Wan 2.1: Rewolucja otwartoźródłowej generacji wideo przez AI
Wan 2.1 to potężny, otwartoźródłowy model generowania wideo AI od Alibaba, umożliwiający tworzenie filmów studyjnej jakości z tekstu lub obrazów, dostępny za darmo dla każdego do lokalnego użytku.
AI Video Generation
Open Source
Wan 2.1
Alibaba
Generative AI
Video AI
AI Tools
Wan 2.1 (znany także jako WanX 2.1) to przełomowy, w pełni otwartoźródłowy model generowania wideo AI opracowany przez laboratorium Tongyi firmy Alibaba. W przeciwieństwie do wielu zamkniętych systemów generowania wideo, które wymagają drogich subskrypcji lub dostępu przez API, Wan 2.1 oferuje porównywalną lub lepszą jakość, pozostając całkowicie darmowym i dostępnym dla deweloperów, badaczy i profesjonalistów kreatywnych.
To, co naprawdę wyróżnia Wan 2.1, to połączenie dostępności i wydajności. Mniejszy wariant T2V-1.3B wymaga zaledwie ~8,2 GB pamięci GPU, dzięki czemu jest kompatybilny z większością współczesnych kart konsumenckich. Z kolei większa wersja z 14 miliardami parametrów zapewnia wydajność na światowym poziomie, przewyższając zarówno otwarte alternatywy, jak i wiele modeli komercyjnych w standardowych testach porównawczych.
Kluczowe cechy wyróżniające Wan 2.1
Obsługa wielu zadań
Wan 2.1 nie ogranicza się tylko do generowania wideo z tekstu. Jego wszechstronna architektura wspiera:
Zamianę tekstu na wideo (T2V)
Zamianę obrazu na wideo (I2V)
Edycję wideo na wideo
Generowanie obrazów z tekstu
Generowanie dźwięku z wideo
Ta elastyczność pozwala rozpocząć pracę od promptu tekstowego, pojedynczego obrazu lub nawet istniejącego filmu i przekształcić go według własnej wizji.
Generowanie tekstu w wielu językach
Jako pierwszy model wideo zdolny do renderowania czytelnych napisów po angielsku i chińsku w generowanych filmach, Wan 2.1 otwiera nowe możliwości dla twórców międzynarodowych treści. Funkcja ta jest szczególnie cenna przy dodawaniu napisów lub tekstów scenicznych w filmach wielojęzycznych.
Rewolucyjny Video VAE (Wan-VAE)
Sercem efektywności Wan 2.1 jest jego 3D causal Video Variational Autoencoder. To technologiczne osiągnięcie pozwala na:
Kompresję filmów nawet kilkaset razy
Zachowanie płynności ruchu i szczegółowości obrazu
Obsługę wysokiej rozdzielczości aż do 1080p
Wyjątkowa wydajność i dostępność
Mniejszy model 1.3B wymaga tylko 8,19 GB VRAM i potrafi wygenerować 5-sekundowy film 480p w około 4 minuty na RTX 4090. Pomimo tej efektywności, jakość jego wyników dorównuje lub przewyższa znacznie większe modele, zapewniając idealną równowagę między szybkością a wiernością wizualną.
Wiodące w branży benchmarki i jakość
W publicznych testach Wan 14B uzyskał najwyższy ogólny wynik w testach Wan-Bench, przewyższając konkurentów w:
Jakości ruchu
Stabilności
Precyzji podążania za promptem
Gotowy na rozwój swojej firmy?
Rozpocznij bezpłatny okres próbny już dziś i zobacz rezultaty w ciągu kilku dni.
Jak Wan 2.1 wypada na tle innych modeli generowania wideo
W przeciwieństwie do zamkniętych systemów, takich jak Sora od OpenAI czy Gen-2 od Runway, Wan 2.1 jest dostępny za darmo do lokalnego uruchomienia. Zwykle przewyższa wcześniejsze otwarte modele (jak CogVideo, MAKE-A-VIDEO, czy Pika), a nawet wiele komercyjnych rozwiązań w testach jakości.
Jak podkreślono w niedawnym branżowym przeglądzie, „spośród wielu modeli wideo AI, Wan 2.1 i Sora się wyróżniają” – Wan 2.1 dzięki otwartości i wydajności, Sora zaś dzięki innowacjom własnościowym. W testach społecznościowych użytkownicy zgłaszali, że funkcja image-to-video Wan 2.1 przewyższa konkurentów pod względem klarowności i filmowego charakteru.
Technologia stojąca za Wan 2.1
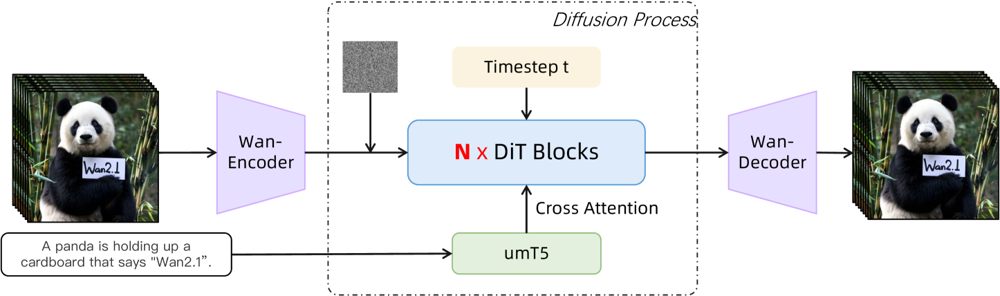
Wan 2.1 opiera się na bazie diffusion-transformer z nowatorskim spatio-temporal VAE. Oto jak działa:
Dane wejściowe (tekst i/lub obraz/wideo) są kodowane do latentnej reprezentacji wideo przez Wan-VAE
Diffusion transformer (oparty na architekturze DiT) iteracyjnie odszumia tę latentną reprezentację
Proces jest prowadzony przez enkoder tekstowy (wielojęzyczny wariant T5 o nazwie umT5)
Na końcu dekoder Wan-VAE rekonstruuje wyjściowe klatki filmowe
Ilustracja: Ogólna architektura Wan 2.1 (przypadek text-to-video). Film (lub obraz) najpierw jest kodowany przez Wan-VAE encoder do postaci latentnej. Ta latentna reprezentacja przechodzi przez N bloki diffusion transformer, które uwzględniają embedding tekstowy (z umT5) przez cross-attention. Na końcu Wan-VAE decoder rekonstruuje klatki wideo. To podejście – „3D causal VAE encoder/decoder otaczający diffusion transformer” (ar5iv.org
) – pozwala na efektywną kompresję danych spatio-temporalnych i wspiera generowanie wysokiej jakości filmów.
Ta innowacyjna architektura — z „3D causal VAE encoder/decoder otaczającym diffusion transformer” — umożliwia wydajną kompresję danych przestrzenno-czasowych i generowanie wysokiej jakości wideo.
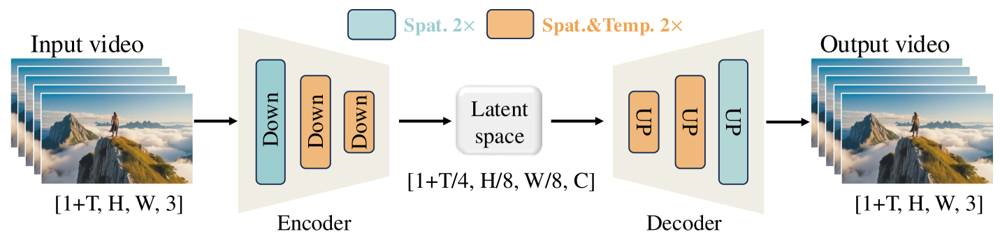
Wan-VAE został zaprojektowany specjalnie do filmów. Kompresuje dane wejściowe nawet 4× czasowo i 8× przestrzennie do zwartej latentnej reprezentacji, zanim zdekompresuje je do pełnego filmu. Zastosowanie konwolucji 3D i warstw przyczynowych (zachowujących czas) zapewnia spójność ruchu w całym generowanym materiale.
Ilustracja: Framework Wan-VAE w Wan 2.1 (encoder-decoder). Enkoder Wan-VAE (po lewej) stosuje szereg warstw down-samplingu („Down”) do wejściowego filmu (kształt [1+T, H, W, 3] klatek), aż osiągnie zwartą latentną reprezentację ([1+T/4, H/8, W/8, C]). Dekoder Wan-VAE (po prawej) symetrycznie upsampluje („UP”) tę latentną reprezentację do oryginalnych klatek. Niebieskie bloki oznaczają kompresję przestrzenną, a pomarańczowe – kompresję przestrzenną i czasową równocześnie (ar5iv.org
). Dzięki kompresji nawet 256× (w ujęciu przestrzenno-czasowym), Wan-VAE umożliwia wydajne modelowanie wysokorozdzielczych filmów dla późniejszego modelu dyfuzyjnego.
Dołącz do naszego newslettera
Otrzymuj najnowsze wskazówki, trendy i oferty za darmo.
Jak uruchomić Wan 2.1 na własnym komputerze
Chcesz wypróbować Wan 2.1 samodzielnie? Oto jak zacząć:
Wymagania systemowe
Python 3.8+
PyTorch ≥2.4.0 z obsługą CUDA
NVIDIA GPU (8GB+ VRAM dla modelu 1.3B, 16–24GB dla modeli 14B)
Dodatkowe biblioteki z repozytorium
Kroki instalacji
Sklonuj repozytorium i zainstaluj zależności:
git clone https://github.com/Wan-Video/Wan2.1.git
cd Wan2.1
pip install -r requirements.txt
python generate.py --task t2v-14B --size 1280*720 \
--ckpt_dir ./Wan2.1-T2V-14B \
--prompt "A futuristic city skyline at sunset, with flying cars zooming overhead."
Wskazówki dotyczące wydajności
W przypadku maszyn z ograniczoną pamięcią GPU użyj lżejszego modelu t2v-1.3B
Użyj flag --offload_model True --t5_cpu, aby część modelu przenieść na CPU
Kontroluj proporcje obrazu parametrem --size (np. 832*480 dla 16:9 480p)
Wan 2.1 oferuje rozszerzanie promptów i „tryb inspiracji” dzięki dodatkowym opcjom
Dla porównania: RTX 4090 generuje 5-sekundowy film 480p w ok. 4 minuty. Wsparcie dla wielu GPU i różne optymalizacje wydajności (FSDP, kwantyzacja itp.) są obsługiwane przy większej skali.
Dlaczego Wan 2.1 jest ważny dla przyszłości wideo AI
Jako otwartoźródłowa siła napędowa rzucająca wyzwanie gigantom generowania wideo przez AI, Wan 2.1 oznacza przełom w dostępności. Jego wolna i otwarta natura sprawia, że każdy z przyzwoitą kartą GPU może eksplorować najnowocześniejsze generowanie wideo bez opłat abonamentowych czy kosztów API.
Dla deweloperów otwarta licencja pozwala dostosowywać i ulepszać model. Naukowcy mogą rozszerzać jego możliwości, a twórcy – szybko i efektywnie prototypować treści wideo.
W czasach, gdy zamknięte modele AI są coraz częściej blokowane za paywallem, Wan 2.1 udowadnia, że wydajność na światowym poziomie można demokratyzować i dzielić z szeroką społecznością.
Najczęściej zadawane pytania
Czym jest Wan 2.1?
Wan 2.1 to w pełni otwartoźródłowy model generowania wideo AI opracowany przez laboratorium Tongyi Alibaba, zdolny do tworzenia wysokiej jakości filmów na podstawie promptów tekstowych, obrazów lub istniejących nagrań. Jest darmowy, obsługuje wiele zadań i działa wydajnie na konsumenckich kartach GPU.
Jakie funkcje wyróżniają Wan 2.1?
Wan 2.1 obsługuje wielozadaniowe generowanie wideo (text-to-video, image-to-video, edycję wideo itp.), renderowanie tekstu w wielu językach w filmach, wysoką wydajność dzięki 3D causal Video VAE oraz przewyższa wiele komercyjnych i otwartych modeli w benchmarkach.
Jak mogę uruchomić Wan 2.1 na własnym komputerze?
Potrzebujesz Pythona 3.8+, PyTorch 2.4.0+ z obsługą CUDA oraz karty NVIDIA GPU (8GB+ VRAM dla mniejszego modelu, 16-24GB dla dużego). Sklonuj repozytorium GitHub, zainstaluj zależności, pobierz wagi modelu i użyj dostarczonych skryptów do generowania wideo lokalnie.
Dlaczego Wan 2.1 jest ważny dla generowania wideo przez AI?
Wan 2.1 demokratyzuje dostęp do najnowocześniejszego generowania wideo, będąc otwartoźródłowym i darmowym, co pozwala deweloperom, naukowcom i twórcom eksperymentować i wprowadzać innowacje bez opłat czy ograniczeń własnościowych.
Jak Wan 2.1 wypada w porównaniu do modeli takich jak Sora czy Runway Gen-2?
W przeciwieństwie do zamkniętych rozwiązań takich jak Sora czy Runway Gen-2, Wan 2.1 jest w pełni otwartoźródłowy i można go uruchomić lokalnie. Zwykle przewyższa wcześniejsze otwarte modele i dorównuje lub przewyższa wiele komercyjnych rozwiązań w jakościowych benchmarkach.
Arshia jest Inżynierką Przepływów Pracy AI w FlowHunt. Z wykształceniem informatycznym i pasją do sztucznej inteligencji, specjalizuje się w tworzeniu wydajnych przepływów pracy, które integrują narzędzia AI z codziennymi zadaniami, zwiększając produktywność i kreatywność.
Arshia Kahani
Inżynierka Przepływów Pracy AI
Wypróbuj FlowHunt i buduj rozwiązania AI
Zacznij budować własne narzędzia AI i workflow generowania wideo z FlowHunt lub umów się na demo, aby zobaczyć platformę w akcji.
Jak zrewolucjonizować tworzenie treści dzięki generowaniu wideo Wan 2.2 i 2.5?
FlowHunt obsługuje już modele generowania wideo Wan 2.2 i 2.5 do tekstu na wideo, obrazu na wideo, podmiany person i animacji. Odmień swoje tworzenie treści dzi...
Aktualizacja październik 2025: Potężne nowe modele AI do wideo i obrazów
Październikowa aktualizacja FlowHunt 2025 wprowadza rewolucyjne modele generowania wideo Wan 2.2 i 2.5 do tekstu-na-wideo, obrazu-na-wideo i animacji, a także z...
Sora 2: Generowanie wideo przez AI dla twórców treści
Poznaj przełomowe możliwości Sora 2 w generowaniu wideo przez AI: od realistycznego odtwarzania postaci po symulację fizyki i zobacz, jak ta technologia zmienia...
16 min czytania
AI
Video Generation
+3
Zgoda na Pliki Cookie Używamy plików cookie, aby poprawić jakość przeglądania i analizować nasz ruch. See our privacy policy.