Middleware Human-in-the-Loop en Python: Construyendo Agentes de IA Seguros con Flujos de Aprobación
Aprende a implementar middleware human-in-the-loop en Python usando LangChain para agregar capacidades de aprobación, edición y rechazo a agentes de IA antes de la ejecución de herramientas.
Construir agentes de IA que puedan ejecutar herramientas y tomar acciones de manera autónoma es poderoso, pero conlleva riesgos inherentes. ¿Qué sucede cuando un agente decide enviar un correo electrónico con información incorrecta, aprobar una gran transacción financiera o modificar registros críticos de una base de datos? Sin las protecciones adecuadas, los agentes autónomos pueden causar daños significativos antes de que alguien se dé cuenta de lo ocurrido. Aquí es donde el middleware human-in-the-loop se vuelve esencial. En esta guía completa, exploraremos cómo implementar middleware human-in-the-loop en Python usando LangChain, permitiéndote construir agentes de IA que se detienen para solicitar aprobación humana antes de ejecutar operaciones sensibles. Aprenderás cómo agregar flujos de aprobación, implementar capacidades de edición y manejar rechazos, todo mientras mantienes la eficiencia e inteligencia de tus sistemas autónomos.
Entendiendo los Bucles de los Agentes de IA y la Ejecución de Herramientas
Antes de adentrarnos en el middleware human-in-the-loop, es fundamental comprender cómo funcionan los agentes de IA en esencia. Un agente de IA opera mediante un bucle continuo que se repite hasta que el agente decide que ha completado su tarea. El bucle central del agente consta de tres componentes principales: un modelo de lenguaje que razona sobre qué hacer a continuación, un conjunto de herramientas que el agente puede invocar para actuar y un sistema de gestión de estado que rastrea el historial de la conversación y cualquier contexto relevante. El agente comienza recibiendo un mensaje de entrada de un usuario, luego el modelo de lenguaje analiza esta entrada junto con las herramientas disponibles y decide si llamar a una herramienta o proporcionar una respuesta final. Si el modelo decide llamar a una herramienta, esa herramienta se ejecuta y los resultados se agregan al historial de la conversación. Este ciclo continúa—razonamiento del modelo, selección de herramienta, ejecución de herramienta, integración de resultados—hasta que el modelo determina que no se necesitan más llamadas a herramientas y proporciona una respuesta final al usuario.
Este patrón simple pero poderoso se ha convertido en la base para cientos de frameworks de agentes de IA en los últimos años. La elegancia del bucle del agente reside en su flexibilidad: al cambiar las herramientas disponibles para un agente, puedes habilitarlo para realizar tareas muy diferentes. Un agente con herramientas de correo electrónico puede gestionar comunicaciones, un agente con herramientas de base de datos puede consultar y actualizar registros, y un agente con herramientas financieras puede procesar transacciones. Sin embargo, esta flexibilidad también introduce riesgo. Debido a que el bucle del agente opera de forma autónoma, no hay un mecanismo incorporado para pausar y preguntar a una persona si realmente debería realizarse una acción en particular. El modelo podría decidir enviar un correo, ejecutar una consulta de base de datos o aprobar una transacción financiera, y para cuando una persona se da cuenta de lo que ocurrió, la acción ya se ha completado. Aquí es donde las limitaciones del bucle básico del agente se hacen evidentes en entornos de producción.
¿Listo para hacer crecer tu negocio?
Comienza tu prueba gratuita hoy y ve resultados en días.
Por Qué la Supervisión Humana es Importante en Sistemas de IA en Producción
A medida que los agentes de IA se vuelven más capaces y se despliegan en entornos empresariales reales, la necesidad de supervisión humana se vuelve cada vez más crítica. La importancia de las acciones de los agentes autónomos varía drásticamente según el contexto. Algunas llamadas a herramientas son de bajo riesgo y pueden ejecutarse inmediatamente sin revisión humana—por ejemplo, leer un correo o recuperar información de una base de datos. Otras llamadas a herramientas son de alto riesgo y potencialmente irreversibles, como enviar comunicaciones en nombre de un usuario, transferir fondos, eliminar registros o realizar compromisos que vinculan a una organización. En sistemas de producción, el costo de que un agente cometa un error en una operación de alto riesgo puede ser enorme. Un correo mal redactado enviado al destinatario equivocado podría dañar relaciones comerciales. Una aprobación incorrecta de presupuesto podría ocasionar pérdidas financieras. Una eliminación de base de datos ejecutada por error podría resultar en la pérdida de datos que toma horas o días recuperar de respaldos.
Más allá de los riesgos operativos inmediatos, también existen consideraciones de cumplimiento y regulatorias. Muchas industrias tienen requisitos estrictos de que ciertos tipos de decisiones deben involucrar juicio y aprobación humanos. Las instituciones financieras deben tener supervisión humana de transacciones superiores a ciertos umbrales. Los sistemas de salud deben tener revisión humana de ciertas decisiones automatizadas. Los despachos legales deben asegurarse de que las comunicaciones sean revisadas antes de enviarse en nombre de clientes. Estos requisitos regulatorios no son solo burocracia: existen porque las consecuencias de decisiones totalmente autónomas en estos dominios pueden ser graves. Adicionalmente, la supervisión humana proporciona un mecanismo de retroalimentación que ayuda a mejorar al agente con el tiempo. Cuando una persona revisa una acción propuesta por el agente y la aprueba o sugiere ediciones, esa retroalimentación puede utilizarse para refinar los prompts del agente, ajustar su lógica de selección de herramientas o reentrenar sus modelos subyacentes. Esto crea un ciclo virtuoso donde el agente se vuelve más fiable y mejor calibrado a las necesidades y tolerancia al riesgo específicas de la organización.
¿Qué es el Middleware Human-in-the-Loop?
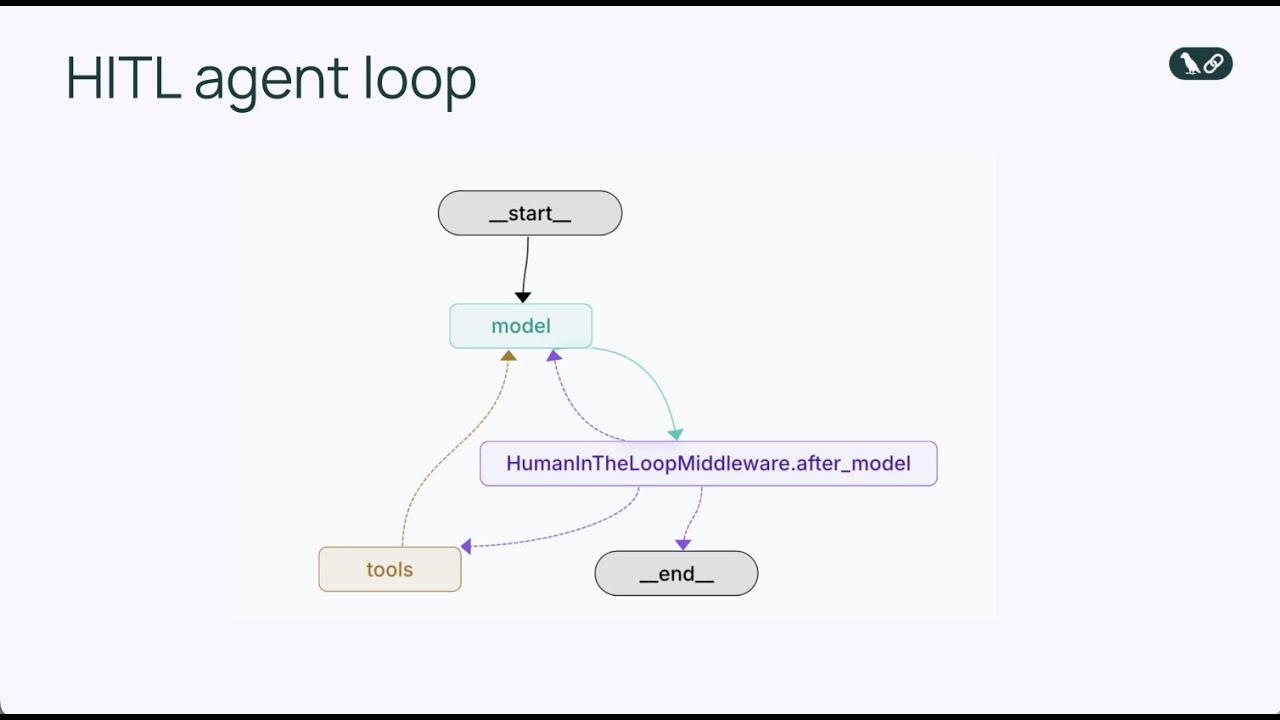
El middleware human-in-the-loop es un componente especializado que intercepta el bucle del agente en un punto crítico: justo antes de que se ejecute una herramienta. En lugar de permitir que el agente ejecute inmediatamente una llamada a herramienta, el middleware pausa la ejecución y presenta la acción propuesta a una persona para su revisión. El humano entonces tiene varias opciones para responder. Puede aprobar la acción, permitiendo que proceda exactamente como lo propuso el agente. Puede editar la acción, modificando los parámetros (como cambiar el destinatario de un correo o ajustar el contenido del mensaje) antes de permitir la ejecución. O puede rechazar la acción por completo, enviando retroalimentación al agente explicando por qué la acción fue inapropiada y pidiéndole que reconsidere su enfoque. Este mecanismo de decisión triple—aprobar, editar, rechazar—proporciona un marco flexible que se adapta a diferentes tipos de necesidades de supervisión humana.
El middleware opera modificando el bucle estándar del agente para incluir un punto de decisión adicional. En el bucle básico del agente, la secuencia es: el modelo llama a herramientas → las herramientas se ejecutan → los resultados regresan al modelo. Con el middleware human-in-the-loop, la secuencia se convierte en: el modelo llama a herramientas → el middleware intercepta → el humano revisa → el humano decide (aprobar/editar/rechazar) → si se aprueba o edita, la herramienta se ejecuta → los resultados regresan al modelo. Esta inserción de un punto de decisión humano no rompe el bucle del agente; más bien, lo mejora agregando una válvula de seguridad. El middleware es configurable, lo que significa que puedes especificar exactamente qué herramientas deben activar la revisión humana y cuáles pueden ejecutarse automáticamente. Puede que quieras interrumpir en todas las herramientas de envío de correos pero permitir que las consultas de base de datos solo lectura se ejecuten sin revisión. Este control granular asegura que añades supervisión humana justo donde se necesita sin crear cuellos de botella innecesarios para operaciones de bajo riesgo.
Únete a nuestro boletín
Obtén los últimos consejos, tendencias y ofertas gratis.
Los Tres Tipos de Respuesta: Aprobación, Edición y Rechazo
Cuando un middleware human-in-the-loop interrumpe la ejecución de una herramienta por parte de un agente, el revisor humano tiene tres formas principales de responder, cada una sirviendo un propósito diferente en el flujo de aprobación. Entender estos tres tipos de respuesta es esencial para diseñar sistemas human-in-the-loop efectivos.
Aprobación es el tipo de respuesta más simple. Cuando una persona revisa una llamada a herramienta propuesta y determina que es apropiada y debe proceder exactamente como la propuso el agente, proporciona una decisión de aprobación. Esto indica al middleware que la herramienta debe ejecutarse con los parámetros exactos que especificó el agente. En el contexto de un asistente de correo, la aprobación significa que el borrador del correo se ve bien y debe enviarse al destinatario especificado con el asunto y el cuerpo indicados. La aprobación es el camino de menor resistencia—permite que la acción propuesta por el agente se realice sin modificaciones. Esto es apropiado cuando el agente ha hecho bien su trabajo y el revisor humano está de acuerdo con la acción propuesta. Las decisiones de aprobación suelen tomarse rápidamente, lo cual es importante porque no quieres que la revisión humana se convierta en un cuello de botella que ralentice todo tu flujo.
Edición es un tipo de respuesta más matizado que reconoce que el enfoque general del agente es correcto, pero algunos detalles necesitan ajuste antes de la ejecución. Cuando un humano proporciona una respuesta de edición, no está rechazando la decisión del agente de actuar; más bien, está refinando los detalles de cómo debe realizarse esa acción. En un escenario de correo, editar podría significar cambiar la dirección de correo del destinatario, modificar el asunto para que sea más profesional o ajustar el cuerpo del mensaje para incluir contexto adicional o eliminar lenguaje potencialmente problemático. La característica clave de una respuesta de edición es que modifica los parámetros de la herramienta manteniendo la misma llamada. El agente decidió enviar un correo, y el humano está de acuerdo en que enviar un correo es la acción correcta, pero quiere ajustar lo que dice ese correo o a quién va dirigido. Tras la edición humana, la herramienta se ejecuta con los parámetros modificados y los resultados regresan al agente. Este enfoque es particularmente valioso porque permite que el agente proponga acciones mientras da a las personas la capacidad de ajustar esas acciones según su experiencia o conocimiento del contexto organizacional que el agente podría no tener.
Rechazo es el tipo de respuesta más significativo porque no solo detiene la acción propuesta sino que también envía retroalimentación al agente explicando por qué la acción era inapropiada. Cuando un humano rechaza una llamada a herramienta, está diciendo que la acción propuesta no debe tomarse en absoluto y proporciona orientación sobre cómo el agente debe reconsiderar su enfoque. En el ejemplo del correo, el rechazo podría ocurrir cuando el agente propone enviar un mensaje aprobando una solicitud de presupuesto importante sin suficiente detalle o justificación. El humano rechaza esta acción y envía un mensaje al agente explicando que se necesita más detalle antes de poder aprobar. Este mensaje de rechazo se convierte en parte del contexto del agente, y el agente puede entonces razonar sobre esta retroalimentación y proponer un enfoque revisado. El agente podría entonces proponer un correo diferente solicitando más información sobre la propuesta de presupuesto antes de comprometerse a aprobar. Las respuestas de rechazo son cruciales para evitar que el agente proponga repetidamente la misma acción inapropiada. Al proporcionar retroalimentación clara sobre por qué se rechazó una acción, ayudas al agente a aprender y mejorar su toma de decisiones.
Implementando Middleware Human-in-the-Loop: Un Ejemplo Práctico
Veamos una implementación concreta de middleware human-in-the-loop usando LangChain y Python. El ejemplo que usaremos es un asistente de correo electrónico—un escenario práctico que demuestra el valor de la supervisión humana y resulta fácil de entender. El asistente de correo podrá enviar correos en nombre de un usuario y agregaremos middleware human-in-the-loop para asegurarnos de que todos los envíos de correos sean revisados antes de ejecutarse.
Primero, necesitamos definir la herramienta de correo que usará nuestro agente. Esta herramienta toma tres parámetros: una dirección de correo de destino, un asunto y el cuerpo del mensaje. La herramienta es sencilla—simplemente representa la acción de enviar un correo. En una implementación real, podría integrarse con un servicio como Gmail u Outlook, pero para efectos de demostración, podemos mantenerlo simple. Aquí la estructura básica:
defsend_email(recipient: str, subject: str, body: str) -> str:
"""Envía un correo al destinatario especificado."""returnf"Correo enviado a {recipient} con asunto '{subject}'"
Luego, creamos un agente que use esta herramienta de correo. Usaremos GPT-4 como modelo de lenguaje y proporcionaremos un prompt de sistema que indique al agente que es un asistente de correo útil. El agente se inicializa con la herramienta de correo y está listo para responder solicitudes de usuarios:
from langchain.agents import create_agent
from langchain_openai import ChatOpenAI
model = ChatOpenAI(model="gpt-4o")
tools = [send_email]
agent = create_agent(
model=model,
tools=tools,
system_prompt="Eres un asistente de correo útil para Sydney. Puedes enviar correos en nombre del usuario.")
En este punto, tenemos un agente básico que puede enviar correos. Sin embargo, no existe supervisión humana—el agente puede enviar correos sin revisión alguna. Ahora agreguemos el middleware human-in-the-loop. La implementación es notablemente simple, requiriendo solo dos líneas de código:
from langchain.agents.middleware import HumanInTheLoopMiddleware
agent = create_agent(
model=model,
tools=tools,
system_prompt="Eres un asistente de correo útil para Sydney. Puedes enviar correos en nombre del usuario.",
middleware=[
HumanInTheLoopMiddleware(
interrupt_on={"send_email": True}
)
]
)
Al agregar HumanInTheLoopMiddleware y especificar interrupt_on={"send_email": True}, estamos indicando al agente que se detenga antes de ejecutar cualquier llamada a la herramienta send_email y espere aprobación humana. El valor True significa que todas las llamadas a send_email activarán una interrupción con la configuración predeterminada. Si quisiéramos control más granular, podríamos especificar qué tipos de decisiones se permiten (aprobar, editar, rechazar) o proporcionar descripciones personalizadas para la interrupción.
Probando el Middleware con Escenarios de Bajo Riesgo
Una vez colocado el middleware, probémoslo con un escenario de correo de bajo riesgo. Imagina que un usuario le pide al agente que responda a un correo casual de una colega llamada Alice que sugiere tomar un café la próxima semana. El agente procesa esta solicitud y decide enviar una respuesta amistosa. Esto es lo que ocurre:
El usuario envía un mensaje: “Por favor responde al correo de Alice sobre tomar café la próxima semana.”
El modelo de lenguaje del agente procesa esto y decide llamar a la herramienta send_email con parámetros como recipient=“alice@example.com
”, subject="¿Café la próxima semana?", body="¡Me encantaría tomar café contigo la próxima semana!"
Antes de que el correo se envíe, el middleware intercepta la llamada y lanza una interrupción.
El revisor humano ve el correo propuesto y lo revisa. El correo parece apropiado—es amistoso, profesional y atiende la solicitud del usuario.
El humano aprueba la acción proporcionando una decisión de aprobación.
El middleware permite la ejecución de la herramienta y el correo se envía.
Este flujo demuestra el camino básico de aprobación. La revisión humana añade una capa de seguridad sin ralentizar significativamente el proceso. Para operaciones de bajo riesgo como esta, la aprobación ocurre típicamente de manera rápida porque la acción propuesta por el agente es razonable y no requiere modificaciones.
Probando el Middleware con Escenarios de Alto Riesgo: La Respuesta de Edición
Ahora consideremos un escenario más trascendental donde la edición resulta valiosa. Imagina que el agente recibe una solicitud para responder a un correo de un socio de startup pidiéndole al usuario que apruebe un presupuesto de ingeniería de un millón de dólares para el Q1. Esta es una decisión de alto riesgo que requiere consideración cuidadosa. El agente podría proponer un correo que diga algo como: “He revisado y aprobado la propuesta para el presupuesto de ingeniería de $1 millón para el Q1.”
Cuando este correo propuesto llega al revisor humano a través de la interrupción del middleware, la persona reconoce que se trata de un compromiso financiero importante que no debería aprobarse sin más revisión. El humano no quiere rechazar la idea de responder al correo, pero sí modificar la respuesta para ser más cauteloso. El humano proporciona una respuesta de edición que modifica el cuerpo del correo para decir algo como: “Gracias por la propuesta. Me gustaría revisar los detalles más cuidadosamente antes de aprobar. ¿Podrías enviarme un desglose de cómo se asignará el presupuesto?”
Así se vería una respuesta de edición en código:
edit_decision = {
"type": "edit",
"edited_action": {
"name": "send_email",
"args": {
"recipient": "partner@startup.com",
"subject": "Propuesta de Presupuesto de Ingeniería Q1",
"body": "Gracias por la propuesta. Me gustaría revisar los detalles más cuidadosamente antes de aprobar. ¿Podrías enviarme un desglose de cómo se asignará el presupuesto?" }
}
}
Cuando el middleware recibe esta decisión de edición, ejecuta la herramienta con los parámetros modificados. El correo se envía con el contenido revisado por la persona, que es más apropiado para una decisión financiera de alto riesgo. Esto demuestra el poder del tipo de respuesta de edición: permite a las personas aprovechar la capacidad del agente para redactar comunicaciones asegurando que el resultado refleje el juicio humano y los estándares organizacionales.
Probando el Middleware con Rechazo y Retroalimentación
El tipo de respuesta de rechazo es especialmente potente porque no solo detiene una acción inapropiada, sino que además proporciona retroalimentación que ayuda al agente a mejorar su razonamiento. Consideremos otro escenario con el mismo correo de presupuesto de alto riesgo. Supongamos que el agente propone un correo que dice: “He revisado y aprobado el presupuesto de ingeniería de $1 millón para el Q1.”
El revisor humano ve esto y reconoce que es demasiado apresurado. Un compromiso de $1 millón no debe aprobarse sin una revisión exhaustiva, discusión con las partes interesadas y comprensión de los detalles del presupuesto. El humano no solo quiere editar el correo; quiere rechazar completamente este enfoque y pedirle al agente que lo reconsidere. El humano proporciona una respuesta de rechazo con retroalimentación:
reject_decision = {
"type": "reject",
"message": "No puedo aprobar este presupuesto sin más información. Por favor, redacta un correo solicitando un desglose detallado de la propuesta, incluyendo cómo se asignarán los fondos entre los diferentes equipos de ingeniería y qué entregables específicos se esperan."}
Cuando el middleware recibe esta decisión de rechazo, no ejecuta la herramienta. En su lugar, envía el mensaje de rechazo de vuelta al agente como parte del contexto de la conversación. El agente ahora ve que su acción propuesta fue rechazada y entiende el motivo. El agente puede entonces razonar sobre esta retroalimentación y proponer un enfoque diferente. En este caso, el agente podría proponer un nuevo correo solicitando más detalles sobre el presupuesto, lo que sería una respuesta más apropiada a una solicitud financiera de alto riesgo. El humano puede entonces revisar esta propuesta revisada y aprobarla, editarla nuevamente o rechazarla si es necesario.
Este proceso iterativo—propuesta, revisión, rechazo con retroalimentación, nueva propuesta—es uno de los aspectos más valiosos del middleware human-in-the-loop. Crea un flujo colaborativo donde la velocidad y el razonamiento del agente se combinan con el juicio humano y la experiencia en el dominio.
Potencia tu Flujo de Trabajo con FlowHunt
Descubre cómo FlowHunt automatiza tus flujos de contenido y SEO impulsados por IA — desde la investigación y generación de contenido hasta la publicación y analítica — todo en un solo lugar.
Configuración Avanzada: Control Granular sobre las Interrupciones
Aunque la implementación básica del middleware human-in-the-loop es sencilla, LangChain ofrece opciones de configuración avanzadas que te permiten afinar exactamente cómo y cuándo ocurren las interrupciones. Una configuración importante es especificar qué tipos de decisiones se permiten para cada herramienta. Por ejemplo, quizás quieras permitir aprobación y edición para envíos de correos, pero no rechazo. O quizás quieras permitir los tres tipos de decisión para transacciones financieras pero solo aprobación para consultas de base de datos de solo lectura.
Aquí tienes un ejemplo de configuración más granular:
from langchain.agents.middleware import HumanInTheLoopMiddleware
agent = create_agent(
model=model,
tools=tools,
middleware=[
HumanInTheLoopMiddleware(
interrupt_on={
"send_email": {
"allowed_decisions": ["approve", "edit", "reject"]
},
"read_database": False, # Autorización automática, sin interrupción"delete_record": {
"allowed_decisions": ["approve", "reject"] # No se permite editar en eliminaciones }
}
)
]
)
En esta configuración, los envíos de correo interrumpen y permiten los tres tipos de decisión. Las operaciones de solo lectura se ejecutan automáticamente sin interrupción. Las operaciones de eliminación interrumpen pero no permiten edición—el humano solo puede aprobar o rechazar, no modificar los parámetros de la eliminación. Este control granular asegura que añadas supervisión humana donde realmente se necesita, evitando cuellos de botella innecesarios en operaciones de bajo riesgo.
Otra característica avanzada es la posibilidad de proporcionar descripciones personalizadas para las interrupciones. Por defecto, el middleware proporciona una descripción genérica como “La ejecución de la herramienta requiere aprobación.” Puedes personalizar esto para dar información más específica según el contexto:
HumanInTheLoopMiddleware(
interrupt_on={
"send_email": {
"allowed_decisions": ["approve", "edit", "reject"],
"description": "El envío de correos requiere aprobación humana antes de la ejecución" }
}
)
Consideraciones Importantes de Implementación: Checkpointers y Gestión de Estado
Un aspecto crítico de la implementación del middleware human-in-the-loop que es fácil pasar por alto es la necesidad de un checkpointer. Un checkpointer es un mecanismo que guarda el estado del agente en el punto de la interrupción, permitiendo que el flujo de trabajo se reanude más tarde. Esto es esencial porque la revisión humana no ocurre instantáneamente—puede haber un retraso entre cuando ocurre la interrupción y cuando la persona proporciona su decisión. Sin un checkpointer, el estado del agente se perdería durante este lapso y no podrías reanudar el flujo correctamente.
LangChain proporciona varias opciones de checkpointer. Para desarrollo y pruebas, puedes usar un checkpointer en memoria:
Para sistemas en producción, normalmente querrás usar un checkpointer persistente que guarde el estado en una base de datos o sistema de archivos, asegurando que las interrupciones puedan reanudarse incluso si la aplicación se reinicia. El checkpointer mantiene un registro completo del estado del agente en cada paso, incluyendo el historial de la conversación, cualquier llamada a herramientas realizada y los resultados de esas llamadas. Cuando una persona proporciona una decisión (aprobar, editar o rechazar), el middleware usa el checkpointer para recuperar el estado guardado, aplicar la decisión humana y reanudar el bucle del agente desde ese punto.
Aplicaciones y Casos de Uso en el Mundo Real
El middleware human-in-the-loop es aplicable a una amplia variedad de escenarios reales donde los agentes autónomos necesitan tomar acciones pero esas acciones requieren supervisión humana. En el sector financiero, agentes que procesan transacciones, aprueban préstamos o gestionan inversiones pueden usar middleware human-in-the-loop para asegurar que decisiones de alto valor sean revisadas por personas calificadas antes de ejecutarse. En salud, agentes que puedan recomendar tratamientos o acceder a registros de pacientes pueden usar middleware para asegurar el cumplimiento de normativas de privacidad y protocolos clínicos. En servicios legales, agentes que redactan comunicaciones o acceden a documentos confidenciales pueden usar middleware para asegurar que se mantenga la supervisión de los abogados. En atención al cliente, agentes que puedan emitir reembolsos, hacer compromisos con clientes o escalar incidencias pueden usar middleware para asegurar que estas acciones estén alineadas con las políticas de la empresa.
Más allá de estas aplicaciones específicas de la industria, el middleware human-in-the-loop es valioso en cualquier escenario donde el costo de que un agente cometa un error sea significativo. Esto incluye sistemas de moderación de contenido donde los agentes pueden eliminar contenido generado por usuarios, sistemas de RRHH donde los agentes puedan procesar decisiones laborales y sistemas de cadena de suministro donde los agentes puedan realizar pedidos o ajustar inventario. El hilo común entre todas estas aplicaciones es que las acciones propuestas por el agente tienen consecuencias reales, y esas consecuencias son lo suficientemente significativas como para justificar una revisión humana antes de ejecutarse.
Comparación con Enfoques Alternativos
Vale la pena considerar cómo el middleware human-in-the-loop se compara con enfoques alternativos para añadir supervisión humana a los sistemas de agentes. Una alternativa es que las personas revisen todas las salidas del agente después de la ejecución, pero este enfoque tiene limitaciones importantes. Para cuando una persona revise una acción, ya se habrá ejecutado y revertirla podría ser difícil o imposible. Un correo ya ha sido enviado, un registro ya ha sido eliminado o una transacción financiera ya ha sido procesada. El middleware human-in-the-loop previene que estas acciones irreversibles ocurran en primer lugar.
Otra alternativa es que las personas realicen manualmente todas las tareas que los agentes podrían realizar, pero esto anula el propósito de tener agentes. Los agentes son valiosos precisamente porque pueden manejar tareas rutinarias de manera rápida y eficiente, liberando a las personas para que se concentren en la toma de decisiones de mayor nivel. El objetivo del middleware human-in-the-loop es encontrar el equilibrio adecuado: dejar que los agentes manejen el trabajo rutinario, pero pausar para revisión humana cuando hay mucho en juego.
Una tercera alternativa es implementar limitaciones o reglas de validación que eviten que los agentes tomen acciones inapropiadas. Por ejemplo, podrías implementar una regla que evite que un agente envíe correos a direcciones fuera de tu organización o elimine registros sin confirmación explícita. Aunque las limitaciones son valiosas y deben usarse en conjunto con el middleware human-in-the-loop, tienen limitaciones. Las limitaciones suelen ser basadas en reglas y no pueden contemplar todas las posibles acciones inapropiadas. Un agente puede pasar todas tus reglas y aun así proponer una acción inapropiada en un contexto específico. El juicio humano es más flexible y consciente del contexto que las reglas, por lo cual el middleware human-in-the-loop es tan valioso.
Mejores Prácticas para Implementar Flujos Human-in-the-Loop
Al implementar middleware human-in-the-loop en tus aplicaciones, varias mejores prácticas pueden ayudarte a asegurar que tu sistema sea tanto efectivo como eficiente. Primero, sé estratégico respecto a qué herramientas requieren interrupciones. Interrumpir cada llamada a herramienta creará cuellos de botella y ralentizará tu flujo. En cambio, enfoca las interrupciones en herramientas que sean costosas, riesgosas o tengan consecuencias significativas si se ejecutan incorrectamente. Las operaciones de solo lectura típicamente no necesitan interrupciones. Las operaciones de escritura que modifican datos o toman acciones externas sí suelen necesitarlas.
Segundo, proporciona contexto claro a los revisores humanos. Cuando ocurre una interrupción, la persona necesita entender qué acción está proponiendo el agente y por qué. Asegúrate de que las descripciones de la interrupción sean claras y brinden el contexto relevante. Si el agente propone enviar un correo, muestra el contenido completo. Si propone eliminar un registro, muestra qué registro será eliminado y el motivo. Cuanto más contexto brindes, más rápido y preciso será el proceso de decisión humano.
Tercero, haz que el proceso de aprobación sea lo más sencillo posible. Las personas aprobarán acciones más rápido si el proceso es simple y no requiere una navegación extensa ni introducción de datos. Proporciona botones claros u opciones para aprobar, editar y rechazar. Si se permite la edición, haz que sea fácil para los humanos modificar los parámetros relevantes sin necesidad de comprender el código o las estructuras de datos subyacentes.
Cuarto, usa la retroalimentación por rechazo de manera estratégica. Cuando rechaces una acción propuesta por el agente, proporciona una retroalimentación clara sobre por qué la acción era inapropiada y qué debería hacer el agente en su lugar. Esta retroalimentación ayuda al agente a aprender y mejorar su toma de decisiones. Con el tiempo, a medida que el agente recibe retroalimentación sobre sus propuestas, debería calibrarse mejor a los estándares y tolerancia al riesgo de tu organización.
Quinto, monitorea y analiza los patrones de interrupción. Lleva registro de qué herramientas son interrumpidas con mayor frecuencia, qué decisiones (aprobar, editar, rechazar) son más comunes y cuánto tarda el proceso de aprobación. Estos datos pueden ayudarte a identificar cuellos de botella, refinar tu configuración de interrupciones y, potencialmente, mejorar los prompts de tu agente o su lógica de selección de herramientas.
Integrando Middleware Human-in-the-Loop con FlowHunt
Para organizaciones que buscan implementar flujos human-in-the-loop a escala, FlowHunt ofrece una plataforma integral que se integra perfectamente con las capacidades de middleware de LangChain. FlowHunt te permite construir, desplegar y gestionar agentes de IA con flujos de aprobación integrados, facilitando la incorporación de supervisión humana a tus procesos de automatización. Con FlowHunt, puedes configurar qué herramientas requieren aprobación humana, personalizar la interfaz de aprobación según tus necesidades y rastrear todas las aprobaciones y rechazos para fines de cumplimiento y auditoría. La plataforma gestiona la complejidad de la gestión de estado, checkpointing y orquestación de flujos, permitiéndote enfocarte en construir agentes efectivos y definir políticas de aprobación adecuadas. La integración de FlowHunt con LangChain significa que puedes aprovechar todo el poder del middleware human-in-the-loop beneficiándote de una interfaz fácil de usar y confiabilidad de nivel empresarial.
Conclusión
El middleware human-in-the-loop representa un puente crucial entre la eficiencia de los agentes de IA autónomos y la necesidad de supervisión humana en sistemas de producción. Al implementar flujos de aprobación, capacidades de edición y mecanismos de retroalimentación por rechazo, puedes construir agentes que sean tanto poderosos como seguros. El modelo de decisión triple—aprobar, editar, rechazar—proporciona flexibilidad para manejar distintos tipos de necesidades de supervisión humana, desde operaciones de bajo riesgo que pueden aprobarse rápidamente hasta decisiones críticas que requieren consideración cuidadosa y modificaciones. La implementación es sencilla, requiriendo solo unas líneas de código adicionales a tus agentes LangChain existentes, pero el impacto en la confiabilidad y seguridad del sistema es sustancial. A medida que los agentes de IA se vuelvan más capaces y se desplieguen en procesos empresariales cada vez más críticos, el middleware human-in-the-loop será un componente esencial para un despliegue responsable de IA. Ya sea que estés construyendo asistentes de correo, sistemas financieros, aplicaciones de salud o cualquier otro dominio donde las acciones del agente tengan consecuencias reales, el middleware human-in-the-loop proporciona el marco necesario para asegurar que el juicio humano siga siendo central en tus flujos de automatización.
Preguntas frecuentes
El middleware human-in-the-loop es un componente que pausa la ejecución de un agente de IA antes de ejecutar herramientas específicas, permitiendo que una persona apruebe, edite o rechace la acción propuesta. Esto añade una capa de seguridad para operaciones costosas o riesgosas.
Úsalo para operaciones de alto riesgo como envío de correos electrónicos, transacciones financieras, escrituras en bases de datos o cualquier ejecución de herramienta que requiera supervisión de cumplimiento o que podría tener consecuencias significativas si se ejecuta incorrectamente.
Los tres tipos principales de respuesta son: Aprobación (ejecutar la herramienta tal como se propuso), Edición (modificar los parámetros de la herramienta antes de la ejecución) y Rechazo (rechazar la ejecución y enviar retroalimentación al modelo para su revisión).
Importa HumanInTheLoopMiddleware desde langchain.agents.middleware, configúralo con las herramientas en las que quieres interrumpir y pásalo a tu función de creación de agente. También necesitarás un checkpointer para mantener el estado a través de las interrupciones.
Arshia es ingeniera de flujos de trabajo de IA en FlowHunt. Con formación en ciencias de la computación y una pasión por la IA, se especializa en crear flujos de trabajo eficientes que integran herramientas de IA en las tareas cotidianas, mejorando la productividad y la creatividad.
Arshia Kahani
Ingeniera de flujos de trabajo de IA
Automatiza tus flujos de trabajo de IA de forma segura con FlowHunt
Construye agentes inteligentes con flujos de aprobación integrados y supervisión humana. FlowHunt facilita la implementación de automatizaciones human-in-the-loop para tus procesos de negocio.
Cómo construir agentes de IA extensibles: Un análisis profundo de la arquitectura de middleware
Descubre cómo la arquitectura de middleware de LangChain 1.0 revoluciona el desarrollo de agentes, permitiendo a los desarrolladores crear agentes profundos y p...
Snowglobe: Simulaciones para tu IA – Prueba y Validación de Agentes de IA Antes de Producción
Descubre cómo el motor de simulación de Snowglobe te ayuda a probar agentes de IA, chatbots y sistemas generativos de IA antes de producción, simulando interacc...
Por qué los mejores ingenieros están abandonando los servidores MCP: 3 alternativas probadas para agentes de IA eficientes
Descubre por qué los ingenieros líderes están dejando atrás los servidores MCP y explora tres alternativas probadas: enfoques basados en CLI, herramientas basad...
21 min de lectura
AI Agents
MCP
+3
Consentimiento de Cookies Usamos cookies para mejorar tu experiencia de navegación y analizar nuestro tráfico. See our privacy policy.