
Agents IA : Comment raisonne GPT 4o
Explorez les processus de réflexion des agents IA dans cette évaluation complète de GPT-4o. Découvrez ses performances sur des tâches telles que la génération d...
9 min de lecture
AI
GPT-4o
+6

Maîtrisez la méthodologie LLM en tant que juge pour évaluer agents et chatbots IA. Ce guide couvre les métriques d’évaluation, les meilleures pratiques de prompts de jugement et la mise en pratique avec la boîte à outils FlowHunt.
À mesure que l’intelligence artificielle progresse, évaluer les systèmes IA comme les chatbots devient de plus en plus crucial. Les métriques traditionnelles peinent souvent à saisir la complexité et la subtilité du langage naturel, d’où l’émergence de la méthodologie « LLM en tant que juge » — où un grand modèle de langage évalue les sorties d’une autre IA. Cette approche offre des avantages significatifs en matière d’évolutivité et de cohérence, avec des études montrant jusqu’à 85 % d’alignement avec les jugements humains, bien qu’elle présente certains défis, comme des biais potentiels [1].
Dans ce guide complet, nous allons explorer ce que recouvre la méthode LLM en tant que juge, examiner son fonctionnement, discuter des métriques impliquées et fournir des conseils pratiques pour rédiger des prompts de jugement efficaces. Nous montrerons également comment évaluer des agents IA avec la boîte à outils FlowHunt, à travers un exemple détaillé d’évaluation de la performance d’un chatbot de support client.
LLM en tant que juge consiste à utiliser un grand modèle de langage pour évaluer la qualité des réponses générées par un autre système IA, tel qu’un chatbot ou un agent. Cette méthodologie s’avère particulièrement efficace pour les tâches ouvertes, où les métriques classiques comme BLEU ou ROUGE ne capturent pas des éléments essentiels comme la cohérence, la pertinence ou l’adéquation contextuelle. L’approche surpasse l’évaluation humaine en termes d’évolutivité, de coût et de cohérence, là où la revue humaine peut être chronophage et subjective.
Par exemple, un juge LLM peut déterminer si la réponse d’un chatbot à une question client est exacte et utile, mimant efficacement le jugement humain via une automatisation sophistiquée. Cette capacité est précieuse pour évaluer des systèmes conversationnels complexes où de multiples dimensions de qualité doivent être considérées.
La recherche indique que les juges LLM peuvent atteindre jusqu’à 85 % d’alignement avec les évaluations humaines, ce qui en fait une solution intéressante pour les évaluations à grande échelle [1]. Cependant, ces systèmes présentent aussi certains biais, comme une tendance à préférer les réponses longues ou à favoriser les sorties de modèles similaires (on estime que GPT-4 préfère ses propres réponses d’environ 10 %) [2]. Ces limites nécessitent une rédaction de prompts soignée et parfois une supervision humaine pour garantir la fiabilité et l’équité des évaluations.
Commencez votre essai gratuit aujourd'hui et voyez les résultats en quelques jours.
Le processus LLM en tant que juge suit une approche systématique en plusieurs étapes clés :
1. Définir les critères d’évaluation : Commencez par identifier les qualités spécifiques à évaluer, comme l’exactitude, la pertinence, la cohérence, la fluidité, la sécurité, l’exhaustivité ou le ton. Ces critères doivent correspondre à l’objectif et au contexte d’utilisation de votre système IA.
2. Rédiger un prompt de jugement : Élaborer un prompt détaillé qui indique clairement au LLM comment évaluer la sortie. Ce prompt doit inclure des critères précis et peut intégrer des exemples pour plus de clarté.
3. Fournir l’entrée et la sortie : Donnez au LLM juge à la fois l’entrée d’origine (ex : question utilisateur) et la réponse de l’IA (ex : réponse du chatbot) pour garantir la compréhension contextuelle complète.
4. Recevoir l’évaluation : Le LLM fournit une note, un classement ou un feedback détaillé selon vos critères prédéfinis, apportant des pistes d’amélioration concrètes.
Le processus d’évaluation utilise généralement deux méthodes principales :
Évaluation d’une sortie unique : Le LLM note une réponse individuelle, soit sans référence (évaluation sans vérité terrain), soit en comparaison avec une réponse attendue. Par exemple, G-Eval utilise le chain-of-thought prompting pour noter les réponses selon la justesse et d’autres dimensions de qualité [1].
Comparaison par paires : Le LLM compare deux sorties et sélectionne la meilleure. Cette méthode est utile pour comparer différents modèles ou prompts, et ressemble aux compétitions automatisées de type LLM arena [1].
Exemple de prompt de juge efficace :
« Évaluez la réponse suivante sur une échelle de 1 à 5 pour son exactitude factuelle et sa pertinence par rapport à la question utilisateur. Donnez une brève explication de votre notation. Question : [question]. Réponse : [réponse]. »
Les métriques spécifiques dépendent de vos objectifs d’évaluation, mais incluent couramment les dimensions suivantes :
| Métrique | Description | Critère Exemple |
|---|---|---|
| Exactitude / Justesse factuelle | Dans quelle mesure la réponse est-elle factuelle ? | Correction des faits donnés |
| Pertinence | La réponse répond-elle efficacement à la question ? | Alignement avec l’intention utilisateur |
| Cohérence | La réponse est-elle logique et bien structurée ? | Clarté et enchaînement logique |
| Fluidité | Le langage est-il naturel et sans faute ? | Correction grammaticale, lisibilité |
| Sécurité | La réponse est-elle exempte de contenu nuisible, biaisé ou inapproprié ? | Absence de toxicité ou de biais |
| Exhaustivité | La réponse fournit-elle toutes les informations nécessaires ? | Degré de complétude |
| Ton / Style | Le ton ou le style correspond-il à l’attendu ? | Cohérence avec la personnalité visée |
Ces métriques peuvent être notées numériquement (échelles 1-5) ou de façon catégorielle (ex : pertinent / non pertinent). Pour les systèmes RAG (Retrieval-Augmented Generation), d’autres métriques comme la pertinence contextuelle ou la fidélité au contexte fourni peuvent aussi s’appliquer [2].
La performance du LLM juge lui-même peut être évaluée via des métriques classiques (précision, rappel, accord avec l’humain), notamment lors de la validation de la fiabilité du juge [2].
Recevez gratuitement les derniers conseils, tendances et offres.
Des prompts efficaces sont essentiels pour obtenir des évaluations fiables. Voici les bonnes pratiques issues de l’expérience et de la littérature [1, 2, 3] :
Soyez spécifique et précis : Définissez clairement vos critères d’évaluation avec un langage concret. Par exemple, utilisez « Notez l’exactitude factuelle sur une échelle de 1 à 5 » plutôt que des instructions vagues.
Fournissez des exemples concrets : Utilisez le few-shot prompting avec des exemples de bonnes et mauvaises réponses pour guider la compréhension du LLM.
Utilisez un langage clair et sans ambiguïté : Évitez les instructions ambiguës qui pourraient provoquer des interprétations différentes selon les cas.
Équilibrez soigneusement les critères multiples : Précisez si vous souhaitez une note globale ou des notes distinctes pour chaque critère lors de l’évaluation de plusieurs dimensions.
Incluez le contexte pertinent : Donnez toujours la question ou le contexte d’origine pour garantir une évaluation pertinente au besoin utilisateur.
Atténuez activement les biais : Évitez les prompts favorisant involontairement les réponses longues ou certains styles, sauf si c’est voulu. Le chain-of-thought prompting ou l’inversion systématique des positions lors des comparaisons par paires peuvent aider à réduire les biais [1].
Demandez une sortie structurée : Demandez des scores au format standardisé (ex : JSON) pour faciliter l’analyse et le traitement automatisé.
Itérez et testez en continu : Testez d’abord vos prompts sur de petits jeux de données et améliorez-les avant de passer à l’échelle.
Favorisez le raisonnement étape par étape : Demandez au LLM d’expliquer son raisonnement pour des jugements plus précis et explicables.
Choisissez le bon modèle : Sélectionnez un LLM apte à juger avec nuance, tel que GPT-4 ou Claude, selon vos besoins [3].
Exemple de prompt bien structuré :
« Notez la réponse suivante de 1 à 5 selon son exactitude factuelle et sa pertinence pour la question. Expliquez brièvement votre note. Question : ‘Quelle est la capitale de la France ?’ Réponse : ‘La capitale de la France est la Floride.’ »
FlowHunt est une plateforme no-code complète d’automatisation de workflows IA permettant de construire, déployer et évaluer des agents et chatbots IA via une interface intuitive de glisser-déposer [4]. La plateforme propose des intégrations transparentes avec des LLM leaders comme ChatGPT et Claude, et sa boîte à outils CLI open-source permet des rapports avancés dédiés à l’évaluation des flux IA [4].
Bien que la documentation spécifique sur l’outil d’évaluation de FlowHunt soit limitée, on peut esquisser un processus général basé sur des plateformes similaires et les meilleures pratiques :
1. Définir les critères d’évaluation : Utilisez l’interface ergonomique de FlowHunt pour spécifier les métriques clés (exactitude, pertinence, exhaustivité) en fonction de votre cas d’usage.
2. Configurer le LLM juge : Paramétrez un LLM de jugement dans la boîte à outils FlowHunt, en choisissant un modèle qui fournit des sorties structurées pour des évaluations fiables.
3. Lancer les évaluations : Saisissez un jeu de données de questions et de réponses attendues, puis utilisez la fonctionnalité LLM en tant que juge pour exécuter les évaluations à grande échelle.
4. Analyser et agir sur les résultats : Passez en revue les scores et retours fournis dans les rapports détaillés de FlowHunt pour cibler les axes d’amélioration.
L’approche no-code de FlowHunt rend l’évaluation avancée accessible aux non-techniciens, tandis que sa CLI permet aux développeurs d’automatiser les évaluations et de générer des rapports complets [4].
Suivons un exemple concret d’évaluation d’un chatbot de support client pour un site e-commerce avec FlowHunt.
Scénario : Un chatbot destiné à traiter les questions sur les commandes, retours et livraisons.
Exemples d’interactions :
Utilisateur : « J’ai besoin d’aide pour ma commande. »
Bot : « Bien sûr, pouvez-vous me donner votre numéro de commande ? »
Utilisateur : « Quelle est votre politique de retour ? »
Bot : « Notre politique permet un retour sous 30 jours après l’achat. Merci de consulter notre page dédiée pour plus d’informations. »
Utilisateur : « Comment suivre mon colis ? »
Bot : « Vous pouvez suivre votre colis en saisissant votre numéro de suivi sur notre site. »
Créez un jeu complet de questions utilisateur et de réponses attendues :
| Question | Réponse attendue |
|---|---|
| J’ai besoin d’aide pour ma commande. | Bien sûr, pouvez-vous me donner votre numéro de commande ? |
| Quelle est votre politique de retour ? | Notre politique permet un retour sous 30 jours après l’achat. Merci de consulter notre page dédiée pour plus d’informations. |
| Comment suivre mon colis ? | Vous pouvez suivre votre colis en saisissant votre numéro de suivi sur notre site. |
Importer le jeu de données : Chargez votre jeu de données préparé sur la plateforme FlowHunt avec les outils adéquats.
Sélectionner le flux de chatbot : Choisissez le flux de support client à évaluer parmi vos configurations.
Définir les critères d’évaluation : Configurez vos critères (exactitude, pertinence) dans l’interface FlowHunt pour garantir une évaluation homogène.
Lancer l’évaluation : Exécutez le processus d’évaluation ; la boîte à outils teste le chatbot avec votre jeu de données et fait juger chaque réponse par un LLM selon vos critères.
Analyser les résultats : Analysez le rapport d’évaluation détaillé. Par exemple, si le bot répond à « Quelle est votre politique de retour ? » par « Je ne sais pas », le LLM juge attribuera probablement une faible note de pertinence, signalant un point d’amélioration immédiat.
Ce processus systématique garantit que votre chatbot atteint les standards attendus avant d’être mis en production, réduisant le risque d’expériences clients insatisfaisantes.
LLM en tant que juge représente une approche transformatrice pour l’évaluation des systèmes IA, offrant une évolutivité et une cohérence incomparables par rapport aux évaluations humaines traditionnelles. En s’appuyant sur des outils avancés comme FlowHunt, les développeurs peuvent mettre en œuvre cette méthodologie pour garantir la performance et la qualité de leurs agents IA.
Le succès de cette démarche repose sur la rédaction de prompts clairs et non biaisés, ainsi que sur la définition de métriques adaptées à vos objectifs. À mesure que la technologie IA progresse, LLM en tant que juge jouera un rôle croissant dans le maintien de standards élevés de performance, de fiabilité et de satisfaction utilisateur à travers toutes les applications IA.
L’avenir de l’évaluation IA réside dans la combinaison réfléchie d’outils automatisés et de supervision humaine, afin que nos systèmes IA soient performants sur le plan technique et apportent une vraie valeur ajoutée aux utilisateurs dans des situations réelles.
LLM en tant que juge est une méthodologie où un grand modèle de langage évalue les sorties d’un autre système IA. C’est important car cela permet une évaluation évolutive et économique des agents IA, avec jusqu’à 85 % d’alignement sur les jugements humains, notamment pour des tâches complexes où les métriques traditionnelles échouent.
LLM en tant que juge offre une évolutivité supérieure (traitement de milliers de réponses rapidement), un coût réduit (moins cher que les évaluateurs humains), et une cohérence dans les standards d’évaluation, tout en maintenant un fort alignement avec les jugements humains.
Les métriques courantes incluent la justesse / exactitude factuelle, la pertinence, la cohérence, la fluidité, la sécurité, l’exhaustivité et le ton / style. Ces aspects peuvent être notés de façon numérique ou catégorique selon vos besoins d’évaluation.
Des prompts de juge efficaces doivent être spécifiques et clairs, fournir des exemples concrets, utiliser un langage non ambigu, équilibrer soigneusement de multiples critères, inclure le contexte pertinent, atténuer activement les biais et demander une sortie structurée pour une évaluation cohérente.
Oui, la plateforme no-code FlowHunt prend en charge la mise en œuvre de LLM en tant que juge via son interface glisser-déposer, son intégration avec des LLM leaders comme ChatGPT et Claude, et sa boîte à outils CLI pour des rapports avancés et des évaluations automatisées.
Arshia est ingénieure en workflows d'IA chez FlowHunt. Avec une formation en informatique et une passion pour l’IA, elle se spécialise dans la création de workflows efficaces intégrant des outils d'IA aux tâches quotidiennes, afin d’accroître la productivité et la créativité.

Mettez en œuvre la méthodologie LLM en tant que juge pour garantir que vos agents IA atteignent des standards de performance élevés. Construisez, évaluez et optimisez vos workflows IA avec la boîte à outils complète FlowHunt.
Explorez les processus de réflexion des agents IA dans cette évaluation complète de GPT-4o. Découvrez ses performances sur des tâches telles que la génération d...

Comparaison des derniers bots de trading pilotés par LLM, leurs modèles sous-jacents, les techniques d'amélioration de la qualité et les résultats concrets. Inc...
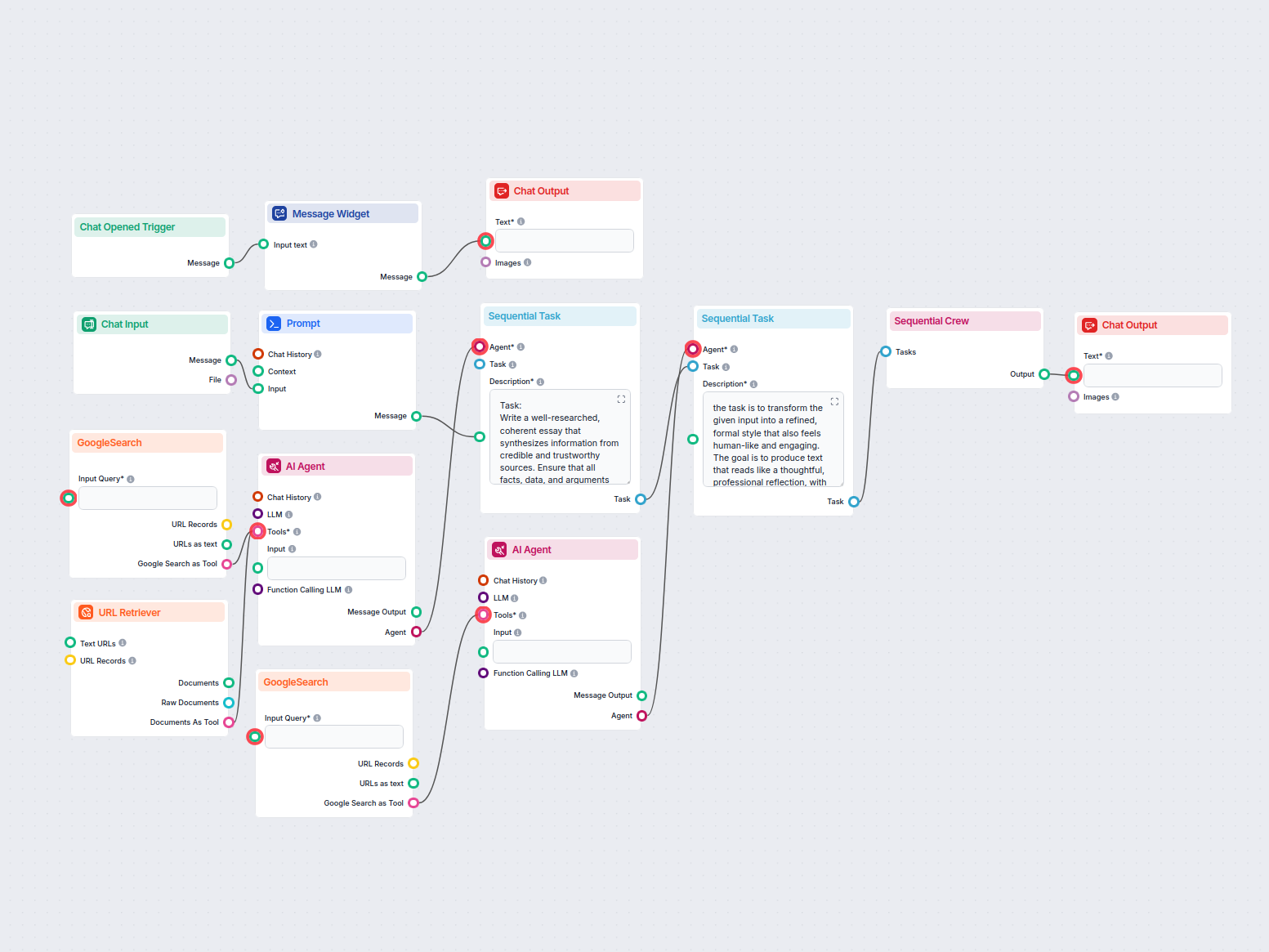
Génère automatiquement des essais factuels et bien structurés au format MLA en utilisant des sources crédibles trouvées via la recherche Google. Idéal pour les ...
Consentement aux Cookies
Nous utilisons des cookies pour améliorer votre expérience de navigation et analyser notre trafic. See our privacy policy.