LG EXAONE Deep kontra DeepSeek R1: Porównanie modeli rozumowania AI
Dogłębna analiza modelu rozumowania EXAONE Deep 32B firmy LG, testowanego w porównaniu z DeepSeek R1 i QwQ Alibaby, badająca deklaracje dotyczące wydajności i rzeczywiste zdolności rozumowania.
AI Models
LLM Testing
Model Comparison
Reasoning Models
AI Research
Rynek modeli rozumowania sztucznej inteligencji staje się coraz bardziej konkurencyjny, a wiele organizacji deklaruje przełomowe wyniki w rozwiązywaniu złożonych zadań matematycznych i logicznych. Najnowsza premiera EXAONE Deep firmy LG — modelu rozumowania posiadającego 32 miliardy parametrów — wywołała spore zainteresowanie dzięki deklaracjom przewyższania uznanych konkurentów, takich jak DeepSeek R1. Jednak testy praktyczne ujawniają bardziej złożony obraz, niż sugerują materiały marketingowe. W tym artykule przeprowadzamy dogłębną analizę rzeczywistej wydajności EXAONE Deep na tle innych wiodących modeli rozumowania, przyglądając się rozbieżnościom między deklarowanymi benchmarkami a praktycznym działaniem. Poprzez testy praktyczne i szczegółowe porównania sprawdzimy, do czego faktycznie są zdolne te modele, jak radzą sobie z trudnymi zadaniami rozumowania i co to oznacza dla organizacji rozważających wdrożenie tych narzędzi w produkcji.
Zrozumienie modeli rozumowania AI i dekodowania w czasie testu
Pojawienie się modeli rozumowania oznacza fundamentalną zmianę w sposobie, w jaki sztuczna inteligencja podchodzi do rozwiązywania złożonych problemów. W przeciwieństwie do tradycyjnych modeli językowych, które generują odpowiedzi w jednym kroku, modele rozumowania stosują technikę zwaną dekodowaniem w czasie testu, przydzielając podczas wnioskowania znacznie większe zasoby obliczeniowe, by krok po kroku analizować problem. To podejście przypomina ludzkie rozumowanie, gdzie często musimy rozważyć kilka aspektów problemu, zanim znajdziemy rozwiązanie. Koncepcja ta zdobyła rozgłos wraz z modelem o1 OpenAI i została później zaadaptowana przez wiele firm, w tym DeepSeek, Alibabę i obecnie LG. Modele te generują tzw. sekwencje tokenów “rozumowania” lub “myślenia”, których użytkownik zwykle nie widzi w finalnej odpowiedzi, ale które odzwierciedlają wewnętrzny proces rozumowania modelu. Te tokeny są kluczowe, ponieważ pozwalają modelowi eksplorować różne ścieżki rozwiązania, wychwytywać błędy i dopracowywać podejście przed przedstawieniem ostatecznej odpowiedzi. Jest to szczególnie istotne przy zadaniach matematycznych, logicznych i złożonych scenariuszach wieloetapowych, gdzie pojedyncze przejście przez problem może prowadzić do pominięcia istotnych szczegółów lub błędnych wniosków.
Gotowy na rozwój swojej firmy?
Rozpocznij bezpłatny okres próbny już dziś i zobacz rezultaty w ciągu kilku dni.
Dlaczego modele rozumowania są ważne dla wdrożeń AI w przedsiębiorstwach
Dla firm wdrażających systemy AI modele rozumowania oznaczają znaczący postęp w zakresie niezawodności i trafności przy rozwiązywaniu złożonych zadań. Tradycyjne modele językowe często mają trudności z wieloetapowymi problemami matematycznymi, dedukcją logiczną czy sytuacjami wymagającymi starannej analizy ograniczeń i warunków. Modele rozumowania rozwiązują te ograniczenia, pokazując krok po kroku swój tok rozumowania, co zapewnia przejrzystość procesu dochodzenia do odpowiedzi. Ta transparentność jest szczególnie ważna w firmach, gdzie decyzje oparte na rekomendacjach AI muszą być audytowalne i wyjaśnialne. Minusem jest jednak koszt obliczeniowy i opóźnienie — ponieważ modele rozumowania generują wiele tokenów rozumowania przed ostateczną odpowiedzią, wymagają więcej mocy obliczeniowej i czasu niż standardowe modele językowe. Dlatego wybór modelu jest kluczowy — firmy muszą brać pod uwagę nie tylko wyniki benchmarków, ale też rzeczywistą wydajność w swoich przypadkach użycia. Rosnąca oferta modeli rozumowania różnych producentów, z których każdy deklaruje przewagę, sprawia, że niezależne testy i porównania są niezbędne do podejmowania świadomych decyzji wdrożeniowych.
LG EXAONE Deep: deklaracje kontra rzeczywistość
Wejście LG na rynek modeli rozumowania z EXAONE Deep wzbudziło spore zainteresowanie, szczególnie że firma dysponuje dużym zapleczem badawczym, a model ma stosunkowo niewielki rozmiar (32 miliardy parametrów). W materiałach marketingowych LG prezentuje imponujące wyniki: EXAONE Deep miał osiągnąć 90% trafności na konkursie AIME (American Invitational Mathematics Examination) przy zaledwie 64 próbach oraz 95% na zadaniach MATH-500. Gdyby liczby te były prawdziwe, oznaczałoby to wydajność na poziomie lub przewyższającym DeepSeek R1 i QwQ Alibaby. Firma wypuściła też kilka wersji modelu o różnych rozmiarach, w tym wariant 2,4 miliarda parametrów zaprojektowany jako model roboczy w dekodowaniu spekulacyjnym — technice polegającej na wykorzystaniu mniejszego modelu do przewidywania tokenów, jakie wygeneruje większy model, co może przyspieszyć wnioskowanie. Jednak w praktycznych testach na standardowych problemach rozumowania EXAONE Deep wykazał niepokojące zachowania, sprzeczne z deklaracjami benchmarków. Model miał skłonność do zapętlania się w rozważaniach bez dojścia do logicznych wniosków, generując tysiące powtarzalnych lub pozbawionych sensu tokenów zamiast produktywnego rozumowania. Zachowanie to może wskazywać na problemy z procesem treningu modelu, metodologią oceny benchmarków lub sposobem obsługi określonych typów promptów.
Dołącz do naszego newslettera
Otrzymuj najnowsze wskazówki, trendy i oferty za darmo.
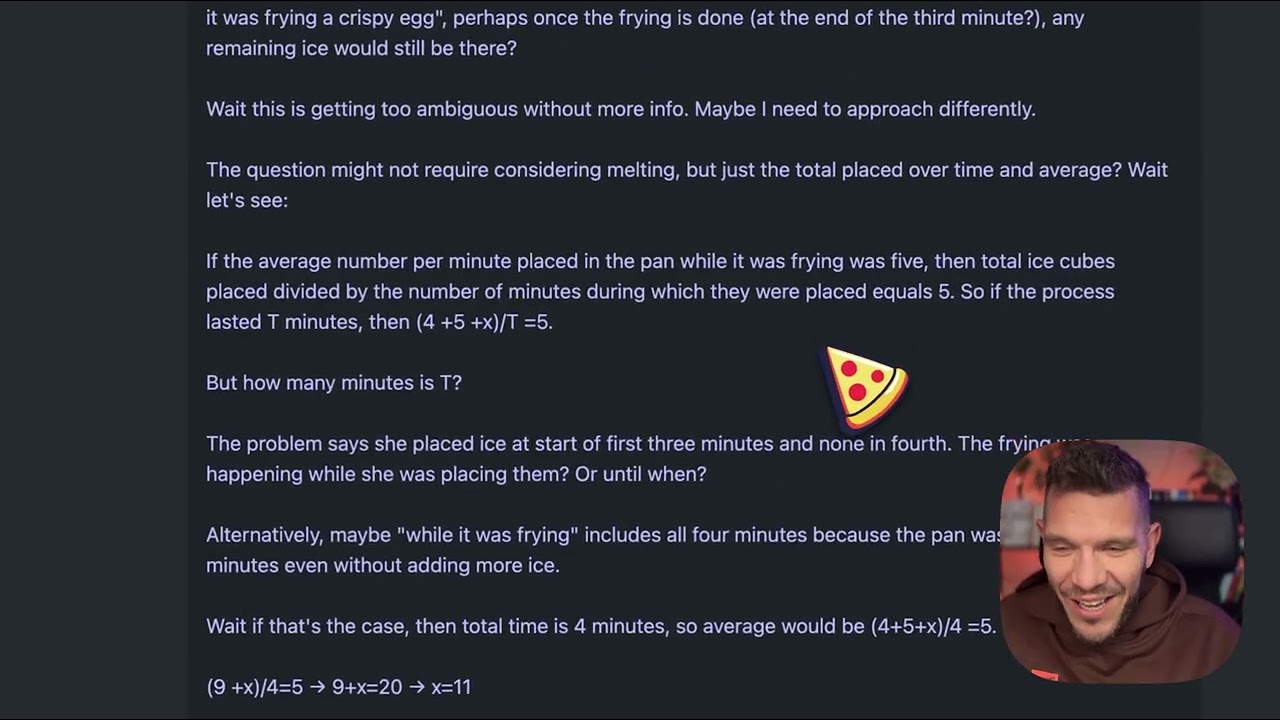
Problem z kostkami lodu: kluczowy przypadek testowy
Aby zrozumieć praktyczne różnice między modelami rozumowania, przyjrzyjmy się z pozoru prostemu zadaniu, które stało się standardowym testem jakości tych modeli: “Beth wkłada kilka całych kostek lodu do patelni. Po minucie jest 20 kostek lodu. Po dwóch minutach jest ich 10. Po trzech minutach jest 0. Ile całych kostek lodu znajduje się na patelni na końcu trzeciej minuty?”. Poprawna odpowiedź to zero, ponieważ pytanie wprost dotyczy całych kostek lodu po trzech minutach, a w treści zadania jasno podano, że jest ich wtedy zero. Jednak problem ten został zaprojektowany tak, by zmylić modele, które nadmiernie go analizują lub gubią się w narracji o topnieniu lodu. Niektóre modele mogą próbować obliczać tempo topnienia, co oddali je od właściwej odpowiedzi. Gdy EXAONE Deep został poddany temu testowi, wygenerował ok. 5 000 tokenów rozumowania, nie dochodząc do sensownego wniosku. Proces rozumowania modelu wymknął się spod kontroli — tekst stawał się coraz mniej zrozumiały i nie prezentował logicznego toku rozumowania. Wygenerowane tokeny były fragmentaryczne, nie tworzyły spójnych myśli, a model nigdy nie zaprezentował jasnej drogi rozumowania ani ostatecznej odpowiedzi. To wyraźnie kontrastuje z tym, jak zadanie powinno zostać rozwiązane — model rozumowania powinien rozpoznać haczyk, przeanalizować problem i sprawnie dojść do odpowiedzi.
Porównanie: EXAONE Deep kontra DeepSeek R1 kontra QwQ
Ten sam problem z kostkami lodu został przetestowany na DeepSeek R1 oraz QwQ Alibaby i oba modele wykazały zdecydowanie lepsze wyniki. DeepSeek R1 przejrzyście przeprowadził proces rozumowania, metodycznie rozwiązał problem i podał poprawną odpowiedź: zero. Sposób rozumowania modelu był jasny i logiczny — widać było analizę, rozpoznanie pułapki i dojście do właściwego wniosku. QwQ również spisał się bardzo dobrze, choć także wygenerował dość rozbudowany ciąg rozumowania. Co ciekawe, QwQ początkowo rozważał, czy kostki lodu potrzebują czasu na stopnienie i czy problem dotyczy fizyki czy matematyki, ale ostatecznie doszedł do poprawnej odpowiedzi. Kluczowa różnica polegała na tym, że oba modele przez cały czas prezentowały spójne rozumowanie, nawet analizując różne aspekty zagadnienia. Potrafiły rozpoznać moment, w którym mają już wystarczające informacje, by udzielić odpowiedzi. EXAONE Deep tymczasem nigdy do tego nie doszedł — generował kolejne tokeny bez wyraźnego celu, nie prezentując logicznej progresji. Sugeruje to fundamentalne problemy z obsługą zadań rozumowania przez model, mimo imponujących deklaracji benchmarkowych.
Dekodowanie spekulacyjne i optymalizacja modeli
Ciekawym technicznym aspektem premiery EXAONE Deep jest obecność kilku wersji modelu zaprojektowanych do współpracy w trybie dekodowania spekulacyjnego. Wersja 2,4 miliarda parametrów może służyć jako model roboczy, przewidując tokeny głównego modelu 32-miliardowego. Gdy przewidywania zgadzają się z generacją głównego modelu, system może pominąć obliczenia głównego modelu i użyć przewidywania roboczego, co znacząco przyspiesza wnioskowanie. To zaawansowana technika optymalizacyjna, pozwalająca zredukować opóźnienia i zużycie zasobów. W testach implementacja dekodowania spekulacyjnego pokazywała zielone tokeny oznaczające skuteczne przewidywania robocze, co sugeruje, że technika działa poprawnie. Jednak ta optymalizacja nie rozwiązuje podstawowego problemu jakości rozumowania głównego modelu — szybsze wnioskowanie oparte na błędnych rozważaniach nadal pozostaje błędnym rozumowaniem. Obecność tej funkcji rodzi też pytania, czy wyniki benchmarków LG nie zostały osiągnięte przy użyciu konfiguracji lub technik, które nie znajdują odzwierciedlenia w typowych zastosowaniach produkcyjnych.
Podejście FlowHunt do oceny i automatyzacji modeli AI
Dla organizacji mających trudności z oceną i porównywaniem wielu modeli AI, FlowHunt oferuje kompleksową platformę automatyzującą proces testowania i benchmarkingu. Zamiast ręcznie uruchamiać testy na różnych modelach i porównywać wyniki, FlowHunt pozwala zespołom ustawić zautomatyzowane workflow, które systematycznie oceniają wydajność modeli w wielu wymiarach. Jest to szczególnie cenne przy porównywaniu modeli rozumowania, gdzie wyniki mogą się znacznie różnić w zależności od typu zadania, złożoności i sformułowania promptu. Możliwości automatyzacji FlowHunt pozwalają testować modele na ustandaryzowanych zestawach problemów, śledzić metryki wydajności w czasie i generować szczegółowe raporty porównawcze. Platforma integruje się z wieloma dostawcami modeli i API, dzięki czemu można oceniać modele różnych firm w jednym workflow. Dla zespołów rozważających wdrożenie modeli takich jak EXAONE Deep, DeepSeek R1 czy QwQ, FlowHunt zapewnia infrastrukturę do podejmowania decyzji opartych na rzeczywistych wynikach, a nie tylko deklaracjach producentów. Automatyzacja powtarzalnych testów pozwala także inżynierom skupić się na integracji i optymalizacji zamiast ręcznego benchmarkowania.
Znaczenie niezależnych testów i weryfikacji
Rozbieżność między deklarowaną wydajnością EXAONE Deep a rzeczywistym zachowaniem modelu podczas testów to kluczowa lekcja dla wdrażania AI: wyniki producenta zawsze należy weryfikować niezależnie. Wyniki benchmarków mogą być zależne od wielu czynników, takich jak użyty zestaw testowy, metodologia oceny, konfiguracja sprzętowa czy parametry wnioskowania. Model może uzyskiwać świetne wyniki w jednym benchmarku, a słabo radzić sobie z innymi zadaniami lub w rzeczywistych scenariuszach. Dlatego organizacje takie jak Weights & Biases czy niezależni badacze odgrywają ważną rolę w ekosystemie AI — zapewniają bezstronne testy i analizy, które pomagają społeczności zrozumieć realne możliwości modeli. Przy wyborze modeli rozumowania do wdrożeń produkcyjnych firmy powinny przeprowadzać własne testy na reprezentatywnych zadaniach ze swojej dziedziny. Model świetny w matematyce może mieć trudności z logiką lub generacją kodu. Problem z kostkami lodu, choć pozornie prosty, jest dobrym testem diagnostycznym, pokazującym, czy model radzi sobie z podchwytliwymi pytaniami i nie popada w nadmierne rozważania. Modele, które oblewają takie zadania, prawdopodobnie będą mieć problemy także z bardziej złożonymi przypadkami rozumowania.
Problemy techniczne i potencjalne przyczyny
Wydłużone pętle rozumowania zaobserwowane podczas testów EXAONE Deep mogą wynikać z kilku czynników. Jednym z nich jest to, że proces trenowania modelu nie nauczył go, kiedy należy zakończyć rozumowanie i podać odpowiedź. Modele rozumowania wymagają starannego dostrojenia podczas treningu, by znaleźć balans między rozważaniami a ryzykiem nadmiernego generowania nieproduktywnych tokenów. Jeśli podczas treningu nie było wystarczająco dużo przykładów kończenia rozumowania, model może generować tokeny aż do osiągnięcia limitu. Inną przyczyną mogą być problemy z obsługą promptów, szczególnie w interpretacji określonych typów pytań lub instrukcji. Niektóre modele są wrażliwe na konkretne sformułowania i mogą zachowywać się różnie w zależności od brzmienia pytania. Fakt, że EXAONE Deep generował niespójne sekwencje tokenów, sugeruje, że model mógł wpadać w stan, w którym generuje tokeny bez sensownej treści semantycznej — co może wskazywać na problemy z mechanizmem uwagi lub logiką przewidywania tokenów. Trzecią możliwą przyczyną jest to, że metodologia oceny benchmarku wykorzystywała inną konfigurację lub strategię promptowania niż w testach praktycznych, co prowadziło do znacznych rozbieżności między deklarowaną a rzeczywistą wydajnością.
Konsekwencje dla rynku modeli rozumowania
Problemy wydajnościowe EXAONE Deep mają szersze konsekwencje dla rynku modeli rozumowania. Wraz z pojawianiem się coraz większej liczby modeli rynek ryzykuje nasycenie rozwiązaniami o imponujących deklaracjach, ale wątpliwej wydajności w rzeczywistości. Utrudnia to wybór odpowiednich modeli do zastosowań produkcyjnych. Rozwiązaniem jest większy nacisk na niezależne testy, ustandaryzowane metody oceny i transparentność ograniczeń modeli. Rynek modeli rozumowania skorzystałby na branżowych standardach ewaluacji i porównywania tych rozwiązań, podobnie jak ma to miejsce w przypadku innych benchmarków AI. Dodatkowo firmy powinny zachować ostrożność wobec modeli, które deklarują znacznie lepsze wyniki od uznanych konkurentów, zwłaszcza gdy przewaga ta wydaje się nieadekwatna do architektury lub podejścia treningowego. DeepSeek R1 i QwQ wykazały stabilne wyniki w licznych scenariuszach testowych, co buduje zaufanie do ich możliwości. Niekonsekwentna wydajność EXAONE Deep — świetne deklaracje, słabe wyniki praktyczne — sugeruje problemy albo samego modelu, albo sposobu przeprowadzania benchmarków.
Zautomatyzuj swój workflow z FlowHunt
Zobacz, jak FlowHunt automatyzuje tworzenie treści AI i workflow SEO — od badań i generowania treści po publikację i analitykę — wszystko w jednym miejscu.
Firmy rozważające wdrożenie modeli rozumowania powinny stosować uporządkowany proces ewaluacji. Po pierwsze, należy przygotować reprezentatywny zestaw testowy obejmujący problemy z konkretnej domeny lub zastosowania. Ogólne benchmarki nie muszą odzwierciedlać wydajności modelu w realnych zadaniach. Po drugie, należy testować wiele modeli na tych samych zadaniach, aby umożliwić bezpośrednie porównanie. Wymaga to ustandaryzowania środowiska testowego: sprzętu, parametrów wnioskowania i formułowania promptów. Po trzecie, oceniaj nie tylko trafność, ale też efektywność, np. opóźnienie i liczbę generowanych tokenów. Model, który generuje poprawne odpowiedzi, ale wymaga 10 000 tokenów rozumowania, może być niepraktyczny w zastosowaniach wymagających odpowiedzi w czasie rzeczywistym. Po czwarte, analizuj nie tylko ostateczną odpowiedź, ale też tok rozumowania modelu. Model, który dochodzi do poprawnej odpowiedzi poprzez błędne rozważania, może zawieść przy podobnych problemach o innych parametrach. Po piąte, testuj przypadki brzegowe i pytania podchwytliwe, by zobaczyć, jak model radzi sobie z sytuacjami zaprojektowanymi do jego zmylenia. Na końcu należy uwzględnić całkowity koszt posiadania — nie tylko licencję lub koszt API, ale także zasoby obliczeniowe potrzebne do działania i nakład pracy inżynierskiej do integracji.
Rola wielkości modelu i efektywności
32 miliardy parametrów EXAONE Deep to wyraźnie mniej niż niektóre konkurencyjne modele rozumowania, co rodzi pytania, czy problemy modelu wynikają z niewystarczającej pojemności. Jednak sama wielkość modelu nie determinuje zdolności rozumowania. QwQ, który również działa w podobnym zakresie parametrów, wykazuje wysoką skuteczność rozumowania. Sugeruje to, że problemy EXAONE Deep wynikają raczej z metodologii uczenia, konstrukcji architektury lub konfiguracji wnioskowania, a nie z ograniczeń rozmiaru modelu. Obecność modelu roboczego 2,4 mld parametrów w pakiecie EXAONE Deep pokazuje, że LG myśli o efektywności, co jest godne pochwały. Jednak efektywność ma wartość tylko wtedy, gdy model zapewnia poprawne wyniki — szybka zła odpowiedź jest gorsza niż wolna dobra odpowiedź w większości zastosowań produkcyjnych. Rynek modeli rozumowania będzie prawdopodobnie coraz większy nacisk kładł na efektywność, ale ta optymalizacja nie może odbywać się kosztem jakości rozumowania.
Przyszłość modeli rozumowania
Rynek modeli rozumowania jest nadal na wczesnym etapie rozwoju i w najbliższych miesiącach oraz latach można się spodziewać znaczących zmian. Wraz z premierą kolejnych modeli i coraz większą liczbą niezależnych testów rynek będzie się konsolidował wokół rozwiązań oferujących stabilną, powtarzalną wydajność. DeepSeek i Alibaba zyskały zaufanie konsekwentnymi wynikami, a nowi gracze, jak LG, będą musieli rozwiązać dostrzeżone problemy z wydajnością, by zyskać akceptację rynku. Można spodziewać się dalszych innowacji w metodach trenowania i oceny modeli rozumowania. Obecne podejście z generowaniem rozbudowanych tokenów rozumowania jest skuteczne, ale kosztowne obliczeniowo. Przyszłe modele mogą wypracować bardziej efektywne mechanizmy rozumowania, osiągając podobną trafność przy mniejszej liczbie tokenów. Pojawi się też zapewne większa specjalizacja: modele rozumowania dedykowane do matematyki, generacji kodu czy logiki. Integracja modeli rozumowania z innymi technikami AI, np. generacją wspomaganą wyszukiwaniem czy wykorzystaniem narzędzi, dodatkowo poszerzy ich możliwości i zastosowania.
Podsumowanie
EXAONE Deep od LG to ambitna próba wejścia na rynek modeli rozumowania, jednak testy praktyczne pokazują znaczne rozbieżności między deklarowaną a rzeczywistą wydajnością modelu. Choć wyniki benchmarków sugerują konkurencyjność wobec DeepSeek R1 i QwQ Alibaby, praktyczne testy na standardowych zadaniach rozumowania pokazują, że EXAONE Deep ma problemy nawet z prostymi zadaniami — generuje nadmiarowe tokeny, nie dochodząc do spójnych wniosków. DeepSeek R1 i QwQ wykazały zdecydowanie lepszą wydajność w tych samych zadaniach, dochodząc do poprawnych odpowiedzi poprzez jasny, logiczny tok rozumowania. Dla organizacji oceniających modele rozumowania pod kątem wdrożeń produkcyjnych analiza ta podkreśla kluczowe znaczenie niezależnych testów i weryfikacji. Wyniki benchmarków producenta powinny być traktowane jako punkt wyjścia do własnej oceny, nie jako ostateczna miara możliwości modelu. Rynek modeli rozumowania zyska na większej transparentności, standaryzacji metod ewaluacji i kontynuacji niezależnych testów prowadzonych przez środowisko badawcze. Wraz z dojrzewaniem tej technologii firmy, które zainwestują w rzetelny proces oceny i porównania modeli, będą w najlepszej pozycji, by wdrażać rozwiązania faktycznie dostarczające wartość dla ich zastosowań.
Najczęściej zadawane pytania
Czym jest EXAONE Deep i czym różni się od innych modeli rozumowania?
EXAONE Deep to 32-miliardowy model rozumowania opracowany przez LG, wykorzystujący dekodowanie w czasie testu do rozwiązywania złożonych problemów. W przeciwieństwie do standardowych modeli językowych, podczas wnioskowania przydziela zasoby obliczeniowe, aby krok po kroku analizować problem, podobnie jak modele DeepSeek R1 i QwQ Alibaby.
Czy EXAONE Deep rzeczywiście przewyższył DeepSeek R1 w praktycznych testach?
W praktycznych testach na zadaniach rozumowania, takich jak problem z kostkami lodu, EXAONE Deep wykazał poważne problemy z nadmiernym rozmyślaniem i generowaniem zbyt wielu tokenów bez osiągnięcia logicznych wniosków. DeepSeek R1 i QwQ radziły sobie lepiej, szybciej i trafniej dochodząc do poprawnych odpowiedzi.
Czym jest dekodowanie w czasie testu i dlaczego jest ważne dla modeli rozumowania?
Dekodowanie w czasie testu to technika, w której modele AI podczas wnioskowania przydzielają więcej zasobów obliczeniowych, aby przeanalizować złożone problemy. Pozwala to modelom pokazać proces rozumowania i dochodzić do trafniejszych odpowiedzi, choć wymaga precyzyjnego dostrojenia, by uniknąć 'przemyślenia' problemu.
Jak FlowHunt pomaga w ocenie i testowaniu modeli AI?
FlowHunt automatyzuje proces testowania, porównywania i oceny wielu modeli AI, umożliwiając zespołom systematyczne benchmarkowanie wydajności, śledzenie metryk i podejmowanie decyzji o wdrożeniu najlepszego modelu do konkretnych zastosowań.
Arshia jest Inżynierką Przepływów Pracy AI w FlowHunt. Z wykształceniem informatycznym i pasją do sztucznej inteligencji, specjalizuje się w tworzeniu wydajnych przepływów pracy, które integrują narzędzia AI z codziennymi zadaniami, zwiększając produktywność i kreatywność.
Arshia Kahani
Inżynierka Przepływów Pracy AI
Automatyzuj testowanie i ocenę modeli AI
Wykorzystaj FlowHunt, aby usprawnić testowanie modeli AI, porównania i monitorowanie wydajności przy inteligentnej automatyzacji.
Gemini 3 Flash: Przełomowy model AI, który pokonuje Pro za ułamek ceny
Odkryj, dlaczego Gemini 3 Flash od Google rewolucjonizuje AI dzięki lepszej wydajności, niższym kosztom i szybszemu działaniu – nawet przewyższając Gemini 3 Pro...
Rozszyfrowanie modeli agentów AI: Ostateczna analiza porównawcza
Poznaj świat modeli agentów AI dzięki kompleksowej analizie 20 najnowocześniejszych systemów. Odkryj, jak myślą, rozumują i realizują różnorodne zadania, a takż...
Porównanie modeli generujących obrazy AI: Qwen, GPT-4 Vision, Seadream, Nano Banana
Kompleksowe porównanie czołowych modeli generowania obrazów AI, w tym Qwen ImageEdit Plus, Nano Banana, GPT Image 1 i Seadream. Dowiedz się, który model najlepi...
15 min czytania
AI
Image Generation
+3
Zgoda na Pliki Cookie Używamy plików cookie, aby poprawić jakość przeglądania i analizować nasz ruch. See our privacy policy.