Schedules
The Schedules feature in FlowHunt lets you periodically crawl domains and YouTube channels, keeping your chatbots and flows up-to-date with the latest informati...
3 min read
AI
Schedules
+4
Learn how to set up automated schedules for crawling websites, sitemaps, domains, and YouTube channels to keep your AI Agent knowledge base up-to-date.
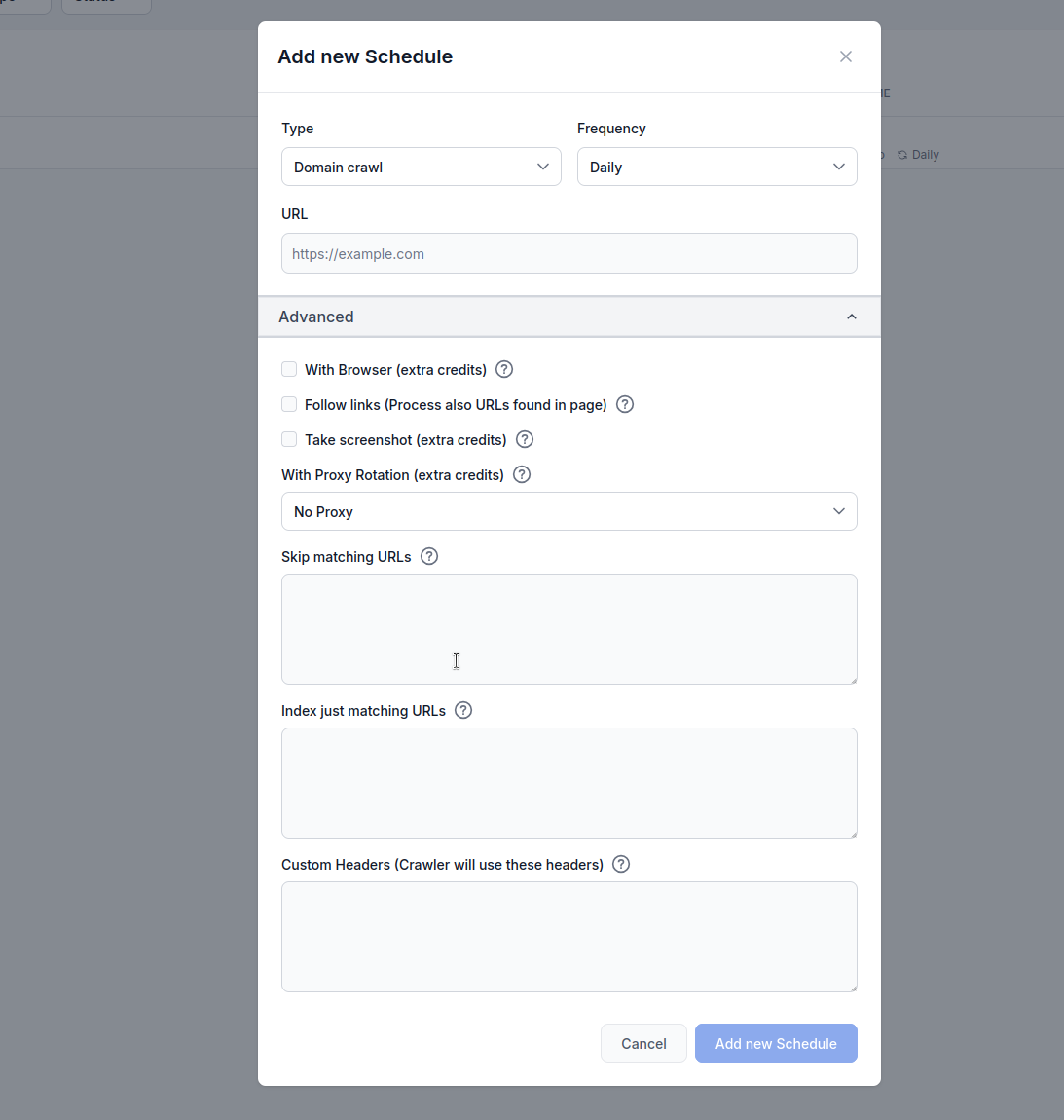
FlowHunt’s Schedule feature allows you to automate the crawling and indexing of websites, sitemaps, domains, and YouTube channels. This ensures your AI Agent’s knowledge base stays current with fresh content without manual intervention.
Automated crawling:
Set up recurring crawls that run daily, weekly, monthly, or yearly to keep your knowledge base updated.
Multiple crawl types:
Choose from Domain crawl, Sitemap crawl, URL crawl, or YouTube channel crawl based on your content source.
Advanced options:
Configure browser rendering, link following, screenshots, proxy rotation, and URL filtering for optimal results.
Type: Choose your crawl method:
Frequency: Set how often the crawl runs:
URL: Enter the target URL, domain, or YouTube channel to crawl
With Browser (extra credits): Enable when crawling JavaScript-heavy websites that require full browser rendering. This option is slower and more expensive but necessary for sites that load content dynamically.
Follow links (extra credits): Process additional URLs found within pages. Useful when sitemaps don’t contain all URLs, but can consume significant credits as it crawls discovered links.
Take screenshot (extra credits): Capture visual screenshots during crawling. Helpful for websites without og:images or those requiring visual context for AI processing.
With Proxy Rotation (extra credits): Rotate IP addresses for each request to avoid detection by Web Application Firewalls (WAF) or anti-bot systems.
Skip matching URLs: Enter strings (one per line) to exclude URLs containing these patterns from crawling. Example:
/admin/
/login
.pdf
This example explains what happens when you use FlowHunt’s Schedule feature to crawl the flowhunt.io domain while setting /blog as a matching URL to skip in the URL filtering settings.
Configuration Settings
flowhunt.io/blogWhat Happens
Crawl Initiation:
flowhunt.io, targeting all accessible pages on the domain (e.g., flowhunt.io, flowhunt.io/features, flowhunt.io/pricing, etc.).URL Filtering Applied:
/blog./blog (e.g., flowhunt.io/blog, flowhunt.io/blog/post1, flowhunt.io/blog/category) is excluded from the crawl.flowhunt.io/about, flowhunt.io/contact, or flowhunt.io/docs, are crawled as they don’t match the /blog pattern.Crawl Execution:
flowhunt.io, indexing their content for your AI Agent’s knowledge base.Outcome:
flowhunt.io, excluding anything under the /blog path./blog) without manual intervention.Index just matching URLs: Enter strings (one per line) to only crawl URLs containing these patterns. Example:
/blog/
/articles/
/knowledge/
Configuration Settings
flowhunt.io/blog/
/articles/
/knowledge/
Crawl Initiation:
flowhunt.io, targeting all accessible pages on the domain (e.g., flowhunt.io, flowhunt.io/blog, flowhunt.io/articles, etc.).URL Filtering Applied:
/blog/, /articles/, and /knowledge/.flowhunt.io/blog/post1, flowhunt.io/articles/news, flowhunt.io/knowledge/guide) are included in the crawl.flowhunt.io/about, flowhunt.io/pricing, or flowhunt.io/contact, are excluded because they don’t match the specified patterns.Crawl Execution:
/blog/, /articles/, or /knowledge/, indexing their content for your AI Agent’s knowledge base.Outcome:
flowhunt.io pages under the /blog/, /articles/, and /knowledge/ paths.Custom Headers:
Add custom HTTP headers for crawling requests. Format as HEADER=Value (one per line):
This feature is highly useful for tailoring crawls to specific website requirements. By enabling custom headers, users can authenticate requests to access restricted content, mimic specific browser behaviors, or comply with a website’s API or access policies. For example, setting an Authorization header can grant access to protected pages, while a custom User-Agent can help avoid bot detection or ensure compatibility with sites that restrict certain crawlers. This flexibility ensures more accurate and comprehensive data collection, making it easier to index relevant content for an AI Agent’s knowledge base while adhering to a website’s security or access protocols.
MYHEADER=Any value
Authorization=Bearer token123
User-Agent=Custom crawler
Start your free trial today and see results within days.
Navigate to Schedules in your FlowHunt dashboard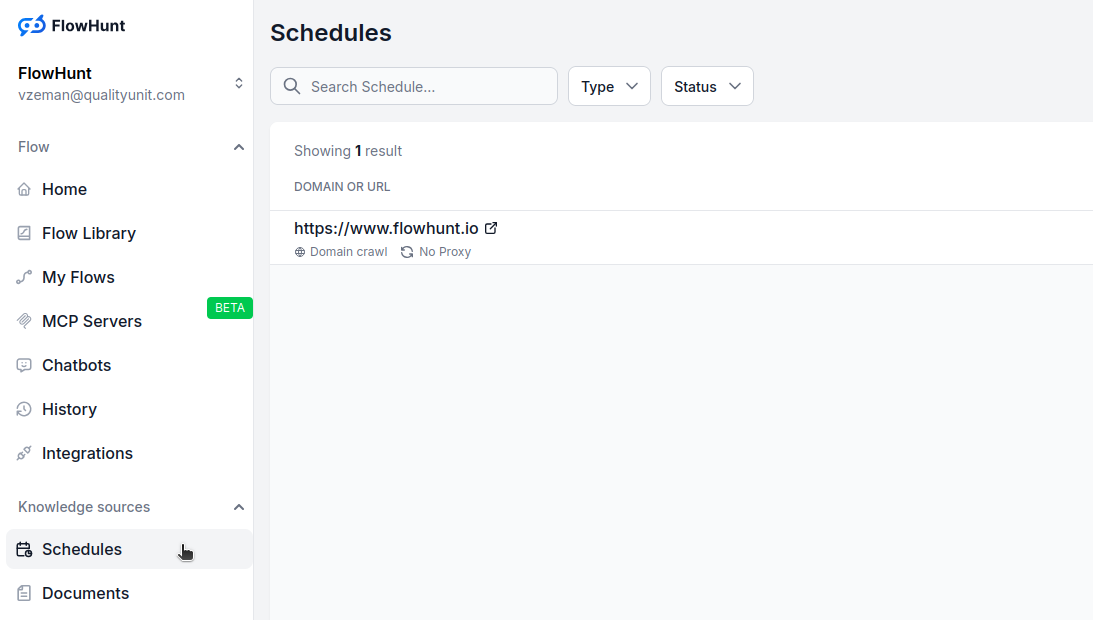
Click “Add new Schedule”
Configure basic settings:
Expand Advanced options if needed:
Click “Add new Schedule” to activate
For Most Websites:
For JavaScript-Heavy Sites:
For Large Sites:
For E-commerce or Dynamic Content:
Get latest tips, trends, and deals for free.
Advanced features consume additional credits:
Monitor your credit usage and adjust schedules based on your needs and budget.
Crawl Failures:
Too Many/Few Pages:
Missing Content:
The Schedules feature in FlowHunt lets you periodically crawl domains and YouTube channels, keeping your chatbots and flows up-to-date with the latest informati...

Learn how to use AI agents with FlowHunt to extract key points and summaries from YouTube videos. Discover step-by-step instructions to automate content extract...

Learn how to automatically generate comprehensive, SEO-optimized glossary pages using AI agents and workflow automation in FlowHunt. Discover the complete proce...