
通过添加自定义知识库减少AI幻觉
通过使用FlowHunt的计划功能,减少AI幻觉并确保聊天机器人响应的准确性。了解其优势、实际应用场景,以及逐步设置此强大工具的指南。...
1 分钟阅读
AI
Chatbot
+4
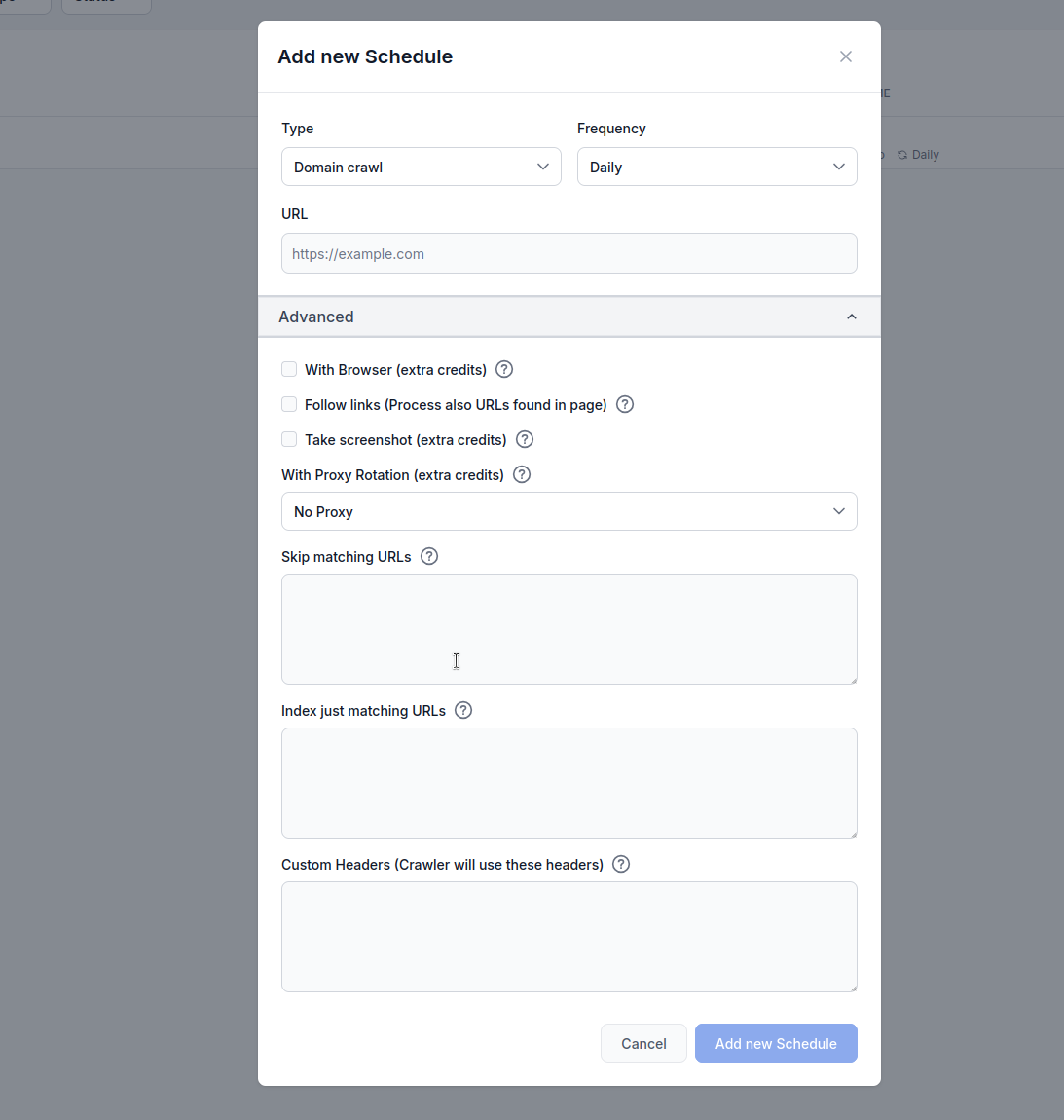
了解如何为网站、站点地图、域名及 YouTube 频道设置自动定时爬取计划,确保 AI Agent 知识库内容始终保持最新。
FlowHunt 的定时调度功能可让你自动化网站、站点地图、域名及 YouTube 频道的爬取与索引,无需人工干预,即可确保 AI Agent 的知识库始终获取最新内容。
自动爬取:
设置每日、每周、每月或每年定时爬取任务,持续为知识库更新内容。
多种爬取类型:
可根据内容源选择域名爬取、站点地图爬取、URL 爬取或 YouTube 频道爬取。
高级选项:
可配置浏览器渲染、链接跟踪、截图、代理轮换以及 URL 过滤,以实现最佳爬取效果。
类型: 选择你的爬取方式:
频率: 设定爬取的周期:
URL: 输入目标 URL、域名或 YouTube 频道
使用浏览器(消耗额外积分):
适用于需要完整浏览器渲染的 JavaScript 密集型网站。此选项速度较慢且成本更高,但对于动态加载内容的网站来说是必需的。
跟踪链接(消耗额外积分):
处理页面中发现的额外 URL。适用于站点地图未包含所有 URL 的情况,但会因爬取新增链接而消耗大量积分。
截图(消耗额外积分):
爬取过程中截取页面截图。对于没有 og:images 或 AI 需要视觉上下文的网站尤为有用。
代理轮换(消耗额外积分):
每次请求自动更换 IP,避免被网站防火墙(WAF)或反爬虫系统检测。
跳过匹配的 URL:
输入字符串(每行一条),排除含有这些模式的 URL。例如:
/admin/
/login
.pdf
本示例说明,若你在使用 FlowHunt 定时调度功能爬取 flowhunt.io 域名时,在 URL 过滤中设置 /blog 为需跳过的模式,将发生如下过程:
配置设置
flowhunt.io/blog执行流程
任务启动:
flowhunt.io 进行域名级别爬取,目标包括该域名下所有可访问页面(如 flowhunt.io、flowhunt.io/features、flowhunt.io/pricing 等)。应用 URL 过滤:
/blog 模式进行比对。/blog 的 URL(如 flowhunt.io/blog、flowhunt.io/blog/post1、flowhunt.io/blog/category)均排除在爬取之外。flowhunt.io/about、flowhunt.io/contact 或 flowhunt.io/docs 等未包含 /blog 的 URL 会被正常爬取。执行爬取:
结果:
flowhunt.io 上除 /blog 路径外的所有新内容。/blog 部分)。仅索引匹配的 URL:
输入字符串(每行一条),只爬取包含这些模式的 URL。例如:
/blog/
/articles/
/knowledge/
配置设置
flowhunt.io/blog/
/articles/
/knowledge/
任务启动:
flowhunt.io 的域名级爬取,目标为所有可访问页面(如 flowhunt.io、flowhunt.io/blog、flowhunt.io/articles 等)。应用 URL 过滤:
/blog/、/articles/、/knowledge/ 模式比对。flowhunt.io/blog/post1、flowhunt.io/articles/news、flowhunt.io/knowledge/guide)会被索引。flowhunt.io/about、flowhunt.io/pricing、flowhunt.io/contact 等未匹配模式的 URL 将被排除。执行爬取:
/blog/、/articles/ 或 /knowledge/ 的 URL,为 AI Agent 知识库建立索引。结果:
flowhunt.io 域名下 /blog/、/articles/、/knowledge/ 路径下的最新内容。自定义请求头:
为爬取请求添加自定义 HTTP 请求头。格式为 HEADER=值(每行一条):
此功能非常适用于根据特定网站需求定制爬取行为。通过设置自定义请求头,用户可以为爬虫请求添加认证信息以访问受限内容,模拟特定浏览器访问,或遵循网站 API 或访问策略。例如,设置 Authorization 请求头可授权访问受保护页面,自定义 User-Agent 有助于规避反爬虫检测或提升特定网站兼容性。此灵活性可确保数据采集更准确、更全面,便于 AI Agent 索引相关内容,同时遵循网站安全和访问规范。
MYHEADER=Any value
Authorization=Bearer token123
User-Agent=Custom crawler
进入 FlowHunt 控制台的 Schedules 页面
点击“Add new Schedule”
配置基础设置:
如需,展开高级选项:
点击“Add new Schedule” 激活定时任务
大多数网站建议:
JavaScript 密集型网站:
大型网站:
电商或动态内容网站:
免费获取最新提示、趋势和优惠。
高级功能会消耗额外积分:
请根据需求与预算,监控积分用量并适时调整定时任务。
爬取失败:
爬取页面过多/过少:
内容缺失:
通过使用FlowHunt的计划功能,减少AI幻觉并确保聊天机器人响应的准确性。了解其优势、实际应用场景,以及逐步设置此强大工具的指南。...
FlowHunt 的计划任务功能可以让您定期爬取域名和 YouTube 频道,确保您的聊天机器人和流程始终获得最新信息。通过可自定义的爬取类型和频率自动获取数据,确保您的 AI 交互始终相关且准确。...

详细指南,教你如何仅将 docs.cpanel.net 的指定部分导入 FlowHunt 聊天机器人,让其专注于特定 cPanel 主题,而无需导入整个文档门户。...
Cookie 同意
我们使用 cookie 来增强您的浏览体验并分析我们的流量。 See our privacy policy.