Wan 2.1xa0: la révolution open source de la génération vidéo par IA
Wan 2.1 est un puissant modèle open source de génération vidéo par IA développé par Alibaba, offrant des vidéos de qualité studio à partir de texte ou d’images, librement utilisable localement par tous.
AI Video Generation
Open Source
Wan 2.1
Alibaba
Generative AI
Video AI
AI Tools
Wan 2.1 (également appelé WanX 2.1) repousse les limites en tant que modèle entièrement open source de génération vidéo par IA, développé par le Tongyi Lab d’Alibaba. Contrairement à de nombreux systèmes de génération vidéo propriétaires nécessitant des abonnements coûteux ou un accès API, Wan 2.1 offre une qualité comparable, voire supérieure, tout en restant entièrement gratuit et accessible aux développeurs, chercheurs et professionnels de la création.
Ce qui rend Wan 2.1 vraiment unique, c’est sa combinaison d’accessibilité et de performance. La variante compacte T2V-1.3B nécessite seulement ~8,2 Go de mémoire GPU, la rendant compatible avec la plupart des GPU grand public modernes. Parallèlement, la version 14B de paramètres offre des performances de pointe, surpassant aussi bien les alternatives open source que de nombreux modèles commerciaux sur les benchmarks standards.
Les fonctionnalités clés qui distinguent Wan 2.1
Prise en charge multitâche
Wan 2.1 ne se limite pas à la génération texte-en-vidéo. Son architecture polyvalente prend en charge :
Texte en vidéo (T2V)
Image en vidéo (I2V)
Montage vidéo (vidéo en vidéo)
Génération d’image à partir de texte
Génération audio à partir de vidéo
Cette flexibilité vous permet de commencer avec une instruction textuelle, une image fixe, voire une vidéo existante, et de la transformer selon votre vision créative.
Génération de texte multilingue
En tant que premier modèle vidéo capable d’afficher du texte lisible en anglais et en chinois dans les vidéos générées, Wan 2.1 ouvre de nouvelles perspectives aux créateurs de contenus internationaux. Cette fonctionnalité est particulièrement utile pour créer des sous-titres ou du texte de scène dans des vidéos multilingues.
VAE vidéo révolutionnaire (Wan-VAE)
Au cœur de l’efficacité de Wan 2.1 se trouve son Autoencodeur Variationnel Vidéo causal 3D. Cette avancée technologique compresse efficacement l’information spatio-temporelle, permettant au modèle de :
Compresser les vidéos par des centaines de fois
Préserver la fidélité du mouvement et des détails
Supporter des sorties haute résolution jusqu’à 1080p
Efficacité et accessibilité exceptionnelles
Le modèle compact 1.3B nécessite seulement 8,19 Go de VRAM et peut produire une vidéo 480p de 5 secondes en environ 4 minutes sur une RTX 4090. Malgré cette efficacité, sa qualité rivalise avec celle de modèles bien plus volumineux, offrant un équilibre parfait entre rapidité et fidélité visuelle.
Benchmarks et qualité leaders du secteur
Lors des évaluations publiques, Wan 14B a obtenu le meilleur score global lors des tests Wan-Bench, surpassant ses concurrents sur :
La qualité du mouvement
La stabilité
La précision dans le suivi des instructions
Prêt à développer votre entreprise?
Commencez votre essai gratuit aujourd'hui et voyez les résultats en quelques jours.
Comparaison de Wan 2.1 avec d’autres modèles de génération vidéo
Contrairement aux systèmes propriétaires tels que Sora d’OpenAI ou Gen-2 de Runway, Wan 2.1 est librement disponible et peut être exécuté localement. Il dépasse en général les anciens modèles open source (comme CogVideo, MAKE-A-VIDEO et Pika) et même de nombreuses solutions commerciales lors des benchmarks de qualité.
Un récent rapport sectoriel a noté que « parmi de nombreux modèles vidéo IA, Wan 2.1 et Sora se distinguent » : Wan 2.1 pour son ouverture et son efficacité, Sora pour son innovation propriétaire. Lors des tests communautaires, les utilisateurs ont rapporté que la capacité image-en-vidéo de Wan 2.1 surpasse la concurrence en clarté et en rendu cinématographique.
La technologie derrière Wan 2.1
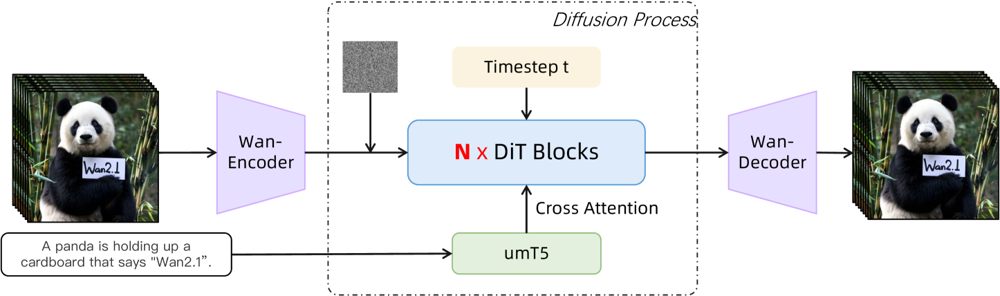
Wan 2.1 s’appuie sur une architecture diffusion-transformer avec un VAE spatio-temporel innovant. Voici son fonctionnement :
Une entrée (texte et/ou image/vidéo) est encodée en une représentation vidéo latente par Wan-VAE
Un transformeur de diffusion (basé sur l’architecture DiT) débruite itérativement ce latent
Le processus est guidé par l’encodeur de texte (une variante multilingue de T5 appelée umT5)
Enfin, le décodeur Wan-VAE reconstruit les images vidéo de sortie
Figure : Architecture haut niveau de Wan 2.1 (cas texte-en-vidéo). Une vidéo (ou image) est d’abord encodée par l’encodeur Wan-VAE en un latent. Ce latent passe ensuite à travers N blocs de transformeur de diffusion, qui prennent en compte l’embedding texte (depuis umT5) via cross-attention. Enfin, le décodeur Wan-VAE reconstruit les images vidéo. Ce design — avec un « encodeur/décodeur VAE causal 3D entourant un transformeur de diffusion » (ar5iv.org
) — permet une compression efficace des données spatio-temporelles et autorise une sortie vidéo de haute qualité.
Cette architecture innovante — comprenant un « encodeur/décodeur VAE causal 3D entourant un transformeur de diffusion » — permet une compression efficace des données spatio-temporelles et autorise une sortie vidéo de haute qualité.
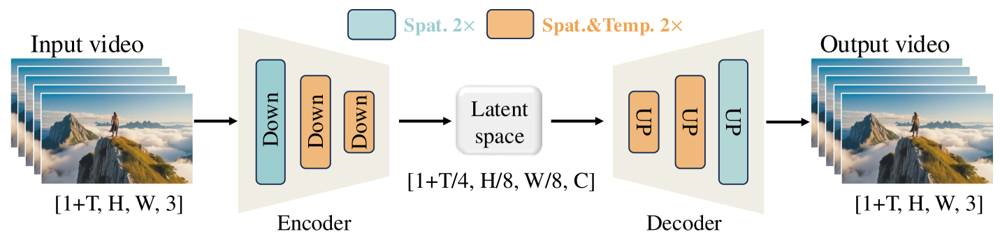
Le Wan-VAE est spécialement conçu pour la vidéo. Il compresse l’entrée par des facteurs impressionnants (x4 temporel et x8 spatial) en un latent compact avant de le décoder en vidéo complète. L’utilisation de convolutions 3D et de couches causales (préservant le temps) garantit la cohérence du mouvement dans tout le contenu généré.
Figure : Framework Wan-VAE de Wan 2.1 (encodeur-décodeur). L’encodeur Wan-VAE (gauche) applique une série de couches de sous-échantillonnage (« Down ») à la vidéo d’entrée (forme [1+T, H, W, 3] images) jusqu’à obtenir un latent compact ([1+T/4, H/8, W/8, C]). Le décodeur Wan-VAE (droite) rééchantillonne symétriquement (« UP ») ce latent vers les images vidéo d’origine. Les blocs bleus indiquent la compression spatiale, les blocs orange la compression spatiale+temporelle (ar5iv.org
). En compressant la vidéo par un facteur 256x (en volume spatio-temporel), Wan-VAE rend la modélisation vidéo haute résolution accessible au modèle de diffusion suivant.
Rejoignez notre newsletter
Recevez gratuitement les derniers conseils, tendances et offres.
Comment exécuter Wan 2.1 sur votre propre ordinateur
Prêt à essayer Wan 2.1 vous-même ? Voici comment commencer :
Prérequis système
Python 3.8+
PyTorch ≥2.4.0 avec support CUDA
GPU NVIDIA (8 Go+ de VRAM pour le modèle 1.3B, 16-24 Go pour les modèles 14B)
Bibliothèques additionnelles du dépôt
Étapes d’installation
Clonez le dépôt et installez les dépendances :
git clone https://github.com/Wan-Video/Wan2.1.git
cd Wan2.1
pip install -r requirements.txt
python generate.py --task t2v-14B --size 1280*720 \
--ckpt_dir ./Wan2.1-T2V-14B \
--prompt "Un skyline futuriste au coucher du soleil, avec des voitures volantes filant dans le ciel."
Conseils de performance
Pour les machines avec moins de mémoire GPU, essayez le modèle t2v-1.3B plus léger
Utilisez les options --offload_model True --t5_cpu pour déporter une partie du modèle sur le CPU
Contrôlez le ratio d’aspect avec le paramètre --size (ex. 832*480 pour du 16:9 480p)
Wan 2.1 propose l’extension d’instruction et un « mode inspiration » via des options supplémentaires
À titre indicatif, une RTX 4090 génère une vidéo 480p de 5 secondes en environ 4 minutes. Les configurations multi-GPU et diverses optimisations de performance (FSDP, quantification, etc.) sont prises en charge pour un usage à grande échelle.
Pourquoi Wan 2.1 est important pour l’avenir de la vidéo IA
Véritable moteur open source défiant les géants de la génération vidéo par IA, Wan 2.1 marque un tournant en matière d’accessibilité. Sa nature libre et ouverte permet à toute personne disposant d’un GPU correct d’explorer la génération vidéo de pointe, sans frais d’abonnement ni coûts d’API.
Pour les développeurs, la licence open source permet la personnalisation et l’amélioration du modèle. Les chercheurs peuvent étendre ses capacités, tandis que les créatifs peuvent prototyper rapidement et efficacement du contenu vidéo.
À l’ère où les modèles IA propriétaires sont de plus en plus verrouillés derrière des paywalls, Wan 2.1 démontre que la performance de pointe peut être démocratisée et partagée avec la communauté au sens large.
Questions fréquemment posées
Qu’est-ce que Wan 2.1xa0?
Wan 2.1 est un modèle de génération vidéo par IA entièrement open source développé par le Tongyi Lab d’Alibaba, capable de créer des vidéos de haute qualité à partir de textes, d’images ou de vidéos existantes. Il est gratuit, prend en charge plusieurs tâches et fonctionne efficacement sur des GPU grand public.
Quelles sont les fonctionnalités qui distinguent Wan 2.1xa0?
Wan 2.1 prend en charge la génération vidéo multitâche (texte en vidéo, image en vidéo, montage vidéo, etc.), le rendu de texte multilingue dans les vidéos, une grande efficacité grâce à son VAE vidéo 3D causal, et surpasse de nombreux modèles commerciaux et open source dans les benchmarks.
Comment puis-je exécuter Wan 2.1 sur mon propre ordinateurxa0?
Vous avez besoin de Python 3.8+, PyTorch 2.4.0+ avec CUDA et d’un GPU NVIDIA (8 Go+ de VRAM pour le petit modèle, 16-24 Go pour le grand modèle). Clonez le dépôt GitHub, installez les dépendances, téléchargez les poids du modèle et utilisez les scripts fournis pour générer des vidéos localement.
Pourquoi Wan 2.1 est-il important pour la génération vidéo par IAxa0?
Wan 2.1 démocratise l’accès à la génération vidéo de pointe en étant open source et gratuit, permettant aux développeurs, chercheurs et créatifs d’expérimenter et d’innover sans barrières payantes ni restrictions propriétaires.
Comment Wan 2.1 se compare-t-il à des modèles comme Sora ou Runway Gen-2xa0?
Contrairement aux alternatives propriétaires comme Sora ou Runway Gen-2, Wan 2.1 est entièrement open source et peut être exécuté localement. Il surpasse généralement les précédents modèles open source et égale ou dépasse de nombreuses solutions commerciales sur les benchmarks de qualité.
Arshia est ingénieure en workflows d'IA chez FlowHunt. Avec une formation en informatique et une passion pour l’IA, elle se spécialise dans la création de workflows efficaces intégrant des outils d'IA aux tâches quotidiennes, afin d’accroître la productivité et la créativité.
Arshia Kahani
Ingénieure en workflows d'IA
Essayez FlowHunt et créez des solutions IA
Commencez à créer vos propres outils IA et workflows de génération vidéo avec FlowHunt ou planifiez une démo pour voir la plateforme en action.
Comment transformer la création de contenu avec la génération vidéo Wan 2.2 & 2.5 ?
FlowHunt prend désormais en charge les modèles de génération vidéo Wan 2.2 et 2.5 pour le texte en vidéo, l'image en vidéo, le remplacement de persona et l'anim...
Mise à jour d'octobre 2025 : de puissants nouveaux modèles IA pour la vidéo et l'image
La mise à jour d'octobre 2025 de FlowHunt apporte les modèles révolutionnaires Wan 2.2 et 2.5 pour la génération de vidéos à partir de texte, d'image ou d'anima...
Sora 2 : Génération vidéo IA pour les créateurs de contenu
Découvrez les capacités révolutionnaires de Sora 2 en génération vidéo par IA, de la reconstitution réaliste de personnages à la simulation physique, et voyez c...
19 min de lecture
AI
Video Generation
+3
Consentement aux Cookies Nous utilisons des cookies pour améliorer votre expérience de navigation et analyser notre trafic. See our privacy policy.