enfoque es ideal para datos visuales y de audio.
Aislamiento de Estado es quizás la técnica menos valorada. El estado en ejecución de un agente puede diseñarse como un esquema estructurado (como un modelo Pydantic) con varios campos. Un campo (como mensajes) se expone al LLM en cada paso, mientras los demás quedan aislados para uso selectivo. Así se logra control granular sin complejidad arquitectónica.
Cuatro Estrategias Clave para una Ingeniería de Contexto Efectiva en Agentes de IA
El Problema del Context Rot: Un Reto Crítico
Aunque los avances en longitud de contexto han sido celebrados, investigaciones recientes revelan una realidad preocupante: más contexto no significa automáticamente mejor rendimiento.
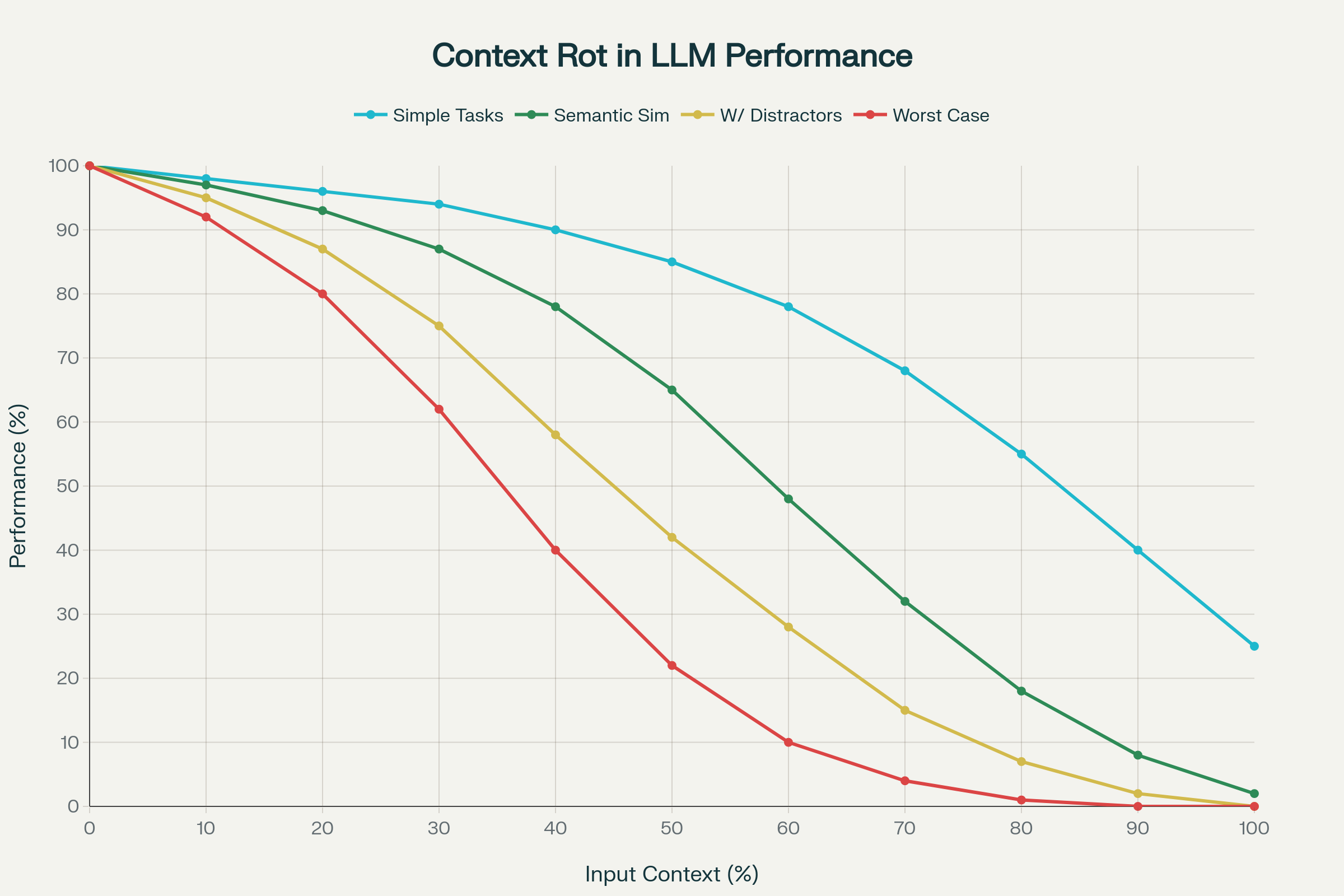
Un estudio referente que analizó 18 LLMs líderes—incluyendo GPT-4.1, Claude 4, Gemini 2.5 y Qwen 3—descubrió el fenómeno del context rot: la degradación impredecible y a menudo severa del rendimiento a medida que la entrada crece.
Hallazgos Clave sobre el Context Rot
1. Degradación No Uniforme
El rendimiento no cae de forma lineal ni predecible. Los modelos muestran descensos bruscos e idiosincráticos según el modelo y la tarea. Un modelo puede mantener 95% de precisión hasta una longitud, y de repente caer a 60%. Estos “precipicios” varían entre modelos.
2. La Complejidad Semántica Amplifica el Context Rot
Tareas simples (como copiar palabras repetidas o recuperación semántica exacta) muestran declive moderado. Pero cuando la tarea exige similitud semántica y no coincidencia exacta, el rendimiento cae abruptamente. Añadir distractores plausibles—información parecida pero incorrecta—empeora la precisión.
3. Sesgo Posicional y Colapso de Atención
La atención de los transformers no escala linealmente con contextos largos. Los tokens al inicio (sesgo de primacía) y al final (sesgo de recencia) reciben atención desproporcionada. En casos extremos, la atención colapsa y el modelo ignora gran parte de la entrada.
4. Patrones Específicos de Fallo según el Modelo
Cada LLM se comporta de forma única a escala:
GPT-4.1: Tiende a alucinar, repitiendo tokens incorrectos
Gemini 2.5: Introduce fragmentos o signos de puntuación irrelevantes
Claude Opus 4: Puede negarse a tareas o volverse excesivamente cauteloso
5. Impacto Real en Conversación
Quizás lo más revelador: en el benchmark LongMemEval, los modelos con acceso a conversaciones completas (~113k tokens) rindieron mejor recibiendo solo el segmento focalizado de 300 tokens. Esto muestra que el context rot degrada tanto la recuperación como el razonamiento en diálogos reales.
Context Rot: Degradación del Rendimiento al Aumentar la Longitud de Entrada en 18 LLMs
Implicaciones: Calidad sobre Cantidad
La principal conclusión de la investigación sobre context rot es clara: la cantidad de tokens de entrada no determina la calidad. Cómo se construye, filtra y presenta el contexto es igual o más importante.
Esto valida toda la disciplina de la ingeniería de contexto. Más que ver ventanas largas como solución mágica, los equipos sofisticados reconocen que una ingeniería de contexto cuidadosa—mediante compresión, selección y aislamiento—es esencial para mantener el rendimiento con entradas sustanciales.
Ingeniería de Contexto en la Práctica: Aplicaciones Reales
Caso 1: Sistemas de Agentes Multiturno (Claude Code, Cursor)
Claude Code y Cursor representan lo último en ingeniería de contexto para asistencia en código:
Recolección: Reúnen contexto de múltiples fuentes—archivos abiertos, estructura de proyecto, historial de ediciones, salida de terminal y comentarios del usuario.
Gestión: En vez de volcar todos los archivos en el prompt, comprimen inteligentemente. Claude Code usa resúmenes jerárquicos. El contexto se etiqueta por función (“archivo editado”, “dependencia referenciada”, “mensaje de error”).
Uso: En cada turno, el sistema selecciona los archivos y elementos contextuales relevantes, los presenta de forma estructurada y mantiene pistas separadas para razonamiento y salida visible.
Compresión: Al acercarse al límite, auto-compact resume la trayectoria de interacción, preservando las decisiones clave.
Resultado: Estas herramientas siguen siendo útiles en grandes proyectos (miles de archivos) sin perder rendimiento, pese a las restricciones de ventana.
Caso 2: Tongyi DeepResearch (Agente de Investigación de Código Abierto)
Tongyi DeepResearch muestra cómo la ingeniería de contexto permite tareas complejas de investigación:
Pipeline de Síntesis de Datos: No depende de datos manuales, sino de un enfoque de síntesis que genera preguntas de investigación a nivel doctoral mediante iteraciones de complejidad creciente. Cada iteración profundiza y construye tareas de razonamiento más complejas.
Gestión de Contexto: Usa el paradigma IterResearch—en cada ronda, reconstruye un workspace reducido con solo lo esencial de la ronda previa. Así evita la “asfixia cognitiva” al acumular todo en una ventana.
Exploración Paralela: Varios agentes investigan en paralelo, cada uno con contexto aislado. Un agente de síntesis integra hallazgos para respuestas completas.
Resultados: Tongyi DeepResearch compite con sistemas propietarios como OpenAI DeepResearch, logrando 32.9 en Humanity’s Last Exam y 75 en benchmarks centrados en usuario.
Caso 3: Investigador Multiagente de Anthropic
La investigación de Anthropic muestra cómo el aislamiento y la especialización mejoran el rendimiento:
Arquitectura: Subagentes especializados gestionan tareas específicas (revisión, síntesis, verificación) con ventanas de contexto separadas.
Beneficios: Este enfoque superó a los sistemas monoagente, con el contexto de cada subagente optimizado para su tarea.
Compromiso: Aunque la calidad es superior, el uso de tokens puede multiplicarse por quince frente al chat monoagente.
Esto refleja un aprendizaje clave: la ingeniería de contexto exige equilibrar calidad, velocidad y coste. El balance óptimo depende de cada caso de uso.
Marco para Consideraciones de Diseño
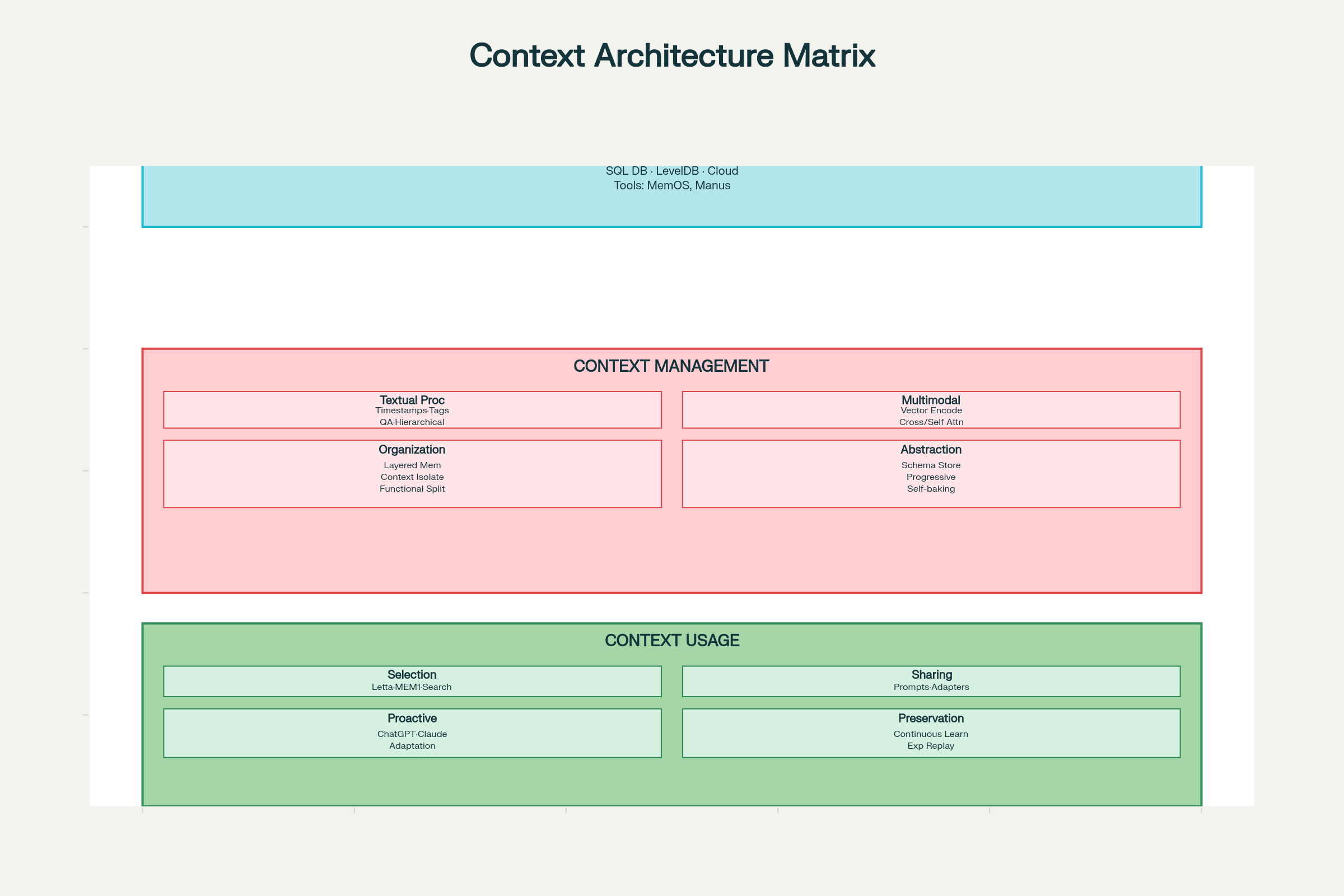
Implementar ingeniería de contexto efectiva requiere pensar sistemáticamente en tres dimensiones: recolección y almacenamiento, gestión y uso.
Consideraciones de Diseño en Ingeniería de Contexto: Arquitectura y Componentes del Sistema Completo
Decisiones de Diseño para Recolección y Almacenamiento
Opciones Tecnológicas de Almacenamiento:
Almacenamiento Local (SQLite, LevelDB): Rápido, baja latencia, ideal para agentes en cliente
Almacenamiento en la Nube (DynamoDB, PostgreSQL): Escalable, accesible desde cualquier lugar
Sistemas Distribuidos: Para gran escala con redundancia y tolerancia a fallos
Patrones de Diseño:
MemOS: Sistema operativo de memoria para gestión unificada
Manus: Memoria estructurada con acceso por roles
Principio clave: Diseña para recuperación eficiente, no solo para almacenamiento. El sistema óptimo es aquel donde encuentras rápidamente lo que necesitas.
Decisiones de Diseño para Gestión
Procesamiento de Contexto Textual:
Marcado por Timestamps: Simple pero limitado. Preserva el orden, pero sin estructura semántica, lo que dificulta la escalabilidad.
Etiquetado por Rol/Función: Etiqueta cada elemento de contexto como “objetivo”, “decisión”, “acción”, “error”, etc. Permite etiquetado multidimensional (prioridad, fuente, confianza). Sistemas como LLM4Tag lo escalan.
Compresión con Pares QA: Convierte interacciones en pares pregunta-respuesta comprimidos, preservando lo esencial y reduciendo tokens.
Notas Jerárquicas: Compresión progresiva en vectores de significado, como en sistemas H-MEM, captando la esencia semántica en varios niveles.
Procesamiento de Contexto Multimodal:
Espacios Vectoriales Comparables: Codifica todas las modalidades (texto, imagen, audio) en espacios vectoriales comparables usando embeddings compartidos (como ChatGPT y Claude).
Cross-Attention: Usa una modalidad para guiar la atención a otra (como Qwen2-VL).
Codificación Independiente con Self-Attention: Codifica modalidades por separado y combina con atención unificada.
Organización de Contexto:
Arquitectura de Memoria en Capas: Separa memoria de trabajo (contexto actual), memoria a corto plazo (historial reciente) y memoria a largo plazo (hechos persistentes).
Aislamiento Funcional de Contexto: Usa subagentes con ventanas de contexto separadas por función (enfoque de Claude).
Abstracción de Contexto (Self-Baking):
El término “self-baking” se refiere a la capacidad del contexto de mejorar tras procesamientos repetidos. Patrones incluyen:
Almacenar contexto bruto y agregar resúmenes en lenguaje natural (Claude Code, Gemini CLI)
Adaptadores para convertir el formato de contexto (Langroid)
Representaciones compartidas entre plataformas (Sharedrop)
Inferencia Proactiva de Usuario:
ChatGPT y Claude analizan patrones para anticipar necesidades
Los sistemas de contexto aprenden a mostrar información antes de ser solicitada
El equilibrio entre utilidad y privacidad sigue siendo un reto clave
Habilidades Clave y Qué Deben Dominar los Equipos
A medida que la ingeniería de contexto se vuelve central en IA, ciertas habilidades diferencian a los equipos efectivos de los que luchan por escalar.
1. Ensamblaje Estratégico de Contexto
Los equipos deben comprender qué información sirve a cada tarea. No es solo reunir datos, es entender los requisitos a fondo para separar lo esencial del ruido.
En la Práctica:
Analiza modos de fallo para detectar contexto ausente
Haz A/B testing con diferentes combinaciones de contexto
Implementa observabilidad para rastrear qué elementos impulsan el rendimiento
2. Arquitectura de Sistemas de Memoria
Diseñar memorias efectivas requiere entender los tipos y cuándo usarlos:
¿Cuándo poner información en memoria a corto o largo plazo?
¿Cómo interactúan los diferentes tipos?
¿Qué estrategias de compresión mantienen fidelidad y ahorran tokens?
3. Búsqueda y Recuperación Semántica
Más allá del simple matching por palabras clave:
Modelos de embeddings y sus límites
Métricas de similitud y sus pros/contras
Re-rankeado y estrategias de filtrado
Manejo de queries ambiguas
4. Economía de Tokens y Análisis de Costes
Cada byte supone un compromiso:
Monitorea uso de tokens según composición de contexto
Comprende costes de procesamiento según el modelo
Equilibra calidad, coste y latencia
5. Orquestación de Sistemas
Con varios agentes, herramientas y memorias, la orquestación es esencial:
Coordinación entre subagentes
Manejo de fallos y recuperación
Gestión de estado en tareas largas
6. Evaluación y Medición
La ingeniería de contexto es, en el fondo, una disciplina de optimización:
Define métricas que capturen el rendimiento
Haz A/B testing de enfoques de contexto
Mide el impacto en la experiencia de usuario, no solo la precisión del modelo
Como comentó un ingeniero senior, el camino más rápido para entregar software de IA de calidad a clientes es tomar pequeños conceptos modulares de la construcción de agentes e incorporarlos en productos existentes.
Buenas Prácticas para Implementar Ingeniería de Contexto
1. Empieza Simple y Evoluciona con Criterio
Comienza con ingeniería de prompts básica y memoria tipo scratchpad. Solo añade complejidad (aislamiento multiagente, recuperación sofisticada) cuando la evidencia lo justifique.
2. Mide Todo
Utiliza herramientas como LangSmith para observabilidad. Rastrea:
Uso de tokens según el enfoque de contexto
Métricas de rendimiento (precisión, corrección, satisfacción)
Equilibrios de coste y latencia
3. Automatiza la Gestión de Memoria
La curación manual no escala. Implementa:
Resúmenes automáticos en los límites de contexto
Filtrado y puntuación de relevancia inteligentes
Funciones de decaimiento para información antigua
4. Diseña para Claridad y Auditabilidad
La calidad del contexto importa más cuando puedes comprender qué ve el modelo. Usa:
Formatos claros y estructurados (JSON, Markdown)
Contexto etiquetado con roles explícitos
Separación de responsabilidades entre componentes
5. Construye Contexto Primero, no LLM Primero
En vez de empezar con “¿qué LLM usamos?”, empieza con “¿qué contexto necesita esta tarea?”. El LLM es un componente de un sistema impulsado por contexto.
6. Adopta Arquitecturas en Capas
Separa:
Memoria de trabajo (contexto actual)
Memoria a corto plazo (interacciones recientes)
Memoria a largo plazo (hechos persistentes)
Cada capa cumple un propósito y puede optimizarse por separado.
Retos y Direcciones Futuras
Retos Actuales
1. Context Rot y Escalabilidad
Aunque existen técnicas para mitigarlo, el problema fundamental persiste. Al crecer la entrada, se requieren mecanismos de selección y compresión más sofisticados.
2. Consistencia y Coherencia de Memoria
Mantener coherencia entre diferentes tipos de memoria y escalas temporales es complicado. Memorias conflictivas o desactualizadas degradan el rendimiento.
3. Privacidad y Divulgación Selectiva
A medida que los sistemas guardan más contexto de los usuarios, equilibrar personalización y privacidad es crucial. Surge el problema de “la ventana de contexto ya no les pertenece” cuando aparece información inesperada.
4. Sobrecarga Computacional
La ingeniería avanzada de contexto añade coste computacional. Selección, compresión y recuperación consumen recursos. Encontrar el equilibrio óptimo sigue siendo un reto abierto.
Direcciones Futuras Prometedoras
1. Ingenieros de Contexto Aprendidos
En vez de gestionar el contexto manualmente, los sistemas podrían aprender estrategias óptimas de selección mediante meta-aprendizaje o refuerzo.
2. Emergencia de Mecanismos Simbólicos
Investigaciones recientes sugieren que los LLMs desarrollan mecanismos simbólicos emergentes. Aprovechar esto permitiría abstracción y razonamiento más sofisticados.
3. Herramientas Cognitivas y Programación de Prompts
Frameworks como “Cognitive Tools” de IBM encapsulan operaciones de razonamiento como componentes modulares. Así, la ingeniería de contexto se asemeja al software componible—piezas pequeñas y reutilizables que cooperan.
4. Teoría de Campos Neurales para Contexto
En vez de elementos discretos, modelar el contexto como un campo neuronal continuo permitiría gestión más fluida y adaptable.
5. Semántica Cuántica y Superposición
La investigación inicial explora si el contexto puede aprovechar la superposición cuántica—donde la información existe en varios estados hasta que se necesita. Esto podría revolucionar el almacenamiento y recuperación de contexto.
Conclusión: Por Qué la Ingeniería de Contexto Importa Ahora
Estamos en un punto de inflexión en el desarrollo de IA. Durante años, el enfoque estuvo en hacer modelos más grandes e inteligentes. La pregunta era: “¿Cómo mejoramos el LLM?”
La pregunta de frontera hoy es diferente: “¿Cómo diseñamos sistemas alrededor de los LLMs para extraer todo su potencial?”
La ingeniería de contexto responde a esa pregunta. No es un truco técnico menor—es una disciplina fundamental para construir sistemas de IA fiables, escalables y realmente útiles en producción.
La evidencia es abrumadora. Equipos en Anthropic, Alibaba (Tongyi) y grandes tecnológicas han demostrado que la ingeniería de contexto sofisticada supera al simple aumento de escala. Un pequeño equipo bien coordinado, con un modelo menos potente pero gestión de contexto cuidadosa, supera sistemáticamente a grandes equipos con acceso a modelos frontera pero mala disciplina contextual.
Esto tiene implicaciones profundas:
La ingeniería de contexto democratiza la IA: No necesitas el modelo más grande, sino el contexto mejor diseñado para tu tarea.
**Es
Preguntas frecuentes
La ingeniería de prompts se centra en crear una instrucción única para un LLM. La ingeniería de contexto es una disciplina sistémica más amplia que gestiona todo el ecosistema de información para un modelo de IA, incluyendo memoria, herramientas y datos recuperados, para optimizar el rendimiento en tareas complejas y con estado.
El context rot es la degradación impredecible del rendimiento de un LLM a medida que su contexto de entrada se hace más largo. Los modelos pueden mostrar caídas bruscas en precisión, ignorar partes del contexto o alucinar, lo que demuestra la necesidad de gestionar cuidadosamente la calidad del contexto más que la cantidad.
Las cuatro estrategias son: 1. Escribir Contexto (persistir información fuera de la ventana de contexto, como notas o memoria), 2. Seleccionar Contexto (recuperar solo la información relevante), 3. Comprimir Contexto (resumir o recortar para ahorrar espacio), y 4. Aislar Contexto (usar sistemas multiagente o sandboxes para separar preocupaciones).
Arshia es ingeniera de flujos de trabajo de IA en FlowHunt. Con formación en ciencias de la computación y una pasión por la IA, se especializa en crear flujos de trabajo eficientes que integran herramientas de IA en las tareas cotidianas, mejorando la productividad y la creatividad.
Arshia Kahani
Ingeniera de flujos de trabajo de IA
Domina la Ingeniería de Contexto
¿Listo para construir la próxima generación de sistemas de IA? Explora nuestros recursos y herramientas para implementar ingeniería de contexto avanzada en tus proyectos.
OpenAI DevDay 2025: Apps SDK, Agent Kit, MCP y por qué el Prompting sigue siendo fundamental para el éxito de la IA
Explora los anuncios de OpenAI en DevDay 2025, incluyendo el Apps SDK, Agent Kit y Model Context Protocol. Descubre por qué el prompting es más importante que n...
Larga vida a la Ingeniería de Contexto: Construyendo Sistemas de IA en Producción con Bases de Datos Vectoriales Modernas
Explora cómo la ingeniería de contexto está transformando el desarrollo de IA, la evolución del RAG a sistemas listos para producción, y por qué las bases de da...
El futuro es impulsado por prompts: ¿Por qué la ingeniería de prompts es la nueva habilidad clave?
Descubre por qué la ingeniería de prompts se está convirtiendo rápidamente en una habilidad esencial para todo profesional, cómo está transformando la productiv...
12 min de lectura
prompt engineering
ai
+2
Consentimiento de Cookies Usamos cookies para mejorar tu experiencia de navegación y analizar nuestro tráfico. See our privacy policy.