
Servidor Unity Catalog MCP
El Servidor Unity Catalog MCP permite a asistentes de IA y desarrolladores gestionar, descubrir y manipular funciones de Unity Catalog de forma programática med...
5 min de lectura
AI
MCP
+5

Conecta agentes de IA con Databricks sin complicaciones para exploración autónoma de metadatos, ejecución de consultas SQL y automatización avanzada de datos usando el Servidor MCP de Databricks.
FlowHunt proporciona una capa de seguridad adicional entre tus sistemas internos y las herramientas de IA, dándote control granular sobre qué herramientas son accesibles desde tus servidores MCP. Los servidores MCP alojados en nuestra infraestructura pueden integrarse perfectamente con el chatbot de FlowHunt, así como con plataformas de IA populares como ChatGPT, Claude y varios editores de IA.
El Servidor MCP de Databricks actúa como un servidor Model Context Protocol (MCP) que conecta asistentes de IA directamente con entornos Databricks, con un enfoque específico en aprovechar los metadatos de Unity Catalog (UC). Su función principal es permitir que los agentes de IA accedan, comprendan e interactúen de manera autónoma con los activos de datos de Databricks. El servidor proporciona herramientas que permiten a los agentes explorar los metadatos de UC, comprender las estructuras de datos y ejecutar consultas SQL. Esto capacita a los agentes de IA para responder preguntas relacionadas con los datos, realizar consultas a bases de datos y cumplir solicitudes de datos complejas de forma independiente, sin requerir intervención manual en cada paso. Al hacer que los metadatos detallados sean accesibles y procesables, el Servidor MCP de Databricks mejora los flujos de trabajo de desarrollo impulsados por IA y facilita la exploración y gestión inteligente de datos en Databricks.
No se mencionan plantillas de prompts específicas en el repositorio ni en la documentación.
Comienza tu prueba gratuita hoy y ve resultados en días.
No se proporciona una lista explícita de recursos MCP en el repositorio ni en la documentación.
La documentación describe las siguientes herramientas y funciones disponibles:
Obtén los últimos consejos, tendencias y ofertas gratis.
No se proporcionan instrucciones de configuración específicas ni fragmentos JSON para Windsurf.
No se proporcionan instrucciones de configuración específicas ni fragmentos JSON para Claude.
El repositorio menciona integración con Cursor:
requirements.txt.mcpServers:{
"databricks-mcp": {
"command": "python",
"args": ["main.py"]
}
}
Asegura las claves API usando variables de entorno (ejemplo):
{
"databricks-mcp": {
"command": "python",
"args": ["main.py"],
"env": {
"DATABRICKS_TOKEN": "TU_API_KEY"
}
}
}
No se proporcionan instrucciones de configuración específicas ni fragmentos JSON para Cline.
Uso de MCP en FlowHunt
Para integrar servidores MCP en tu flujo de trabajo de FlowHunt, comienza agregando el componente MCP a tu flujo y conectándolo a tu agente de IA:

Haz clic en el componente MCP para abrir el panel de configuración. En la sección de configuración MCP del sistema, inserta los detalles de tu servidor MCP usando este formato JSON:
{
"databricks-mcp": {
"transport": "streamable_http",
"url": "https://yourmcpserver.example/pathtothemcp/url"
}
}
Una vez configurado, el agente de IA podrá usar este MCP como herramienta con acceso a todas sus funciones y capacidades. Recuerda cambiar “databricks-mcp” por el nombre real de tu servidor MCP y reemplazar la URL por la de tu propio servidor MCP.
| Sección | Disponibilidad | Detalles/Notas |
|---|---|---|
| Resumen | ✅ | Buena síntesis y motivación disponible |
| Lista de Prompts | ⛔ | No se encontraron plantillas de prompts |
| Lista de Recursos | ⛔ | No se listan recursos MCP explícitos |
| Lista de Herramientas | ✅ | Herramientas de alto nivel descritas en la documentación |
| Protección de Claves API | ✅ | Ejemplo con "env" provisto en la sección de Cursor |
| Soporte para muestreo (menos relevante) | ⛔ | No mencionado |
Según la documentación disponible, el Servidor MCP de Databricks está bien enfocado para la integración Databricks/UC y flujos de trabajo de IA de tipo agente, pero carece de plantillas de prompts explícitas, listas de recursos y menciones de funciones de raíces o muestreo. Su configuración y descripción de herramientas son claras para Cursor, pero menos para otras plataformas.
El servidor MCP es enfocado y útil para la automatización IA + Databricks, pero se beneficiaría de una documentación más explícita sobre prompts, recursos y configuración multiplataforma. Para quienes buscan integración con Databricks/UC, es una solución sólida y práctica.
| ¿Tiene una LICENSE? | ✅ (MIT) |
|---|---|
| ¿Tiene al menos una herramienta? | ✅ |
| Número de Forks | 5 |
| Número de Estrellas | 11 |
El Servidor MCP de Databricks es un servidor Model Context Protocol que conecta agentes de IA con entornos Databricks, permitiéndoles acceder de forma autónoma a los metadatos de Unity Catalog, comprender estructuras de datos y ejecutar consultas SQL para exploración y automatización avanzada de datos.
Permite a los agentes de IA explorar los metadatos de Unity Catalog, comprender estructuras de datos, ejecutar consultas SQL y operar en modos autónomos de agente para tareas de datos en varios pasos.
Los casos de uso típicos incluyen descubrimiento de metadatos, construcción automatizada de consultas SQL, asistencia en documentación de datos, exploración inteligente de datos y automatización de tareas complejas dentro de Databricks.
Debes usar variables de entorno para información sensible. En la configuración de tu servidor MCP, establece `DATABRICKS_TOKEN` como variable de entorno en lugar de codificarla directamente.
Agrega el componente MCP a tu flujo en FlowHunt, configúralo con los detalles de tu servidor y conéctalo a tu agente de IA. Usa el formato JSON provisto en la sección de configuración MCP del sistema para especificar la conexión de tu servidor MCP de Databricks.
Permite que tus flujos de trabajo de IA interactúen directamente con los metadatos de Databricks Unity Catalog y automaticen tareas de datos. Pruébalo con FlowHunt hoy.
El Servidor Unity Catalog MCP permite a asistentes de IA y desarrolladores gestionar, descubrir y manipular funciones de Unity Catalog de forma programática med...
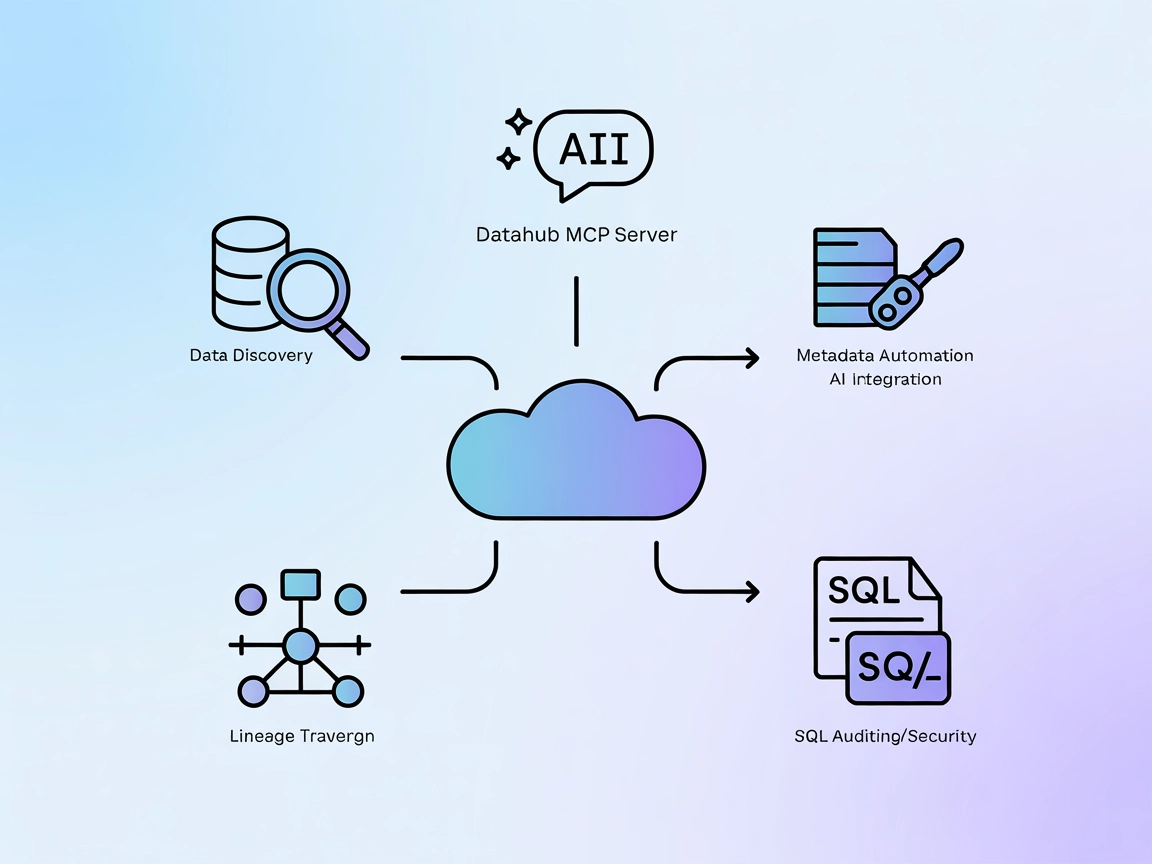
El Servidor MCP de DataHub conecta los agentes de IA de FlowHunt con la plataforma de metadatos DataHub, permitiendo descubrimiento avanzado de datos, análisis ...

Integra FlowHunt con Databricks MCP para habilitar que los agentes de IA exploren, analicen y consulten tu entorno Databricks de manera autónoma. Aprovecha los ...
Consentimiento de Cookies
Usamos cookies para mejorar tu experiencia de navegación y analizar nuestro tráfico. See our privacy policy.