Kontekst Mühendisliği: 2025'te Yapay Zeka Sistem Tasarımında Ustalığın Kesin Rehberi
Yapay zeka için kontekst mühendisliğine derinlemesine dalış. Bu rehber, prompt ve kontekst farkından, bellek yönetimi, kontekst çürümesi ve çoklu ajan tasarımı gibi ileri stratejilere kadar temel ilkeleri kapsar.
AI
LLM
System Design
Agents
Context Engineering
Prompt Engineering
RAG
Yapay zeka geliştirme dünyası köklü bir dönüşüm geçirdi. Eskiden mükemmel prompt hazırlamaya odaklanırken, artık çok daha karmaşık bir sorunla karşı karşıyayız: Dil modellerimizi çevreleyen ve güçlendiren tüm bilgi mimarilerini inşa etmek.
Bu değişim, prompt mühendisliğindenkontekst mühendisliğine evrimi işaret ediyor—ve pratik yapay zeka geliştirmede geleceğin ta kendisini temsil ediyor. Bugün gerçek değer sunan sistemler sihirli promptlara dayanmıyor. Başarılarının sırrı, mimarlarının kapsamlı bilgi ekosistemlerini ustalıkla yönetmesinde yatıyor.
Andrej Karpathy, kontekst mühendisliğini, kontekst penceresini tam doğru anda tam doğru bilgiyle doldurma sanatı olarak tanımlayarak bu evrimi mükemmel biçimde özetledi. Bu aldatıcı derecede basit ifade temel bir gerçeği açığa çıkarıyor: LLM artık gösterinin yıldızı değil. O, dikkatle tasarlanmış bir sistemin kritik bir bileşeni; burada her bilgi kırıntısı—her bellek parçası, her araç tanımı, her alınan doküman—maksimum sonuç için kasıtlı olarak konumlandırılmış.
Kontekst Mühendisliği Nedir?
Tarihsel Bir Bakış
Kontekst mühendisliğinin kökleri çoğu kişinin sandığından daha derinlere uzanır. Prompt mühendisliği hakkındaki ana akım tartışmalar 2022-2023 yıllarında patlasa da, kontekst mühendisliğinin temel kavramları iki on yıl önce, yaygın hesaplama ve insan-bilgisayar etkileşimi araştırmalarından doğdu.
2001’de Anind K. Dey, oldukça öngörülü bir tanım ortaya koydu: Kontekst, bir varlığın durumunu karakterize etmeye yardımcı olan her türlü bilgidir. Bu erken çerçeve, makinelerin çevreleri anlaması konusunda bugün düşündüğümüz her şeyin temelini attı.
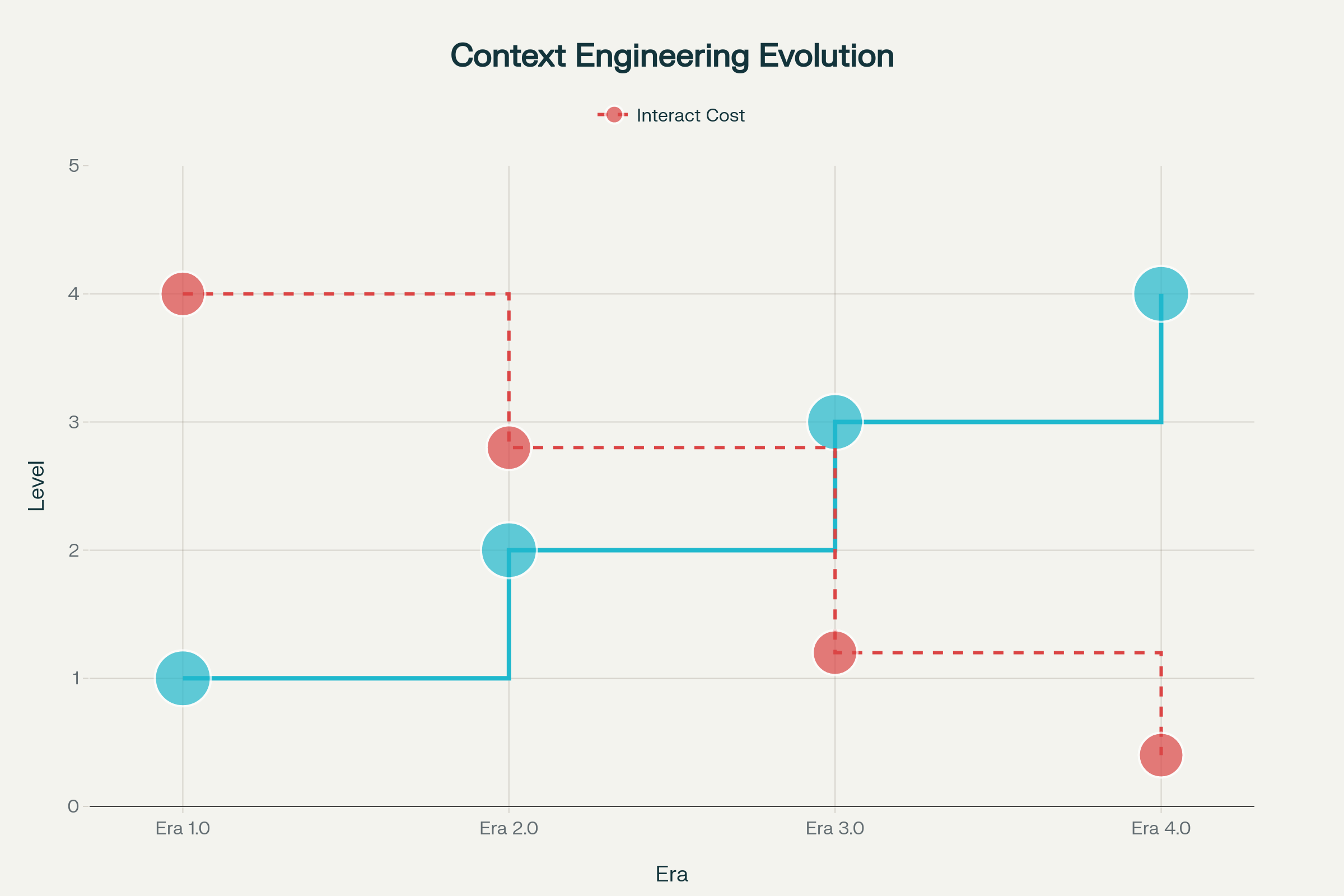
Kontekst mühendisliğinin evrimi, makine zekasındaki ilerlemelerle şekillenen belirgin evrelerle gerçekleşti:
Dönem 1.0: İlkel Hesaplama (1990’lar–2020) — Bu uzun dönemde makineler yalnızca yapılandırılmış girdileri ve temel çevresel sinyalleri işleyebildi. Kontekstin makine tarafından işlenebilir formata çevrilmesinin tüm yükü insanlardaydı. Masaüstü uygulamalar, sensörlü mobil uygulamalar ve katı yanıt ağaçlı erken sohbet botlarını düşünün.
Dönem 2.0: Ajan Merkezli Zekâ (2020–Günümüz) — GPT-3’ün 2020’de piyasaya sürülmesiyle paradigma değişti. Büyük dil modelleri, gerçek doğal dil anlayışı ve örtük niyetlerle çalışma yeteneği getirdi. Bu dönem, belirsizlik ve eksik bilginin karmaşık dil anlama ve kontekst içi öğrenme yoluyla yönetilebilir hale geldiği, insan-ajan işbirliğini mümkün kıldı.
Dönem 3.0 & 4.0: İnsan ve Üstinsan Zekâsı (Gelecek) — Sıradaki dalgalar, yüksek entropili bilgiyi insan benzeri akışkanlıkla algılayıp işleyebilen sistemler ve eninde sonunda reaktif yanıtların ötesine geçip, kullanıcıların henüz dile getirmediği ihtiyaçları proaktif biçimde inşa eden kontekstler vadediyor.
Dört Dönemde Kontekst Mühendisliğinin Evrimi: İlkel Hesaplamadan Üstinsan Zekâsına
Resmi Bir Tanım
Kontekst mühendisliği temelde, kontekst bilgisinin AI sistemlerinde ilk toplanmasından depolanmasına, yönetilmesine ve nihai kullanımına kadar makinelerin anlayışını ve görev başarımını artıracak şekilde akışını tasarlama ve optimize etme disiplinidir.
Bunu matematiksel olarak bir dönüşüm fonksiyonu ile ifade edebiliriz:
$CE: (C, T) \rightarrow f_{context}$
Burada:
C, ham kontekst bilgisini (varlıklar ve özellikleri) temsil eder
T, hedef görevi veya uygulama alanını belirtir
f_{context}, ortaya çıkan kontekst işleme fonksiyonunu verir
Bunu pratikte dört temel işleme ayırabiliriz:
İlgili kontekst sinyallerini toplamak için çeşitli sensörler ve bilgi kanallarını kullanmak
Bu bilgiyi etkili şekilde depolamak (yerel sistemler, ağ altyapısı, bulut)
Karmaşıklığı yönetmek için metin, çoklu modal girişler ve karmaşık ilişkileri işlemek
Konteksti stratejik kullanmak: İlgiliyi filtrelemek, sistemler arası paylaşımı mümkün kılmak, kullanıcı gereksinimine göre uyarlamak
Neden Kontekst Mühendisliği: Entropi Azaltma Çerçevesi
Kontekst mühendisliği insan-makine iletişimindeki temel bir asimetriyi giderir. İnsanlar sohbet ederken, kültürel bilgi, duygusal zekâ ve durumsal farkındalık sayesinde boşlukları çabasızca doldurur. Makinelerde bunların hiçbiri yoktur.
Bu fark, bilgi entropisi olarak ortaya çıkar. İnsan iletişimi, devasa miktarda ortak kontekste güvenerek çok verimli çalışır. Makineler için ise her şeyin açıkça temsil edilmesi gerekir. Kontekst mühendisliği temelde, makineler için konteksti ön işlemden geçirme—insan niyet ve durumlarının yüksek entropili karmaşıklığını, makinelerin işleyebileceği düşük entropili temsillere sıkıştırma—işidir.
Makine zekâsı ilerledikçe bu entropi azaltımı giderek daha otomatik hale gelir. Bugün, 2.0 Dönemi’nde mühendisler bunun çoğunu elle yönetir. 3.0 ve sonrası için, makineler bu yükü giderek daha fazla kendi başına üstlenecek. Ancak ana sorun değişmeyecek: İnsan karmaşıklığı ile makine anlayışı arasındaki uçurumu kapatmak.
Prompt Mühendisliği ile Kontekst Mühendisliği: Kritik Farklar
Bu iki disiplin sıkça karıştırılır. Oysa, AI sistem mimarisinde temelde farklı yaklaşımları temsil ederler.
Prompt mühendisliği, model davranışını şekillendirmek için tek tek talimatlar veya sorgular hazırlamaya odaklanır. Bir etkileşim içindeki dilsel yapının—ifade şekli, örnekler, akıl yürütme kalıpları—optimizasyonudur.
Kontekst mühendisliği ise, modelin çıkarım sırasında karşılaştığı her şeyi—promptlar da dahil; ama alınan dokümanlar, bellek sistemleri, araç tanımları, durum bilgisi ve daha fazlası ile birlikte—yöneten kapsamlı bir sistem disiplinidir.
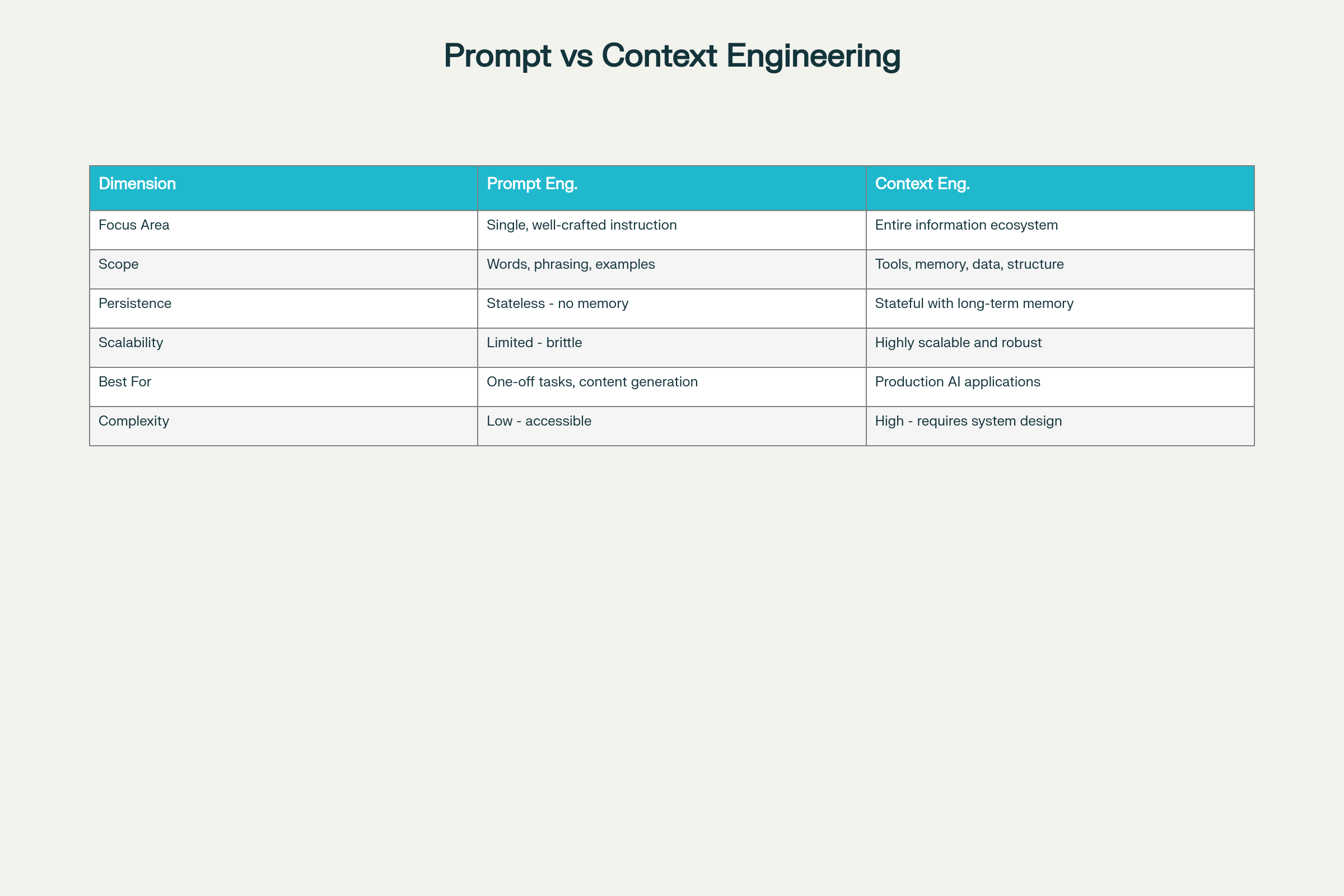
Prompt Mühendisliği ve Kontekst Mühendisliği: Temel Farklar ve Ödünleşimler
Bu ayrımı şöyle düşünebilirsiniz: ChatGPT’den profesyonel bir e-posta yazmasını istemek prompt mühendisliğidir. Konuşma geçmişini, kullanıcı hesap detaylarını ve önceki destek taleplerini hatırlayan bir müşteri hizmetleri platformu kurmak ise kontekst mühendisliğidir.
Sekiz Boyutta Temel Farklar:
Boyut
Prompt Mühendisliği
Kontekst Mühendisliği
Odak Alanı
Bireysel talimat optimizasyonu
Kapsamlı bilgi ekosistemi
Kapsam
Kelimeler, ifadeler, örnekler
Araçlar, bellek, veri mimarisi, yapı
Süreklilik
Durumsuz—bellek tutulmaz
Durumlu, uzun süreli bellekle
Ölçeklenebilirlik
Sınırlı ve kırılgan
Çok ölçekli ve sağlam
En Uygun Olduğu
Tek seferlik işler, içerik üretimi
Üretim seviyesinde AI uygulamaları
Karmaşıklık
Giriş engeli düşük
Yüksek—sistem tasarım bilgisi gerekir
Güvenilirlik
Ölçekte öngörülemez
Tutarlı ve güvenilir
Bakım
Gereksinim değişimine kırılgan
Modüler ve sürdürülebilir
Kritik içgörü: Üretim seviyesinde LLM uygulamaları neredeyse tamamen kontekst mühendisliğine ihtiyaç duyar; sadece akıllıca promptlar yeterli değildir. Cognition AI’nin gözlemiyle, kontekst mühendisliği, AI ajanları inşa eden mühendislerin temel sorumluluğu haline gelmiştir.
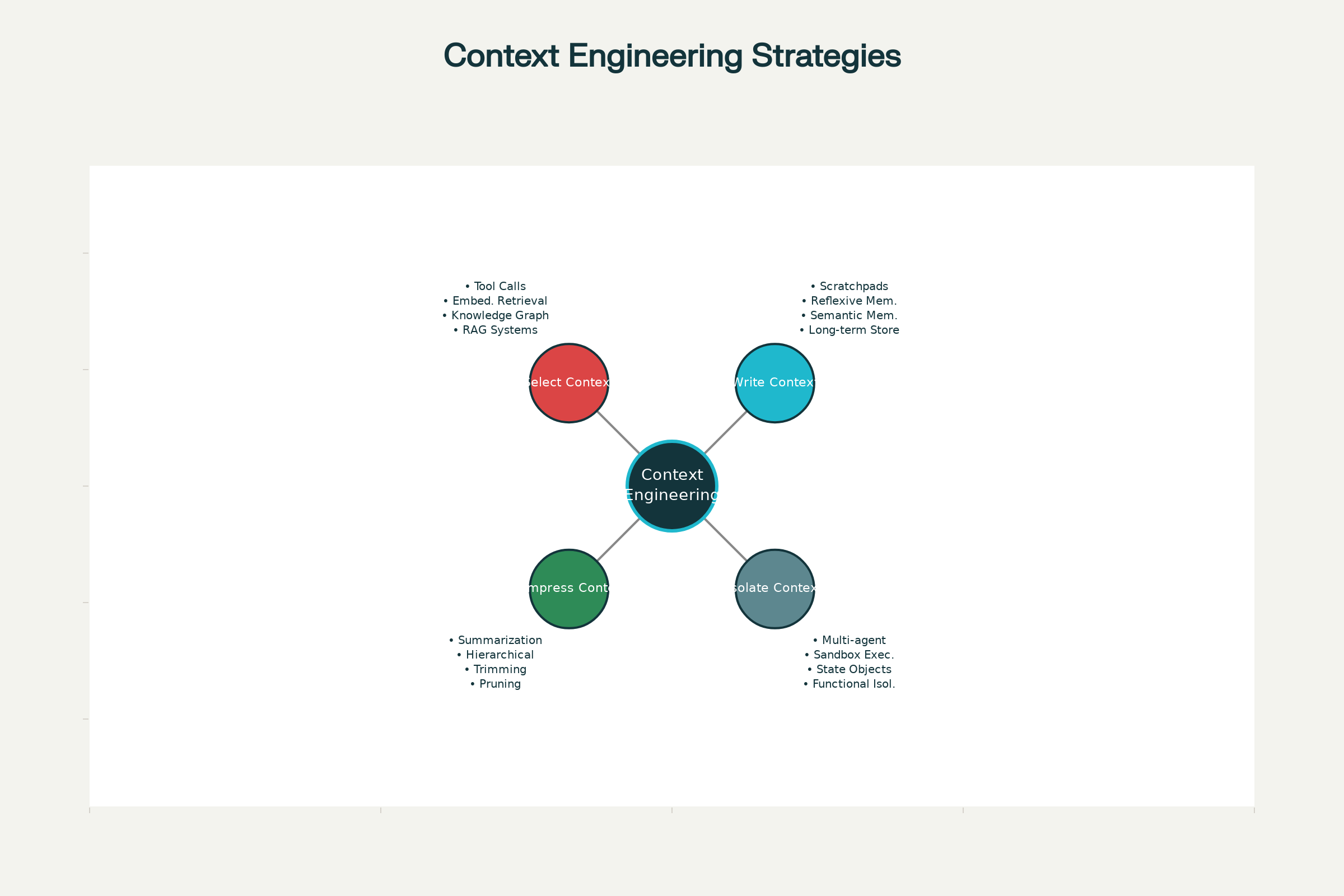
Kontekst Mühendisliğinin Dört Temel Stratejisi
Claude ve ChatGPT’den Anthropic ve önde gelen laboratuvarların geliştirdiği özel ajanlara kadar, etkili kontekst yönetimi için dört temel strateji ortaya çıkmıştır. Bunlar bağımsız olarak veya daha güçlü etki için birlikte kullanılabilir.
1. Kontekst Yazma: Bilgiyi Kontekst Penceresi Dışında Tutmak
Temel ilke gayet basittir: Modelin her şeyi hatırlamasını beklemeyin. Bunun yerine, kritik bilgileri ihtiyaç duyulduğunda güvenilir şekilde erişilebilecek biçimde kontekst penceresi dışında kalıcı hale getirin.
Karalama defterleri en sezgisel uygulamadır. İnsanlar karmaşık sorunlarla uğraşırken nasıl not alıyorsa, AI ajanları da gelecekte başvurmak üzere bilgi saklamak için karalama defterleri kullanır. Uygulama, ajanın not kaydetmek için bir araç çağırmasından, yürütme adımları arasında kalıcı kalan bir çalışma durumu nesnesindeki alanlara kadar değişebilir.
Anthropic’in çoklu ajan araştırmacısı bu yaklaşımı harika gösterir: LeadResearcher, bir yaklaşım oluşturup planını Bellek’e kaydeder, çünkü 200.000 token’ı aşarsa pencere kesilecektir ve planın tutulması gerekir.
Bellekler, karalama defteri mantığını oturumlar arası genişletir. Bilgi sadece tek bir görevde toplanmaz (oturum kapsamlı bellek); sistemler, çoklu kullanıcı-ajan etkileşimi boyunca kalıcı ve evrilen uzun vadeli bellekler inşa edebilir. Bu desen, ChatGPT, Claude Code, Cursor ve Windsurf gibi ürünlerde standart hale geldi.
Reflexion gibi araştırma projeleri yansıtıcı bellekleri öncülük etti—ajan, her turda kendini gözden geçirir ve gelecekte kullanmak için bellekler oluşturur. Generative Agents yaklaşımı, geçmiş geri bildirim koleksiyonlarından periyodik olarak bellekler sentezleyerek bu yaklaşımı daha da geliştirdi.
Üç Bellek Tipi:
Episodik: Geçmiş davranış veya etkileşim örnekleri (few-shot öğrenme için değerli)
Prosedürel: Davranışı yöneten talimatlar veya kurallar (tutarlılığı sağlar)
Semantik: Dünya hakkında gerçekler ve ilişkiler (temellendirilmiş bilgi sağlar)
2. Kontekst Seçimi: Doğru Bilgiyi Getirmek
Bilgi saklandıktan sonra, ajan mevcut görev için yalnızca ilgili olanı getirmelidir. Kötü seçim, hiç bellek olmamasından daha zararlı olabilir—alakasız bilgi modeli şaşırtabilir veya halüsinasyona yol açabilir.
Bellek Seçim Mekanizmaları:
Daha basit yaklaşımlar, her zaman dahil edilen dar dosyalar kullanır. Claude Code, prosedürel bellekler için CLAUDE.md dosyası kullanırken, Cursor ve Windsurf rules dosyalarından yararlanır. Ancak, bu yöntem, ajan yüzlerce gerçek ve ilişki biriktirdiğinde ölçeklenmekte zorlanır.
Daha büyük bellek koleksiyonlarında, gömme tabanlı getirme ve bilgi grafikleri yaygın olarak kullanılır. Sistem, hem bellekleri hem de mevcut sorguyu vektör temsillere dönüştürür ve en anlamca benzer bellekleri getirir.
Ancak Simon Willison’un AIEngineer Dünya Fuarı’nda gösterdiği gibi, bu yaklaşım felaketle sonuçlanabilir. ChatGPT, anılarındaki konumunu beklenmedik şekilde oluşturulan bir görsele ekledi—karmaşık sistemlerin bile yanlış bellek getirebileceğini gösterdi. Bu da titiz mühendisliğin önemini vurguluyor.
Araç Seçimi de ayrı bir zorluktur. Ajanlar onlarca veya yüzlerce araca erişebiliyorsa, hepsini sıralamak kafa karışıklığına yol açar—çakışan açıklamalar modellerin yanlış araç seçmesine neden olur. Etkili bir çözüm: Araç açıklamalarında RAG ilkelerini uygulayın. Sadece anlamca ilgili araçları getirerek, araç seçimi doğruluğu üç kat artırılabilir.
Bilgi Getirme ise en zengin problem alanıdır. Kod ajanları, bu zorluğu üretim ölçeğinde örnekler. Windsurf mühendisi şöyle diyor: Kodu indekslemek, etkili kontekst getirme anlamına gelmez. AST ayrıştırması ve anlamlı sınırlarla bölme ile indeksleme ve gömme arama yapıyorlar. Ancak kod tabanları büyüdükçe gömme arama güvenilmez hale geliyor. Başarı için grep/dosya arama, bilgi grafiği tabanlı getirme ve anlamca sıralama gibi tekniklerin birleştirilmesi gerekiyor.
3. Kontekst Sıkıştırma: Sadece Gerekli Olanı Tutmak
Ajanlar uzun vadeli görevlerde çalıştıkça kontekst doğal olarak birikir. Karalama defteri notları, araç çıktıları, etkileşim geçmişi hızla kontekst penceresini aşabilir. Sıkıştırma stratejileri, önemli olanı koruyarak bilgiyi akıllıca damıtar.
Özetleme ana tekniktir. Claude Code, “otomatik sıkıştırma” uygular—kontekst penceresi %95’e ulaştığında, kullanıcı-ajan etkileşiminin tüm sürecini özetler. Bu çeşitli stratejilerle yapılabilir:
Hiyerarşik özetleme: Farklı soyutlama seviyelerinde özetler üretmek
Hedefli özetleme: Tüm kontekst yerine sadece token-yoğun belirli bileşenleri (ör. arama sonuçları) sıkıştırmak
Cognition AI, bilgi devri sırasında ajanlar arası sınırda özetleme için ince ayarlı modeller kullandıklarını açıkladı—bu adımın mühendislik derinliğini gösteriyor.
Kontekst Kırpma tamamlayıcı bir yaklaşımdır. LLM’ye özetletmek yerine, kırpma basit kurallarla konteksti budar—eski mesajları silmek, öneme göre filtrelemek veya QA görevlerinde Provence gibi eğitilmiş kırpıcılar kullanmak.
Temel içgörü: Çıkardığınız şey, tuttuğunuz kadar önemli olabilir. Odaklanmış 300-token’lık bir kontekst, sohbet görevlerinde odaklanmamış 113.000-token’lık bir konteksten genellikle daha iyi performans verir.
4. Konteksti İzolasyon: Bilgiyi Sistemler Arasında Paylaştırmak
Son olarak, izolasyon stratejileri farklı görevlerin farklı bilgi gerektirdiğini kabul eder. Tüm konteksti tek bir model penceresine sığdırmak yerine, izolasyon teknikleri konteksti uzmanlaşmış sistemler arasında böler.
Çoklu Ajan Mimarileri en yaygın yaklaşımdır. OpenAI Swarm kütüphanesi, “görev ayrımı” etrafında özellikle tasarlanmıştır—özel alt ajanlar, kendi araçları, talimatları ve kontekst pencereleri ile belirli görevleri üstlenir.
Anthropic’in araştırmaları bu yaklaşımın gücünü gösteriyor: İzole kontekste sahip çoklu ajanlar, tek ajanlı uygulamalardan daha iyi performans gösterdi; çünkü her alt ajan penceresi daha dar bir alt göreve ayrılabilir. Alt ajanlar, kendi kontekst pencereleriyle paralel çalışır ve sorunun farklı yönlerini aynı anda keşfeder.
Ancak çoklu ajan sistemleri ödünleşim içerir. Anthropic, tek ajanlı sohbete göre token kullanımında on beş kata kadar artış rapor etti. Bu, dikkatli orkestrasyon, planlama için prompt mühendisliği ve sofistike koordinasyon mekanizmaları gerektirir.
Sandbox Ortamları başka bir izolasyon stratejisidir. HuggingFace’in CodeAgent’ı bunun güzel bir örneği: Modelin yorumlaması gereken JSON döndürmek yerine, ajan bir sandbox’ta çalıştırılan kod çıktısı üretir. Seçili çıktılar (dönüş değerleri) LLM’ye geri iletilir, token-yoğun nesneler ise yürütme ortamında izole tutulur. Bu yaklaşım görsel ve sesli verilerde mükemmel sonuç verir.
Durum Nesnesi İzolasyonu belki de en az bilinen tekniktir. Bir ajanın çalışma zamanı durumu, çok alanlı yapılandırılmış bir şema (ör. Pydantic modeli) olarak tasarlanabilir. Bir alan (ör. messages), her adımda LLM’ye sunulur; diğer alanlar ise seçici kullanım için izole kalır. Bu, mimari karmaşıklık olmadan ince ayarlı kontrol sağlar.
AI Ajanlarında Etkili Kontekst Mühendisliği için Dört Temel Strateji
Kontekst Çürümesi Sorunu: Kritik Bir Meydan Okuma
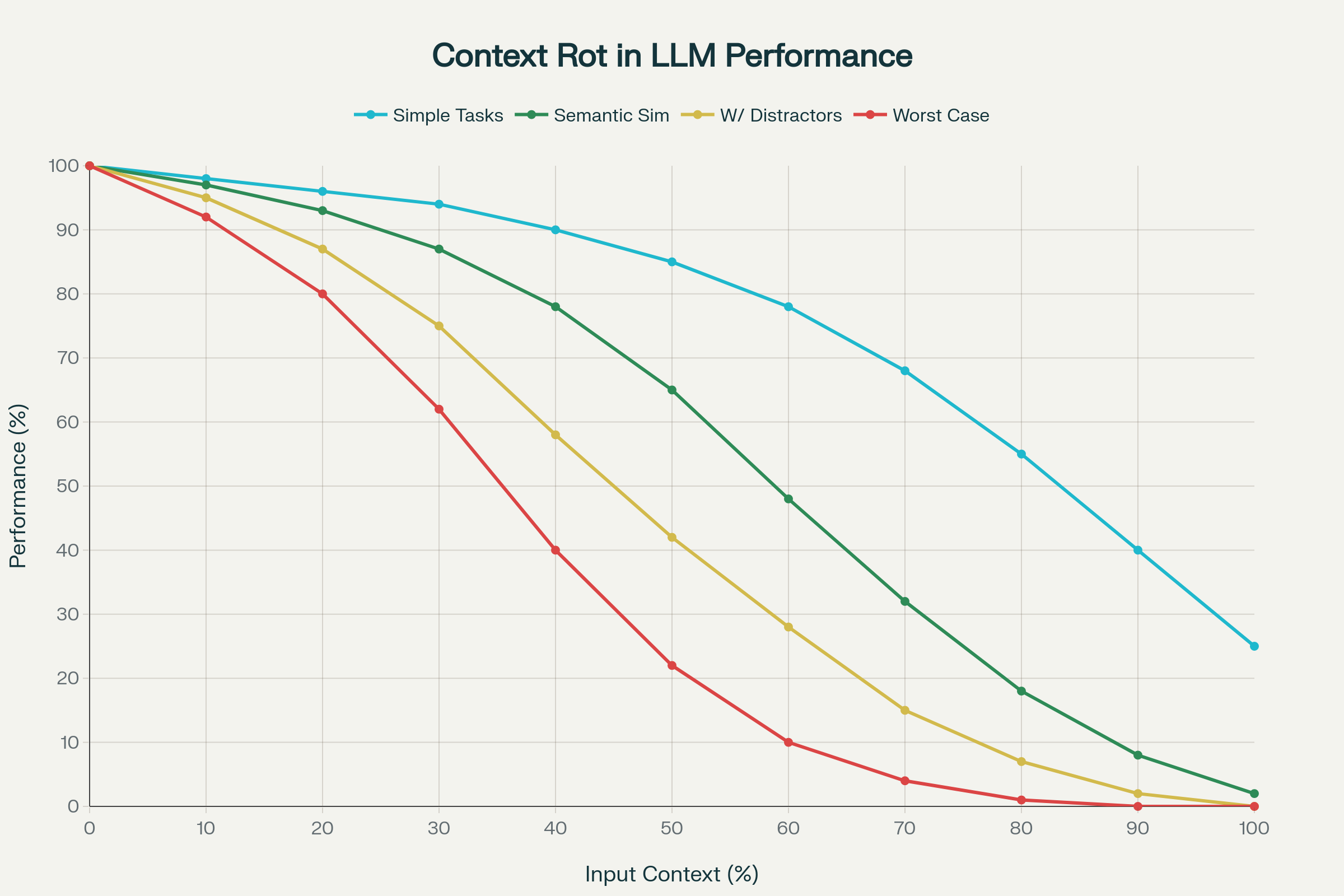
Kontekst uzunluğundaki ilerlemeler sektörde geniş ölçüde kutlansa da, son araştırmalar rahatsız edici bir gerçeği ortaya koyuyor: Daha uzun kontekst, otomatik olarak daha iyi performans anlamına gelmiyor.
18 önde gelen LLM’yi analiz eden öncü bir çalışma—GPT-4.1, Claude 4, Gemini 2.5 ve Qwen 3 dahil—kontekst çürümesi adlı bir olguyu açığa çıkardı: Giriş konteksti uzadıkça performansta öngörülemeyen ve çoğu zaman ciddi bozulmalar.
Kontekst Çürümesiyle İlgili Temel Bulgular
1. Düzensiz Performans Bozulması
Performans doğrusal ve öngörülebilir biçimde azalmaz. Aksine, modeller modele ve göreve göre keskin, kendine has düşüşler gösterir. Bir model, belirli bir kontekst uzunluğuna kadar %95 doğruluk koruyabilir, ardından aniden %60’a düşebilir. Bu eşikler modeller arasında öngörülemezdir.
Basit görevlerde (tekrarlanan kelimeleri kopyalama veya tam eşleşmeli anlamsal getirme gibi) orta düzeyde bir azalma görülür. Ancak, “samanlıkta iğne” gibi görevlerde, anlamca benzer ama tam eşleşmeyen bilgi eklendiğinde performans dramatik biçimde düşer.
3. Pozisyon Sapması ve Dikkat Çökmesi
Transformer dikkat mekanizması uzun kontekstlerde doğrusal ölçeklenmez. Başlangıç (primacy bias) ve son (recency bias) token’lar orantısız dikkat görür. Aşırı durumlarda, dikkat tamamen çöker ve model, girdinin büyük bölümünü görmezden gelir.
4. Modele Özgü Hata Desenleri
Farklı LLM’ler ölçeklenince benzersiz davranışlar gösterir:
GPT-4.1: Halüsinasyona eğilimli, yanlış token’ları tekrarlar
Gemini 2.5: Alakasız parçalar veya noktalama işaretleri ekler
Claude Opus 4: Görevleri reddedebilir veya aşırı temkinli davranabilir
5. Gerçek Dünya Etkisi Sohbet Ortamında
Belki de en çarpıcı olanı: LongMemEval benchmark’ında, tam sohbeti (yaklaşık 113k token) gören modeller, yalnızca odaklanmış 300-token’lık bölümü verildiğinde daha iyi performans gösterdi. Bu, kontekst çürümesinin gerçek diyalog ortamında hem getirme hem de akıl yürütmeyi bozduğunu gösteriyor.
Kontekst Çürümesi: 18 LLM’de Girdi Token Uzunluğu Arttıkça Performans Bozulması
Sonuçlar: Miktardan Çok Kalite
Kontekst çürümesi araştırmasının ana sonucu açık: Girdi token miktarı kaliteyi tek başına belirlemez. Kontekstin nasıl kurulduğu, filtrelendiği ve sunulduğu en az bunun kadar, hatta daha da önemlidir.
Bu bulgu, kontekst mühendisliği disiplinini doğrular. Uzun kontekst pencerelerini sihirli çözüm olarak görmek yerine, ileri ekipler, dikkatli kontekst mühendisliği—sıkıştırma, seçim ve izolasyon yoluyla—büyük girişlerde performans korumanın şart olduğunu kabul ediyor.
Pratikte Kontekst Mühendisliği: Gerçek Dünya Uygulamaları
Vaka 1: Çok Turlu Ajan Sistemleri (Claude Code, Cursor)
Claude Code ve Cursor, kod asistanları için kontekst mühendisliğinin en ileri uygulamalarını temsil eder:
Toplama: Bu sistemler, açık dosyalar, proje yapısı, düzenleme geçmişi, terminal çıktısı ve kullanıcı yorumları gibi birçok kaynaktan kontekst toplar.
Yönetim: Tüm dosyaları prompt’a dökmek yerine akıllıca sıkıştırırlar. Claude Code, hiyerarşik özetler kullanır. Kontekst, işlevine göre etiketlenir (ör. “düzenlenen dosya”, “referans bağımlılık”, “hata mesajı”).
Kullanım: Her turda, sistem hangi dosya ve kontekst öğelerinin ilgili olduğunu seçer, bunları yapılandırılmış biçimde sunar ve akıl yürütme ile görünür çıktı için ayrı izler tutar.
Sıkıştırma: Kontekst limitine yaklaşınca otomatik sıkıştırma tetiklenir; etkileşim öyküsü özetlenir, ana kararlar korunur.
Sonuç: Bu araçlar, büyük projelerde (binlerce dosya) bile kontekst pencere kısıtlarına rağmen kullanılabilirliğini korur.
Vaka 2: Tongyi DeepResearch (Açık Kaynak Derin Araştırma Ajanı)
Tongyi DeepResearch, kontekst mühendisliğinin karmaşık araştırma görevlerinde nasıl olanak sağladığını gösterir:
Veri Sentez Hattı: Sınırlı insan etiketli veriye bağlı kalmak yerine, Tongyi, karmaşıklığı adım adım artırarak doktora seviyesinde araştırma soruları oluşturan sofistike bir veri sentezi yaklaşımı kullanır. Her yineleme, bilgi sınırlarını derinleştirir ve daha karmaşık akıl yürütme görevleri oluşturur.
Kontekst Yönetimi: Sistem, IterResearch paradigmasını kullanır—her araştırma turunda, yalnızca önceki turdan gelen temel çıktıları kullanarak sadeleştirilmiş bir çalışma alanı yeniden kurar. Bu, tüm bilgiyi tek bir kontekst penceresine yığmanın neden olduğu “bilişsel boğulmayı” engeller.
Paralel Keşif: Birden fazla araştırma ajanı, izole kontekstlerde paralel çalışır ve farklı yönleri keşfeder. Bir sentez ajanı, bulguları bütüncül yanıta entegre eder.
Sonuçlar: Tongyi DeepResearch, OpenAI’nin DeepResearch’ü gibi tescilli sistemlerle başa baş performans elde etmiştir (Humanity’s Last Exam’de 32.9, kullanıcı merkezli benchmarklarda 75 puan).
Vaka 3: Anthropic’in Çoklu Ajan Araştırmacısı
Anthropic’in araştırması, izolasyon ve uzmanlaşmanın performansı nasıl artırdığını gösterir:
Mimari: Özel alt ajanlar (literatür tarama, sentez, doğrulama) ayrı kontekst pencereleriyle belirli araştırma görevlerini yürütür.
Fayda: Bu yaklaşım, tek ajanlı sistemlerden daha iyi sonuç vermiştir; her alt ajanın konteksti dar görevine optimize edilmiştir.
Ödünleşim: Kalite üstünlüğüne rağmen, token kullanımı tek ajanlı sohbete kıyasla on beş katına çıkmıştır.
Bu, temel bir içgörüyü vurgular: Kontekst mühendisliği genellikle kalite, hız ve maliyet arasında ödünleşim gerektirir. Doğru denge, uygulamanın gereksinimlerine bağlıdır.
Tasarım Kararları Çerçevesi
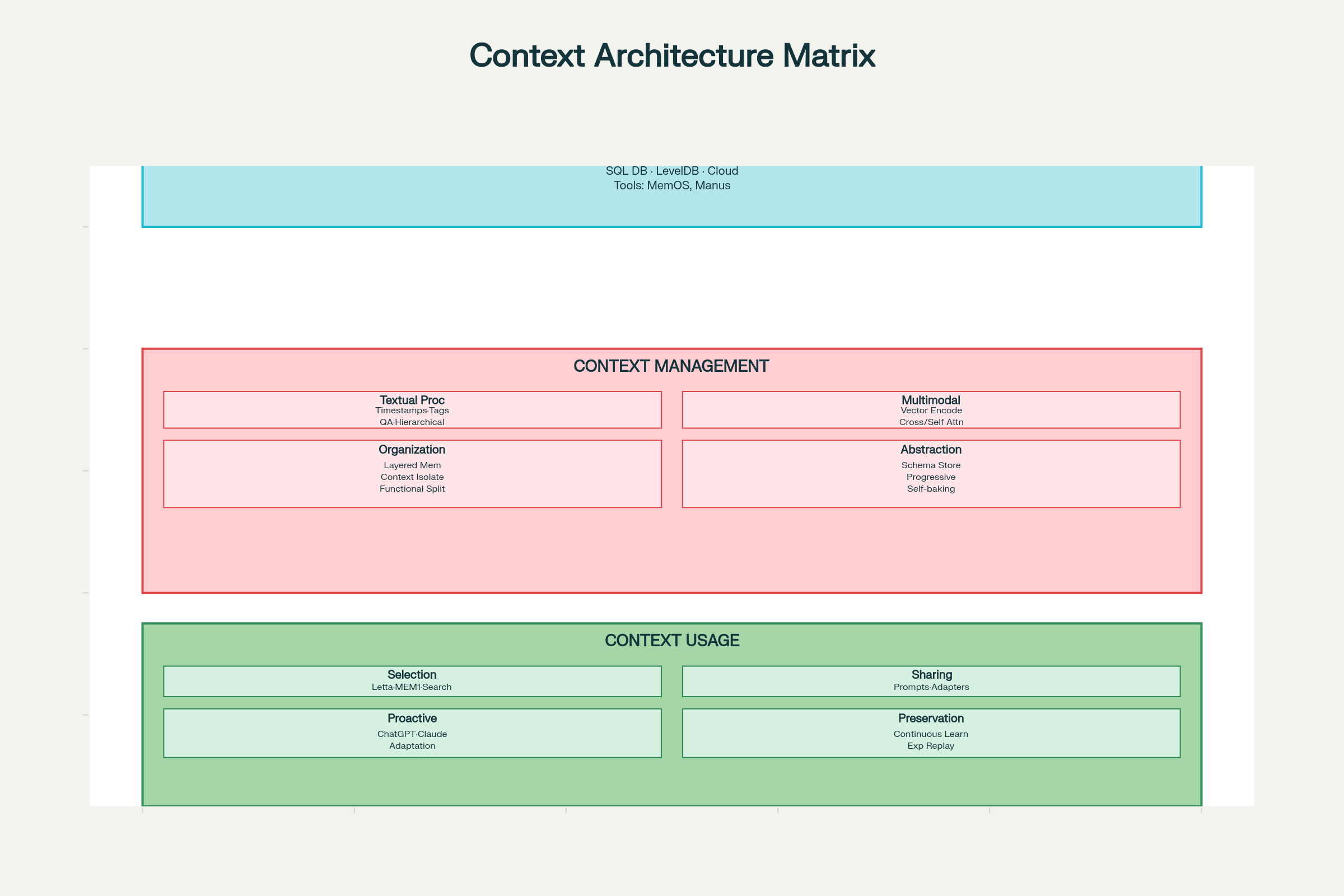
Etkili kontekst mühendisliği uygulamak, toplama & depolama, yönetim ve kullanım olmak üzere üç boyutta sistematik düşünmeyi gerektirir.
Kontekst Mühendisliği Tasarım Kararları: Tam Sistem Mimarisi ve Bileşenler
Toplama & Depolama Tasarımı
Depolama Teknolojisi Seçenekleri:
Yerel Depolama (SQLite, LevelDB): Hızlı, düşük gecikmeli, istemci tarafı ajanlar için uygun
Bulut Depolama (DynamoDB, PostgreSQL): Ölçeklenebilir, her yerden erişilebilir
Dağıtık Sistemler: Yüksek ölçek için yedekli ve hataya dayanıklı
Tasarım Kalıpları:
MemOS: Birleşik bellek yönetimi için bellek işletim sistemi
Manus: Rol tabanlı erişimli yapılandırılmış bellek
Temel ilke: Sadece depolama değil, etkili getirme için tasarım yapın. En iyi depolama sistemi, ihtiyacınızı hızla bulabildiğiniz sistemdir.
Yönetim Tasarım Kararları
Metinsel Kontekst İşleme:
Zaman Damgası İşaretleme: Basit ama sınırlı. Kronolojik sıralamayı korur ama anlamsal yapı sunmaz; etkileşim biriktikçe ölçeklenemez.
Rol/Fonksiyon Etiketleme: Her kontekst öğesine işlev etiketi ekleyin—“hedef”, “karar”, “eylem”, “hata” vs. Çok boyutlu etiketlemeyi (öncelik, kaynak, güven) destekler. LLM4Tag gibi sistemler bunu ölçekli yapar.
QA Çifti ile Sıkıştırma: Etkileşimleri sıkıştırılmış soru-cevap çiftlerine dönüştürerek temel bilgiyi korurken token’ı azaltır.
Hiyerarşik Notlar: H-MEM sistemlerinde olduğu gibi, çoklu soyutlama seviyelerinde anlam vektörlerine aşamalı sıkıştırma.
Çoklu Modal Kontekst İşleme:
Karşılaştırılabilir Vektör Uzayları: Tüm modaliteleri (metin, görsel, ses) ortak gömme modellerle karşılaştırılabilir vektörlere kodlayın (ChatGPT ve Claude gibi).
Çapraz Dikkat: Bir modaliteyi diğerini yönlendirmek için kullanın (Qwen2-VL gibi).
Bağımsız Kodlama ve Öz-Dikkat: Modaliteleri ayrı kodlayın, ardından birleşik dikkat mekanizmasıyla birleştirin.
Kontekst Organizasyonu:
Katmanlı Bellek Mimarisi: Çalışma belleği (anlık kontekst), kısa süreli bellek (yakın geçmiş), uzun süreli bellek (kalıcı gerçekler) ayrımı.
Fonksiyonel Kontekst İzolasyonu: Farklı işlevler için ayrı kontekst pencereleriyle alt ajanlar kullanmak (Claude yaklaşımı).
Kontekst Soyutlama (Self-Baking):
“Self-baking”, kontekstin tekrarlı işleme ile iyileşmesini ifade eder. Kalıplar şunlardır:
Ham konteksti saklayıp sonra doğal dil özetleri ekleme (Claude Code, Gemini CLI)
Sabit şemalarla kilit gerçekleri çıkarma (ChatSchema yaklaşımı)
Platformlar arası paylaşılan temsiller (Sharedrop)
Proaktif Kullanıcı Çıkarımı:
ChatGPT ve Claude, kullanıcı ihtiyaçlarını önceden tahmin etmek için etkileşim kalıplarını analiz eder
Kontekst sistemleri, açıkça istenmeden bilgiyi yüzeye çıkaracak şekilde öğrenir
Yardımcılık ve gizlilik arasında denge, ana tasarım meydan okuması olmaya devam ediyor
Kontekst Mühendisliği Becerileri ve Takımların Ustalaşması Gerekenler
Kontekst mühendisliği AI geliştirmede giderek merkezi
Sıkça sorulan sorular
Prompt mühendisliği, bir LLM için tek bir talimat hazırlamaya odaklanır. Kontekst mühendisliği ise, bir AI modelinin karmaşık, durumsal görevlerdeki performansını optimize etmek için bellek, araçlar ve alınan veriler dahil olmak üzere tüm bilgi ekosistemini yöneten daha geniş bir sistem disiplinidir.
Kontekst çürümesi, bir LLM'nin giriş konteksti uzadıkça performansının öngörülemeyen şekilde bozulmasıdır. Modeller, doğrulukta ani düşüşler gösterebilir, kontekstin bazı bölümlerini göz ardı edebilir veya halüsinasyon üretebilir; bu da, miktardan ziyade kontekstin kalitesinin ve dikkatli yönetiminin gerekliliğini vurgular.
Dört temel strateji şunlardır: 1. Kontekst Yazma (bilgiyi kontekst penceresi dışında kalıcı hale getirme; örn. karalama defterleri veya bellek), 2. Kontekst Seçimi (sadece ilgili bilgiyi getirme), 3. Kontekst Sıkıştırma (yerden tasarruf için özetleme veya kırpma), 4. Konteksti İzolasyon (çoklu ajan sistemleri veya sandbox’lar kullanarak görevleri ayırma).
Arshia, FlowHunt'ta bir Yapay Zeka İş Akışı Mühendisidir. Bilgisayar bilimi geçmişi ve yapay zekaya olan tutkusu ile, yapay zeka araçlarını günlük görevlere entegre eden verimli iş akışları oluşturmada uzmanlaşmıştır ve bu sayede verimlilik ile yaratıcılığı artırır.
Arshia Kahani
Yapay Zeka İş Akışı Mühendisi
Kontekst Mühendisliğinde Ustalaşın
Bir sonraki nesil AI sistemlerini inşa etmeye hazır mısınız? Projelerinizde gelişmiş kontekst mühendisliğini uygulamak için kaynaklarımızı ve araçlarımızı keşfedin.
Gelecek Yönlendirilmiş: Neden Prompt Mühendisliği Yeni Temel Beceri?
Prompt mühendisliğinin neden her profesyonel için hızla vazgeçilmez bir beceri haline geldiğini, işyeri verimliliğini nasıl dönüştürdüğünü ve bugün bu beceriyi ...