Cách Kiểm Thử Chatbot AI
Tìm hiểu chiến lược kiểm thử chatbot AI toàn diện bao gồm kiểm thử chức năng, hiệu suất, bảo mật và khả năng sử dụng. Khám phá các phương pháp hay nhất, công cụ...
17 phút đọc
Tìm hiểu các phương pháp toàn diện để đo lường độ chính xác của chatbot hỗ trợ khách hàng AI vào năm 2025. Khám phá các chỉ số precision, recall, điểm F1, mức độ hài lòng của người dùng và các kỹ thuật đánh giá nâng cao cùng FlowHunt.
Đo lường độ chính xác của chatbot hỗ trợ khách hàng AI bằng nhiều chỉ số như tính toán precision, recall, ma trận nhầm lẫn, điểm hài lòng của người dùng, tỷ lệ giải quyết vấn đề và các phương pháp đánh giá dựa trên LLM nâng cao. FlowHunt cung cấp công cụ toàn diện cho đánh giá độ chính xác tự động và giám sát hiệu suất.
Đo lường độ chính xác của chatbot hỗ trợ khách hàng AI là điều thiết yếu để đảm bảo chatbot cung cấp các phản hồi đáng tin cậy, hữu ích cho các câu hỏi của khách hàng. Khác với các bài toán phân loại đơn giản, độ chính xác của chatbot bao gồm nhiều khía cạnh cần được đánh giá đồng thời để có cái nhìn đầy đủ về hiệu suất. Quá trình này liên quan đến việc phân tích mức độ hiểu đúng truy vấn của người dùng, cung cấp thông tin chính xác, giải quyết vấn đề hiệu quả và duy trì sự hài lòng của người dùng trong suốt quá trình tương tác. Một chiến lược đo lường độ chính xác toàn diện sẽ kết hợp các chỉ số định lượng với phản hồi định tính để nhận diện điểm mạnh cũng như các lĩnh vực cần cải thiện.
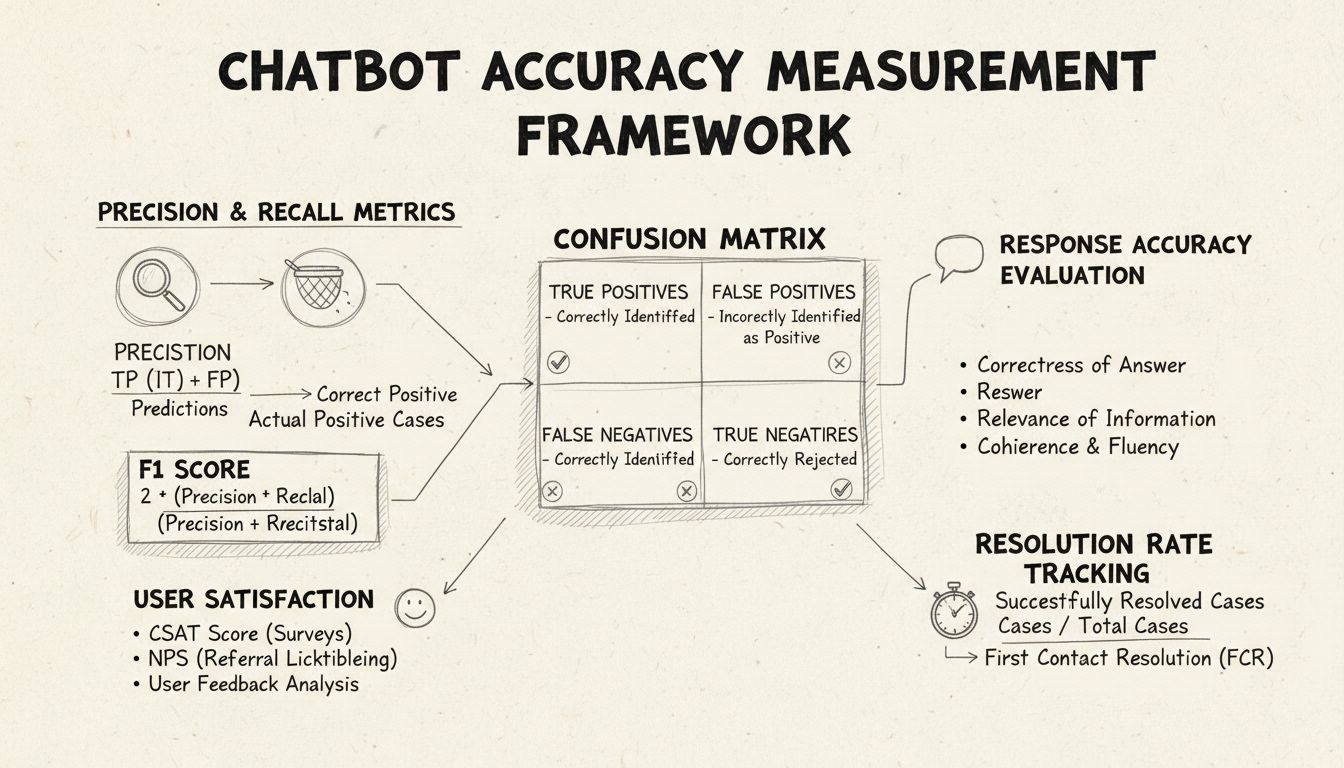
Precision và recall là hai chỉ số cơ bản được rút ra từ ma trận nhầm lẫn, đo lường các khía cạnh khác nhau về hiệu suất của chatbot. Precision thể hiện tỷ lệ phản hồi đúng trên tổng số phản hồi mà chatbot đã cung cấp, được tính theo công thức: Precision = Số Đúng Dương / (Số Đúng Dương + Số Dương Sai). Chỉ số này trả lời cho câu hỏi: “Khi chatbot đưa ra câu trả lời, nó đúng bao nhiêu phần trăm?” Điểm precision cao cho thấy chatbot hiếm khi cung cấp thông tin sai, yếu tố quan trọng để duy trì niềm tin của người dùng trong các tình huống hỗ trợ khách hàng.
Recall, còn gọi là độ nhạy, đo lường tỷ lệ phản hồi đúng trên tổng số câu trả lời đúng mà chatbot lẽ ra nên cung cấp, sử dụng công thức: Recall = Số Đúng Dương / (Số Đúng Dương + Số Âm Sai). Chỉ số này cho biết liệu chatbot có nhận diện và phản hồi đầy đủ các vấn đề của khách hàng hay không. Trong môi trường hỗ trợ khách hàng, recall cao đảm bảo khách hàng nhận được trợ giúp cho các vấn đề của họ thay vì bị báo là chatbot không thể hỗ trợ khi thực tế chatbot có khả năng. Mối quan hệ giữa precision và recall tạo ra một sự đánh đổi tự nhiên: tối ưu hóa cái này thường làm giảm cái kia, do đó cần cân nhắc kỹ dựa trên ưu tiên kinh doanh của bạn.
Điểm F1 cung cấp một chỉ số tổng hợp cân bằng cả precision và recall, được tính theo trung bình điều hòa: F1 = 2 × (Precision × Recall) / (Precision + Recall). Chỉ số này đặc biệt hữu ích khi cần một chỉ số tổng thể hoặc khi dữ liệu không cân bằng giữa các lớp. Ví dụ, nếu chatbot của bạn xử lý 1.000 truy vấn thường nhật nhưng chỉ có 50 trường hợp phức tạp, điểm F1 sẽ giúp tránh việc chỉ số bị lệch bởi lớp chiếm đa số. Điểm F1 dao động từ 0 đến 1, với 1 là hoàn hảo cả precision lẫn recall, giúp các bên liên quan dễ dàng hiểu được hiệu suất tổng thể của chatbot.
Ma trận nhầm lẫn là công cụ nền tảng giúp phân tích hiệu suất chatbot thành bốn loại: Đúng Dương (trả lời đúng truy vấn hợp lệ), Đúng Âm (từ chối hợp lý các câu hỏi ngoài phạm vi), Dương Sai (trả lời sai), và Âm Sai (bỏ lỡ cơ hội hỗ trợ). Ma trận này cho thấy các mô hình thất bại đặc thù của chatbot, giúp cải thiện mục tiêu. Ví dụ, nếu ma trận cho thấy tỷ lệ Âm Sai cao với các truy vấn về thanh toán, bạn có thể xác định rằng bộ dữ liệu huấn luyện của chatbot thiếu ví dụ liên quan đến thanh toán và cần bổ sung ở lĩnh vực đó.
| Chỉ số | Định nghĩa | Cách tính | Ảnh hưởng kinh doanh |
|---|---|---|---|
| Đúng Dương (TP) | Phản hồi đúng cho truy vấn hợp lệ | Đếm trực tiếp | Xây dựng niềm tin khách hàng |
| Đúng Âm (TN) | Từ chối hợp lý câu hỏi ngoài phạm vi | Đếm trực tiếp | Ngăn ngừa thông tin sai lệch |
| Dương Sai (FP) | Trả lời sai | Đếm trực tiếp | Làm giảm uy tín |
| Âm Sai (FN) | Bỏ lỡ cơ hội hỗ trợ | Đếm trực tiếp | Giảm sự hài lòng |
| Precision | Chất lượng dự đoán dương | TP / (TP + FP) | Chỉ số độ tin cậy |
| Recall | Bao phủ các trường hợp dương | TP / (TP + FN) | Chỉ số mức độ đầy đủ |
| Accuracy | Độ đúng tổng thể | (TP + TN) / Tổng | Hiệu suất chung |
Độ chính xác phản hồi đo lường tần suất chatbot cung cấp thông tin đúng sự thật, giải quyết trực tiếp truy vấn của người dùng. Điều này vượt lên trên việc khớp mẫu đơn giản, đánh giá liệu nội dung có chính xác, cập nhật và phù hợp với ngữ cảnh hay không. Quy trình đánh giá thủ công thường yêu cầu người đánh giá kiểm tra ngẫu nhiên một số cuộc trò chuyện, so sánh phản hồi của chatbot với bộ kiến thức đúng chuẩn. Các phương pháp so khớp tự động có thể triển khai bằng kỹ thuật NLP để đối chiếu với câu trả lời mong đợi lưu trong hệ thống, tuy nhiên cần hiệu chỉnh cẩn thận để tránh âm sai nếu chatbot trả lời đúng nhưng dùng từ khác với đáp án mẫu.
Độ phù hợp phản hồi đánh giá liệu câu trả lời của chatbot có thực sự giải quyết điều người dùng hỏi không, dù nội dung chưa hoàn toàn chính xác. Khía cạnh này ghi nhận khi chatbot cung cấp thông tin hữu ích, dù chưa đúng hoàn toàn nhưng giúp hướng cuộc trò chuyện đến giải pháp. Các phương pháp NLP như cosine similarity có thể đo mức độ tương đồng ngữ nghĩa giữa câu hỏi và phản hồi, tạo ra điểm số mức độ phù hợp tự động. Cơ chế phản hồi của người dùng, ví dụ như nút thích/không thích sau mỗi tương tác, cung cấp đánh giá trực tiếp từ chính khách hàng. Những tín hiệu này cần được thu thập và phân tích thường xuyên để nhận diện các loại truy vấn chatbot xử lý tốt hoặc chưa tốt.
Điểm Hài Lòng Khách Hàng (CSAT) đo mức độ hài lòng của người dùng với trải nghiệm chatbot thông qua khảo sát trực tiếp, thường theo thang điểm 1-5 hoặc đơn giản là hài lòng/không hài lòng. Sau mỗi tương tác, người dùng sẽ được hỏi đánh giá mức độ hài lòng, qua đó thu nhận phản hồi ngay về việc chatbot có đáp ứng nhu cầu hay không. CSAT trên 80% thường cho thấy hiệu suất tốt, dưới 60% cảnh báo có vấn đề nghiêm trọng cần xem xét. Ưu điểm của CSAT là đơn giản và trực tiếp, tuy nhiên có thể bị ảnh hưởng bởi các yếu tố ngoài độ chính xác như mức độ phức tạp của vấn đề hoặc kỳ vọng của người dùng.
Net Promoter Score đo khả năng người dùng giới thiệu chatbot cho người khác, được tính qua câu hỏi “Bạn có sẵn sàng giới thiệu chatbot này cho đồng nghiệp không?” trên thang 0-10. Người trả lời 9-10 là nhóm khuyến nghị, 7-8 là trung lập, 0-6 là nhóm phản đối. NPS = (Khuyến nghị - Phản đối) / Tổng số người trả lời × 100. Chỉ số này thường liên quan chặt đến sự trung thành lâu dài của khách hàng và cho biết chatbot có tạo ra trải nghiệm tích cực hay không. NPS trên 50 là xuất sắc, NPS âm cho thấy có vấn đề nghiêm trọng về hiệu suất.
Phân tích cảm xúc xem xét sắc thái cảm xúc của tin nhắn người dùng trước và sau khi tương tác với chatbot để đánh giá sự hài lòng. Các kỹ thuật NLP nâng cao phân loại tin nhắn thành tích cực, trung tính hoặc tiêu cực, nhận biết người dùng có trở nên hài lòng hơn hay bực bội hơn. Sự thay đổi cảm xúc tích cực cho thấy chatbot đã giải quyết được mối quan tâm, còn thay đổi tiêu cực cho thấy chatbot có thể đã làm người dùng thất vọng hoặc chưa đáp ứng nhu cầu. Chỉ số này bổ sung góc nhìn cảm xúc mà các chỉ số truyền thống bỏ lỡ, giúp hiểu rõ hơn chất lượng trải nghiệm người dùng.
Tỷ lệ Giải quyết ngay lần đầu đo phần trăm vấn đề được chatbot giải quyết mà không cần chuyển cho nhân viên hỗ trợ. Chỉ số này ảnh hưởng trực tiếp đến hiệu quả vận hành và sự hài lòng của khách hàng, vì khách hàng luôn mong muốn vấn đề được xử lý ngay thay vì bị chuyển tiếp. FCR trên 70% cho thấy hiệu quả tốt, dưới 50% cho thấy chatbot chưa đủ kiến thức hoặc khả năng xử lý các truy vấn phổ biến. Theo dõi FCR theo từng loại vấn đề sẽ xác định lĩnh vực chatbot xử lý tốt và lĩnh vực cần sự can thiệp của con người, từ đó cải thiện đào tạo và mở rộng kho kiến thức.
Tỷ lệ chuyển tiếp đo lường tần suất chatbot chuyển cuộc trò chuyện cho nhân viên, còn tần suất phản hồi chung chung đo lường số lần chatbot trả lời kiểu “Tôi không hiểu” hoặc “Vui lòng diễn đạt lại”. Tỷ lệ chuyển tiếp cao (trên 30%) cho thấy chatbot thiếu kiến thức hoặc tự tin ở nhiều tình huống, còn tần suất phản hồi chung chung cao cho thấy khả năng nhận diện ý định kém hoặc thiếu dữ liệu huấn luyện. Các chỉ số này giúp xác định lỗ hổng cụ thể về năng lực, có thể cải thiện bằng mở rộng kho kiến thức, huấn luyện lại hoặc tăng cường khả năng hiểu ngôn ngữ tự nhiên.
Thời gian phản hồi đo lường tốc độ chatbot trả lời tin nhắn người dùng, thường tính bằng mili giây đến giây. Người dùng kỳ vọng phản hồi gần như tức thì; chậm quá 3-5 giây sẽ làm giảm sự hài lòng. Thời gian xử lý đo tổng thời gian từ khi người dùng bắt đầu đến khi vấn đề được giải quyết hoặc chuyển tiếp, cho biết mức độ hiệu quả của chatbot. Thời gian xử lý ngắn cho thấy chatbot hiểu và giải quyết vấn đề nhanh, thời gian dài thường do phải làm rõ nhiều lần hoặc gặp truy vấn phức tạp. Nên theo dõi các chỉ số này riêng cho từng loại vấn đề, vì các vấn đề kỹ thuật phức tạp sẽ mất thời gian xử lý lâu hơn các câu hỏi FAQ đơn giản.
“LLM Làm Giám Khảo” là phương pháp đánh giá tiên tiến, trong đó một mô hình ngôn ngữ lớn đánh giá chất lượng đầu ra của hệ thống AI khác. Phương pháp này đặc biệt hiệu quả khi cần đánh giá phản hồi chatbot trên nhiều khía cạnh cùng lúc như chính xác, phù hợp, mạch lạc, trôi chảy, an toàn, đầy đủ và thái độ. Nghiên cứu cho thấy LLM làm giám khảo có thể đạt tới 85% sự đồng thuận với đánh giá của con người, giúp mở rộng quy mô đánh giá mà không cần kiểm tra thủ công. Quy trình gồm xác định tiêu chí đánh giá, xây dựng prompt chi tiết kèm ví dụ, cung cấp truy vấn gốc và phản hồi chatbot cho giám khảo, sau đó nhận điểm số hoặc nhận xét chi tiết.
Quy trình này thường áp dụng hai cách: đánh giá đơn lẻ (cho điểm từng phản hồi, có thể không cần đáp án chuẩn hoặc so với đáp án mẫu) và so sánh cặp đôi (so sánh hai phản hồi để chọn cái tốt hơn). Tùy chọn này giúp đánh giá cả hiệu suất tuyệt đối lẫn cải tiến tương đối khi thử nghiệm các phiên bản chatbot khác nhau. Nền tảng FlowHunt hỗ trợ triển khai phương pháp này với giao diện kéo-thả, tích hợp LLM hàng đầu như ChatGPT, Claude và bộ công cụ CLI cho báo cáo nâng cao cũng như đánh giá tự động.
Ngoài các phép tính cơ bản, phân tích chi tiết ma trận nhầm lẫn giúp phát hiện các kiểu lỗi cụ thể của chatbot. Bằng cách xem xét loại truy vấn nào hay sinh ra Dương Sai hoặc Âm Sai, bạn có thể phát hiện điểm yếu có hệ thống. Ví dụ, nếu ma trận cho thấy chatbot thường phân loại nhầm câu hỏi thanh toán thành hỗ trợ kỹ thuật, đây là dấu hiệu mất cân bằng dữ liệu huấn luyện hoặc vấn đề nhận diện ý định ở lĩnh vực thanh toán. Tạo các ma trận nhầm lẫn riêng theo từng loại vấn đề sẽ giúp cải thiện chính xác hơn thay vì chỉ huấn luyện lại chung chung.
Thử nghiệm A/B so sánh các phiên bản khác nhau của chatbot để xác định phiên bản nào hoạt động tốt hơn trên các chỉ số chính. Điều này có thể bao gồm thử nghiệm mẫu phản hồi, cấu hình kho kiến thức hoặc mô hình ngôn ngữ nền tảng khác nhau. Bằng cách chuyển ngẫu nhiên một phần lưu lượng sang mỗi phiên bản và so sánh các chỉ số như FCR, CSAT, độ chính xác phản hồi, bạn sẽ đưa ra các quyết định cải tiến dựa trên dữ liệu. Thử nghiệm A/B nên kéo dài đủ lâu để bao quát sự đa dạng tự nhiên của truy vấn và đảm bảo kết quả có ý nghĩa thống kê.
FlowHunt cung cấp nền tảng tích hợp để xây dựng, triển khai và đánh giá chatbot hỗ trợ khách hàng AI với các khả năng đo lường độ chính xác nâng cao. Trình dựng trực quan của nền tảng cho phép người không chuyên tạo flow chatbot phức tạp, các thành phần AI tích hợp với các mô hình hàng đầu như ChatGPT, Claude. Bộ công cụ đánh giá của FlowHunt hỗ trợ triển khai phương pháp LLM làm giám khảo, cho phép bạn định nghĩa tiêu chí riêng và tự động đánh giá hiệu suất chatbot trên toàn bộ tập dữ liệu hội thoại.
Để triển khai đo lường toàn diện với FlowHunt, hãy bắt đầu bằng cách xác định các tiêu chí đánh giá phù hợp với mục tiêu kinh doanh – ưu tiên độ chính xác, tốc độ, sự hài lòng hay tỷ lệ giải quyết vấn đề. Cấu hình LLM giám khảo với prompt chi tiết, chỉ rõ cách đánh giá phản hồi kèm ví dụ cụ thể về đáp án tốt và chưa tốt. Tải lên tập dữ liệu hội thoại hoặc kết nối với lưu lượng trực tiếp, sau đó chạy đánh giá để tạo báo cáo chi tiết cho mọi chỉ số. Bảng điều khiển của FlowHunt cung cấp cái nhìn thời gian thực về hiệu suất, giúp nhanh chóng phát hiện vấn đề và xác thực các cải tiến.
Thiết lập chỉ số cơ sở trước khi thực hiện cải tiến, tạo điểm tham chiếu để đánh giá tác động của thay đổi. Thu thập đo lường liên tục thay vì định kỳ để phát hiện sớm suy giảm hiệu suất do trôi dữ liệu hoặc thoái hóa mô hình. Xây dựng vòng phản hồi, nơi đánh giá và chỉnh sửa của người dùng tự động bổ sung vào quá trình huấn luyện, liên tục cải thiện độ chính xác. Phân loại chỉ số theo loại vấn đề, loại người dùng và từng thời kỳ để xác định khu vực cần chú ý thay vì chỉ dựa vào số liệu tổng hợp.
Đảm bảo tập dữ liệu đánh giá phản ánh đúng truy vấn thực tế và câu trả lời mong đợi, tránh trường hợp kiểm thử không sát thực tế. Thường xuyên xác thực các chỉ số tự động bằng đánh giá thủ công một mẫu hội thoại, đảm bảo hệ thống đo lường vẫn bám sát chất lượng thực tế. Ghi chép rõ ràng phương pháp đo lường và định nghĩa chỉ số để đảm bảo đánh giá nhất quán theo thời gian và truyền đạt minh bạch kết quả đến các bên liên quan. Cuối cùng, đặt mục tiêu hiệu suất cho từng chỉ số phù hợp với mục tiêu kinh doanh, tạo trách nhiệm cho việc cải tiến liên tục và cung cấp mục tiêu rõ ràng cho các nỗ lực tối ưu hóa.
Nền tảng tự động hóa AI tiên tiến của FlowHunt giúp bạn tạo, triển khai và đánh giá chatbot hỗ trợ khách hàng hiệu suất cao với các công cụ đo lường độ chính xác tích hợp và khả năng đánh giá bằng LLM.
Tìm hiểu chiến lược kiểm thử chatbot AI toàn diện bao gồm kiểm thử chức năng, hiệu suất, bảo mật và khả năng sử dụng. Khám phá các phương pháp hay nhất, công cụ...
Tìm hiểu các phương pháp đã được kiểm chứng để xác thực độ tin cậy của chatbot AI năm 2025. Khám phá kỹ thuật xác minh kỹ thuật, kiểm tra bảo mật và các thực ti...
Khám phá tầm quan trọng của độ chính xác và độ ổn định của mô hình AI trong học máy. Tìm hiểu cách các chỉ số này ảnh hưởng đến các ứng dụng như phát hiện gian ...
Đồng Ý Cookie
Chúng tôi sử dụng cookie để cải thiện trải nghiệm duyệt web của bạn và phân tích lưu lượng truy cập của mình. See our privacy policy.