Luồng
Luồng là bộ não đứng sau mọi thứ trong FlowHunt. Tìm hiểu cách xây dựng chúng với trình dựng trực quan không cần mã, từ việc đặt thành phần đầu tiên đến tích hợ...
3 phút đọc
AI
No-Code
+4

Bộ công cụ CLI mã nguồn mở mới của FlowHunt cho phép đánh giá luồng toàn diện với LLM làm Giám khảo, cung cấp báo cáo chi tiết và đánh giá chất lượng tự động cho quy trình AI.
Chúng tôi rất vui mừng thông báo phát hành Bộ công cụ FlowHunt CLI – công cụ dòng lệnh mã nguồn mở mới của chúng tôi được thiết kế để cách mạng hóa cách các nhà phát triển đánh giá và kiểm thử luồng AI. Bộ công cụ mạnh mẽ này mang các khả năng đánh giá luồng cấp doanh nghiệp đến cộng đồng mã nguồn mở, với tính năng báo cáo nâng cao và triển khai “LLM làm Giám khảo” độc đáo.
Bộ công cụ FlowHunt CLI đánh dấu một bước tiến lớn trong kiểm thử và đánh giá quy trình AI. Hiện đã có mặt trên GitHub , bộ công cụ mã nguồn mở này cung cấp cho nhà phát triển các công cụ toàn diện cho:
Bộ công cụ thể hiện cam kết của chúng tôi với sự minh bạch và phát triển cộng đồng, giúp kỹ thuật đánh giá AI tiên tiến trở nên dễ tiếp cận với nhà phát triển trên toàn thế giới.
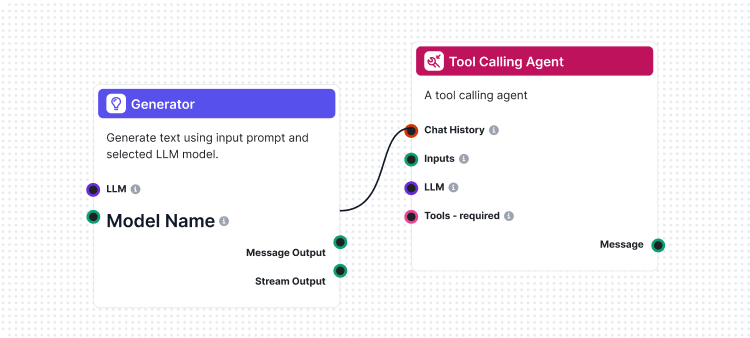
Một trong những tính năng sáng tạo nhất của bộ công cụ CLI của chúng tôi là triển khai “LLM làm Giám khảo”. Phương pháp này sử dụng trí tuệ nhân tạo để đánh giá chất lượng và tính chính xác của phản hồi do AI tạo ra – về cơ bản là để AI đánh giá hiệu suất AI với khả năng lý luận tinh vi.
Điểm khác biệt của chúng tôi là sử dụng chính FlowHunt để tạo luồng đánh giá. Cách tiếp cận meta này chứng minh sức mạnh và tính linh hoạt của nền tảng, đồng thời tạo ra hệ thống đánh giá vững chắc. Luồng LLM làm Giám khảo bao gồm một số thành phần kết nối với nhau:
1. Mẫu Prompt: Soạn prompt đánh giá với tiêu chí cụ thể
2. Bộ sinh đầu ra có cấu trúc: Xử lý đánh giá bằng LLM
3. Bộ phân tích dữ liệu: Định dạng đầu ra có cấu trúc cho báo cáo
4. Đầu ra Chat: Trình bày kết quả đánh giá cuối cùng
Trọng tâm của hệ thống LLM làm Giám khảo là một prompt được thiết kế kỹ lưỡng để đảm bảo tính nhất quán và đáng tin cậy. Đây là mẫu prompt cốt lõi mà chúng tôi sử dụng:
You will be given an ANSWER and REFERENCE couple.
Your task is to provide the following:
1. a 'total_rating' scoring: how close is the ANSWER to the REFERENCE
2. a binary label 'correctness' which can be either 'correct' or 'incorrect', which defines if the ANSWER is correct or not
3. and 'reasoning', which describes the reason behind your choice of scoring and correctness/incorrectness of ANSWER
An ANSWER is correct when it is the same as the REFERENCE in all facts and details, even if worded differently. the ANSWER is incorrect if it contradicts the REFERENCE, changes or omits details. its ok if the ANSWER has more details comparing to REFERENCE.
'total rating' is a scale of 1 to 4, where 1 means that the ANSWER is not the same as REFERENCE at all, and 4 means that the ANSWER is the same as the REFERENCE in all facts and details even if worded differently.
Here is the scale you should use to build your answer:
1: The ANSWER is contradicts the REFERENCE completely, adds additional claims, changes or omits details
2: The ANSWER points to the same topic but the details are omitted or changed completely comparing to REFERENCE
3: The ANSWER's references are not completely correct, but the details are somewhat close to the details mentioned in the REFERENCE. its ok, if there are added details in ANSWER comparing to REFERENCES.
4: The ANSWER is the same as the REFERENCE in all facts and details, even if worded differently. its ok, if there are added details in ANSWER comparing to REFERENCES. if there are sources available in REFERENCE, its exactly the same as ANSWER and is for sure mentioned in ANSWER
REFERENCE
===
{target_response}
===
ANSWER
===
{actual_response}
===
Prompt này đảm bảo giám khảo LLM của chúng tôi cung cấp:
Bắt đầu dùng thử miễn phí ngay hôm nay và xem kết quả trong vài ngày.
Luồng LLM làm Giám khảo thể hiện thiết kế quy trình AI tiên tiến bằng trình dựng luồng trực quan của FlowHunt. Các thành phần phối hợp như sau:
Luồng bắt đầu với thành phần Chat Input nhận yêu cầu đánh giá bao gồm phản hồi thực tế và đáp án tham chiếu.
Thành phần Prompt Template xây dựng động prompt đánh giá bằng cách:
{target_response}{actual_response}Structured Output Generator xử lý prompt bằng LLM đã chọn và tạo đầu ra có cấu trúc gồm:
total_rating: Điểm số từ 1-4correctness: Phân loại đúng/sai nhị phânreasoning: Giải thích chi tiết cho đánh giáThành phần Parse Data định dạng đầu ra có cấu trúc thành dạng dễ đọc, và Chat Output trình bày kết quả đánh giá cuối cùng.
Hệ thống LLM làm Giám khảo cung cấp nhiều khả năng nâng cao giúp đánh giá luồng AI hiệu quả:
Khác với so khớp chuỗi đơn giản, giám khảo LLM của chúng tôi hiểu:
Thang điểm 4 mức cho phép đánh giá chi tiết:
Mỗi đánh giá đều kèm giải thích chi tiết, cho phép:
Nhận các mẹo, xu hướng và ưu đãi mới nhất miễn phí.
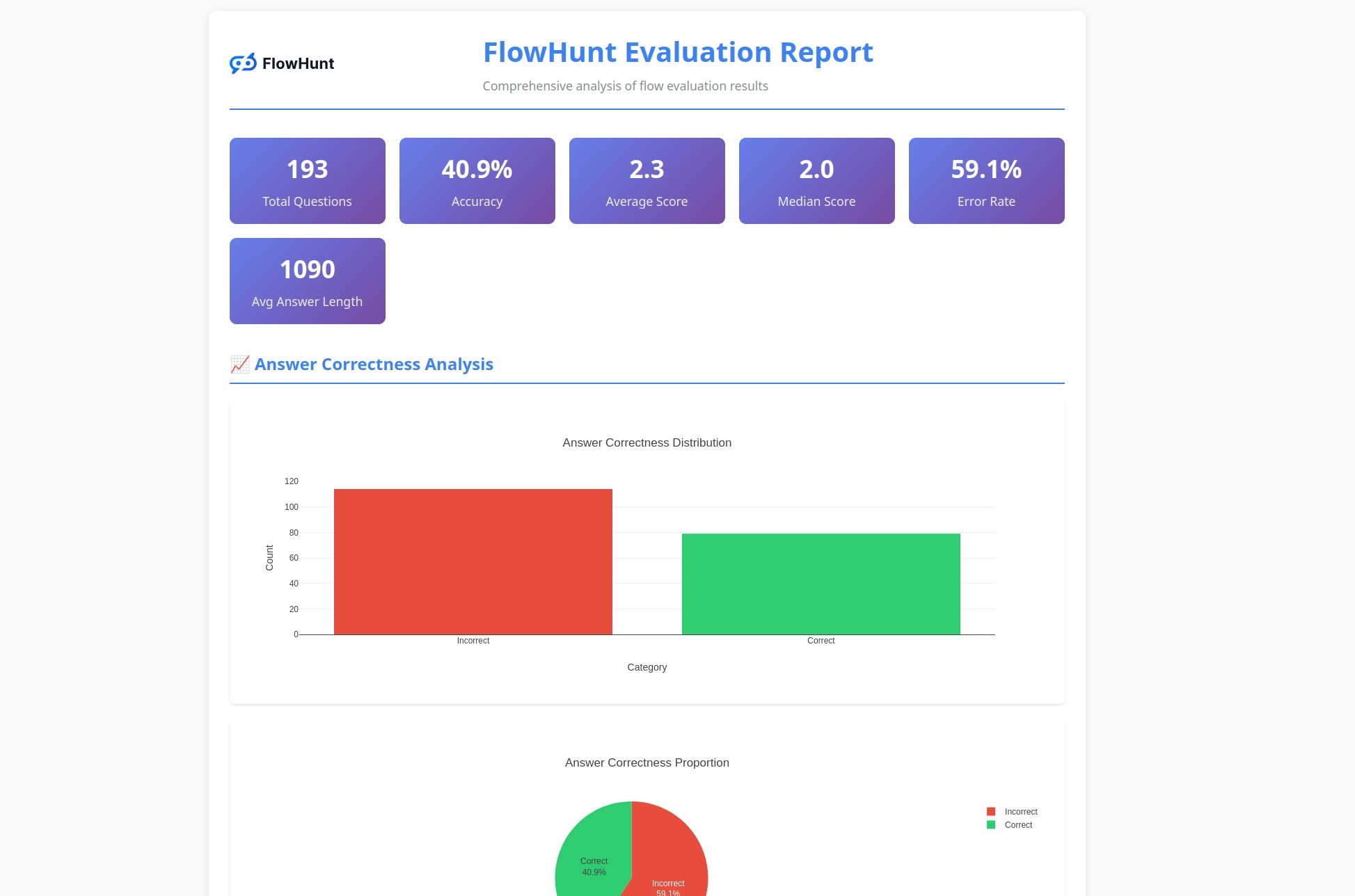
Bộ công cụ CLI tạo ra các báo cáo chi tiết cung cấp thông tin thực tiễn về hiệu suất luồng:
Sẵn sàng đánh giá các luồng AI của bạn với công cụ chuyên nghiệp? Làm theo hướng dẫn sau:
Cài đặt một dòng lệnh (Khuyến nghị) cho macOS và Linux:
curl -sSL https://raw.githubusercontent.com/yasha-dev1/flowhunt-toolkit/main/install.sh | bash
Lệnh này sẽ tự động:
flowhunt vào PATHCài đặt thủ công:
# Sao chép kho lưu trữ
git clone https://github.com/yasha-dev1/flowhunt-toolkit.git
cd flowhunt-toolkit
# Cài đặt bằng pip
pip install -e .
Kiểm tra cài đặt:
flowhunt --help
flowhunt --version
1. Xác thực Đầu tiên, xác thực với API FlowHunt của bạn:
flowhunt auth
2. Liệt kê các luồng của bạn
flowhunt flows list
3. Đánh giá một luồng Tạo file CSV với dữ liệu kiểm thử:
flow_input,expected_output
"What is 2+2?","4"
"What is the capital of France?","Paris"
Chạy đánh giá với LLM làm Giám khảo:
flowhunt evaluate your-flow-id path/to/test-data.csv --judge-flow-id your-judge-flow-id
4. Thực thi hàng loạt các luồng
flowhunt batch-run your-flow-id input.csv --output-dir results/
Hệ thống đánh giá cung cấp phân tích toàn diện:
flowhunt evaluate FLOW_ID TEST_DATA.csv \
--judge-flow-id JUDGE_FLOW_ID \
--output-dir eval_results/ \
--batch-size 10 \
--verbose
Tính năng bao gồm:
Bộ công cụ CLI tích hợp liền mạch với nền tảng FlowHunt, cho phép bạn:
Phát hành bộ công cụ CLI của chúng tôi không chỉ là một công cụ mới – đó là tầm nhìn về tương lai phát triển AI nơi:
Chất lượng được đo lường: Kỹ thuật đánh giá tiên tiến giúp hiệu suất AI có thể định lượng và so sánh.
Kiểm thử được tự động hóa: Khung kiểm thử toàn diện giảm bớt thao tác thủ công, tăng độ tin cậy.
Minh bạch là tiêu chuẩn: Báo cáo lý do chi tiết giúp hành vi AI dễ hiểu và dễ gỡ lỗi.
Cộng đồng thúc đẩy đổi mới: Công cụ mã nguồn mở khuyến khích cải tiến hợp tác và chia sẻ tri thức.
Bằng việc mở mã nguồn Bộ công cụ FlowHunt CLI, chúng tôi thể hiện cam kết với:
Bộ công cụ FlowHunt CLI với LLM làm Giám khảo đánh dấu một bước tiến lớn trong khả năng đánh giá luồng AI. Kết hợp logic đánh giá tinh vi, báo cáo toàn diện và tính mở mã nguồn, chúng tôi trao quyền cho nhà phát triển xây dựng hệ thống AI tốt hơn, tin cậy hơn.
Cách tiếp cận meta sử dụng FlowHunt để đánh giá chính các luồng FlowHunt minh chứng sự trưởng thành và linh hoạt của nền tảng, đồng thời cung cấp công cụ mạnh mẽ cho cộng đồng phát triển AI rộng lớn.
Dù bạn đang xây dựng chatbot đơn giản hay hệ thống đa tác nhân phức tạp, Bộ công cụ FlowHunt CLI cung cấp hạ tầng đánh giá cần thiết để đảm bảo chất lượng, độ tin cậy và cải tiến liên tục.
Sẵn sàng nâng tầm đánh giá luồng AI của bạn? Truy cập kho GitHub của chúng tôi để bắt đầu với Bộ công cụ FlowHunt CLI ngay hôm nay và trải nghiệm sức mạnh của LLM làm Giám khảo.
Tương lai phát triển AI đã đến – và nó là mã nguồn mở.
Bộ công cụ FlowHunt CLI là một công cụ dòng lệnh mã nguồn mở để đánh giá các luồng AI với khả năng báo cáo toàn diện. Nó bao gồm các tính năng như đánh giá LLM làm Giám khảo, phân tích đúng/sai kết quả và các chỉ số hiệu suất chi tiết.
LLM làm Giám khảo sử dụng một luồng AI tinh vi được xây dựng trong FlowHunt để đánh giá các luồng khác. Nó so sánh phản hồi thực tế với đáp án tham chiếu, cung cấp xếp hạng, đánh giá đúng/sai và giải thích chi tiết cho từng đánh giá.
Bộ công cụ FlowHunt CLI là mã nguồn mở và có sẵn trên GitHub tại https://github.com/yasha-dev1/flowhunt-toolkit. Bạn có thể sao chép, đóng góp và sử dụng miễn phí cho nhu cầu đánh giá luồng AI của mình.
Bộ công cụ tạo ra các báo cáo toàn diện bao gồm phân tích đúng/sai kết quả, đánh giá LLM làm Giám khảo với xếp hạng và giải thích, các chỉ số hiệu suất và phân tích chi tiết hành vi luồng qua các bộ kiểm thử khác nhau.
Có! Luồng LLM làm Giám khảo được xây dựng bằng nền tảng FlowHunt và có thể tùy chỉnh cho nhiều tình huống đánh giá khác nhau. Bạn có thể sửa đổi mẫu prompt và tiêu chí đánh giá để phù hợp với trường hợp sử dụng cụ thể của mình.
Yasha là một nhà phát triển phần mềm tài năng, chuyên về Python, Java và học máy. Yasha viết các bài báo kỹ thuật về AI, kỹ thuật prompt và phát triển chatbot.

Xây dựng và đánh giá các quy trình AI tinh vi với nền tảng FlowHunt. Bắt đầu tạo luồng có thể đánh giá các luồng khác ngay hôm nay.
Luồng là bộ não đứng sau mọi thứ trong FlowHunt. Tìm hiểu cách xây dựng chúng với trình dựng trực quan không cần mã, từ việc đặt thành phần đầu tiên đến tích hợ...

FlowHunt ra mắt các cập nhật lớn bao gồm máy chủ MCP tùy chỉnh, đăng nhập SSO cho khách hàng doanh nghiệp, tích hợp Odoo, các mô hình AI mới (Grok 4 và Kimi K2)...
Tích hợp FlowHunt với MCP Discovery để tự động kiểm tra máy chủ MCP, tạo tài liệu đa định dạng và tối ưu hóa quy trình CI/CD cho các nhà phát triển quản lý năng...
Đồng Ý Cookie
Chúng tôi sử dụng cookie để cải thiện trải nghiệm duyệt web của bạn và phân tích lưu lượng truy cập của mình. See our privacy policy.