
Çıkarımsal Yapay Zeka
Çıkarımsal Yapay Zeka, mevcut veri kaynaklarından belirli bilgileri tespit edip çekmeye odaklanan yapay zekanın uzmanlaşmış bir dalıdır. Üretici yapay zekanın a...
6 dakika okuma
Extractive AI
Data Extraction
+3

Yapay Zeka Arama, arama sorgularının arkasındaki niyet ve bağlamsal anlamı anlamak için makine öğrenimi modelleri kullanan, geleneksel anahtar kelime tabanlı aramalardan daha alakalı ve doğru sonuçlar sunan semantik veya vektör tabanlı bir arama metodolojisidir.
Yapay Zeka Arama, arama sorgularının bağlamını ve niyetini anlamak için makine öğrenimini kullanır ve sorguları daha doğru sonuçlar için sayısal vektörlere dönüştürür. Geleneksel anahtar kelime aramalarından farklı olarak, Yapay Zeka Arama semantik ilişkileri yorumlar ve bu sayede farklı veri türleri ve dilleri için etkilidir.
Yapay Zeka Arama, sıklıkla semantik veya vektör arama olarak da adlandırılır, arama sorgularının arkasındaki niyeti ve bağlamsal anlamı anlamak için makine öğrenimi modellerinden yararlanan bir arama metodolojisidir. Geleneksel anahtar kelime tabanlı aramadan farklı olarak, yapay zeka arama verileri ve sorguları vektör veya gömü adı verilen sayısal temsillere dönüştürür. Bu, arama motorunun farklı veri parçaları arasındaki semantik ilişkileri kavramasını sağlar, böylece tam anahtar kelimeler mevcut olmasa bile daha alakalı ve doğru sonuçlar sunar.
Yapay Zeka Arama, arama teknolojilerinde önemli bir evrimi temsil eder. Geleneksel arama motorları, sorgu ve belgelerdeki belirli terimlerin varlığına dayalı olarak alaka düzeyini belirleyen anahtar kelime eşleştirmesine büyük ölçüde güvenir. Ancak Yapay Zeka Arama, sorguların ve verilerin altında yatan bağlamı ve anlamı kavramak için makine öğrenimi modellerini kullanır.
Metin, görsel, ses ve diğer yapılandırılmamış verileri yüksek boyutlu vektörlere dönüştürerek, Yapay Zeka Arama farklı içerik parçaları arasındaki benzerliği ölçebilir. Bu yaklaşım, arama motorunun tam olarak sorguda kullanılan anahtar kelimeleri içermeseler bile bağlamsal olarak alakalı sonuçlar sunmasını sağlar.
Temel Bileşenler:
Yapay Zeka Aramanın merkezinde vektör gömü kavramı yer alır. Vektör gömüler, metin, görsel veya diğer veri türlerinin anlamsal anlamını yakalayan sayısal temsillerdir. Bu gömüler, benzer veri parçalarını çok boyutlu vektör uzayında birbirine yakın konumlandırır.
Nasıl Çalışır:
Örnek:
Bugün ücretsiz denemenizi başlatın ve günler içinde sonuçları görün.
Geleneksel anahtar kelime tabanlı arama motorları, sorgudaki terimleri içeren belgelerle terimleri eşleştirerek çalışır. Sonuçları sıralamak için ters indeksler ve terim sıklığı gibi tekniklere güvenirler.
Anahtar Kelime Tabanlı Aramanın Sınırlamaları:
Yapay Zeka Aramanın Avantajları:
| Özellik | Anahtar Kelime Tabanlı Arama | Yapay Zeka Arama (Semantik/Vektör) |
|---|---|---|
| Eşleştirme | Tam anahtar kelime eşleşmeleri | Anlamsal benzerlik |
| Bağlam Farkındalığı | Sınırlı | Yüksek |
| Eşanlamlı İşleme | Manuel eşanlamlı listeleri gerekir | Gömülerle otomatik |
| Yazım Hataları | Bulanık arama yoksa başarısız | Anlamsal bağlam sayesinde daha toleranslı |
| Niyet Anlayışı | Minimum | Önemli ölçüde |
Semantik Arama, Yapay Zeka Aramanın çekirdek uygulamasıdır ve kullanıcının niyetini ve sorguların bağlamsal anlamını anlamaya odaklanır.
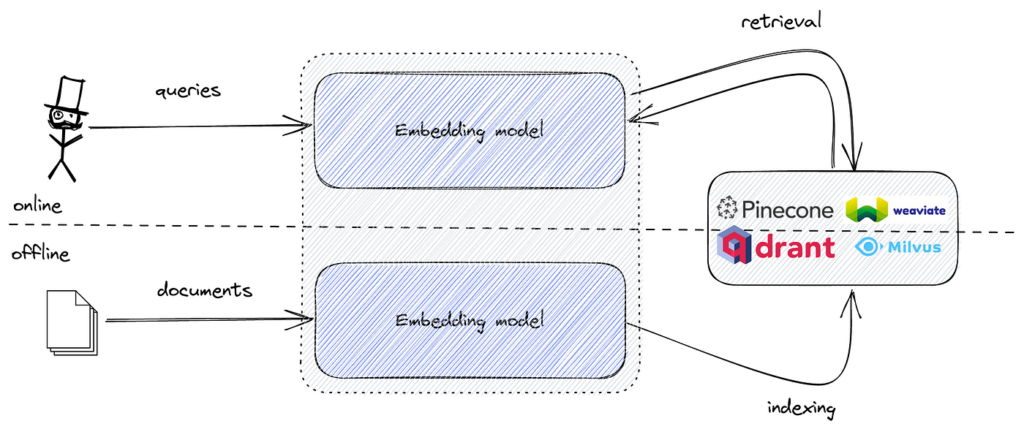
Süreç:
Temel Teknikler:
En son ipuçlarını, trendleri ve teklifleri ücretsiz alın.
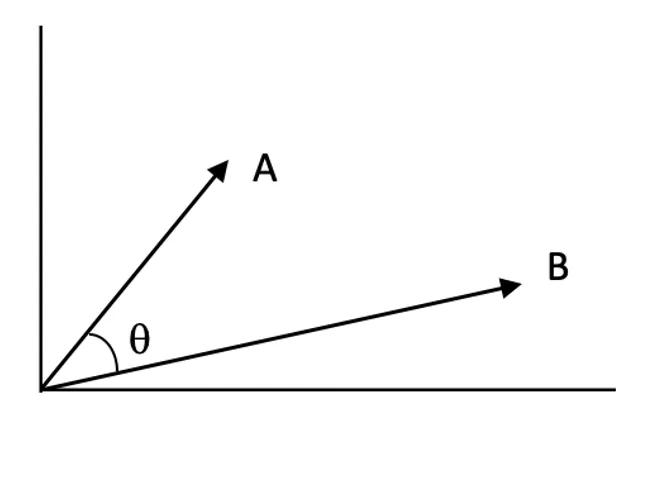
Benzerlik Puanları:
Benzerlik puanları, iki vektörün vektör uzayında ne kadar yakından ilişkili olduğunu nicelendirir. Yüksek puan, sorgu ile bir belgenin daha alakalı olduğunu gösterir.
Yaklaşık En Yakın Komşu (ANN) Algoritmaları:
Yüksek boyutlu uzaylarda tam en yakın komşuları bulmak hesaplama açısından yoğundur. ANN algoritmaları verimli yakınsama sağlar.
Yapay Zeka Arama, anahtar kelime eşleşmesinin ötesinde veriyi anlama ve yorumlama yeteneği sayesinde pek çok sektörde geniş uygulama alanları açar.
Açıklama: Semantik Arama, sorguların arkasındaki niyeti yorumlayarak kullanıcı deneyimini geliştirir ve bağlamsal olarak alakalı sonuçlar sunar.
Örnekler:
Açıklama: Kullanıcı tercihleri ve davranışlarını anlayarak, Yapay Zeka Arama kişiselleştirilmiş içerik veya ürün önerileri sunabilir.
Örnekler:
Açıklama: Yapay Zeka Arama, sistemlerin kullanıcı sorgularını anlayıp belgelerden kesin bilgilerle yanıtlamasını sağlar.
Örnekler:
Açıklama: Yapay Zeka Arama, gömülere dönüştürerek görsel, ses ve video gibi yapılandırılmamış veri türlerinde de indeksleme ve arama yapabilir.
Örnekler:
Yapay Zeka Aramanın AI otomasyon ve sohbet botlarına entegrasyonu, bu sistemlerin yeteneklerini önemli ölçüde geliştirir.
Faydalar:
Uygulama Adımları:
Kullanım Durumu Örneği:
Yapay Zeka Arama birçok avantaj sunsa da, bazı zorluklar göz önünde bulundurulmalıdır:
Çözüm Stratejileri:
Yapay zekada semantik ve vektör arama, geleneksel anahtar kelime ve bulanık aramalara güçlü alternatifler olarak ortaya çıkmış, sorguların arkasındaki bağlamı ve anlamı anlayarak arama sonuçlarının alaka düzeyini ve doğruluğunu önemli ölçüde artırmıştır.
Semantik arama uygularken, metinsel veriler metnin anlamsal anlamını yakalayan vektör gömülerine dönüştürülür. Bu gömüler yüksek boyutlu sayısal temsillerdir. Bu gömülerde verimli şekilde arama yapmak ve bir sorgu gömüsüne en benzer olanları bulmak için yüksek boyutlu uzaylarda benzerlik araması için optimize edilmiş bir araca ihtiyaç vardır.
FAISS, bu görevi verimli şekilde yerine getirmek için gerekli algoritma ve veri yapılarını sağlar. Semantik gömüler ile FAISS’i birleştirerek, büyük veri kümelerini düşük gecikmeyle işleyebilen güçlü bir semantik arama motoru oluşturabiliriz.
Python’da FAISS ile semantik arama uygulamak birkaç adım içerir:
Şimdi her adımı detaylandıralım.
Veri setinizi hazırlayın (ör. makaleler, destek talepleri, ürün açıklamaları).
Örnek:
documents = [
"Platformumuzda şifrenizi nasıl sıfırlarsınız.",
"Ağ bağlantı sorunlarını giderme.",
"Yazılım güncellemelerinin kurulumu rehberi.",
"Veri yedekleme ve kurtarma için en iyi uygulamalar.",
"Gelişmiş güvenlik için iki faktörlü kimlik doğrulama kurulumu."
]
Metin verinizi gerektiği gibi temizleyin ve biçimlendirin.
Metinsel veriyi Hugging Face (transformers veya sentence-transformers) gibi kütüphanelerden önceden eğitilmiş Transformer modelleriyle vektör gömülere dönüştürün.
Örnek:
from sentence_transformers import SentenceTransformer
import numpy as np
# Önceden eğitilmiş modeli yükleyin
model = SentenceTransformer('sentence-transformers/all-MiniLM-L6-v2')
# Tüm belgeler için gömü oluşturun
embeddings = model.encode(documents, convert_to_tensor=False)
embeddings = np.array(embeddings).astype('float32')
float32‘ye dönüştürülür.Gömüleri saklamak ve verimli benzerlik araması sağlamak için FAISS indeksi oluşturun.
Örnek:
import faiss
embedding_dim = embeddings.shape[1]
index = faiss.IndexFlatL2(embedding_dim)
index.add(embeddings)
IndexFlatL2, L2 (Öklid) uzaklığı ile brute-force arama yapar.Kullanıcı sorgusunu gömüye dönüştürüp en yakın komşuları bulun.
Örnek:
query = "Hesap şifremi nasıl değiştiririm?"
query_embedding = model.encode([query], convert_to_tensor=False)
query_embedding = np.array(query_embedding).astype('float32')
k = 3
distances, indices = index.search(query_embedding, k)
İndeksler aracılığıyla en alakalı belgeleri gösterin.
Örnek:
print("Sorgunuz için en iyi sonuçlar:")
for idx in indices[0]:
print(documents[idx])
Beklenen Çıktı:
Sorgunuz için en iyi sonuçlar:
Platformumuzda şifrenizi nasıl sıfırlarsınız.
Gelişmiş güvenlik için iki faktörlü kimlik doğrulama kurulumu.
Veri yedekleme ve kurtarma için en iyi uygulamalar.
FAISS çeşitli indeks türleri sunar:
Ters Dosya İndeksi (IndexIVFFlat) Kullanımı:
nlist = 100
quantizer = faiss.IndexFlatL2(embedding_dim)
index = faiss.IndexIVFFlat(quantizer, embedding_dim, nlist, faiss.METRIC_L2)
index.train(embeddings)
index.add(embeddings)
Normalizasyon ve İç Çarpım Araması:
Metinsel veriler için kosinüs benzerliği kullanmak daha etkili olabilir
Yapay Zeka Arama, makine öğrenimi ve vektör gömülerini kullanarak sorguların niyetini ve bağlamsal anlamını anlayan, geleneksel anahtar kelime tabanlı aramadan daha doğru ve alakalı sonuçlar sunan modern bir arama metodolojisidir.
Anahtar kelime tabanlı arama tam eşleşmelere dayanırken, Yapay Zeka Arama sorguların arkasındaki semantik ilişkileri ve niyeti yorumlar, doğal dil ve belirsiz girdiler için etkili hale getirir.
Vektör gömüler, metin, görsel veya diğer veri türlerinin anlamsal anlamını yakalayan sayısal temsilleridir; arama motorunun farklı veri parçaları arasındaki benzerliği ve bağlamı ölçmesine olanak tanır.
Yapay Zeka Arama, e-ticarette semantik aramayı, akışta kişiselleştirilmiş önerileri, müşteri desteğinde soru-cevap sistemlerini, yapılandırılmamış veri taramasını ve araştırma ve kurumsal alanda belge getirimi sağlar.
Popüler araçlar arasında verimli vektör benzerlik araması için FAISS ve gömülerin ölçeklenebilir depolama ve getirilmesi için Pinecone, Milvus, Qdrant, Weaviate, Elasticsearch ve Pgvector gibi vektör veritabanları bulunur.
Yapay Zeka Arama entegrasyonu ile sohbet botları ve otomasyon sistemleri kullanıcı sorgularını daha derinlemesine anlayabilir, bağlamsal olarak alakalı yanıtlar alabilir ve dinamik, kişiselleştirilmiş yanıtlar sunabilir.
Zorluklar arasında yüksek hesaplama gereksinimleri, model yorumlanabilirliğinde karmaşıklık, yüksek kaliteli veri ihtiyacı ve hassas bilgilerde gizlilik ve güvenliğin sağlanması bulunur.
FAISS, yüksek boyutlu vektör gömülerde verimli benzerlik araması için açık kaynaklı bir kütüphanedir ve büyük ölçekli veri kümelerini işleyebilen semantik arama motorları oluşturmak için yaygın olarak kullanılır.
Yapay zeka destekli semantik aramanın bilgi getirimi, sohbet botları ve otomasyon iş akışlarınızı nasıl dönüştürebileceğini keşfedin.
Çıkarımsal Yapay Zeka, mevcut veri kaynaklarından belirli bilgileri tespit edip çekmeye odaklanan yapay zekanın uzmanlaşmış bir dalıdır. Üretici yapay zekanın a...
Sezgiler, yapay zekada deneyimsel bilgiyi ve kestirme kuralları kullanarak karmaşık arama problemlerini sadeleştirir, algoritmalara (A* ve Yokuş Tırmanma gibi) ...

Bir Yapay Zeka İntihal Kontrolü'nün içerik özgünlüğünü ve bütünlüğünü nasıl sağladığını keşfedin. Özellikleri, faydaları ve FlowHunt.io kaynaklarıyla nasıl etki...
Çerez Onayı
Göz atma deneyiminizi geliştirmek ve trafiğimizi analiz etmek için çerezleri kullanıyoruz. See our privacy policy.