AI Sohbet Botu Gerçekliğini Nasıl Doğrularsınız
2025'te AI sohbet botu gerçekliğini doğrulamanın kanıtlanmış yöntemlerini öğrenin. Gerçek AI sistemlerini belirleyip sahte sohbet botlarından korunmak için tekn...
10 dakika okuma
2025 yılında AI yardım masası chatbot doğruluğunu ölçmenin kapsamlı yöntemlerini öğrenin. Hassasiyet, geri çağırma, F1 skorları, kullanıcı memnuniyeti metrikleri ve FlowHunt ile gelişmiş değerlendirme tekniklerini keşfedin.
AI yardım masası chatbot doğruluğunu, hassasiyet ve geri çağırma hesaplamaları, karışıklık matrisi, kullanıcı memnuniyeti skorları, çözüm oranları ve gelişmiş LLM tabanlı değerlendirme yöntemleri dahil olmak üzere çoklu metriklerle ölçün. FlowHunt, otomatik doğruluk değerlendirmesi ve performans izleme için kapsamlı araçlar sunar.
Bir AI yardım masası chatbot’unun doğruluğunu ölçmek, müşterilere güvenilir ve faydalı yanıtlar sunmasını sağlamak için esastır. Basit sınıflandırma görevlerinden farklı olarak, chatbot doğruluğu birden fazla boyutu kapsar ve performansın tam bir resmini sunmak için birlikte değerlendirilmelidir. Bu süreç, chatbot’un kullanıcı sorgularını ne kadar iyi anladığını, doğru bilgi verip vermediğini, sorunları etkin şekilde çözüp çözmediğini ve etkileşimler boyunca kullanıcı memnuniyetini koruyup korumadığını analiz etmeyi içerir. Kapsamlı bir doğruluk ölçüm stratejisi, güçlü ve geliştirilmesi gereken alanları belirlemek için nicel metrikleri nitel geri bildirimle birleştirir.
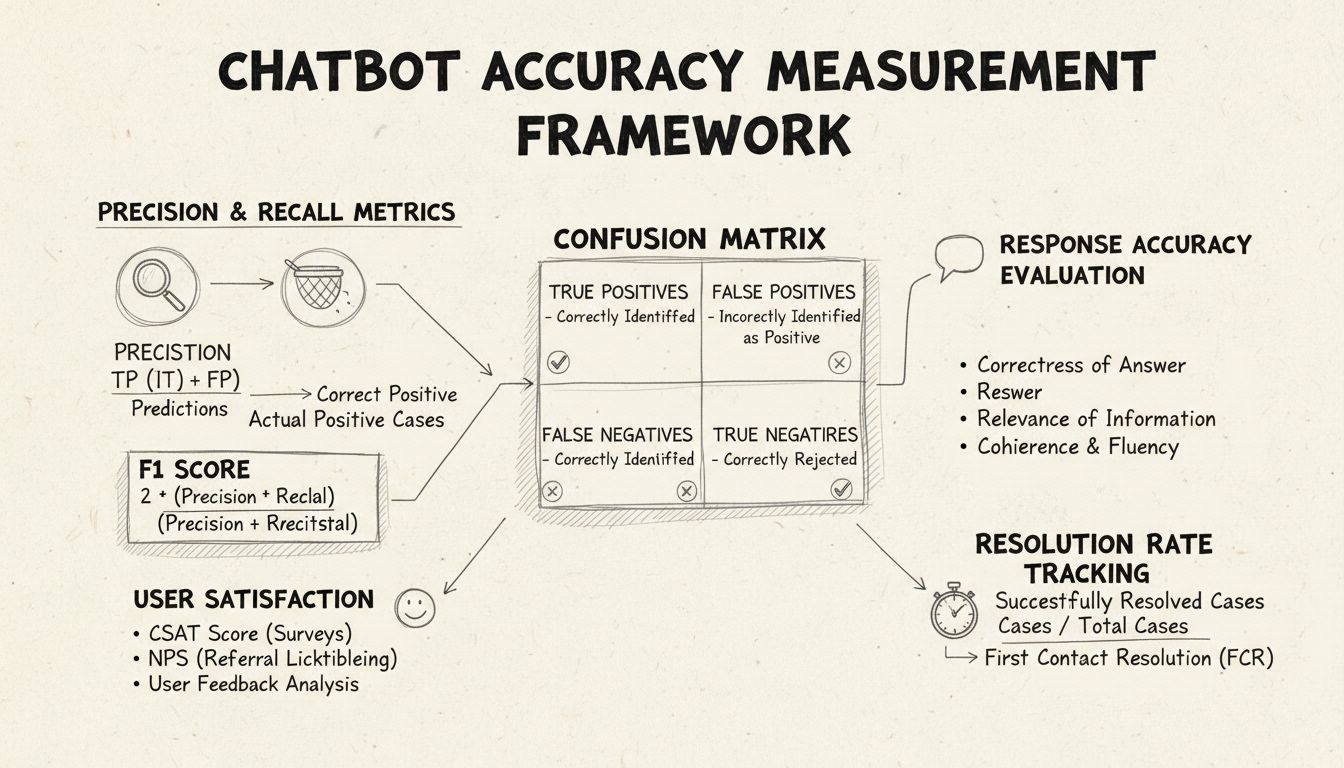
Hassasiyet ve geri çağırma, karışıklık matrisinden türetilen ve chatbot performansının farklı yönlerini ölçen temel metriklerdir. Hassasiyet, chatbot’un verdiği tüm yanıtlar arasından doğru olanların oranını temsil eder ve şu formülle hesaplanır: Hassasiyet = Doğru Pozitifler / (Doğru Pozitifler + Yanlış Pozitifler). Bu metrik şu soruyu cevaplar: “Chatbot bir yanıt verdiğinde, ne sıklıkla doğru oluyor?” Yüksek bir hassasiyet skoru, chatbot’un nadiren yanlış bilgi verdiğini gösterir ki bu da yardım masası senaryolarında kullanıcı güveni için kritiktir.
Geri çağırma ise, hassasiyet olarak da bilinir, chatbot’un vermesi gereken tüm doğru yanıtlar arasından verdiği doğru yanıtların oranını ölçer ve şu formülle hesaplanır: Geri çağırma = Doğru Pozitifler / (Doğru Pozitifler + Yanlış Negatifler). Bu metrik, chatbot’un tüm geçerli müşteri sorunlarını başarıyla tanıyıp yanıtlayıp yanıtlamadığını ele alır. Yardım masası bağlamında, yüksek geri çağırma, müşterilerin sorunları için yardım aldığını ve chatbot’un aslında yardımcı olabilecekken “yardım edemem” demediğini garanti eder. Hassasiyet ve geri çağırma arasındaki ilişki doğal bir denge yaratır: Birini optimize etmek genellikle diğerini azaltır, bu da iş önceliklerinize göre dikkatli bir denge gerektirir.
F1 Skoru, hem hassasiyet hem de geri çağırmayı dengeleyen tek bir metrik sunar ve harmonik ortalama olarak hesaplanır: F1 = 2 × (Hassasiyet × Geri Çağırma) / (Hassasiyet + Geri Çağırma). Bu metrik, birleşik bir performans göstergesine ihtiyaç duyduğunuzda veya bir sınıfın diğerlerinden çok daha fazla olduğu dengesiz veri kümeleriyle çalışırken özellikle değerlidir. Örneğin, chatbot’unuz 1.000 rutin sorgu ve yalnızca 50 karmaşık yönlendirme ile ilgileniyorsa, F1 Skoru, çoğunluk sınıfının metriği çarpıtmasını önler. F1 Skoru 0 ile 1 arasında değişir; 1, mükemmel hassasiyet ve geri çağırmayı temsil eder ve paydaşların genel chatbot performansını bir bakışta anlamasını kolaylaştırır.
Karışıklık matrisi, chatbot performansını dört kategoriye ayıran temel bir araçtır: Doğru Pozitifler (geçerli sorgulara doğru yanıtlar), Doğru Negatifler (kapsam dışı sorulara doğru şekilde yanıt vermemek), Yanlış Pozitifler (yanlış verilen yanıtlar) ve Yanlış Negatifler (yardım fırsatlarının kaçırılması). Bu matris, chatbot hatalarındaki belirli desenleri ortaya çıkararak hedefe yönelik iyileştirmeler sağlar. Örneğin, matris faturalandırma sorgularında yüksek yanlış negatif gösteriyorsa, chatbot’un eğitim verisinin faturalandırma ile ilgili yeterli örnek içermediği ve bu alanda güçlendirilmesi gerektiği anlaşılır.
| Metrik | Tanım | Hesaplama | İş Etkisi |
|---|---|---|---|
| Doğru Pozitifler (TP) | Geçerli sorgulara doğru yanıtlar | Doğrudan sayılır | Müşteri güveni oluşturur |
| Doğru Negatifler (TN) | Kapsam dışı sorulara doğru şekilde yanıt vermemek | Doğrudan sayılır | Yanlış bilgilendirmeyi önler |
| Yanlış Pozitifler (FP) | Yanlış verilen yanıtlar | Doğrudan sayılır | Güveni zedeler |
| Yanlış Negatifler (FN) | Yardım fırsatlarının kaçırılması | Doğrudan sayılır | Memnuniyeti azaltır |
| Hassasiyet | Olumlu tahminlerin kalitesi | TP / (TP + FP) | Güvenilirlik metriği |
| Geri Çağırma | Gerçek olumlu kapsama | TP / (TP + FN) | Tamamlayıcılık metriği |
| Doğruluk | Genel doğruluk | (TP + TN) / Toplam | Genel performans |
Yanıt doğruluğu, chatbot’un kullanıcının sorgusunu doğrudan ve gerçeklere uygun şekilde ne sıklıkla yanıtladığını ölçer. Bu, yalnızca basit örüntü eşlemenin ötesine geçerek, içeriğin doğru, güncel ve bağlama uygun olup olmadığını değerlendirmeyi içerir. Manuel inceleme süreçlerinde, insan değerlendiriciler, konuşmaların rastgele bir örneğini gözden geçirip chatbot yanıtlarını önceden tanımlanmış doğru yanıtlardan oluşan bir bilgi tabanı ile karşılaştırır. Otomatik karşılaştırma yöntemleri, sisteminizde saklanan beklenen yanıtlarla chatbot yanıtlarını eşleştirmek için doğal dil işleme teknikleri kullanabilir; ancak, chatbot referans yanıttan farklı bir ifadeyle doğru bilgi verdiğinde yanlış negatiflerden kaçınmak için dikkatli kalibrasyon gerektirir.
Yanıt alakası, chatbot’un verdiği yanıtın kullanıcının sorduğu şeyi gerçekten ele alıp almadığını değerlendirir, yanıt tamamen doğru olmasa bile. Bu boyut, chatbot’un tam cevabı olmasa da konuşmayı çözüme yaklaştıran faydalı bilgiler verdiği durumları yakalar. Koşin benzerliği gibi NLP tabanlı yöntemler, kullanıcının sorusu ile chatbot’un yanıtı arasındaki anlamsal benzerliği ölçerek otomatik bir alaka puanı sunar. Her etkileşim sonrası başparmak yukarı/aşağı gibi kullanıcı geri bildirimi mekanizmaları, en önemli kişilerden doğrudan alaka değerlendirmesi sağlar—yani müşterilerinizden. Bu geri bildirimler sürekli toplanıp analiz edilmelidir, böylece chatbot’un hangi sorgu türlerinde iyi, hangilerinde zayıf performans gösterdiği belirlenebilir.
Müşteri Memnuniyeti Skoru (CSAT), genellikle 1-5 ölçeğinde veya basit memnuniyet puanlarıyla yapılan doğrudan anketlerle chatbot etkileşimlerinden sonra kullanıcı memnuniyetini ölçer. Her etkileşimden sonra kullanıcılara memnuniyetlerini derecelendirmeleri istenir ve chatbot’un ihtiyaçlarını karşılayıp karşılamadığını gösteren anlık geri bildirim sağlanır. %80’in üzerindeki CSAT skorları genellikle güçlü performansı gösterirken, %60’ın altındaki skorlar önemli sorunları işaret eder. CSAT’ın avantajı basitliği ve doğrudanlığıdır—kullanıcılar açıkça memnun olup olmadıklarını bildirir—ancak, bu skor, konunun karmaşıklığı veya kullanıcı beklentileri gibi chatbot doğruluğunun ötesindeki etkenlerden de etkilenebilir.
Net Tavsiye Skoru, kullanıcıların chatbot’u başkalarına tavsiye etme olasılığını ölçer ve “Bu chatbot’u bir meslektaşınıza tavsiye etme olasılığınız nedir?” sorusuna 0-10 ölçeğinde yanıt alınarak hesaplanır. 9-10 cevaplayanlar destekleyici, 7-8 nötr, 0-6 ise olumsuz olarak kabul edilir. NPS = (Destekleyiciler - Olumsuzlar) / Toplam Katılımcı × 100. Bu metrik, uzun vadeli müşteri bağlılığı ile güçlü bir şekilde ilişkilidir ve chatbot’un kullanıcıların paylaşmak isteyeceği olumlu deneyimler yaratıp yaratmadığını gösterir. 50’nin üzerindeki NPS mükemmel kabul edilirken, negatif NPS ciddi performans sorunlarının göstergesidir.
Duygu analizi, chatbot etkileşimlerinden önce ve sonra kullanıcı mesajlarının duygusal tonunu inceleyerek memnuniyeti ölçer. Gelişmiş NLP teknikleri, mesajları olumlu, nötr veya olumsuz olarak sınıflandırır ve kullanıcıların sohbet sırasında daha memnun mu yoksa daha mı hayal kırıklığına uğradığını gösterir. Olumlu duygu değişimi, chatbot’un endişeleri başarılı şekilde giderdiğini gösterirken, olumsuz değişimler chatbot’un kullanıcıyı hayal kırıklığına uğrattığını veya ihtiyaçlarını karşılayamadığını gösterir. Bu metrik, geleneksel doğruluk metriklerinin kaçırdığı duygusal boyutları yakalayarak kullanıcı deneyimi kalitesini anlamak için değerli bir bağlam sunar.
İlk Temasta Çözüm oranı, müşteri sorunlarının chatbot tarafından insan temsilcisine yönlendirilmeden çözülme yüzdesini ölçer. Bu metrik, operasyonel verimlilik ve müşteri memnuniyetini doğrudan etkiler; çünkü müşteriler, sorunlarını anında çözmeyi tercih ederler. %70’in üzerindeki FCR oranları güçlü chatbot performansını gösterirken, %50’nin altındaki oranlar chatbot’un yaygın sorguları çözmede yetersiz bilgi veya yeteneğe sahip olduğunu gösterir. FCR’yi konu kategorisine göre takip etmek, chatbot’un hangi sorun türlerini iyi çözdüğünü, hangilerinde ise insan müdahalesine ihtiyaç duyduğunu saptayarak eğitim ve bilgi tabanı iyileştirmelerine rehberlik eder.
Yönlendirme oranı, chatbot’un görüşmeleri insan temsilcilerine ne sıklıkta devrettiğini ölçerken, geri dönüş sıklığı chatbot’un “Anlayamadım” veya “Lütfen sorunuzu tekrar ifade edin” gibi genel yanıtları ne sıklıkla verdiğini takip eder. %30’un üzerindeki yüksek yönlendirme oranları, chatbot’un birçok durumda bilgi veya güven eksikliği olduğunu gösterir. Yüksek geri dönüş sıklığı ise kötü niyet tanıma veya yetersiz eğitim verisine işaret eder. Bu metrikler, bilgi tabanı genişletme, model yeniden eğitimi veya gelişmiş doğal dil anlama bileşenleriyle giderilebilecek chatbot yeteneklerindeki belirli eksiklikleri ortaya çıkarır.
Yanıt süresi, chatbot’un kullanıcı mesajlarına ne kadar hızlı yanıt verdiğini ölçer ve genellikle milisaniyeden saniyeye kadar ölçülür. Kullanıcılar neredeyse anında yanıtlar bekler; 3-5 saniyeyi aşan gecikmeler memnuniyeti ciddi şekilde etkiler. İşlem süresi ise, kullanıcının iletişime geçtiği andan sorunun çözülmesi veya yönlendirilmesine kadar geçen toplam süreyi ölçer ve chatbot’un verimliliğini gösterir. Kısa işlem süreleri, chatbot’un sorunları hızla anladığını ve çözdüğünü gösterirken, uzun süreler, chatbot’un birden fazla açıklama turuna ihtiyaç duyduğunu veya karmaşık sorgularla zorlandığını gösterir. Bu metrikler, farklı konu kategorileri için ayrı ayrı takip edilmelidir; çünkü karmaşık teknik sorunlar, basit SSS sorularına kıyasla doğal olarak daha uzun işlem süreleri gerektirir.
Yargıç Olarak LLM, bir büyük dil modelinin başka bir AI sisteminin çıktılarının kalitesini değerlendirdiği sofistike bir değerlendirme yaklaşımını temsil eder. Bu metodoloji, doğruluk, alaka, tutarlılık, akıcılık, güvenlik, tamlık ve ton gibi birden çok kalite boyutunda chatbot yanıtlarını değerlendirmek için özellikle etkilidir. Araştırmalar, LLM yargıçlarının insan değerlendirmeleriyle %85’e kadar uyum sağlayabildiğini göstermektedir; bu da onları manuel incelemeye ölçeklenebilir bir alternatif haline getirir. Yaklaşım, belirli değerlendirme kriterlerinin tanımlanmasını, örneklerle detaylı yargıç istemlerinin hazırlanmasını, yargıca hem orijinal kullanıcı sorgusunun hem de chatbot yanıtının verilmesini ve yapılandırılmış puanlar veya detaylı geri bildirim alınmasını içerir.
LLM Yargıç sürecinde genellikle iki değerlendirme yaklaşımı kullanılır: Tekli çıktı değerlendirmesi (yargıç, bireysel bir yanıtı referanssız değerlendirme (doğru yanıt olmadan) veya referans bazlı karşılaştırma (beklenen yanıta karşı) ile puanlar) ve ikili karşılaştırma (yargıç, iki çıktıyı karşılaştırarak üstün olanı seçer). Bu esneklik, farklı chatbot sürümleri veya yapılandırmaları test ederken hem mutlak performansın hem de göreli iyileşmelerin değerlendirilmesine olanak tanır. FlowHunt platformu, sürükle-bırak arayüzü, ChatGPT ve Claude gibi önde gelen LLM entegrasyonları ve gelişmiş raporlama ile otomatik değerlendirmeler için CLI aracıyla LLM Yargıç yöntemini destekler.
Temel doğruluk hesaplamalarının ötesinde, detaylı karışıklık matrisi analizi, chatbot hatalarındaki belirli desenleri ortaya çıkarır. Hangi sorgu türlerinin yanlış pozitif veya yanlış negatif ürettiğini inceleyerek sistematik zayıflıklar belirlenebilir. Örneğin, matris chatbot’un sıklıkla faturalandırma sorularını teknik destek olarak yanlış sınıflandırdığını gösteriyorsa, bu durum eğitim verisinde bir dengesizlik veya fatura alanına özgü niyet tanıma sorunu olduğunu ortaya koyar. Farklı konu kategorileri için ayrı karışıklık matrisleri oluşturmak, genel model yeniden eğitimi yerine hedefe yönelik iyileştirmeler sağlar.
A/B testi, chatbot’un farklı sürümlerini anahtar metriklerde hangisinin daha iyi performans gösterdiğini belirlemek için karşılaştırır. Bu, farklı yanıt şablonlarını, bilgi tabanı yapılandırmalarını veya temel dil modellerini test etmeyi içerebilir. Trafiğin bir kısmını rastgele her sürüme yönlendirip FCR oranı, CSAT skorları ve yanıt doğruluğu gibi metrikleri karşılaştırarak hangi iyileştirmelerin uygulanacağına dair veri odaklı kararlar verebilirsiniz. A/B testleri, kullanıcı sorgularındaki doğal değişkenliği yakalamak ve sonuçların istatistiksel anlamlılığını sağlamak için yeterli süreyle yürütülmelidir.
FlowHunt, gelişmiş doğruluk ölçüm yetenekleriyle AI yardım masası chatbot’larını oluşturmak, dağıtmak ve değerlendirmek için entegre bir platform sunar. Platformun görsel oluşturucusu, teknik bilgisi olmayan kullanıcıların bile gelişmiş chatbot akışları oluşturmasını sağlar ve AI bileşenleri ChatGPT ve Claude gibi önde gelen dil modelleriyle entegre olur. FlowHunt’ın değerlendirme aracı, LLM Yargıç metodolojisinin uygulanmasını destekler; böylece özel değerlendirme kriterlerinizi tanımlayabilir ve tüm konuşma veri setinizde chatbot performansını otomatik olarak değerlendirebilirsiniz.
FlowHunt ile kapsamlı doğruluk ölçümü uygulamak için, iş hedeflerinizle uyumlu özel değerlendirme kriterlerinizi belirleyerek başlayın—ister doğruluk, ister hız, kullanıcı memnuniyeti ya da çözüm oranlarını önceliklendirin. Platformun yargıç LLM’ini, yanıtların nasıl değerlendirileceğini belirten detaylı istemlerle ve yüksek kaliteli ile zayıf yanıt örnekleriyle yapılandırın. Konuşma veri setinizi yükleyin veya canlı trafiğe bağlanın; ardından tüm metriklerde performansı gösteren detaylı raporlar oluşturmak için değerlendirmeleri başlatın. FlowHunt’ın kontrol paneli, chatbot performansına gerçek zamanlı görünürlük sağlar ve sorunların hızlıca tanımlanmasını ve iyileştirmelerin doğrulanmasını mümkün kılar.
İyileştirmeleri uygulamadan önce bir temel ölçüm belirleyin ve değişikliklerin etkisini değerlendirmek için bir referans noktası oluşturun. Performans bozulmasını veri kayması veya model bozulması nedeniyle erken tespit etmek için ölçümleri periyodik değil sürekli olarak toplayın. Kullanıcı puanları ve düzeltmelerin otomatik olarak eğitim sürecine geri beslendiği geri bildirim döngüleri uygulayın ve böylece chatbot doğruluğu sürekli olarak iyileşsin. Metrikleri konu kategorisi, kullanıcı türü ve zaman dilimine göre segmente edin; yalnızca toplu istatistiklere güvenmek yerine dikkat gerektiren özel alanları belirleyin.
Değerlendirme veri setinizin gerçek kullanıcı sorguları ve beklenen yanıtları temsil ettiğinden emin olun; gerçek kullanım kalıplarını yansıtmayan yapay test senaryolarından kaçının. Değerlendirme sisteminizin gerçek kaliteye kalibreli kalmasını sağlamak için otomatik metrikleri düzenli olarak insan yargısıyla doğrulayın; değerlendiricilerin konuşmaların bir örneğini manuel olarak incelemesini sağlayın. Ölçüm metodolojinizi ve metrik tanımlarınızı açıkça belgeleyin; böylece zaman içinde tutarlı değerlendirme ve sonuçların paydaşlara net iletimi sağlanır. Son olarak, her metrik için iş hedeflerinizle uyumlu performans hedefleri belirleyin; sürekli iyileştirme için hesap verebilirlik oluşturun ve optimizasyon çabalarına net hedefler sağlayın.
FlowHunt'ın gelişmiş AI otomasyon platformu, yerleşik doğruluk ölçüm araçları ve LLM tabanlı değerlendirme yetenekleriyle yüksek performanslı yardım masası chatbot'ları oluşturmanıza, dağıtmanıza ve değerlendirmenize yardımcı olur.
2025'te AI sohbet botu gerçekliğini doğrulamanın kanıtlanmış yöntemlerini öğrenin. Gerçek AI sistemlerini belirleyip sahte sohbet botlarından korunmak için tekn...
Yerleşik A/B testi yeteneklerine sahip en iyi yapay zeka chatbot platformlarını keşfedin. Dialogflow, Botpress, ManyChat, Intercom ve daha fazlasını karşılaştır...
Fonksiyonel, performans, güvenlik ve kullanılabilirlik testleri dahil olmak üzere kapsamlı AI sohbet robotu test stratejilerini öğrenin. Sohbet robotunuzun doğr...
Çerez Onayı
Göz atma deneyiminizi geliştirmek ve trafiğimizi analiz etmek için çerezleri kullanıyoruz. See our privacy policy.