
Integración del Servidor JDBC MCP
El Servidor JDBC MCP conecta asistentes de IA y bases de datos SQL usando el protocolo JDBC, permitiendo consultas en tiempo real, automatización de análisis y ...
5 min de lectura
MCP Server
JDBC
+5

Conecta tus agentes de IA y bases de datos SQL fácilmente con el Servidor JDBC MCP, habilitando flujos de trabajo seguros, automatizados y multidatabase en FlowHunt.
FlowHunt proporciona una capa de seguridad adicional entre tus sistemas internos y las herramientas de IA, dándote control granular sobre qué herramientas son accesibles desde tus servidores MCP. Los servidores MCP alojados en nuestra infraestructura pueden integrarse perfectamente con el chatbot de FlowHunt, así como con plataformas de IA populares como ChatGPT, Claude y varios editores de IA.
El Servidor JDBC MCP es un servidor Model Context Protocol (MCP) diseñado para actuar como puente entre asistentes de IA y bases de datos relacionales mediante el estándar JDBC (Java Database Connectivity). Aprovechando este servidor, los desarrolladores pueden habilitar agentes de IA para ejecutar operaciones en bases de datos, recuperar y manipular datos, e interactuar con múltiples tipos de bases de datos SQL de manera fluida. Esta capacidad mejora los flujos de trabajo permitiendo tareas como ejecutar consultas, realizar análisis y gestionar datos directamente a través de interfaces impulsadas por IA. El Servidor JDBC MCP simplifica el acceso a bases de datos dispares, facilitando la integración de funcionalidades respaldadas por bases de datos en pipelines de desarrollo y automatización.
No se encontraron ni mencionaron plantillas de prompts en el repositorio.
Comienza tu prueba gratuita hoy y ve resultados en días.
No se detallan recursos explícitos en la documentación o archivos disponibles.
No se pudo encontrar una lista explícita de herramientas en server.py ni en archivos relacionados dentro del repositorio.
Obtén los últimos consejos, tendencias y ofertas gratis.
windsurf.config.json).mcpServers utilizando el siguiente fragmento:{
"mcpServers": {
"jdbc-mcp": {
"command": "npx",
"args": ["@jdbc/mcp-server@latest"]
}
}
}
claude.config.json).{
"mcpServers": {
"jdbc-mcp": {
"command": "npx",
"args": ["@jdbc/mcp-server@latest"]
}
}
}
cursor.config.json.{
"mcpServers": {
"jdbc-mcp": {
"command": "npx",
"args": ["@jdbc/mcp-server@latest"]
}
}
}
cline.config.json.{
"mcpServers": {
"jdbc-mcp": {
"command": "npx",
"args": ["@jdbc/mcp-server@latest"]
}
}
}
Para asegurar información sensible como credenciales de bases de datos, utiliza variables de entorno en tu configuración. Ejemplo:
{
"mcpServers": {
"jdbc-mcp": {
"command": "npx",
"args": ["@jdbc/mcp-server@latest"],
"env": {
"JDBC_URL": "${JDBC_URL}",
"JDBC_USER": "${JDBC_USER}",
"JDBC_PASSWORD": "${JDBC_PASSWORD}"
},
"inputs": {
"jdbc_url": "${JDBC_URL}",
"jdbc_user": "${JDBC_USER}",
"jdbc_password": "${JDBC_PASSWORD}"
}
}
}
}
Uso de MCP en FlowHunt
Para integrar servidores MCP en tu flujo de trabajo de FlowHunt, comienza añadiendo el componente MCP a tu flujo y conectándolo a tu agente de IA:

Haz clic en el componente MCP para abrir el panel de configuración. En la sección de configuración MCP del sistema, introduce los detalles de tu servidor MCP utilizando este formato JSON:
{
"jdbc-mcp": {
"transport": "streamable_http",
"url": "https://yourmcpserver.example/pathtothemcp/url"
}
}
Una vez configurado, el agente de IA podrá usar este MCP como herramienta con acceso a todas sus funciones y capacidades. Recuerda cambiar “jdbc-mcp” por el nombre real de tu servidor MCP y reemplazar la URL por la de tu propio servidor MCP.
| Sección | Disponibilidad | Detalles/Notas |
|---|---|---|
| Resumen | ✅ | |
| Lista de Prompts | ⛔ | No se encontraron prompts |
| Lista de Recursos | ⛔ | No especificado |
| Lista de Herramientas | ⛔ | No especificado |
| Protección de las Claves API | ✅ | Ejemplo proporcionado |
| Soporte de muestreo (menos importante en evaluación) | ⛔ | No mencionado |
Una sólida implementación de JDBC MCP con instrucciones de configuración claras y buenas prácticas de seguridad, pero sin definiciones explícitas de prompts, recursos o herramientas. Con base en lo anterior, calificaría este servidor MCP con un 4/10 en documentación y facilidad de uso.
| ¿Tiene LICENCIA? | ⛔ |
|---|---|
| ¿Tiene al menos una herramienta? | ⛔ |
| Número de Forks | |
| Número de Stars |
El Servidor JDBC MCP es un puente entre asistentes de IA y bases de datos relacionales utilizando el estándar JDBC, permitiendo que los agentes de IA ejecuten consultas SQL, gestionen registros y automaticen informes en múltiples tipos de bases de datos.
Añade el componente MCP a tu flujo, abre su panel de configuración e introduce los detalles de tu servidor JDBC MCP en la sección de configuración MCP del sistema. Usa el formato JSON proporcionado para conectar tu servidor.
Utiliza variables de entorno en la configuración de tu servidor MCP para almacenar de forma segura información sensible como URLs JDBC, nombres de usuario y contraseñas. Consulta el ejemplo en la documentación para configurarlo correctamente.
Puedes conectarte a cualquier base de datos SQL compatible con JDBC, como MySQL, PostgreSQL, Oracle, SQL Server y más.
Los casos de uso comunes incluyen ejecutar consultas, gestionar y actualizar datos, integrar múltiples bases de datos, automatizar informes de datos y proporcionar acceso seguro a datos para agentes de IA.
Permite que tus agentes de IA interactúen con cualquier base de datos compatible con JDBC. Ejecuta consultas, gestiona registros y automatiza informes—todo dentro de tus flujos de trabajo en FlowHunt.
El Servidor JDBC MCP conecta asistentes de IA y bases de datos SQL usando el protocolo JDBC, permitiendo consultas en tiempo real, automatización de análisis y ...
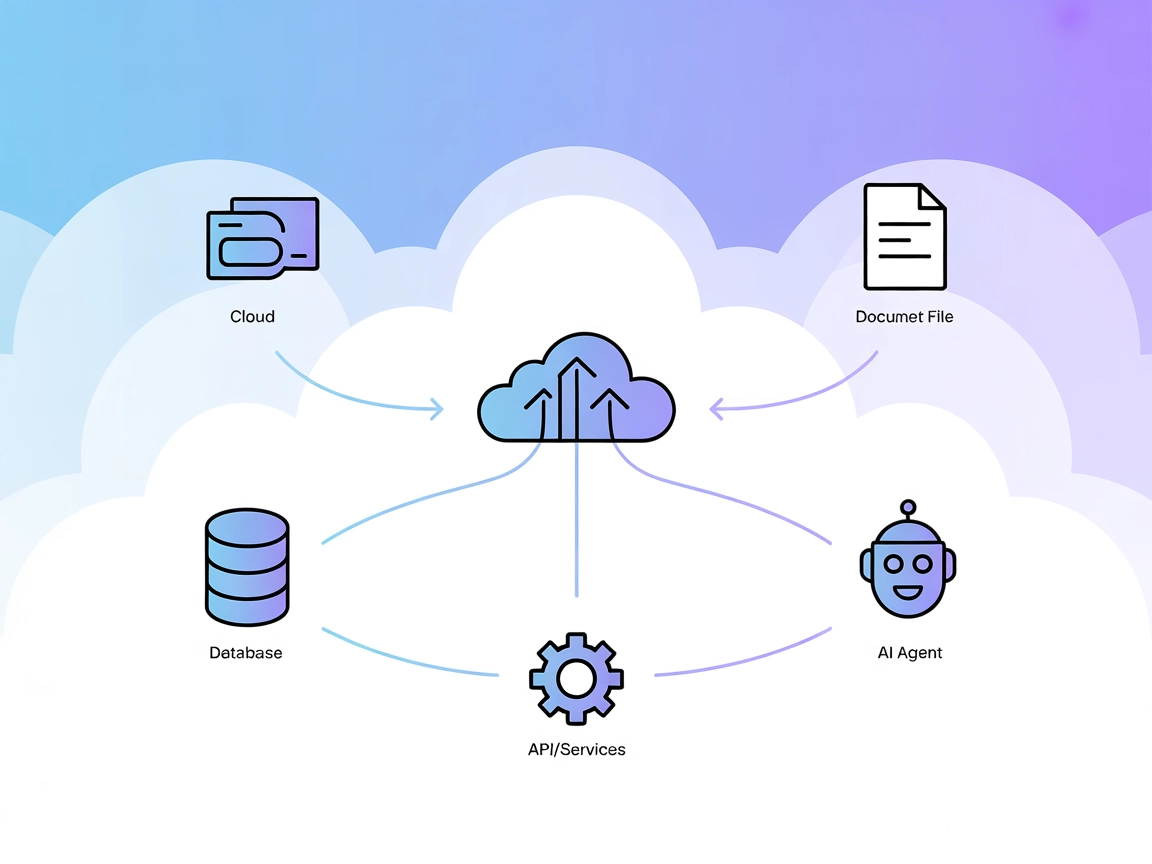
El Servidor del Protocolo de Contexto de Modelo (MCP) conecta asistentes de IA con fuentes de datos externas, APIs y servicios, permitiendo una integración flui...

El servidor MSSQL MCP permite una interacción segura, auditable y estructurada entre FlowHunt y bases de datos Microsoft SQL Server. Admite listado de tablas, e...
Consentimiento de Cookies
Usamos cookies para mejorar tu experiencia de navegación y analizar nuestro tráfico. See our privacy policy.