Cómo Probar un Chatbot de IA
Aprende estrategias completas para probar chatbots de IA, incluyendo pruebas funcionales, de rendimiento, seguridad y usabilidad. Descubre mejores prácticas, he...
14 min de lectura
Aprende métodos integrales para medir la precisión de chatbots de asistencia de IA en 2025. Descubre métricas de precisión, recall, puntuaciones F1, métricas de satisfacción del usuario y técnicas avanzadas de evaluación con FlowHunt.
Mide la precisión de un chatbot de asistencia de IA utilizando múltiples métricas, incluidas los cálculos de precisión y recall, matrices de confusión, puntuaciones de satisfacción del usuario, tasas de resolución y métodos avanzados de evaluación basados en LLM. FlowHunt ofrece herramientas completas para la evaluación automática de la precisión y el monitoreo del rendimiento.
Medir la precisión de un chatbot de asistencia de IA es esencial para asegurar que brinde respuestas fiables y útiles a las consultas de los clientes. A diferencia de tareas simples de clasificación, la precisión del chatbot abarca múltiples dimensiones que deben evaluarse en conjunto para proporcionar una visión completa del rendimiento. El proceso implica analizar qué tan bien el chatbot comprende las consultas del usuario, proporciona información correcta, resuelve problemas de manera efectiva y mantiene la satisfacción del usuario a lo largo de las interacciones. Una estrategia integral de medición de precisión combina métricas cuantitativas con retroalimentación cualitativa para identificar fortalezas y áreas que requieren mejora.
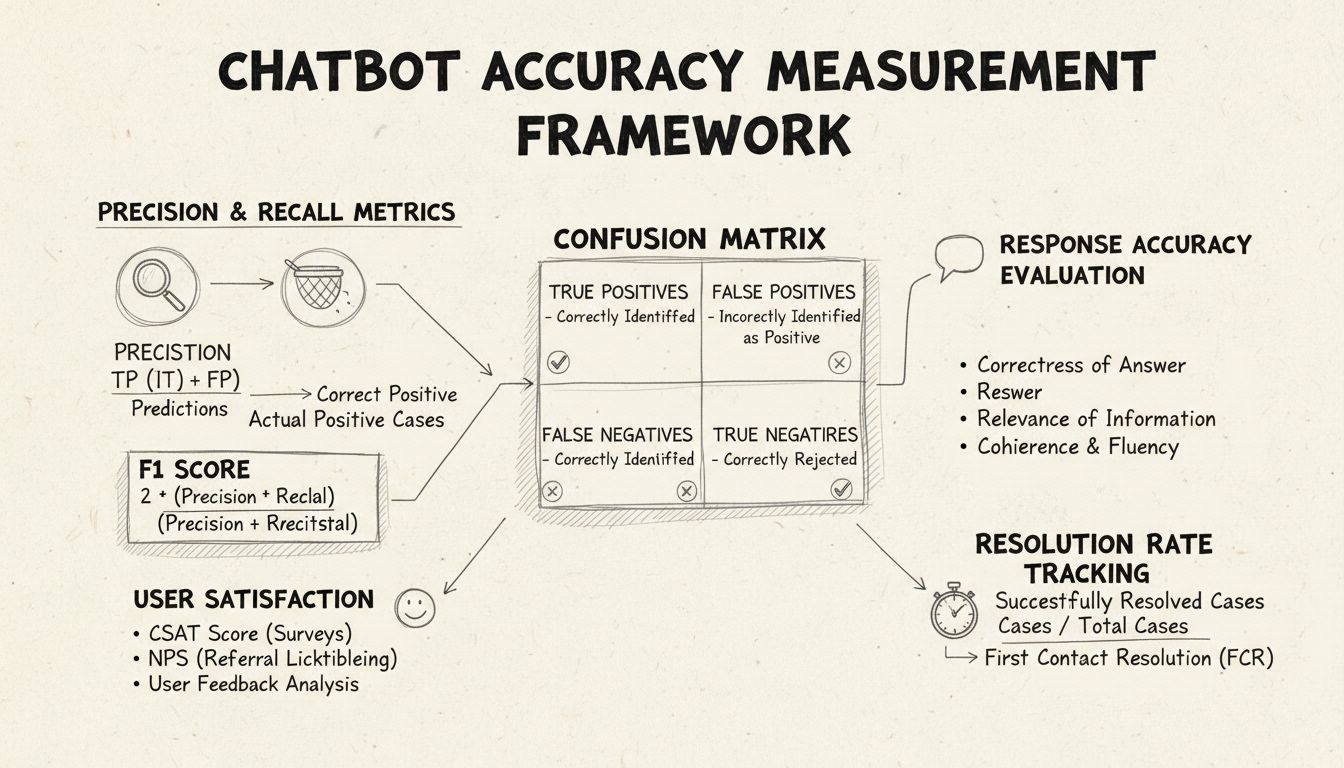
La precisión y el recall son métricas fundamentales derivadas de la matriz de confusión que miden distintos aspectos del rendimiento del chatbot. La precisión representa la proporción de respuestas correctas de todas las respuestas proporcionadas por el chatbot, calculada con la fórmula: Precisión = Verdaderos Positivos / (Verdaderos Positivos + Falsos Positivos). Esta métrica responde a la pregunta: “Cuando el chatbot da una respuesta, ¿con qué frecuencia es correcta?” Una alta puntuación de precisión indica que el chatbot rara vez da información incorrecta, lo cual es fundamental para mantener la confianza del usuario en escenarios de asistencia.
El recall, también conocido como sensibilidad, mide la proporción de respuestas correctas de todas las respuestas correctas que el chatbot debería haber dado, usando la fórmula: Recall = Verdaderos Positivos / (Verdaderos Positivos + Falsos Negativos). Esta métrica aborda si el chatbot identifica y responde exitosamente a todos los problemas legítimos del cliente. En contextos de asistencia, un alto recall asegura que los clientes reciban ayuda para sus problemas en lugar de que el chatbot diga que no puede ayudar cuando en realidad sí podría. La relación entre precisión y recall crea una compensación natural: optimizar una suele reducir la otra, requiriendo un balance cuidadoso según tus prioridades empresariales específicas.
La puntuación F1 proporciona una métrica única que equilibra tanto la precisión como el recall, calculada como la media armónica: F1 = 2 × (Precisión × Recall) / (Precisión + Recall). Esta métrica resulta especialmente valiosa cuando necesitas un indicador de rendimiento unificado o cuando se trata de conjuntos de datos desbalanceados donde una clase supera significativamente a otras. Por ejemplo, si tu chatbot gestiona 1,000 consultas rutinarias pero solo 50 escalaciones complejas, la puntuación F1 evita que la métrica se vea sesgada por la clase mayoritaria. La puntuación F1 oscila entre 0 y 1, siendo 1 la representación de precisión y recall perfectos, lo que la hace intuitiva para que las partes interesadas comprendan el rendimiento general del chatbot de un vistazo.
La matriz de confusión es una herramienta fundamental que desglosa el rendimiento del chatbot en cuatro categorías: Verdaderos Positivos (respuestas correctas a consultas válidas), Verdaderos Negativos (rechazar correctamente responder preguntas fuera de alcance), Falsos Positivos (respuestas incorrectas) y Falsos Negativos (oportunidades perdidas de ayudar). Esta matriz revela patrones específicos en los fallos del chatbot, permitiendo mejoras dirigidas. Por ejemplo, si la matriz muestra muchos falsos negativos en consultas de facturación, puedes identificar que los datos de entrenamiento del chatbot carecen de suficientes ejemplos relacionados con facturación y necesitan mejoras en ese ámbito.
| Métrica | Definición | Cálculo | Impacto en el negocio |
|---|---|---|---|
| Verdaderos Positivos (VP) | Respuestas correctas a consultas válidas | Contados directamente | Genera confianza del cliente |
| Verdaderos Negativos (VN) | Rechazo correcto a preguntas fuera de alcance | Contados directamente | Previene desinformación |
| Falsos Positivos (FP) | Respuestas incorrectas proporcionadas | Contados directamente | Daña la credibilidad |
| Falsos Negativos (FN) | Oportunidades perdidas de ayudar | Contados directamente | Reduce la satisfacción |
| Precisión | Calidad de las predicciones positivas | VP / (VP + FP) | Métrica de fiabilidad |
| Recall | Cobertura de positivos reales | VP / (VP + FN) | Métrica de completitud |
| Exactitud | Corrección general | (VP + VN) / Total | Rendimiento general |
La precisión de la respuesta mide la frecuencia con la que el chatbot proporciona información fácticamente correcta que responde directamente a la consulta del usuario. Esto va más allá de la simple coincidencia de patrones para evaluar si el contenido es exacto, actual y apropiado para el contexto. Los procesos de revisión manual implican que evaluadores humanos revisen una muestra aleatoria de conversaciones, comparando las respuestas del chatbot con una base de conocimiento predefinida de respuestas correctas. Los métodos de comparación automatizada pueden implementarse utilizando técnicas de procesamiento de lenguaje natural para comparar las respuestas con las respuestas esperadas almacenadas en tu sistema, aunque estos requieren una calibración cuidadosa para evitar falsos negativos cuando el chatbot da información correcta usando un lenguaje diferente al de la respuesta de referencia.
La relevancia de la respuesta evalúa si la respuesta del chatbot realmente aborda la pregunta del usuario, incluso si la respuesta no es perfectamente correcta. Esta dimensión captura situaciones en las que el chatbot proporciona información útil que, aunque no sea la respuesta exacta, avanza la conversación hacia la resolución. Métodos basados en PLN como la similitud coseno pueden medir la similitud semántica entre la pregunta del usuario y la respuesta del chatbot, proporcionando una puntuación de relevancia automatizada. Los mecanismos de retroalimentación del usuario, como calificaciones de pulgar arriba/abajo después de cada interacción, ofrecen una evaluación directa de relevancia por parte de quienes más importan: tus clientes. Estas señales deben ser recolectadas y analizadas continuamente para identificar patrones en los tipos de consultas que el chatbot gestiona bien frente a las que maneja mal.
La Puntuación de Satisfacción del Cliente (CSAT) mide la satisfacción del usuario con las interacciones del chatbot a través de encuestas directas, normalmente utilizando una escala del 1 al 5 o calificaciones simples de satisfacción. Después de cada interacción, se pide a los usuarios que califiquen su satisfacción, proporcionando retroalimentación inmediata sobre si el chatbot cumplió con sus necesidades. Puntuaciones CSAT por encima del 80% generalmente indican un buen rendimiento, mientras que puntuaciones por debajo del 60% señalan problemas significativos que requieren investigación. La ventaja de CSAT es su simplicidad y claridad: los usuarios indican explícitamente si están satisfechos, pero puede verse influido por factores más allá de la precisión del chatbot, como la complejidad del problema o las expectativas del usuario.
El Net Promoter Score mide la probabilidad de que los usuarios recomienden el chatbot a otros, calculado preguntando “¿Qué probabilidad hay de que recomiendes este chatbot a un colega?” en una escala del 0 al 10. Los encuestados que califican 9-10 son promotores, 7-8 son pasivos y 0-6 son detractores. NPS = (Promotores - Detractores) / Total de encuestados × 100. Esta métrica se correlaciona fuertemente con la lealtad a largo plazo del cliente y proporciona una visión sobre si el chatbot genera experiencias positivas que los usuarios desean compartir. Un NPS superior a 50 se considera excelente, mientras que un NPS negativo indica problemas graves de rendimiento.
El análisis de sentimiento examina el tono emocional de los mensajes de los usuarios antes y después de las interacciones con el chatbot para medir la satisfacción. Técnicas avanzadas de PLN clasifican los mensajes como positivos, neutros o negativos, revelando si los usuarios quedan más satisfechos o frustrados durante las conversaciones. Un cambio de sentimiento positivo indica que el chatbot resolvió con éxito las inquietudes, mientras que cambios negativos sugieren que el chatbot pudo haber frustrado a los usuarios o no haber cubierto sus necesidades. Esta métrica captura dimensiones emocionales que las métricas tradicionales de precisión no detectan, proporcionando un contexto valioso para entender la calidad de la experiencia del usuario.
La Resolución en el Primer Contacto mide el porcentaje de problemas de clientes resueltos por el chatbot sin requerir escalamiento a agentes humanos. Esta métrica impacta directamente la eficiencia operativa y la satisfacción del cliente, ya que los clientes prefieren resolver sus problemas de inmediato en lugar de ser transferidos. Tasas de FCR por encima del 70% indican un buen rendimiento del chatbot, mientras que tasas por debajo del 50% sugieren que el chatbot carece de conocimiento o capacidad suficiente para gestionar consultas comunes. El seguimiento del FCR por categoría de problema revela qué tipos de problemas el chatbot gestiona bien y cuáles requieren intervención humana, guiando mejoras en el entrenamiento y la base de conocimiento.
La tasa de escalamiento mide con qué frecuencia el chatbot transfiere conversaciones a agentes humanos, mientras que la frecuencia de fallback rastrea con qué frecuencia el chatbot recurre a respuestas genéricas como “No entiendo” o “Por favor, reformula tu pregunta”. Tasas de escalamiento altas (superiores al 30%) indican que el chatbot carece de conocimiento o confianza en muchos escenarios, mientras que tasas altas de fallback sugieren un mal reconocimiento de intenciones o datos de entrenamiento insuficientes. Estas métricas identifican vacíos específicos en las capacidades del chatbot que pueden resolverse mediante la expansión de la base de conocimiento, el reentrenamiento del modelo o la mejora de los componentes de comprensión del lenguaje natural.
El tiempo de respuesta mide cuán rápido responde el chatbot a los mensajes del usuario, normalmente medido en milisegundos a segundos. Los usuarios esperan respuestas casi instantáneas; retrasos superiores a 3-5 segundos afectan significativamente la satisfacción. El tiempo de gestión mide la duración total desde que el usuario inicia el contacto hasta que el problema se resuelve o se escala, ofreciendo una visión sobre la eficiencia del chatbot. Tiempos de gestión más cortos indican que el chatbot comprende y resuelve rápidamente los problemas, mientras que tiempos más largos sugieren que el chatbot requiere varias rondas de aclaración o tiene dificultades con consultas complejas. Estas métricas deben seguirse por separado para diferentes categorías de problemas, ya que los problemas técnicos complejos requieren naturalmente más tiempo que preguntas frecuentes sencillas.
LLM As a Judge representa un enfoque sofisticado de evaluación donde un modelo de lenguaje grande evalúa la calidad de las respuestas de otro sistema de IA. Esta metodología resulta especialmente eficaz para evaluar las respuestas del chatbot en múltiples dimensiones de calidad simultáneamente, como precisión, relevancia, coherencia, fluidez, seguridad, completitud y tono. Las investigaciones demuestran que los jueces LLM pueden alcanzar hasta un 85% de alineación con evaluaciones humanas, lo que los convierte en una alternativa escalable a la revisión manual. El enfoque implica definir criterios de evaluación específicos, crear prompts de juez detallados con ejemplos, proporcionar al juez tanto la consulta original del usuario como la respuesta del chatbot, y recibir puntuaciones estructuradas o retroalimentación detallada.
El proceso LLM As a Judge emplea típicamente dos enfoques de evaluación: evaluación de salida única, donde el juez califica una respuesta individual usando evaluación sin referencia (sin respuesta esperada) o comparación basada en referencia (contra una respuesta esperada), y comparación por pares, donde el juez compara dos respuestas para identificar la superior. Esta flexibilidad permite evaluar tanto el rendimiento absoluto como mejoras relativas al probar diferentes versiones o configuraciones del chatbot. La plataforma de FlowHunt soporta implementaciones de LLM As a Judge a través de su interfaz visual de arrastrar y soltar, integración con LLM líderes como ChatGPT y Claude, y herramientas CLI para informes avanzados y evaluaciones automáticas.
Más allá de los cálculos básicos de precisión, el análisis detallado de la matriz de confusión revela patrones específicos en los fallos del chatbot. Al examinar qué tipos de consultas producen falsos positivos frente a falsos negativos, puedes identificar debilidades sistemáticas. Por ejemplo, si la matriz muestra que el chatbot clasifica con frecuencia preguntas de facturación como problemas de soporte técnico, esto revela un desbalance en los datos de entrenamiento o un problema de reconocimiento de intenciones específico del área de facturación. Crear matrices de confusión separadas para diferentes categorías de problemas permite mejoras dirigidas en lugar de un reentrenamiento genérico del modelo.
Las pruebas A/B comparan diferentes versiones del chatbot para determinar cuál rinde mejor en métricas clave. Esto puede implicar probar diferentes plantillas de respuesta, configuraciones de base de conocimiento o modelos de lenguaje subyacentes. Al dirigir aleatoriamente una parte del tráfico a cada versión y comparar métricas como la tasa de FCR, puntuaciones CSAT y precisión de respuesta, puedes tomar decisiones basadas en datos sobre qué mejoras implementar. Las pruebas A/B deben ejecutarse el tiempo suficiente para capturar la variación natural en las consultas de los usuarios y asegurar la significancia estadística de los resultados.
FlowHunt proporciona una plataforma integrada para construir, desplegar y evaluar chatbots de asistencia de IA con avanzadas capacidades de medición de precisión. El constructor visual de la plataforma permite a usuarios no técnicos crear flujos de chatbot sofisticados, mientras que sus componentes de IA se integran con modelos líderes como ChatGPT y Claude. El conjunto de herramientas de evaluación de FlowHunt soporta la implementación de la metodología LLM As a Judge, permitiéndote definir criterios de evaluación personalizados y evaluar automáticamente el rendimiento del chatbot en todo tu conjunto de conversaciones.
Para implementar una medición integral de precisión con FlowHunt, comienza definiendo tus criterios de evaluación específicos alineados con los objetivos del negocio—ya sea priorizando precisión, velocidad, satisfacción del usuario o tasas de resolución. Configura el LLM juez de la plataforma con prompts detallados que especifiquen cómo evaluar las respuestas, incluyendo ejemplos concretos de respuestas de alta y baja calidad. Sube tu conjunto de conversaciones o conecta tráfico en vivo, luego ejecuta evaluaciones para generar informes detallados que muestren el rendimiento en todas las métricas. El panel de FlowHunt ofrece visibilidad en tiempo real sobre el rendimiento del chatbot, permitiendo una rápida identificación de problemas y validación de mejoras.
Establece una medición de referencia antes de implementar mejoras, creando un punto de comparación para evaluar el impacto de los cambios. Recoge las mediciones de manera continua en lugar de periódica, permitiendo la detección temprana de degradación del rendimiento debido a deriva de datos o deterioro del modelo. Implementa bucles de retroalimentación donde las calificaciones y correcciones de los usuarios se integren automáticamente en el proceso de entrenamiento, mejorando continuamente la precisión del chatbot. Segmenta las métricas por categoría de problema, tipo de usuario y periodo de tiempo para identificar áreas específicas que requieran atención en lugar de basarte únicamente en estadísticas agregadas.
Asegúrate de que tu conjunto de evaluación represente consultas y respuestas reales de usuarios, evitando casos de prueba artificiales que no reflejan patrones de uso reales. Valida regularmente las métricas automatizadas contra el juicio humano haciendo que evaluadores revisen manualmente una muestra de conversaciones, asegurando que tu sistema de medición permanezca calibrado a la calidad real. Documenta claramente tu metodología de medición y definiciones de métricas, permitiendo una evaluación consistente a lo largo del tiempo y una comunicación clara de los resultados a las partes interesadas. Finalmente, establece objetivos de rendimiento para cada métrica alineados con los objetivos del negocio, creando responsabilidad para la mejora continua y proporcionando metas claras para los esfuerzos de optimización.
La avanzada plataforma de automatización de IA de FlowHunt te ayuda a crear, desplegar y evaluar chatbots de asistencia de alto rendimiento con herramientas integradas de medición de precisión y capacidades de evaluación basadas en LLM.
Aprende estrategias completas para probar chatbots de IA, incluyendo pruebas funcionales, de rendimiento, seguridad y usabilidad. Descubre mejores prácticas, he...
Domina el uso de chatbots de IA con nuestra guía integral. Aprende técnicas de prompting efectivas, mejores prácticas y cómo sacar el máximo provecho a los chat...
Aprende métodos comprobados para verificar la autenticidad de chatbots de IA en 2025. Descubre técnicas de verificación técnica, controles de seguridad y mejore...
Consentimiento de Cookies
Usamos cookies para mejorar tu experiencia de navegación y analizar nuestro tráfico. See our privacy policy.