Cómo crear páginas personalizadas de base de conocimientos en Hugo a partir de tickets de LiveAgent
Aprende cómo automatizar la creación de artículos de la base de conocimientos en Hugo directamente desde tickets de soporte al cliente usando agentes de IA e integración con GitHub.
Automation
Knowledge Base
Hugo
GitHub
AI Agents
Customer Support
Los equipos de soporte al cliente generan valiosos conocimientos cada día a través de sus interacciones con los clientes. Estas preguntas, inquietudes y soluciones representan una mina de oro de información que podría beneficiar a toda tu base de usuarios si se documenta adecuadamente. Sin embargo, convertir manualmente los tickets de soporte en artículos pulidos de base de conocimientos consume mucho tiempo, es repetitivo y a menudo se deja de lado ante necesidades de soporte inmediatas. ¿Y si pudieras automatizar todo este proceso, transformando consultas en bruto de los clientes en páginas de base de conocimientos profesionalmente formateadas y optimizadas para SEO que aparecen directamente en tu sitio web? Esto es precisamente lo que los flujos de automatización modernos permiten hoy en día. Al conectar tu sistema de tickets LiveAgent con Hugo para la generación de sitios estáticos y el control de versiones con GitHub, puedes crear un canal fluido que convierte preguntas de clientes en contenido de base de conocimientos automáticamente, haciéndolo buscable y fácil de descubrir. En esta guía completa, exploraremos cómo construir este potente sistema de automatización, la arquitectura técnica detrás de él y los pasos prácticos para implementarlo en tu propia organización.
Comprendiendo la automatización de bases de conocimientos
Una base de conocimientos es un repositorio centralizado de información diseñado para ayudar a los usuarios a encontrar respuestas a preguntas comunes sin requerir la intervención directa de soporte. Tradicionalmente, las bases de conocimientos se construyen manualmente: los equipos de soporte escriben artículos, los formatean, los optimizan para buscadores y los publican a través de un sistema de gestión de contenidos. Este proceso es laborioso y genera un gran cuello de botella, especialmente en empresas en crecimiento que reciben cientos de consultas diarias. La automatización de la base de conocimientos cambia este paradigma utilizando inteligencia artificial para extraer información relevante de los tickets de soporte, estructurarla según plantillas predefinidas y publicarla directamente en tu sitio web. El sistema de automatización actúa como un intermediario inteligente entre tu equipo de soporte y tu web, identificando qué tickets contienen conocimiento generalizable que beneficiará a otros usuarios y transformando esa conversación de soporte en documentación profesional y pulida. Este enfoque no solo ahorra tiempo, sino que también asegura coherencia en el formato, la estructura y la optimización SEO en todos los artículos de la base de conocimientos. El sistema puede configurarse para entender el contexto específico de tu negocio, evitar la creación de contenido duplicado y mantener una base de conocimientos coherente que crece orgánicamente a medida que tu equipo responde más consultas.
¿Listo para hacer crecer tu negocio?
Comienza tu prueba gratuita hoy y ve resultados en días.
Por qué la automatización de la base de conocimientos es importante para tu empresa
La justificación empresarial para la automatización de la base de conocimientos es convincente y multifacética. En primer lugar, reduce drásticamente el volumen de soporte al permitir que los clientes encuentren respuestas de manera independiente. Diversos estudios demuestran que los clientes prefieren las opciones de autoservicio cuando están disponibles y son eficaces, y una base de conocimientos bien mantenida puede reducir los tickets de soporte entre un 20 y un 30%. En segundo lugar, mejora la satisfacción del cliente al proporcionar respuestas instantáneas a preguntas comunes sin que tengan que esperar una respuesta de soporte. En tercer lugar, genera importantes beneficios de SEO: los artículos de la base de conocimientos son indexados por los motores de búsqueda y pueden atraer tráfico orgánico, mejorando tu visibilidad y atrayendo nuevos clientes que encuentran tu contenido a través de búsquedas. En cuarto lugar, captura el conocimiento institucional que de otro modo se perdería cuando los miembros del equipo abandonan la organización. Cada interacción de soporte contiene contexto y soluciones valiosas que, al documentarse, pasan a formar parte del repositorio de conocimiento permanente de tu empresa. En quinto lugar, permite que tu equipo de soporte se enfoque en asuntos complejos y de mayor valor añadido en lugar de responder repetidamente las mismas preguntas. Al automatizar la creación de contenido de base de conocimientos a partir de tickets de soporte, básicamente estás creando un multiplicador de fuerza para tu organización de soporte. El tiempo que tu equipo invierte en responder consultas se transforma en conocimiento documentado que servirá a miles de clientes en el futuro. Finalmente, proporciona datos valiosos sobre los problemas con los que tus clientes tienen dificultades, lo que puede informar el desarrollo de productos, los mensajes de marketing y las iniciativas educativas para clientes.
Arquitectura de la generación automatizada de bases de conocimientos
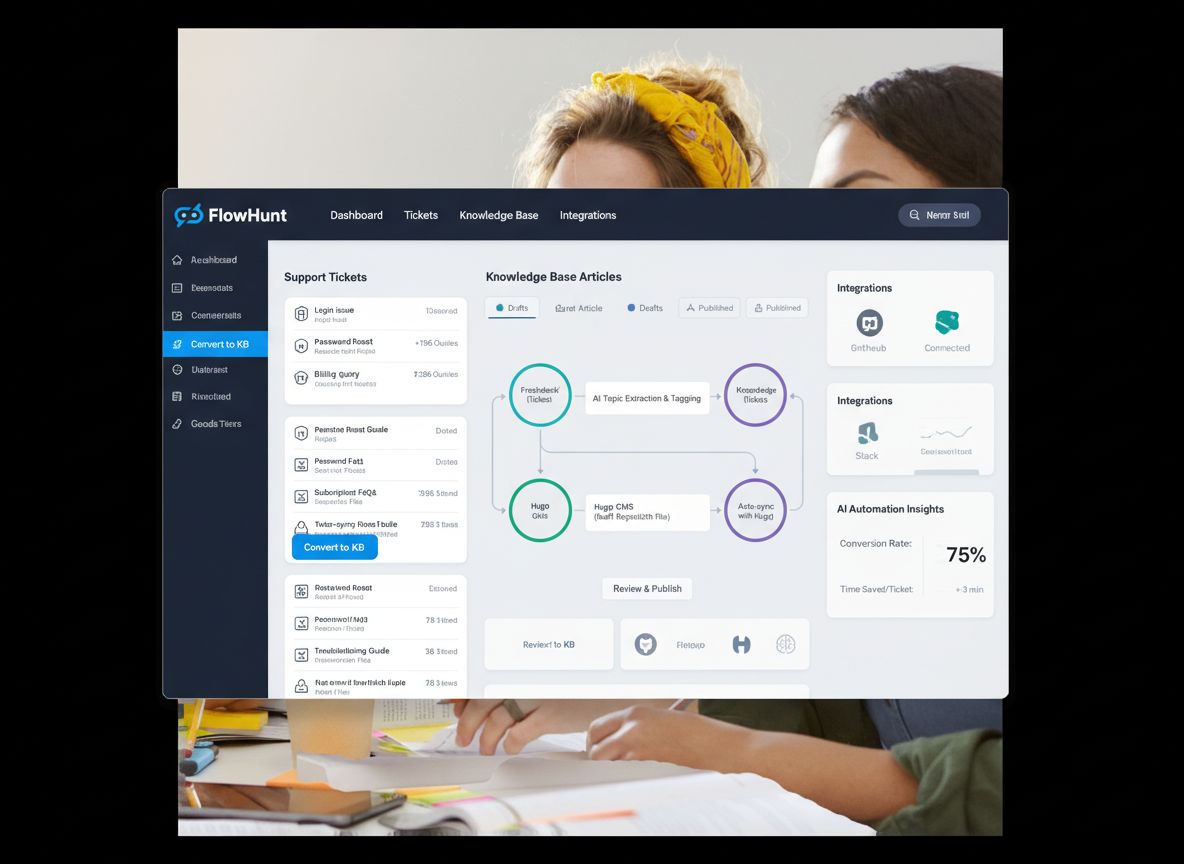
Construir un sistema automatizado de base de conocimientos requiere integrar varias herramientas y plataformas en un flujo de trabajo cohesivo. El sistema suele estar compuesto por cuatro componentes principales: un sistema de tickets (LiveAgent), un agente de IA que procesa los tickets, un sistema de control de versiones (GitHub) y un generador de sitios estáticos (Hugo). LiveAgent es la fuente de verdad para las consultas de los clientes, almacenando todas las conversaciones de soporte con metadatos como etiquetas, categorías y marcas de tiempo. El agente de IA es el orquestador de todo el proceso: recibe un ID de ticket, recupera el contenido completo y el historial de la conversación, analiza si es adecuado para publicarse en la base de conocimientos, verifica la existencia de artículos similares para evitar duplicados, genera contenido SEO-optimizado en el formato adecuado y gestiona el flujo de trabajo con GitHub. GitHub actúa como la capa de gestión de contenidos y control de versiones, permitiendo la revisión, aprobación y seguimiento de todos los cambios en la base de conocimientos. Hugo, como generador de sitios estáticos, transforma los archivos markdown almacenados en GitHub en un sitio web rápido, seguro y optimizado para SEO. Esta arquitectura crea una clara separación de responsabilidades: LiveAgent se encarga del soporte, el agente de IA de la inteligencia y la toma de decisiones, GitHub del control de versiones y colaboración, y Hugo de la presentación. Lo mejor de este sistema es que cada componente puede mantenerse y actualizarse de forma independiente sin afectar a los demás.
Únete a nuestro boletín
Obtén los últimos consejos, tendencias y ofertas gratis.
Cómo FlowHunt facilita la automatización de la base de conocimientos
FlowHunt proporciona la capa de orquestación que conecta todos estos sistemas en un flujo de trabajo sin fisuras. En vez de requerir desarrollo a medida o integraciones complejas, FlowHunt te permite diseñar visualmente el flujo de automatización, conectando LiveAgent, GitHub y Hugo a través de una interfaz intuitiva y sencilla. La plataforma gestiona la autenticación, el manejo de errores, la lógica de reintentos y toda la complejidad técnica que normalmente requeriría un importante esfuerzo de ingeniería. Con FlowHunt, puedes crear flujos de trabajo sofisticados sin escribir código, haciendo que la automatización de la base de conocimientos sea accesible a equipos sin recursos de desarrollo dedicados. Además, la plataforma provee gestión de memoria y contexto, permitiendo que tu automatización aprenda de ejecuciones previas y tome decisiones inteligentes sobre cuándo crear nuevos artículos o actualizar existentes. La integración de FlowHunt con GitHub permite la creación automática de pull requests, de modo que tu equipo pueda revisar el contenido generado antes de que se publique. Este enfoque de “humano en el ciclo” asegura la calidad mientras aprovecha la eficiencia de la automatización.
El flujo completo: proceso paso a paso
El flujo de trabajo de generación automática de la base de conocimientos sigue una secuencia cuidadosamente diseñada de pasos, cada uno construyendo sobre el anterior para crear un artículo completo y listo para producción. Comprender este proceso es esencial para implementarlo eficazmente en tu organización.
Primer paso: Recuperación y validación del ticket
El flujo comienza cuando proporcionas un ID de ticket de tu sistema LiveAgent. El agente de IA recupera de inmediato el contenido completo del ticket, incluyendo el asunto, el texto del cuerpo, todas las etiquetas y el historial completo de la conversación entre el cliente y el equipo de soporte. Esta recuperación integral es crucial porque asegura que la IA tenga todo el contexto necesario para generar contenido preciso y relevante. El agente también valida que el ticket contenga suficiente información y sea adecuado para su publicación en la base de conocimientos. Por ejemplo, si tu organización recibe muchas solicitudes de programación de demos, puedes configurar el sistema para que omita automáticamente estos tickets, ya que no representan conocimiento generalizable útil para otros usuarios. Este filtro previene que tu base de conocimientos se llene de contenido administrativo o transaccional que no aporta valor a tus usuarios.
Segundo paso: Detección de duplicados mediante memoria
Antes de generar nuevo contenido, el sistema revisa su memoria para determinar si ya se ha creado un artículo similar. Este sistema de memoria es una de las funciones más importantes de la automatización, ya que evita la creación de artículos duplicados o casi duplicados que podrían confundir a los usuarios y perjudicar tu SEO. El agente de IA busca en tickets previos y artículos generados para encontrar temas similares. Si encuentra una coincidencia, puede actualizar el artículo existente con nueva información o saltarse la creación, según tu configuración. Si no existe un tema similar, el agente añade este ticket a su memoria, creando un registro que se consultará en futuros tickets. Este enfoque basado en memoria hace que el sistema sea más inteligente con el tiempo: a medida que procesas más tickets, el sistema construye un mapa completo de tu base de conocimientos y puede tomar decisiones cada vez más inteligentes sobre creación y actualización de contenido.
Tercer paso: Análisis de la estructura de la base de conocimientos
El sistema examina tu repositorio existente de base de conocimientos para entender cómo está estructurado, formateado y organizado el contenido. Este paso es clave para asegurar la coherencia en todos los artículos. El agente de IA analiza los archivos markdown existentes, el formato de frontmatter, la estructura de encabezados y los patrones de contenido para entender las convenciones de tu base de conocimientos. Observa cómo se categorizan los artículos, qué metadatos se incluyen, cómo se referencian imágenes y qué elementos SEO están presentes. Al analizar tu contenido existente, el sistema aprende tus requisitos específicos de estilo y estructura, asegurando que los artículos generados se integren perfectamente en tu base de conocimientos y no destaquen como contenido obviamente automatizado.
Cuarto paso: Gestión de ramas en GitHub
Para mantener un control de versiones limpio y permitir flujos de revisión adecuados, el sistema crea o utiliza una rama existente en GitHub para la actualización de la base de conocimientos. En lugar de crear una nueva rama por cada ticket, el sistema gestiona las ramas de forma inteligente para mantener tu repositorio organizado. Si ya existe una rama para actualizaciones de la base de conocimientos, el sistema la utiliza y añade el nuevo archivo. Este enfoque previene la proliferación de ramas y permite agrupar varias actualizaciones en una sola pull request para revisión. El nombre de la rama suele ser descriptivo, como “knowledge-base-updates” o “kb-automation”, facilitando a los miembros del equipo la comprensión del propósito de la rama.
Quinto paso: Generación y formateo de contenido
Con todo el contexto recopilado, el agente de IA genera el artículo de la base de conocimientos. El contenido generado incluye una sección de frontmatter correctamente formateada con metadatos como título, descripción, palabras clave, etiquetas, categorías, fecha de publicación y elementos de llamada a la acción. El cuerpo del artículo sigue un formato estructurado diseñado tanto para la legibilidad del usuario como para la optimización en buscadores. Normalmente incluye un titular principal, varias secciones H2 con encabezados en forma de pregunta (como “¿Qué es esto?”, “¿Por qué deberíamos hacerlo?” y “¿Cómo se hace?”) y respuestas detalladas en párrafos y listas con viñetas. Esta estructura está optimizada para fragmentos destacados y otras funciones de los motores de búsqueda que premian los formatos claros de pregunta-respuesta. El contenido se escribe en formato markdown, que es el estándar para Hugo y la mayoría de generadores de sitios estáticos, asegurando compatibilidad y fácil edición.
Sexto paso: Creación de archivo y commit
El sistema crea un nuevo archivo markdown en tu carpeta de base de conocimientos con un nombre apropiado basado en el tema del artículo. El nombre del archivo suele estar en minúsculas y con guiones en lugar de espacios para seguir los estándares web. El archivo incluye el frontmatter completo y el contenido generado en el paso anterior. Una vez creado el archivo, el sistema realiza el commit de los cambios en la rama de GitHub con un mensaje descriptivo que referencia el ID del ticket original. Este mensaje de commit crea un registro permanente que vincula el artículo de la base de conocimientos con la consulta original del cliente, permitiendo trazabilidad y contexto para futuras referencias.
Séptimo paso: Creación y revisión de pull request
Finalmente, el sistema crea una pull request desde la rama de la base de conocimientos hacia tu rama principal. Esta pull request incluye una descripción de los cambios, el ID del ticket que motivó la creación y cualquier contexto relevante. La pull request funciona como un punto de control donde tu equipo puede revisar el contenido generado, realizar los ajustes necesarios, verificar que el artículo cumple con tus estándares de calidad y asegurarse de que se alinea con la estrategia de tu base de conocimientos. Este paso de revisión humana es fundamental: aunque el contenido generado por IA suele ser de alta calidad, la supervisión humana garantiza precisión, coherencia de marca y adecuación. Una vez que tu equipo aprueba la pull request, puede fusionarse con la rama principal, lo que provoca que Hugo reconstruya tu sitio web y publique el nuevo artículo.
Implementación práctica: cómo encontrar y usar los IDs de ticket
Para utilizar este flujo de automatización, necesitas identificar el ID de ticket correcto en tu sistema LiveAgent. LiveAgent muestra los IDs de ticket en dos lugares convenientes. Primero, dentro de la propia interfaz de LiveAgent, verás una etiqueta “Ticket” con el ID destacado. Puedes copiar este ID directamente de la interfaz. Segundo, y a menudo más conveniente, puedes encontrar el ID de ticket en la URL de la página del ticket. Cuando abres un ticket en LiveAgent, la URL contendrá un parámetro como “ID=12345” al final. Este ID es exactamente el que debes proporcionar al flujo de automatización. Una vez tienes el ID del ticket, simplemente lo introduces en el flujo de trabajo de FlowHunt y todo el proceso comienza automáticamente. El sistema recupera el ticket, lo analiza, comprueba duplicados, genera el artículo, crea la rama y la pull request en GitHub y notifica a tu equipo para su revisión. Todo el proceso suele completarse en segundos o minutos, dependiendo de la complejidad del ticket y del tamaño de tu base de conocimientos.
Potencia tu flujo de trabajo con FlowHunt
Descubre cómo FlowHunt automatiza la creación de tu base de conocimientos a partir de tickets de soporte — desde el análisis del ticket y la generación de contenido hasta la integración con GitHub y la publicación en Hugo — todo en un solo flujo de trabajo integrado.
Una vez que tienes el flujo básico en marcha, existen varias configuraciones avanzadas que pueden optimizar el sistema según tus necesidades específicas. Puedes configurar el sistema para ignorar ciertos tipos de tickets según etiquetas, categorías o palabras clave. Por ejemplo, quizás quieras omitir todos los tickets etiquetados como “facturación” o “específicos de cuenta”, ya que normalmente no representan conocimiento generalizable. También puedes establecer umbrales de calidad o longitud del artículo: si un ticket es demasiado corto o carece de detalles suficientes, el sistema puede saltarlo y esperar información más completa. El sistema de memoria puede configurarse para usar distintos algoritmos de coincidencia, desde coincidencia simple de palabras clave hasta análisis semántico sofisticado. También puedes personalizar el frontmatter y la estructura del contenido para adaptarlos a tus requerimientos, añadiendo campos personalizados o modificando el formato del artículo. Algunas organizaciones añaden metadatos adicionales como nivel de dificultad, público objetivo o artículos relacionados. Incluso puedes configurar el sistema para añadir imágenes automáticamente a los artículos, generándolas con IA o extrayéndolas de tu biblioteca de activos. El sistema puede configurarse para crear artículos en varios idiomas si atiendes a una audiencia internacional. También puedes establecer notificaciones y aprobaciones, por ejemplo, exigiendo que ciertos miembros del equipo aprueben artículos de determinadas categorías antes de publicarlos.
Ejemplo real: error de integración con WordPress
Considera un ejemplo práctico del flujo en acción. Un cliente envía un ticket de soporte preguntando por un error de integración con WordPress que está experimentando. El ticket incluye mensajes de error, capturas de pantalla y una descripción detallada de lo que ha intentado. El equipo de soporte responde con pasos de solución y finalmente resuelve el problema. Este ticket es un candidato perfecto para la automatización de la base de conocimientos. Cuando se proporciona el ID del ticket al flujo, el sistema recupera la conversación completa, la analiza y revisa su memoria. Como no existe un artículo previo sobre errores de integración con WordPress, el sistema añade este tema a la memoria y procede a generar el artículo. El sistema examina tu base de conocimientos y detecta que tienes un formato específico para artículos técnicos de resolución de problemas, con secciones para síntomas, causas, soluciones y prevención. El artículo generado sigue este formato, creando una guía completa sobre errores de integración con WordPress que ayudará a futuros clientes a resolver el mismo problema de forma independiente. El artículo se crea en una rama de GitHub, se genera una pull request, tu equipo la revisa, realiza los ajustes necesarios y la fusiona. En cuestión de minutos, el artículo está disponible en tu web, indexado por buscadores y listo para ayudar a otros clientes. La próxima vez que alguien busque “error de integración con WordPress” o tenga este problema, encontrará tu artículo en la base de conocimientos y resolverá su duda sin necesidad de contactar al soporte.
Medición del éxito y retorno de la inversión
Para justificar la inversión en la automatización de la base de conocimientos, es importante medir su impacto. Las métricas clave incluyen la reducción del volumen de tickets de soporte para preguntas cubiertas por artículos de la base de conocimientos, el aumento de tráfico orgánico desde buscadores, el tiempo ahorrado por tu equipo de soporte y la mejora en los puntajes de satisfacción del cliente. Puedes rastrear cuántos clientes acceden a los artículos antes de contactar al soporte, cuántos tickets hacen referencia a artículos de la base de conocimientos y cuántos clientes reportan haber encontrado la respuesta que necesitaban en la base de conocimientos. También puedes medir la calidad de los artículos generados mediante métricas de engagement como tiempo en página, profundidad de scroll y tasa de rebote. Los artículos valiosos tendrán métricas de engagement más altas. Además, puedes rastrear el número de artículos generados, el tiempo ahorrado frente a la creación manual y el ahorro de costes por menor volumen de soporte. La mayoría de las organizaciones constata que la automatización de la base de conocimientos se paga sola en los primeros meses a través de la reducción de costes y la mejora de la satisfacción del cliente.
Conclusión
Automatizar la creación de la base de conocimientos a partir de tickets de LiveAgent representa una oportunidad significativa para mejorar la eficiencia del soporte, potenciar el SEO de tu sitio web y crear un recurso valioso que siga sirviendo a tus clientes mucho después de la interacción inicial. Al conectar LiveAgent, GitHub, Hugo y la automatización impulsada por IA mediante FlowHunt, creas un sistema que transforma consultas en bruto de clientes en artículos pulidos y profesionales de base de conocimientos de forma automática. El flujo de trabajo es sencillo: proporciona un ID de ticket y el sistema se encarga de todo, desde la generación de contenido hasta la integración con GitHub y la creación de la pull request. El sistema de memoria asegura que no crees contenido duplicado, mientras que la revisión humana mantiene la calidad y coherencia de la marca. A medida que tu base de conocimientos crece, se convierte en un activo cada vez más valioso que reduce costes de soporte, mejora la satisfacción del cliente y atrae tráfico orgánico a tu web. La implementación es accesible para equipos sin gran experiencia técnica, lo que hace que esta poderosa automatización esté al alcance de organizaciones de todos los tamaños.
Preguntas frecuentes
¿Qué es un ticket de LiveAgent?
Un ticket de LiveAgent es una solicitud o consulta de soporte al cliente registrada en el sistema de tickets de LiveAgent. Cada ticket contiene un asunto, cuerpo, etiquetas y el historial completo de la conversación, que puede usarse para generar contenido de base de conocimientos.
¿Cómo encuentro el ID de mi ticket en LiveAgent?
Puedes encontrar el ID de tu ticket de dos maneras: (1) Busca la etiqueta 'Ticket' con el ID visible en la interfaz de LiveAgent, o (2) revisa la URL al final, donde aparece 'ID=tu-id-del-ticket'. Copia este ID para usarlo en el flujo de automatización.
¿Puede el flujo ignorar ciertos tipos de tickets?
Sí, el flujo puede configurarse para ignorar tipos específicos de tickets. Por ejemplo, puedes hacer que omita solicitudes de programación de demos para evitar crear páginas duplicadas de base de conocimientos sobre temas similares.
¿Qué ocurre si ya existe un artículo similar en la base de conocimientos?
El flujo utiliza memoria para comprobar si un tema similar ha sido procesado antes. Si encuentra una coincidencia, actualizará el artículo existente si es necesario o evitará crear uno nuevo para no duplicar contenido.
¿Cómo se integra el flujo con GitHub?
El flujo crea o usa una rama existente en GitHub, genera un archivo markdown con el frontmatter adecuado, realiza el commit de los cambios y crea una solicitud de extracción para revisión antes de fusionar con la rama principal.
Arshia es ingeniera de flujos de trabajo de IA en FlowHunt. Con formación en ciencias de la computación y una pasión por la IA, se especializa en crear flujos de trabajo eficientes que integran herramientas de IA en las tareas cotidianas, mejorando la productividad y la creatividad.
Arshia Kahani
Ingeniera de flujos de trabajo de IA
Automatiza la creación de tu base de conocimientos
Transforma tickets de soporte al cliente en artículos SEO-optimizados de base de conocimientos automáticamente con los flujos de trabajo impulsados por IA de FlowHunt.
Cómo automatizar la respuesta de tickets en LiveAgent con FlowHunt
Aprende cómo integrar los flujos de IA de FlowHunt con LiveAgent para responder automáticamente a tickets de clientes utilizando reglas inteligentes de automati...
Integración avanzada de FlowHunt–LiveAgent: control de idioma, filtrado de spam, selección de API y mejores prácticas de automatización
Una guía técnica para dominar la integración avanzada de FlowHunt con LiveAgent, cubriendo segmentación por idioma, supresión de markdown, filtrado de spam, ver...
Despliega un chatbot potenciado por IA en tu sitio web que aprovecha tu base de conocimientos interna para responder a las consultas de los clientes, y deriva s...
4 min de lectura
Consentimiento de Cookies Usamos cookies para mejorar tu experiencia de navegación y analizar nuestro tráfico. See our privacy policy.