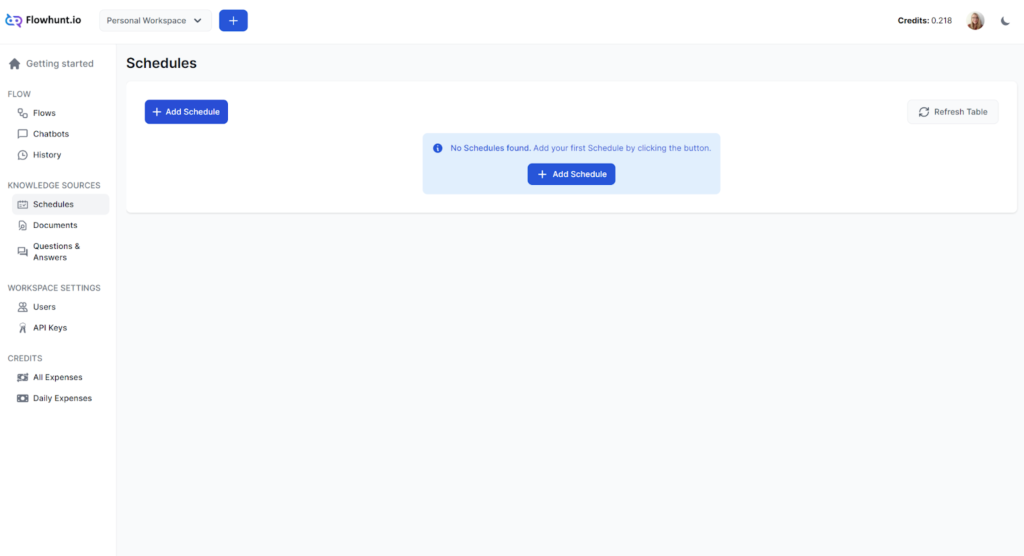
Lịch trình
Tính năng Lịch trình trong FlowHunt cho phép bạn thu thập dữ liệu định kỳ từ các tên miền và kênh YouTube, giúp chatbot và luồng của bạn luôn được cập nhật với ...
3 phút đọc
AI
Schedules
+4
Tìm hiểu cách thiết lập lịch tự động để thu thập dữ liệu website, sitemap, domain và kênh YouTube nhằm giữ cho cơ sở tri thức của AI Agent luôn được cập nhật mới nhất.
Tính năng Lên Lịch của FlowHunt cho phép bạn tự động hóa việc thu thập và lập chỉ mục website, sitemap, domain và kênh YouTube. Điều này đảm bảo cơ sở tri thức của AI Agent luôn được cập nhật với nội dung mới mà không cần can thiệp thủ công.
Thu thập dữ liệu tự động:
Thiết lập lịch thu thập định kỳ hàng ngày, hàng tuần, hàng tháng hoặc hàng năm để cơ sở tri thức luôn được cập nhật.
Nhiều loại thu thập khác nhau:
Chọn giữa thu thập toàn bộ Domain, thu thập theo Sitemap, thu thập URL cụ thể hoặc thu thập kênh YouTube tùy theo nguồn nội dung của bạn.
Tùy chọn nâng cao:
Cấu hình hiển thị trình duyệt, theo dõi liên kết, chụp ảnh màn hình, xoay proxy và lọc URL để đạt hiệu quả tối ưu.
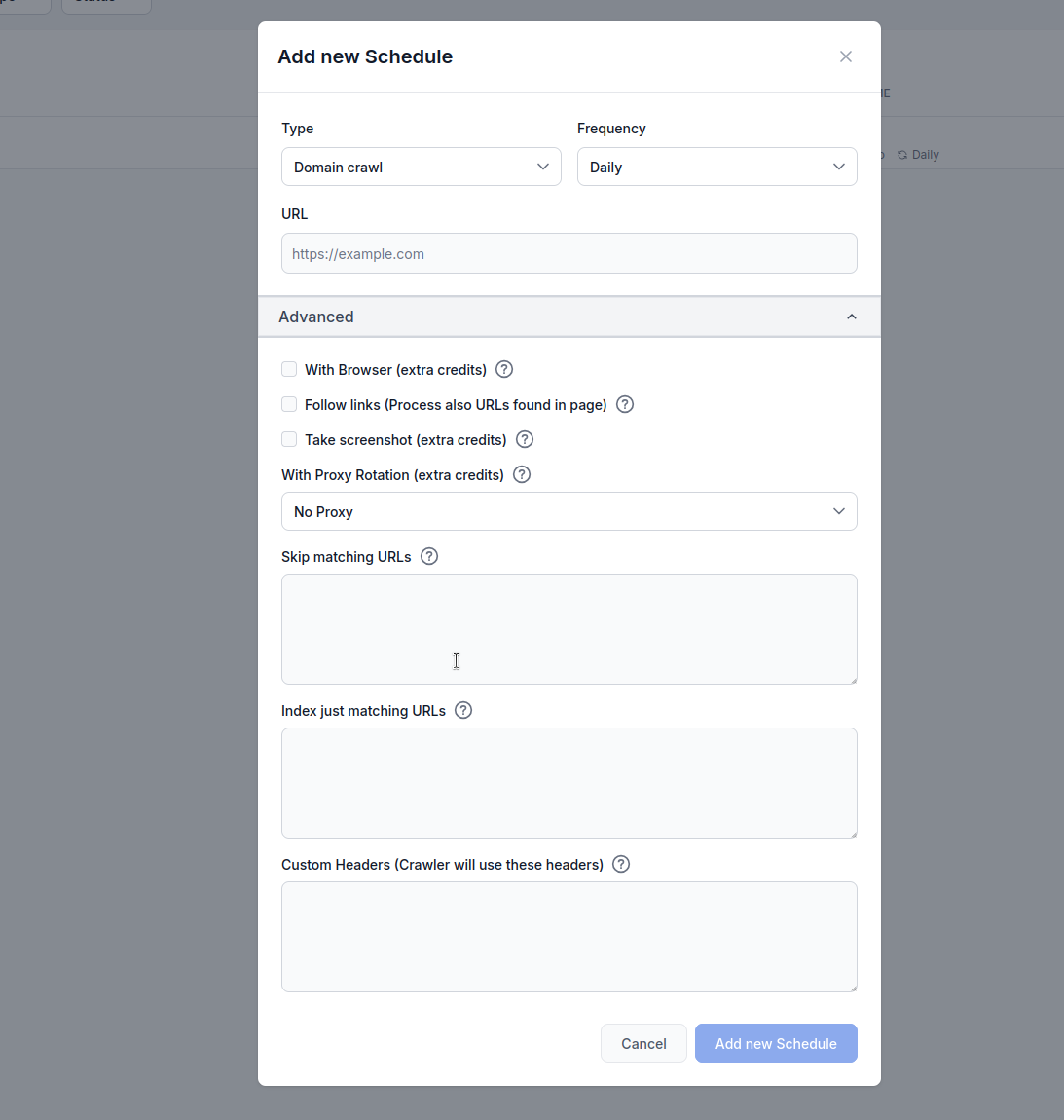
Loại: Chọn phương thức thu thập:
Tần suất: Đặt tần suất chạy thu thập:
URL: Nhập URL, domain hoặc kênh YouTube mục tiêu cần thu thập
Sử dụng Trình Duyệt (tốn thêm credit): Kích hoạt khi thu thập các website sử dụng nhiều JavaScript cần hiển thị trình duyệt đầy đủ. Tùy chọn này chậm hơn và tốn nhiều chi phí hơn nhưng cần thiết cho các trang tải nội dung động.
Theo dõi liên kết (tốn thêm credit): Xử lý thêm các URL được tìm thấy trong trang. Hữu ích khi sitemap không chứa đủ các URL, nhưng có thể tốn nhiều credit do thu thập thêm các liên kết được phát hiện.
Chụp ảnh màn hình (tốn thêm credit): Chụp lại màn hình trong quá trình thu thập. Hữu ích cho các website không có og:image hoặc cần ngữ cảnh hình ảnh cho AI xử lý.
Xoay Proxy (tốn thêm credit): Xoay IP cho mỗi lần gửi yêu cầu để tránh bị hệ thống tường lửa (WAF) hoặc chống bot phát hiện.
Bỏ qua URL khớp mẫu: Nhập chuỗi (mỗi dòng một chuỗi) để loại trừ các URL chứa mẫu này khỏi quá trình thu thập. Ví dụ:
/admin/
/login
.pdf
/blogVí dụ này minh họa điều gì sẽ xảy ra khi bạn sử dụng tính năng Lên Lịch của FlowHunt để thu thập domain flowhunt.io nhưng thiết lập /blog là mẫu URL để bỏ qua trong phần lọc URL.
Cài Đặt Cấu Hình
flowhunt.io/blogQuy Trình
Khởi động thu thập:
flowhunt.io, hướng đến tất cả các trang có thể truy cập trên domain (ví dụ: flowhunt.io, flowhunt.io/features, flowhunt.io/pricing, v.v.).Áp dụng lọc URL:
/blog./blog (ví dụ: flowhunt.io/blog, flowhunt.io/blog/post1, flowhunt.io/blog/category) sẽ bị loại trừ khỏi quá trình thu thập.flowhunt.io/about, flowhunt.io/contact hoặc flowhunt.io/docs vẫn được thu thập vì không khớp với mẫu /blog.Thực thi thu thập:
flowhunt.io, lập chỉ mục nội dung cho cơ sở tri thức của AI Agent.Kết quả:
flowhunt.io, loại trừ mọi thứ dưới đường dẫn /blog./blog) mà không cần thao tác thủ công.Chỉ lập chỉ mục URL khớp mẫu: Nhập chuỗi (mỗi dòng một chuỗi) để chỉ thu thập các URL chứa mẫu này. Ví dụ:
/blog/
/articles/
/knowledge/
Cài Đặt Cấu Hình
flowhunt.io/blog/
/articles/
/knowledge/
Khởi động thu thập:
flowhunt.io, hướng đến tất cả các trang có thể truy cập trên domain (ví dụ: flowhunt.io, flowhunt.io/blog, flowhunt.io/articles, v.v.).Áp dụng lọc URL:
/blog/, /articles/, và /knowledge/.flowhunt.io/blog/post1, flowhunt.io/articles/news, flowhunt.io/knowledge/guide) mới được đưa vào quá trình thu thập.flowhunt.io/about, flowhunt.io/pricing hoặc flowhunt.io/contact sẽ bị loại trừ vì không khớp các mẫu chỉ định.Thực thi thu thập:
/blog/, /articles/ hoặc /knowledge/, lập chỉ mục nội dung cho cơ sở tri thức của AI Agent.Kết quả:
flowhunt.io dưới đường dẫn /blog/, /articles/ và /knowledge/.Headers Tùy Chỉnh:
Thêm header HTTP tùy chỉnh cho các yêu cầu thu thập. Định dạng HEADER=Giá trị (mỗi dòng một header):
Tính năng này rất hữu ích để tùy biến quá trình thu thập cho từng website. Nhờ headers tùy chỉnh, người dùng có thể xác thực truy cập nội dung hạn chế, giả lập hành vi trình duyệt hoặc tuân thủ yêu cầu API/chính sách truy cập. Ví dụ, thiết lập header Authorization giúp truy cập trang được bảo vệ, còn User-Agent tùy chỉnh giúp tránh bị phát hiện bot hoặc đảm bảo tương thích với các site giới hạn crawler. Sự linh hoạt này giúp thu thập dữ liệu chính xác và đầy đủ hơn, thuận tiện cho việc lập chỉ mục nội dung liên quan cho AI Agent trong khi vẫn tuân thủ các quy tắc bảo mật/truy cập của website.
MYHEADER=Any value
Authorization=Bearer token123
User-Agent=Custom crawler
Truy cập mục Lịch trong bảng điều khiển FlowHunt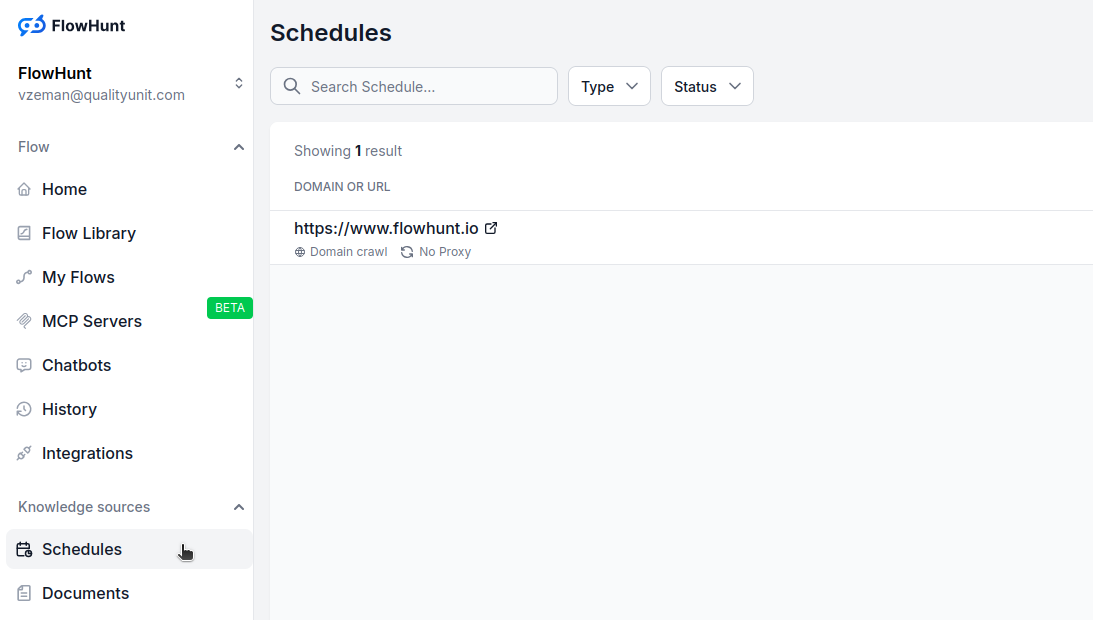
Nhấn “Thêm Lịch Mới”
Cấu hình cài đặt cơ bản:
Mở rộng tùy chọn nâng cao nếu cần:
Nhấn “Thêm Lịch Mới” để kích hoạt
Đối với Hầu Hết Các Website:
Đối với Website Nặng JavaScript:
Đối với Website Lớn:
Đối với Thương Mại Điện Tử hoặc Nội Dung Động:
Các tính năng nâng cao sẽ tiêu tốn thêm credit:
Theo dõi việc sử dụng credit và điều chỉnh lịch phù hợp với nhu cầu và ngân sách của bạn.
Lỗi khi thu thập:
Quá nhiều/ít trang được thu thập:
Thiếu nội dung:
Tính năng Lịch trình trong FlowHunt cho phép bạn thu thập dữ liệu định kỳ từ các tên miền và kênh YouTube, giúp chatbot và luồng của bạn luôn được cập nhật với ...

Tích hợp FlowHunt với Google Lịch để tự động hóa lập lịch, quản lý sự kiện và thúc đẩy quy trình làm việc trên lịch dựa trên AI....

Giảm ảo giác AI và đảm bảo câu trả lời chính xác cho chatbot bằng cách sử dụng tính năng Lập lịch của FlowHunt. Khám phá các lợi ích, tình huống sử dụng thực tế...
Đồng Ý Cookie
Chúng tôi sử dụng cookie để cải thiện trải nghiệm duyệt web của bạn và phân tích lưu lượng truy cập của mình. See our privacy policy.