
Créer un évaluateur de lisibilité dans FlowHunt
Vérifiez tous les indicateurs de lisibilité reconnus. Essayez notre outil gratuit d'évaluation de lisibilité et apprenez à créer le vôtre !
2 min de lecture
AI Tools
Readability
+3

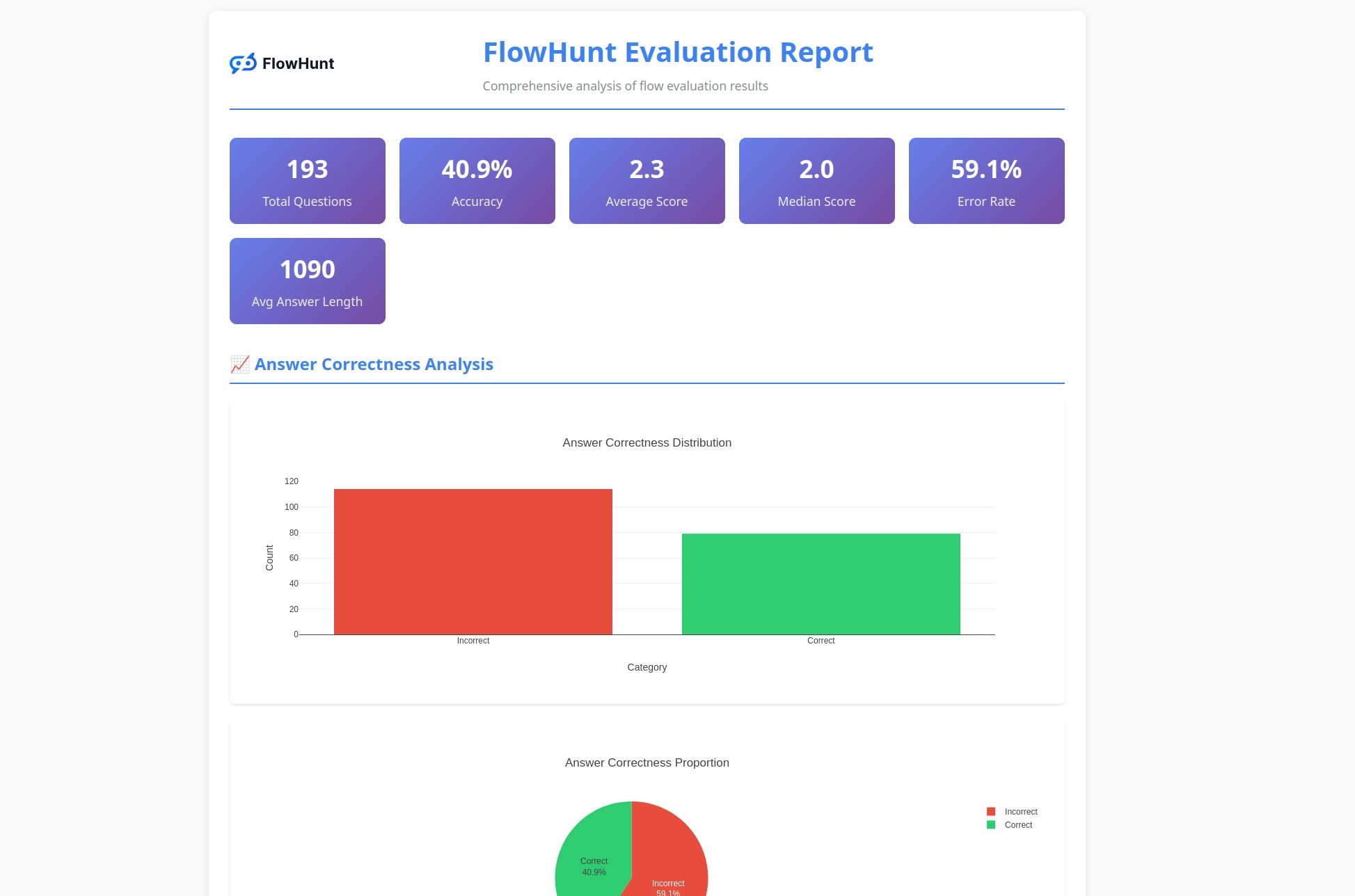
Le nouveau toolkit CLI open source de FlowHunt permet une évaluation complète des flux avec LLM comme juge, offrant un reporting détaillé et une évaluation automatisée de la qualité des workflows IA.
Nous sommes ravis d’annoncer la sortie du FlowHunt CLI Toolkit – notre nouvel outil open source en ligne de commande conçu pour révolutionner la façon dont les développeurs évaluent et testent les flux d’IA. Ce puissant toolkit apporte des capacités d’évaluation de flux de niveau entreprise à la communauté open source, avec un reporting avancé et notre innovation « LLM comme juge ».
Le FlowHunt CLI Toolkit représente une avancée majeure dans le test et l’évaluation des workflows IA. Disponible dès maintenant sur GitHub , ce toolkit open source offre aux développeurs des outils complets pour :
Le toolkit incarne notre engagement envers la transparence et le développement communautaire, rendant les techniques avancées d’évaluation IA accessibles aux développeurs du monde entier.
L’une des fonctionnalités les plus innovantes de notre toolkit CLI est l’implémentation « LLM comme juge ». Cette approche utilise l’intelligence artificielle pour évaluer la qualité et la justesse des réponses générées par l’IA – il s’agit littéralement de faire juger une IA par une autre IA dotée de capacités de raisonnement sophistiquées.
Notre implémentation se distingue par le fait que nous avons utilisé FlowHunt lui-même pour créer le flux d’évaluation. Cette approche méta démontre la puissance et la flexibilité de notre plateforme tout en fournissant un système d’évaluation robuste. Le flux LLM comme juge se compose de plusieurs composants interconnectés :
1. Modèle de prompt : Génère le prompt d’évaluation selon des critères spécifiques
2. Générateur de sortie structurée : Traite l’évaluation via un LLM
3. Parseur de données : Formate la sortie structurée pour le reporting
4. Sortie conversationnelle : Présente les résultats finaux de l’évaluation
Au cœur de notre système LLM comme juge se trouve un prompt soigneusement élaboré pour garantir des évaluations cohérentes et fiables. Voici le modèle de prompt que nous utilisons :
You will be given an ANSWER and REFERENCE couple.
Your task is to provide the following:
1. a 'total_rating' scoring: how close is the ANSWER to the REFERENCE
2. a binary label 'correctness' which can be either 'correct' or 'incorrect', which defines if the ANSWER is correct or not
3. and 'reasoning', which describes the reason behind your choice of scoring and correctness/incorrectness of ANSWER
An ANSWER is correct when it is the same as the REFERENCE in all facts and details, even if worded differently. the ANSWER is incorrect if it contradicts the REFERENCE, changes or omits details. its ok if the ANSWER has more details comparing to REFERENCE.
'total rating' is a scale of 1 to 4, where 1 means that the ANSWER is not the same as REFERENCE at all, and 4 means that the ANSWER is the same as the REFERENCE in all facts and details even if worded differently.
Here is the scale you should use to build your answer:
1: The ANSWER is contradicts the REFERENCE completely, adds additional claims, changes or omits details
2: The ANSWER points to the same topic but the details are omitted or changed completely comparing to REFERENCE
3: The ANSWER's references are not completely correct, but the details are somewhat close to the details mentioned in the REFERENCE. its ok, if there are added details in ANSWER comparing to REFERENCES.
4: The ANSWER is the same as the REFERENCE in all facts and details, even if worded differently. its ok, if there are added details in ANSWER comparing to REFERENCES. if there are sources available in REFERENCE, its exactly the same as ANSWER and is for sure mentioned in ANSWER
REFERENCE
===
{target_response}
===
ANSWER
===
{actual_response}
===
Ce prompt garantit que notre juge LLM fournisse :
Commencez votre essai gratuit aujourd'hui et voyez les résultats en quelques jours.
Le flux LLM comme juge illustre la conception avancée de workflows IA avec le créateur visuel de FlowHunt. Voici comment les composants interagissent :
Le flux commence par un composant Entrée conversationnelle qui reçoit la demande d’évaluation contenant la réponse réelle et la réponse de référence.
Le composant Modèle de prompt construit dynamiquement le prompt d’évaluation en :
{target_response}{actual_response}Le Générateur de sortie structurée traite le prompt via un LLM sélectionné et génère une sortie structurée contenant :
total_rating : note numérique de 1 à 4correctness : étiquette binaire correct/incorrectreasoning : explication détaillée de l’évaluationLe composant Parseur de données formate la sortie structurée, puis le composant Sortie conversationnelle présente les résultats finaux de l’évaluation.
Le système LLM comme juge offre plusieurs fonctionnalités avancées qui le rendent particulièrement efficace pour l’évaluation de flux IA :
Contrairement au simple appariement de chaînes, notre juge LLM comprend :
L’échelle de notation à 4 points permet une évaluation fine :
Chaque évaluation inclut un raisonnement détaillé, permettant de :
Recevez gratuitement les derniers conseils, tendances et offres.
Le toolkit CLI génère des rapports détaillés fournissant des informations exploitables sur la performance des flux :
Prêt à évaluer vos flux IA avec des outils professionnels ? Voici comment commencer :
Installation en une ligne (recommandée) pour macOS et Linux :
curl -sSL https://raw.githubusercontent.com/yasha-dev1/flowhunt-toolkit/main/install.sh | bash
Cela va automatiquement :
flowhunt à votre PATHInstallation manuelle :
# Cloner le dépôt
git clone https://github.com/yasha-dev1/flowhunt-toolkit.git
cd flowhunt-toolkit
# Installer avec pip
pip install -e .
Vérifier l’installation :
flowhunt --help
flowhunt --version
1. Authentification
Commencez par vous authentifier auprès de l’API FlowHunt :
flowhunt auth
2. Lister vos flux
flowhunt flows list
3. Évaluer un flux
Créez un fichier CSV avec vos données de test :
flow_input,expected_output
"What is 2+2?","4"
"What is the capital of France?","Paris"
Lancez l’évaluation avec LLM comme juge :
flowhunt evaluate your-flow-id path/to/test-data.csv --judge-flow-id your-judge-flow-id
4. Exécuter des flux en lot
flowhunt batch-run your-flow-id input.csv --output-dir results/
Le système d’évaluation fournit une analyse complète :
flowhunt evaluate FLOW_ID TEST_DATA.csv \
--judge-flow-id JUDGE_FLOW_ID \
--output-dir eval_results/ \
--batch-size 10 \
--verbose
Les fonctionnalités incluent :
Le toolkit CLI s’intègre parfaitement à la plateforme FlowHunt, vous permettant :
La sortie de notre toolkit CLI représente bien plus qu’un nouvel outil – c’est une vision pour l’avenir du développement IA où :
La qualité est mesurable : Les techniques avancées d’évaluation rendent la performance IA quantifiable et comparable.
Les tests sont automatisés : Des frameworks complets réduisent l’effort manuel et améliorent la fiabilité.
La transparence devient la norme : Un raisonnement détaillé et des rapports rendent le comportement de l’IA compréhensible et déboguable.
La communauté porte l’innovation : Les outils open source favorisent l’amélioration collaborative et le partage des connaissances.
En ouvrant le code du FlowHunt CLI Toolkit, nous affirmons notre engagement envers :
Le FlowHunt CLI Toolkit avec LLM comme juge marque une avancée significative dans les capacités d’évaluation des flux IA. En associant une logique d’évaluation sophistiquée à un reporting complet et à l’accessibilité open source, nous donnons aux développeurs les moyens de bâtir des systèmes IA plus fiables et performants.
L’approche méta consistant à utiliser FlowHunt pour évaluer des flux FlowHunt démontre la maturité et la flexibilité de notre plateforme, tout en offrant un outil puissant à la communauté IA dans son ensemble.
Que vous construisiez de simples chatbots ou des systèmes multi-agents complexes, le FlowHunt CLI Toolkit vous fournit l’infrastructure d’évaluation nécessaire pour garantir qualité, fiabilité et amélioration continue.
Prêt à faire passer l’évaluation de vos flux IA au niveau supérieur ? Rendez-vous sur notre dépôt GitHub pour démarrer avec le FlowHunt CLI Toolkit dès aujourd’hui et découvrez la puissance de LLM comme juge par vous-même.
L’avenir du développement IA commence ici – et il est open source.
Yasha est un développeur logiciel talentueux, spécialisé en Python, Java et en apprentissage automatique. Yasha écrit des articles techniques sur l'IA, l'ingénierie des prompts et le développement de chatbots.

Créez et évaluez des workflows IA sophistiqués avec la plateforme FlowHunt. Commencez dès aujourd’hui à élaborer des flux capables d’en juger d’autres.
Vérifiez tous les indicateurs de lisibilité reconnus. Essayez notre outil gratuit d'évaluation de lisibilité et apprenez à créer le vôtre !

Nous avons testé et classé les capacités rédactionnelles de 5 modèles populaires disponibles sur FlowHunt afin de trouver le meilleur LLM pour la rédaction de c...

L’année 2025 a été placée sous le signe de l’expansion chez FlowHunt. Nous avons créé des sous-produits entiers, ajouté des dizaines de nouveaux composants et d...
Consentement aux Cookies
Nous utilisons des cookies pour améliorer votre expérience de navigation et analyser notre trafic. See our privacy policy.