Opi, miten ‘From H1 if exists’, ‘Load from pointer’ ja ‘Skip Last Header’ -parametrit asetetaan.
Document Retriever
AI knowledge base
Knowledge Sources
Components
Guide
Kuinka määrittää Document Retriever:
Select section...
From H1 if exists – Aloita poiminta pääotsikosta
Load from pointer – Poimi tietoa tietystä kohdasta
Skip Last Header – Ohita alatunniste tai toistuvat otsikot
Max tokens – Hallitse vastausten pituutta
Strategy – Miten useat dokumentit yhdistetään yhdeksi tekstiksi
Muut Document Retrieverin parametrit
Document Count
Document Categories
Hide Resources
Schedules
Threshold
Vianmääritys
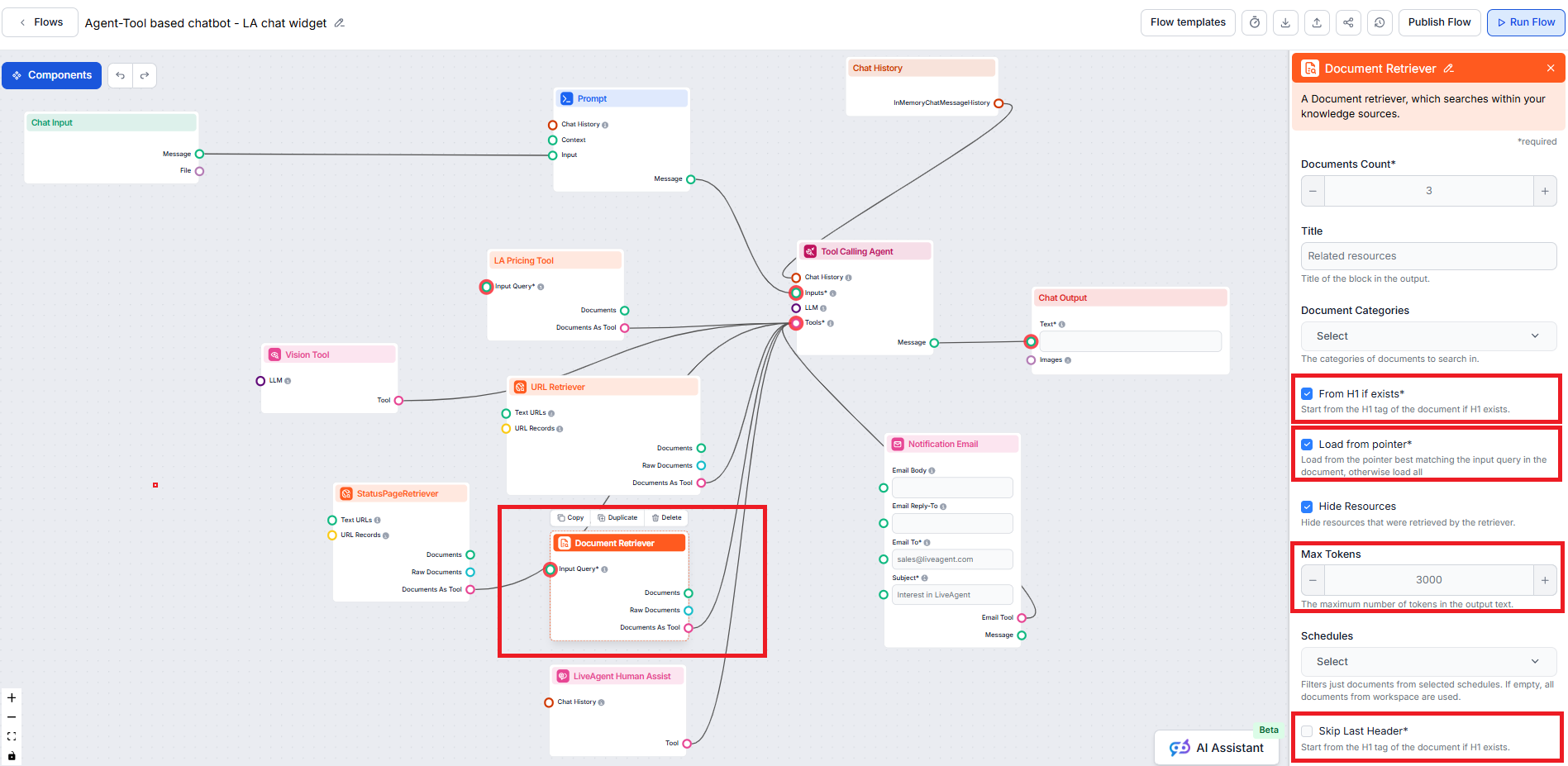
Document Retriever -komponentti
mahdollistaa chatbotin hakea tietoa niistä lähteistä, jotka olet määrittänyt Dokumentit- ja Aikataulut-osioissa. Tämän komponentin tehtävänä on hallita tiedonhakua, ja useat parametrit vaikuttavat siihen, miten komponentti hakee tietoa näistä dokumenteista.
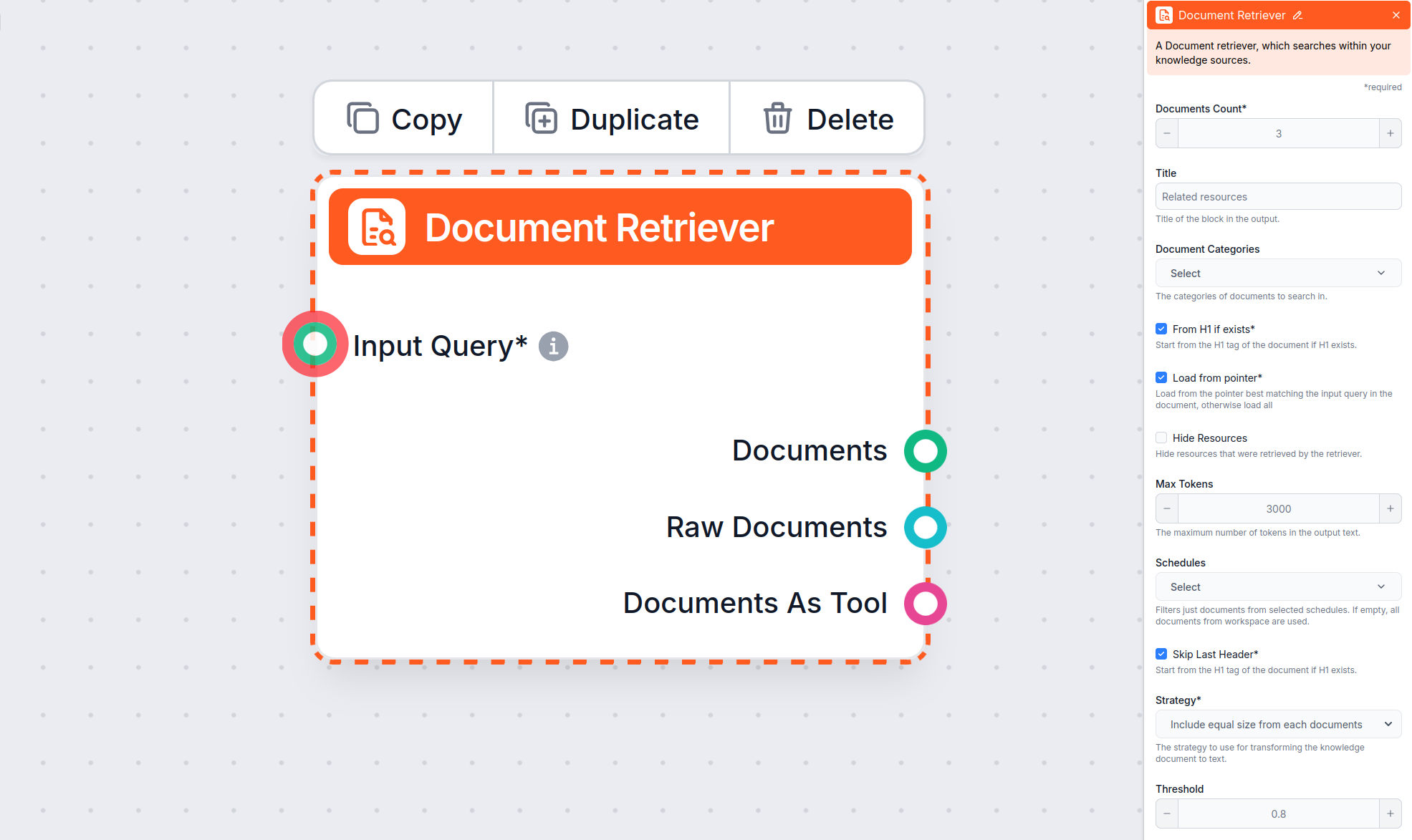
From H1 if exists – Aloita poiminta pääotsikosta
From H1 if exists -valinta ohjaa hakijaa aloittamaan sisällön poiminnan löytämästään H1-otsikosta (yleensä artikkelin pääotsikko).
Mitä tapahtuu?
Jos valittu: Kaikki ennen ensimmäistä H1:tä (kuten navigaatio, murupolut tai kirjautumislinkit) ohitetaan. Poiminta alkaa varsinaisesta artikkelin sisällöstä.
Jos ei valittu: Sisällön poiminta alkaa sivun aivan yläosasta, mukaan lukien kaikki navigaatiot, otsikot ja metatiedot ennen pääartikkelia.
Käyttöesimerkki: Haluat hakea vain varsinaisen oppaan ilman verkkosivusi navigointia tai ylimääräisiä otsikoita.
Huom: From H1 if exists on oletuksena käytössä Document Retriever -komponentissa.
Load from pointer – Poimi tietoa tietystä kohdasta
Load from pointer -valinta antaa enemmän tarkkuutta, koska sillä Document Retriever noutaa tietoa vain osoittimen (pointer) kohdalta mahdollisesti pitkässä artikkelissa.
Mitä tapahtuu?
Jos valittu (ja osoitin on asetettu): Poiminta alkaa määritetystä osoittimesta, jolloin kaikki sitä ennen oleva ohitetaan, vaikka se olisi H1:n jälkeen.
Jos ei valittu: Poiminta alkaa oletuspaikasta (dokumentin yläreunasta tai ensimmäisestä H1:stä, jos sekin on valittu).
Mikä on “pointer”? Osoitin on yleensä dokumentissa oleva yksilöllinen merkkijono tai otsikko (esim. H2 tai tietty lause tai osion otsikko).
Käyttöesimerkki: Haluat ohittaa johdanto-osuudet ja hakea tietoa tietystä, olennaisesta osiosta mahdollisesti pitkässä artikkelissa (esim. kohdasta “Vaihe 4: Lisää live chat -painike” asennusoppaassa).
Valmis kasvattamaan liiketoimintaasi?
Aloita ilmainen kokeilujakso tänään ja näe tulokset muutamassa päivässä.
Skip Last Header – Ohita alatunniste tai toistuvat otsikot
Skip Last Header -valinta on hyödyllinen, jos haluat jättää huomioimatta dokumentin viimeisen otsikon, joka usein toistuu tai liittyy navigaatioon tai alatunnisteeseen.
Mitä tapahtuu?
Jos valittu: Viimeinen otsikko (esim. toistuva artikkelin nimi tai “Muut artikkelit” -osio) ohitetaan poiminnassa.
Jos ei valittu: Kaikki otsikot, myös viimeinen, sisällytetään tulokseen.
Käyttöesimerkki: Haluat estää Document Retrieveriä lataamasta navigaatio-otsikkoa (kuten “Muut artikkelit” ohjesivun lopussa), jotta vain varsinainen sisältö käsitellään.
Huom: Skip Last Header auttaa dokumenteissa, joissa alatunnisteet tai toistuvat navigaatioelementit luodaan automaattisesti. Jos tällaisia osioita ei ole, tämän parametrin käyttö voi johtaa siihen, että osa artikkelin oikeasta tiedosta jää käsittelemättä. Siksi suositellaan jättämään tämä valinta pois päältä, ellei ole perusteltua syytä ottaa sitä käyttöön.
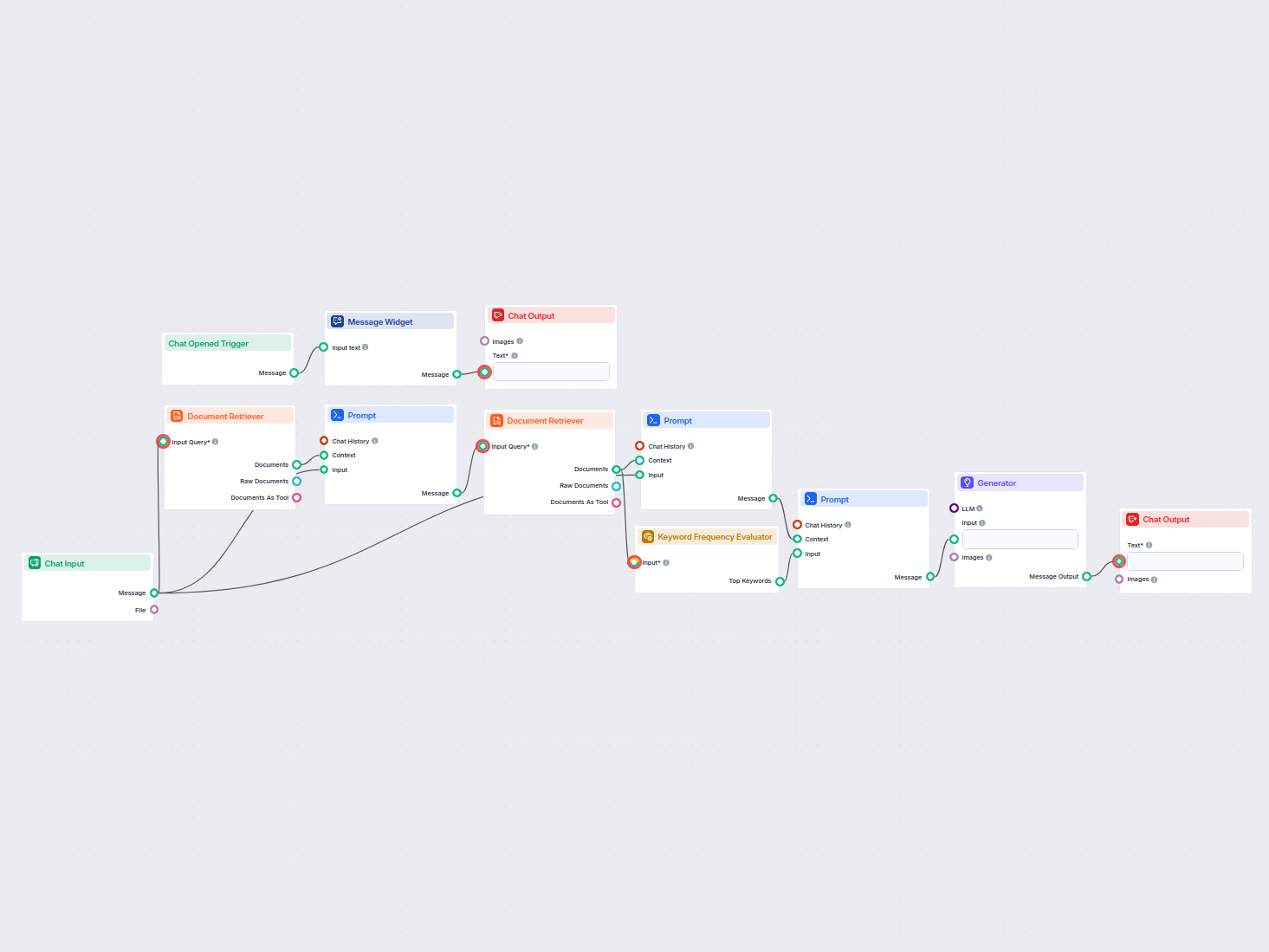
Max tokens – Hallitse vastausten pituutta
Max tokens -parametrilla voit säätää, kuinka monta tokenia (sanaa ja välimerkkiä, kuten taustalla oleva AI-malli laskee) Document Retriever palauttaa poimitusta tekstistä.
Mitä tapahtuu?
Poimittu sisältö rajoitetaan määritettyyn token-määrään. Kaikki ylimenevä sisältö katkaistaan eikä sisälly tulokseen.
Tämä parametri auttaa hallitsemaan erittäin pitkiä dokumentteja ja varmistaa, että tulos pysyy AI-mallien käsittelyrajojen sisällä.
Oletusarvo: Oletuksena arvo on usein 3000 tokenia, mutta tarvittaessa voit säätää tätä.
Käyttöesimerkki: Jos käsittelet pitkiä dokumentteja, alhaisemman Max tokens -arvon asettaminen auttaa pitämään vastaukset ytimekkäinä. Parhaan lopputuloksen saat kuitenkin ottamalla käyttöön myös “Load from pointer” -parametrin. Näin varmistat, että poiminta alkaa dokumentin olennaisimmasta kohdasta eikä alusta, jolloin saat tiiviin ja hallitun tietopaketin määrittelemäsi token-rajan sisällä. Tämä yhdistelmä on erityisen hyödyllinen, kun haluat tiiviitä ja asiayhteyteen sopivia vastauksia laajoista lähteistä.
Huom: Jos huomaat, että tietoa jää pois, kokeile nostaa Max tokens -arvoa. Jos taas haluat lyhyempiä, tiiviimpiä vastauksia, pienennä Max tokens -parametria.
Liity uutiskirjeellemme
Saa uusimmat vinkit, trendit ja tarjoukset ilmaiseksi.
Strategy – Miten useat dokumentit yhdistetään yhdeksi tekstiksi
Kun Document Retriever löytää useita osuvia dokumentteja, Strategy-parametri määrittää, miten ne yhdistetään yhdeksi tekstiksi chatbotillesi “Max tokens” -rajan puitteissa.
Kaksi strategiaa:
Ota yhtä suuri osuus jokaisesta dokumentista: Token-raja jaetaan tasan. Esimerkiksi kolmella dokumentilla ja 3 000 tokenin rajalla jokainen saa enintään 1 000 tokenia. Näin kaikki lähteet vaikuttavat lopputulokseen tasapuolisesti, mikä on hyödyllistä, kun haluat monipuolisen vastauksen useista dokumenteista.
Käytä, kun: Sinulla on ohjeistuksia, joissa saman aiheen eri näkökulmat ovat jaettu useaan dokumenttiin, ja kattavan vastauksen luominen vaatii tietoa kaikista lähteistä. Tämä tapa toimii parhaiten, kun yksikään dokumentti ei sisällä kaikkea olennaista, ja haluat varmistaa, että jokaisesta osuvasta dokumentista tulee tietoa vastaukseen – näin saat monipuolisen näkökulman.
Yhdistä dokumentit, täytä ensimmäisestä token-rajaan asti: Dokumentit lisätään tärkeysjärjestyksessä, kunnes token-raja täyttyy. Tärkein dokumentti täyttää ensin tilan, ja jos tilaa jää, vähemmän tärkeät lisätään mukaan. Jos ensimmäinen dokumentti on pitkä, se voi täyttää koko rajan yksinään.
Käytä, kun: Dokumenteissa on yksityiskohtainen tieto jokaisesta aiheesta yhdessä tiedostossa, ja kysymyksiin vastaaminen hyötyy siitä, että käytetään mahdollisimman laajasti juuri tätä dokumenttia sen sijaan, että yhdistettäisiin tietoa useista samankaltaisista lähteistä.
Miten valita?
Käytä Ota yhtä suuri osuus jokaisesta dokumentista jos haluat tasapainoisen edustuksen kaikista lähteistä.
Käytä Yhdistä dokumentit, täytä ensimmäisestä token-rajaan asti jos haluat painottaa tärkeintä dokumenttia etkä välitä kaikkien lähteiden mukaanottamisesta.
Huom: Nämä strategiat vaikuttavat vain siihen, miten teksti koostetaan haetuista dokumenteista ennen seuraavaa vaihetta (esim. AI-generointi). Ne eivät muuta sitä, mitkä dokumentit haetaan – vain miten niiden sisältö yhdistetään ja lyhennetään Max tokens -asetuksen rajoissa.
Muut Document Retrieverin parametrit
Vaikka tämä ohje keskittyy ‘From H1 if exists’, ‘Load from pointer’, ‘Skip Last Header’ ja ‘Max tokens’ -parametrien asetuksiin, Document Retriever tarjoaa myös muita parametreja, joilla hallitaan dokumenttien valintaa ja hakua:
Document Count
Tämä asetus rajoittaa haettavien dokumenttien määrää, jotta tulokset pysyvät olennaisina ja vastausten tuottaminen on nopeaa.
Document Categories
Tällä valinnaisella asetuksella voit rajoittaa haun yhteen tai useampaan kategoriaan, jotka olet luonut Dokumentit-osiossa Tietolähteissä.
Hide Resources
Tämän avulla voit sisällyttää tai piilottaa erillisen osion ennen varsinaista chatbotin vastausta – siinä listataan resurssit, jotka retriever on hakenut. LiveAgent-integraatiota varten tämä tulee rastittaa, sillä kyseistä osiota ei tueta, eikä se näy oikein LiveAgent-chatbotin widgetissä.
Schedules
Voit rajoittaa hakua niihin aikatauluihin, jotka olet määrittänyt sisällön indeksointia tai päivitystä varten Tietolähteissä.
Threshold
Määrittää, kuinka hyvin haettavien dokumenttien tulee vastata kyselyä, käyttäen relevanssipistettä (0–1). Esimerkiksi 0,7–0,8 on suositeltava arvo erittäin osuville vastauksille. Korkeammat arvot tuottavat tarkempia osumia, matalammat voivat tuoda mukaan vähemmän osuvia dokumentteja.
Esimerkki: Jos asetat threshold-arvoksi 0,6 ja sinulla on neljä artikkelia, joiden relevanssipisteet ovat 0,8, 0,65, 0,5 ja 0,9, mukaan poimintaan valitaan vain ne, joiden arvo on yli 0,6 (eli 0,8, 0,65 ja 0,9).
Vianmääritys
Jos chatbotin antama vastaus ei sisällä tietoa, jonka tiedät olevan saatavilla dokumenteissasi tai aikatauluissasi, tarkista keskusteluhistoria “Verbose”-asetuksella nähdäksesi yksityiskohtaisia lokitietoja siitä, käytettiinkö Document Retrieveriä ja mitä dokumentteja haettiin. Tarvittaessa säädä asetuksia ja promptia näiden lokitietojen perusteella.
Näin syötät FlowHunt-chatbotille valittuja cPanel-dokumentaation osioita (ei koko sivustoa)
Yksityiskohtainen opas siitä, miten tuot vain tietyt docs.cpanel.net-sivut FlowHunt-chatbotiin, jolloin siitä tulee asiantuntija rajatuissa cPanel-aiheissa ilma...
Chatbottisi voi välittömästi käyttää ja hyödyntää dokumentteja, HTML-sivuja sekä jopa YouTube-videoita räätälöidäkseen ainutlaatuisen kontekstisi. Täydellinen l...
Aiheeseen Liittyvien Artikkelien Kappaleen Generaattori
Luo automaattisesti lyhyen ja mukaansatempaavan kappaleen verkkosivustollesi, joka sisältää linkkejä kaikkein olennaisimpiin aiheeseen liittyviin artikkeleihin....
3 min lukuaika
Evästeiden Suostumus Käytämme evästeitä parantaaksemme selauskokemustasi ja analysoidaksemme liikennettämme. See our privacy policy.