IA Generativa (Gen AI)
La IA generativa se refiere a una categoría de algoritmos de inteligencia artificial que pueden generar contenido nuevo, como texto, imágenes, música, código y ...
2 min de lectura
AI
Generative AI
+3
Las GAN son marcos de aprendizaje automático con dos redes neuronales en competencia, utilizadas para generar nuevos datos realistas y ampliamente aplicadas en IA, síntesis de imágenes y ampliación de datos.
Una Red Generativa Antagónica (GAN) es una clase de marcos de aprendizaje automático diseñados para generar nuevas muestras de datos que imitan un conjunto de datos dado. Introducidas por Ian Goodfellow y sus colegas en 2014, las GAN constan de dos redes neuronales, un generador y un discriminador, que se enfrentan entre sí en un marco de suma cero. El generador crea muestras de datos, mientras que el discriminador las evalúa, distinguiendo entre datos reales y falsos. Con el tiempo, el generador mejora su capacidad para producir datos que se asemejan a los reales, mientras que el discriminador se vuelve más hábil en detectar datos falsos.
La conceptualización de las GAN marcó un avance significativo en el modelado generativo. Antes de las GAN, los modelos generativos como los autoencoders variacionales (VAE) y las máquinas de Boltzmann restringidas eran predominantes pero carecían de la robustez y versatilidad que ofrecen las GAN. Desde su introducción, las GAN han ganado popularidad rápidamente debido a su capacidad para producir datos de alta calidad en diversos dominios, incluyendo imágenes, audio y texto.
El generador es una red neuronal convolucional (CNN) que produce nuevas instancias de datos, intentando imitar la distribución real de datos. Comienza a partir de ruido aleatorio y aprende progresivamente a generar datos que puedan engañar al discriminador para clasificarlos como reales. El objetivo del generador es capturar la distribución subyacente de los datos y generar puntos de datos plausibles a partir de ella.
El discriminador es una red neuronal deconvolucional (DNN) que evalúa las instancias de datos como genuinas o fabricadas. Su función es actuar como un clasificador binario para distinguir entre datos reales del conjunto de entrenamiento y los datos falsos producidos por el generador. La retroalimentación del discriminador es crucial para el proceso de aprendizaje del generador, ya que guía al generador para mejorar su salida.
El aspecto antagónico de las GAN proviene de la naturaleza competitiva del proceso de entrenamiento. Las dos redes, generador y discriminador, se entrenan simultáneamente de modo que el generador intenta maximizar la probabilidad de que el discriminador cometa un error, mientras que el discriminador se esfuerza por minimizar esta probabilidad. Esta dinámica crea un ciclo de retroalimentación donde ambas redes mejoran con el tiempo, impulsándose mutuamente hacia un rendimiento óptimo.
La forma más sencilla de GAN, que utiliza perceptrones multicapa básicos tanto para el generador como para el discriminador. Se centra en optimizar la función de pérdida usando descenso de gradiente estocástico. La Vanilla GAN sirve como arquitectura base sobre la que se construyen variantes más avanzadas de GAN.
Incorpora información adicional, como etiquetas de clase, para condicionar el proceso de generación de datos. Esto permite que el generador produzca datos que cumplan criterios específicos. Las CGAN son especialmente útiles en escenarios donde se desea controlar la generación de datos, como generar imágenes de una categoría específica.
Aprovecha la capacidad de las redes neuronales convolucionales para procesar datos de imagen. Las DCGAN son especialmente efectivas para tareas de generación de imágenes y se han convertido en estándar en el campo debido a su capacidad para producir imágenes de alta calidad.
Se especializa en tareas de traducción de imagen a imagen. Aprende a traducir imágenes de un dominio a otro sin ejemplos emparejados, como transformar imágenes de caballos en cebras o convertir fotos en pinturas. Las CycleGAN se utilizan ampliamente en transferencia de estilo artístico y tareas de adaptación de dominios.
Se centra en mejorar la resolución de las imágenes, generando imágenes detalladas y de alta calidad a partir de entradas de baja resolución. Las SRGAN se emplean en aplicaciones donde la claridad y el detalle de la imagen son críticos, como en imágenes médicas y satelitales.
Utiliza un marco de pirámide Laplaciana multinivel para generar imágenes de alta resolución, descomponiendo el problema en etapas más simples. Las LAPGAN están diseñadas para abordar tareas complejas de generación de imágenes descomponiendo la imagen en diferentes componentes de frecuencia.
Las GAN pueden crear imágenes altamente realistas a partir de indicaciones de texto o modificando imágenes existentes. Se usan extensamente en campos como el entretenimiento digital y el diseño de videojuegos para crear personajes y entornos realistas. También se han empleado en la industria de la moda para diseñar nuevos patrones y estilos de ropa.
En aprendizaje automático, las GAN se utilizan para ampliar conjuntos de datos de entrenamiento, produciendo datos sintéticos que conservan las propiedades estadísticas de los datos reales. Esto es especialmente útil en escenarios donde la obtención de grandes conjuntos de datos es difícil, como en la investigación médica donde los datos de pacientes son limitados.
Las GAN pueden entrenarse para identificar anomalías aprendiendo la distribución subyacente de los datos normales. Esto las hace valiosas para detectar actividades fraudulentas o defectos en procesos de fabricación. Las GAN para detección de anomalías también se usan en ciberseguridad para identificar patrones inusuales de tráfico de red.
Las GAN pueden generar imágenes basadas en descripciones textuales, facilitando aplicaciones en diseño, marketing y creación de contenido. Esta capacidad es especialmente valiosa en publicidad, donde se necesitan elementos visuales personalizados para adaptarse a temas específicos de campañas.
A partir de imágenes 2D, las GAN pueden generar modelos 3D, ayudando a campos como la salud para simulaciones quirúrgicas o la arquitectura para visualizaciones de diseño. Esta aplicación de las GAN está transformando industrias al proporcionar experiencias más inmersivas e interactivas.
En el ámbito de la automatización de IA y los chatbots, las GAN pueden aprovecharse para crear datos conversacionales sintéticos para fines de entrenamiento, mejorando la capacidad de los chatbots para comprender y generar respuestas similares a las humanas. También pueden utilizarse para desarrollar avatares realistas o asistentes virtuales que interactúan con los usuarios de manera más atractiva y auténtica.
Al evolucionar continuamente mediante el entrenamiento antagónico, las GAN representan un avance significativo en el modelado generativo, abriendo nuevas posibilidades para la automatización, la creatividad y las aplicaciones de aprendizaje automático en diversas industrias. A medida que las GAN continúan evolucionando, se espera que desempeñen un papel cada vez más crítico en la configuración del futuro de la inteligencia artificial y sus aplicaciones.
Las Redes Generativas Antagónicas (GAN) son una clase de marcos de aprendizaje automático diseñados para generar nuevas muestras de datos que imitan un conjunto de datos dado. Fueron introducidas por Ian Goodfellow y su equipo en 2014 y desde entonces se han convertido en una herramienta fundamental en el campo de la inteligencia artificial, especialmente en la generación de imágenes, síntesis de video y más. Las GAN constan de dos redes neuronales, el generador y el discriminador, que se entrenan simultáneamente mediante un proceso de aprendizaje antagónico.
Adversarial symmetric GANs: bridging adversarial samples and adversarial networks de Faqiang Liu et al., investiga la inestabilidad en el entrenamiento de las GAN. Los autores proponen las Adversarial Symmetric GANs (AS-GANs), que incorporan el entrenamiento antagónico del discriminador sobre muestras reales, un componente habitualmente pasado por alto. Esta metodología aborda la vulnerabilidad de los discriminadores a perturbaciones adversarias, mejorando así la capacidad del generador para imitar muestras reales. Este artículo contribuye a la comprensión de la dinámica de entrenamiento de las GAN y propone soluciones para mejorar su estabilidad.
En el artículo titulado “Improved Network Robustness with Adversary Critic” de Alexander Matyasko y Lap-Pui Chau, los autores proponen un enfoque novedoso para mejorar la robustez de las redes neuronales utilizando GAN. Abordan el problema donde pequeñas perturbaciones imperceptibles pueden alterar las predicciones de la red, asegurando que los ejemplos adversarios sean indistinguibles de los datos regulares. Su enfoque implica una restricción de ciclo de consistencia adversaria para mejorar la estabilidad de los mapeos adversarios, mostrando su efectividad a través de experimentos. El estudio destaca el potencial de las GAN para mejorar la robustez de los clasificadores frente a ataques adversarios.
Leer más
El artículo “Language Guided Adversarial Purification” de Himanshu Singh y A V Subramanyam explora la purificación adversaria empleando modelos generativos. Los autores introducen Language Guided Adversarial Purification (LGAP), un marco que emplea modelos de difusión preentrenados y generadores de subtítulos para defenderse de ataques adversarios. Este método mejora la robustez adversaria sin necesidad de un entrenamiento especializado de la red, demostrando ser más efectivo que muchas técnicas de defensa adversaria existentes. El estudio muestra la versatilidad y eficiencia de las GAN para mejorar la seguridad de las redes.
Una GAN es un marco de aprendizaje automático con dos redes neuronales—un generador y un discriminador—que compiten para crear muestras de datos indistinguibles de los datos reales, permitiendo la generación realista de datos.
Las GAN se utilizan en la generación de imágenes, ampliación de datos, detección de anomalías, síntesis de texto a imagen y creación de modelos 3D, entre otros campos.
Las GAN fueron introducidas por Ian Goodfellow y sus colegas en 2014.
El entrenamiento de las GAN puede ser inestable debido al delicado equilibrio entre el generador y el discriminador, enfrentando a menudo problemas como el colapso de modo, grandes requerimientos de datos y dificultades de convergencia.
Los tipos comunes incluyen Vanilla GAN, Conditional GAN (CGAN), Deep Convolutional GAN (DCGAN), CycleGAN, Super-resolution GAN (SRGAN) y Laplacian Pyramid GAN (LAPGAN).
Chatbots inteligentes y herramientas de IA bajo un mismo techo. Conecta bloques intuitivos para convertir tus ideas en Flujos automatizados.
La IA generativa se refiere a una categoría de algoritmos de inteligencia artificial que pueden generar contenido nuevo, como texto, imágenes, música, código y ...
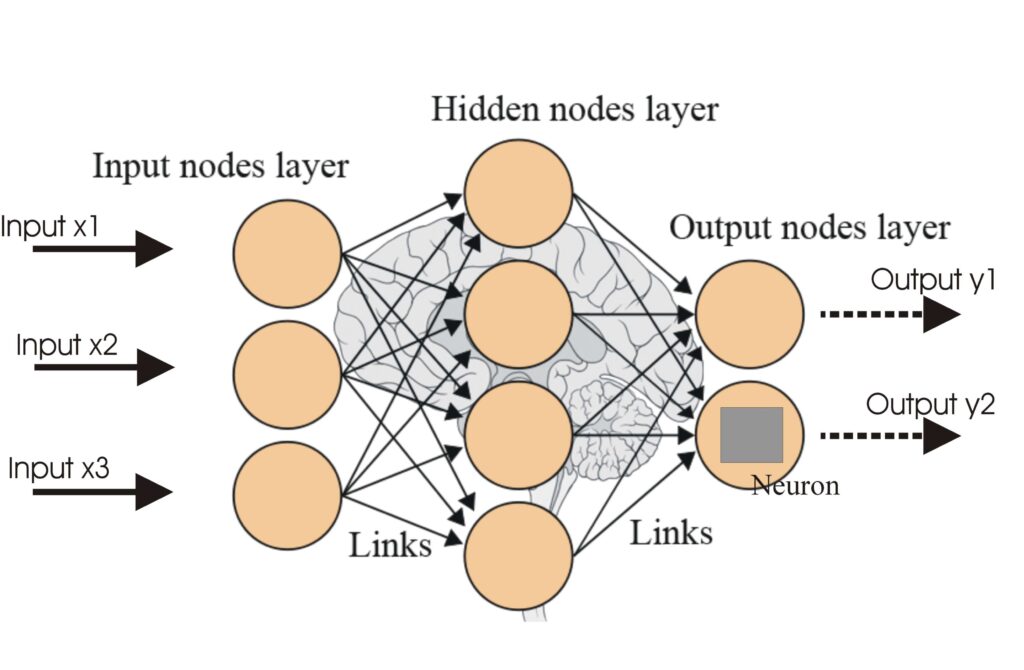
Las Redes Neuronales Artificiales (ANNs) son un subconjunto de algoritmos de aprendizaje automático modelados a partir del cerebro humano. Estos modelos computa...
Una red neuronal, o red neuronal artificial (ANN), es un modelo computacional inspirado en el cerebro humano, esencial en la IA y el aprendizaje automático para...
Consentimiento de Cookies
Usamos cookies para mejorar tu experiencia de navegación y analizar nuestro tráfico. See our privacy policy.