Context Engineering: Definitivní průvodce 2025 pro zvládnutí návrhu AI systémů
Ponořte se do hloubky kontextového inženýrství pro AI. Tento průvodce pokrývá základní principy od promptu vs. kontext až po pokročilé strategie jako správa paměti, rozklad kontextu a multiagentní návrh.
AI
LLM
System Design
Agents
Context Engineering
Prompt Engineering
RAG
Vývoj AI prošel zásadní proměnou. Zatímco dříve jsme se soustředili na tvorbu dokonalého promptu, nyní čelíme mnohem složitějšímu úkolu: budovat celé informační architektury, které obklopují a posilují naše jazykové modely.
Tento posun znamená evoluci od prompt engineeringu ke kontextovému inženýrství—a představuje budoucnost praktického vývoje AI. Systémy, které dnes přinášejí skutečnou hodnotu, nestojí na kouzelných proměnných. Uspívají díky tomu, že jejich architekti se naučili řídit komplexní informační ekosystémy.
Andrej Karpathy tuto evoluci vystihl dokonale, když kontextové inženýrství popsal jako pečlivou praxi zaplňování kontextového okna přesně správnými informacemi ve správný čas. Tento zdánlivě jednoduchý výrok odhaluje zásadní pravdu: LLM již není hlavní hvězdou. Je to klíčová součást pečlivě navrženého systému, kde každý informační fragment, popis nástroje i načtený dokument má své místo pro maximalizaci výsledků.
Co je kontextové inženýrství?
Historická perspektiva
Kořeny kontextového inženýrství sahají hlouběji, než si většina lidí uvědomuje. Zatímco hlavní diskuse o prompt engineeringu explodovaly kolem let 2022–2023, základní koncepty kontextového inženýrství se objevily už před více než dvaceti lety v oblasti výzkumu všudypřítomného počítání a interakce člověk–počítač.
Již v roce 2001 Anind K. Dey definoval kontext jako jakoukoli informaci, která pomáhá charakterizovat situaci entity. Tento raný rámec položil základy pro naše současné uvažování o strojovém chápání prostředí.
Vývoj kontextového inženýrství prošel několika fázemi, z nichž každou ovlivnily pokroky v oblasti strojové inteligence:
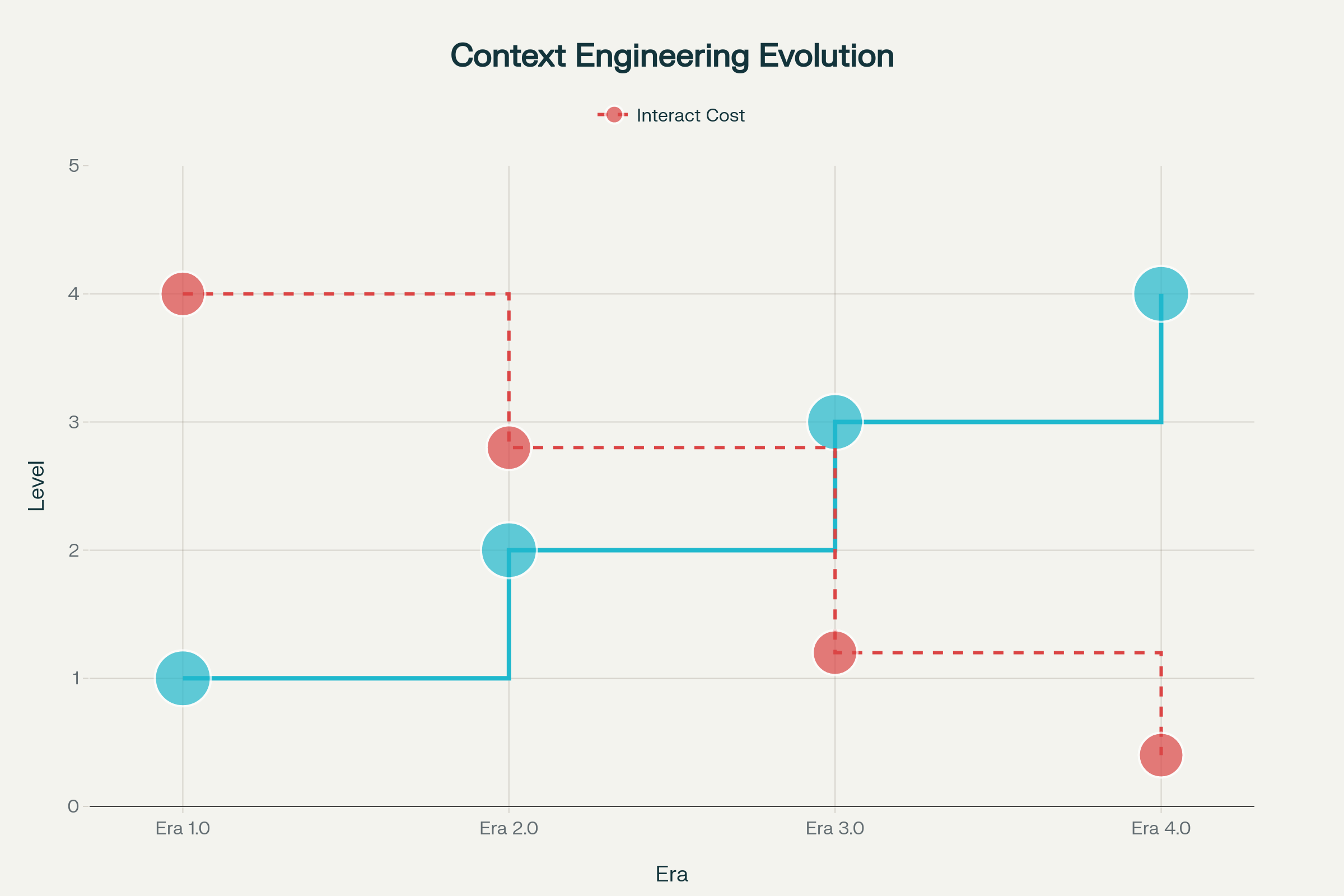
Éra 1.0: Primitivní výpočty (1990s–2020) — V tomto období stroje zvládaly pouze strukturované vstupy a základní signály z okolí. Veškeré převádění kontextu do strojově zpracovatelné podoby zajišťovali lidé. Typické příklady: desktopové aplikace, mobilní aplikace se senzory, rané chatboty s pevnými rozhodovacími stromy.
Éra 2.0: Agentně orientovaná inteligence (2020–současnost) — Vydání GPT-3 v roce 2020 znamenalo zásadní zlom. Velké jazykové modely přinesly skutečné porozumění přirozenému jazyku a schopnost pracovat s implicitními úmysly. Tato éra umožnila skutečnou spolupráci člověka a agenta, kdy se nejasnosti a neúplné informace staly zvládnutelnými díky pokročilému porozumění jazyku a učení v kontextu.
Éry 3.0 & 4.0: Lidská a nadlidská inteligence (budoucnost) — Příští vlny slibují systémy, které budou vnímat a zpracovávat komplexní informace s lidskou plynulostí a nakonec půjdou za hranice reaktivních odpovědí ke schopnosti proaktivně vytvářet kontext a vyhodnocovat potřeby, které uživatel ještě ani nevyslovil.
Vývoj kontextového inženýrství napříč čtyřmi érami: Od primitivního počítání k nadlidské inteligenci
Formální definice
V jádru je kontextové inženýrství systematická disciplína navrhování a optimalizace toku kontextových informací v AI systémech—od počátečního sběru přes ukládání, správu až po konečné využití ke zlepšení porozumění stroje a vykonávání úloh.
Matematicky to lze vyjádřit jako transformační funkci:
$CE: (C, T) \rightarrow f_{context}$
Kde:
C představuje surové kontextové informace (entity a jejich charakteristiky)
T označuje cílový úkol nebo aplikační doménu
f_{context} je výsledná funkce zpracování kontextu
V praktické rovině rozlišujeme čtyři základní operace:
Sběr relevantních kontextových signálů z různých senzorů a informačních zdrojů
Ukládání těchto informací napříč lokálními systémy, sítěmi a cloudem
Správa složitosti skrze inteligentní zpracování textu, multimodálních vstupů a vztahů
Využití kontextu strategicky filtrováním relevance, sdílením mezi systémy a adaptací podle potřeb uživatele
Proč záleží na kontextovém inženýrství: rámec snižování entropie
Kontextové inženýrství řeší základní nesymetrii v komunikaci člověk–stroj. Když spolu hovoří lidé, mezery v konverzaci automaticky vyplňují díky sdílenému kulturnímu povědomí, emoční inteligenci a situačnímu vnímání. Stroje tyto schopnosti nemají.
Tento rozdíl se projevuje jako informační entropie. Lidská komunikace je efektivní díky předpokladu masivního sdíleného kontextu. Stroje potřebují vše explicitně. Kontextové inženýrství je v podstatě předzpracováním kontextu pro stroje—komprimuje složitost lidského záměru do strojově zpracovatelných reprezentací s nízkou entropií.
Jak strojová inteligence pokročuje, tento proces se stále více automatizuje. Dnes, v éře 2.0, orchestrují většinu tohoto zpracování inženýři manuálně. V éře 3.0 a dále převezmou větší část této zátěže samotné stroje. Hlavní výzva však zůstává: překlenout propast mezi lidskou komplexností a strojovým porozuměním.
Prompt engineering vs. Kontextové inženýrství: zásadní rozdíly
Častou chybou je ztotožňování těchto disciplín. Ve skutečnosti jde o zásadně odlišné přístupy k architektuře AI systémů.
Prompt engineering je zaměřený na tvorbu jednotlivých instrukcí nebo dotazů, které ovlivňují chování modelu. Jde o optimalizaci jazykové struktury—formulace, příkladů a vzorů uvažování v rámci jedné interakce.
Kontextové inženýrství je komplexní systémová disciplína, která spravuje vše, s čím se model při inferenci setkává—včetně promptů, ale i načítaných dokumentů, paměťových systémů, popisů nástrojů, stavu a dalších prvků.
Prompt Engineering vs Kontextové inženýrství: Klíčové rozdíly a kompromisy
Rozdíl si představte takto: Požádat ChatGPT o sestavení profesionálního e-mailu je prompt engineering. Vybudovat zákaznickou platformu, která udržuje historii konverzací napříč relacemi, přistupuje k detailům účtu a pamatuje si předchozí ticket je kontextové inženýrství.
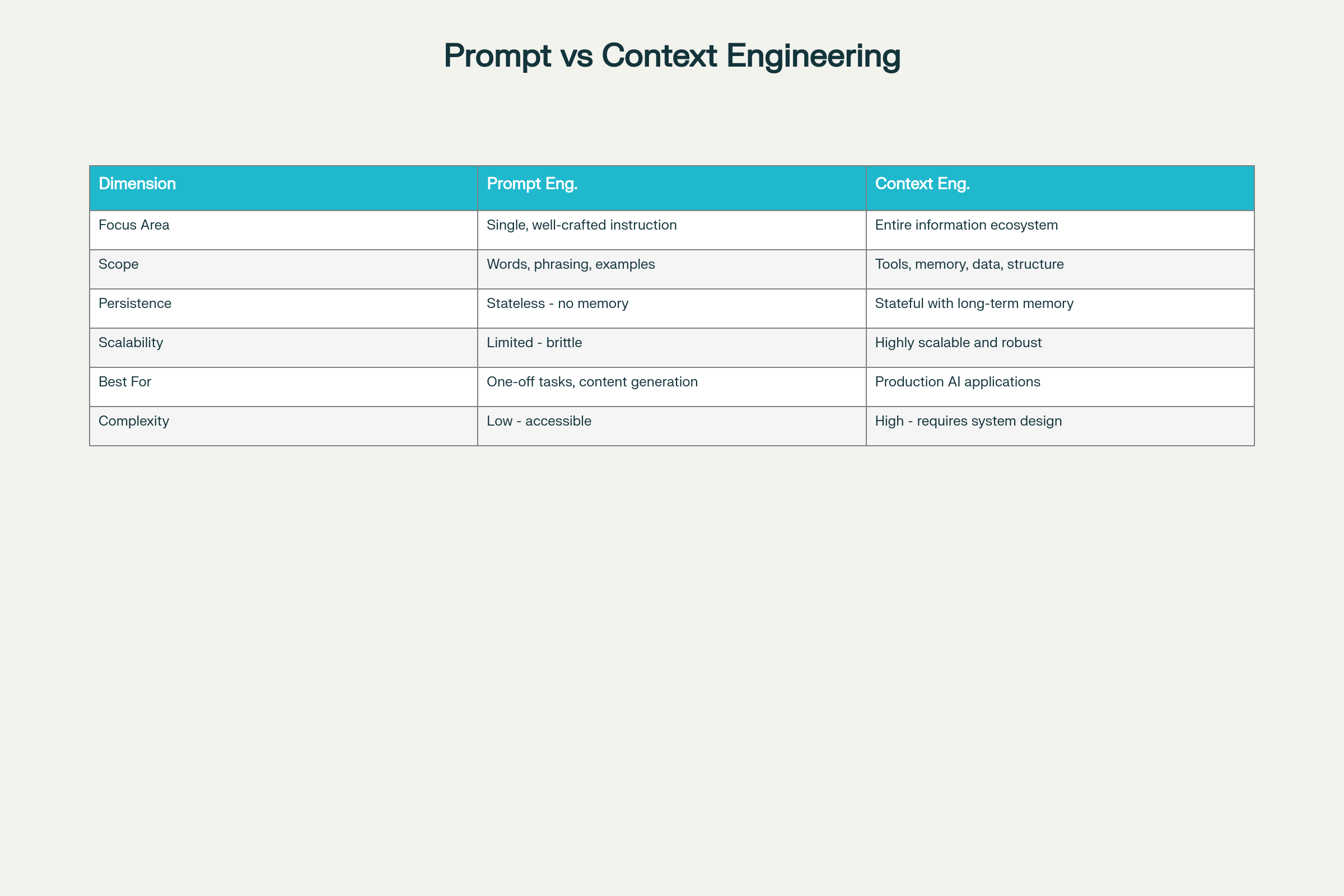
Klíčové rozdíly v osmi dimenzích:
Dimenze
Prompt Engineering
Kontextové inženýrství
Oblast zaměření
Optimalizace jednotlivých instrukcí
Komplexní informační ekosystém
Rozsah
Slova, formulace, příklady
Nástroje, paměť, data, architektura, struktura
Perzistence
Bez stavové paměti
Stavové s dlouhodobou pamětí
Škálovatelnost
Omezená, křehká při škále
Vysoce škálovatelná a robustní
Nejvhodnější pro
Jednorázové úkoly, generování obsahu
Produkční AI aplikace
Složitost
Nízká vstupní bariéra
Vysoká—vyžaduje systémový návrh
Spolehlivost
Nepředvídatelná při škále
Konzistentní a spolehlivá
Údržba
Křehká při změnách požadavků
Modulární a snadno spravovatelná
Podstatná myšlenka: Produkční LLM aplikace téměř vždy vyžadují kontextové inženýrství, nikoli jen promyšlené prompty. Jak poznamenali v Cognition AI, kontextové inženýrství se v podstatě stalo hlavní odpovědností inženýrů budujících AI agenty.
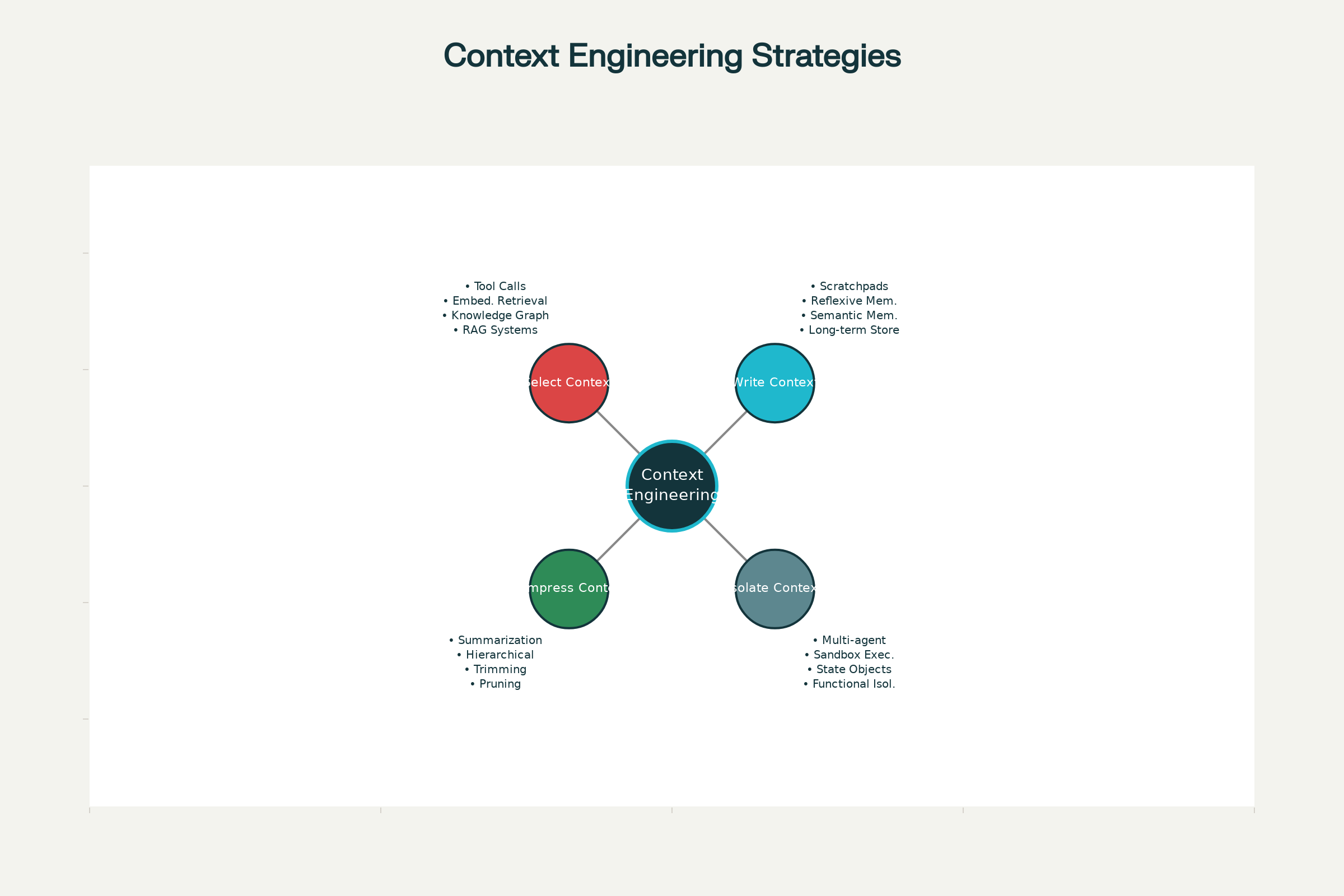
Čtyři základní strategie kontextového inženýrství
Napříč špičkovými AI systémy—od Claude a ChatGPT po specializované agenty Anthropic a dalších laboratoří—krystalizovaly čtyři základní strategie efektivního řízení kontextu. Ty lze nasadit samostatně nebo v kombinaci.
1. Zápis kontextu: Ukládání informací mimo kontextové okno
Základní princip je prostý: nenutí model vše si pamatovat; klíčové informace uložte mimo kontextové okno a načítejte podle potřeby.
Poznámkové bloky (Scratchpady) jsou nejintuitivnější implementací. Stejně jako si lidé zapisují poznámky při složitých úlohách, AI agenti používají scratchpady k uchování informací pro budoucí použití. Implementace sahá od jednoduchého nástroje pro ukládání poznámek až po pole v běhovém stavu, která přetrvávají napříč kroky.
Multiagentní výzkumník Anthropic to demonstruje: LeadResearcher nejprve sestaví plán a uloží jej do paměti, protože při překročení 200 000 tokenů okna dojde k oříznutí a plán je třeba zachovat.
Paměti rozšiřují koncept scratchpadu napříč relacemi. Místo zachycování informací jen v rámci jednoho úkolu (session-scoped memory) systémy budují dlouhodobé paměti, které se vyvíjí napříč interakcemi. Tento vzor je dnes standardem v ChatGPT, Claude Code, Cursor i Windsurf.
Výzkumné projekty jako Reflexion zavedly reflexivní paměti—agent reflektuje každý tah a generuje paměť pro budoucí využití. Generative Agents přistupují k periodickému syntetizování paměti z minulých podnětů.
Tři typy pamětí:
Epizodická: Konkrétní příklady minulých chování či interakcí (cenné pro few-shot učení)
Procedurální: Instrukce nebo pravidla chování (zajišťují konzistenci)
Sémantická: Fakta a vztahy o světě (poskytují ukotvené znalosti)
2. Výběr kontextu: Načtení správných informací
Jakmile jsou informace uloženy, agent musí načítat pouze relevantní pro daný úkol. Špatný výběr je stejně škodlivý jako žádná paměť—nerelevantní informace model matou či spouští halucinace.
Mechanismy výběru paměti:
Jednodušší přístupy používají úzké, vždy začleněné soubory. Claude Code např. používá CLAUDE.md pro procedurální paměť, Cursor a Windsurf pak rules. Tento přístup je však neškálovatelný při stovkách faktů a vztahů.
Pro větší kolekce paměti se běžně nasazuje retrieval na základě embeddingů a znalostní grafy. Systém převádí paměti i aktuální dotaz do vektorových reprezentací a načte nejpodobnější.
Simon Willison ovšem na AIEngineer World’s Fair ukázal, jak i tento přístup může selhat: ChatGPT nečekaně použil jeho lokaci z paměti do generovaného obrázku. I sofistikované systémy tedy musí volbu pamětí pečlivě inženýrovat.
Výběr nástroje je další výzva. Má-li agent desítky či stovky nástrojů, jejich prostý výpis vede ke zmatení. Efektivní řešení: aplikovat principy RAG na popisy nástrojů—načítat jen relevantní, čímž se přesnost výběru ztrojnásobila.
Načítání znalostí je možná nejbohatší problémová oblast. Kódovací agenti s tím bojují ve velkém měřítku. Windsurf např. indexuje a vyhledává kód s AST parsingem a chunkováním podle významových hranic; embedding search ale s rostoucím kódem selhává. Úspěch vyžaduje kombinaci search technik, znalostních grafů a re-rankingu podle relevance.
3. Komprese kontextu: Zachování jen podstatného
Při dlouhých úlohách agentů se kontext přirozeně hromadí. Poznámky, výstupy nástrojů i historie interakcí mohou rychle překročit okno. Kompresní strategie tento problém řeší inteligentní destilací informací.
Sumarizace je hlavní technika. Claude Code implementuje “auto-compact”—při 95 % kapacity okna se shrne celá historie interakcí. Strategie zahrnují:
Rekurzivní sumarizace: Tvorba shrnutí shrnutí pro hierarchickou kompaktnost
Hierarchická sumarizace: Shrnutí na více úrovních abstrakce
Cílená sumarizace: Komprese konkrétních částí (např. objemné výsledky vyhledávání)
Cognition AI využívá jemně doladěné modely pro sumarizaci na rozhraních agentů při předávání znalostí—ukazuje to hloubku potřebného inženýrství.
Ořezávání kontextu je doplňkový přístup: místo sumarizace LLM prostě ořízne kontext podle heuristik—odstraní starší zprávy, filtruje podle důležitosti či používá trénované ořezávače (např. Provence pro QA úlohy).
Klíčová myšlenka: Na tom, co odstraníte, záleží stejně jako na tom, co ponecháte. Zaměřený 300tokenový kontext často překoná neřízený 113 000tokenový v konverzacích.
4. Izolace kontextu: Rozdělování informací mezi systémy
Izolační strategie uznávají, že různé úkoly vyžadují různé informace. Místo nahuštění všeho do jednoho okna se kontext dělí mezi specializované systémy.
Multiagentní architektury jsou nejčastější. OpenAI Swarm je stavěn na “separaci odpovědností”—specializovaní subagenti řeší konkrétní úlohy s vlastními nástroji a kontexty.
Anthropic ukazuje sílu tohoto přístupu: mnoho agentů s oddělenými kontexty překonává jednoagentní implementace, neboť každý subagent má okno přizpůsobené podúkolu a pracuje paralelně.
Multiagentní systémy však mají kompromisy—Anthropic hlásí až patnáctinásobné zvýšení spotřeby tokenů oproti chatování s jedním agentem. Vyžaduje to orchestraci, plánování promptů a sofistikovanou koordinaci.
Sandboxy jsou další izolační strategií. Například CodeAgent od HuggingFace místo návratu JSON generuje kód, který se spouští v sandboxu. Výstupy (např. návratové hodnoty) se předávají zpět LLM, těžké objekty zůstávají v prostředí. Toto je ideální pro vizuální a audio data.
Izolace stavových objektů je možná nejpodceňovanější technika. Stav agenta může být navržen jako strukturované schéma (např. Pydantic model) s více poli—jedno (např. messages) je přístupné LLM, ostatní zůstávají izolované pro selektivní použití. To dává jemnou kontrolu bez složitosti architektury.
Čtyři základní strategie efektivního kontextového inženýrství v AI agentech
Problém rozkladu kontextu: zásadní výzva
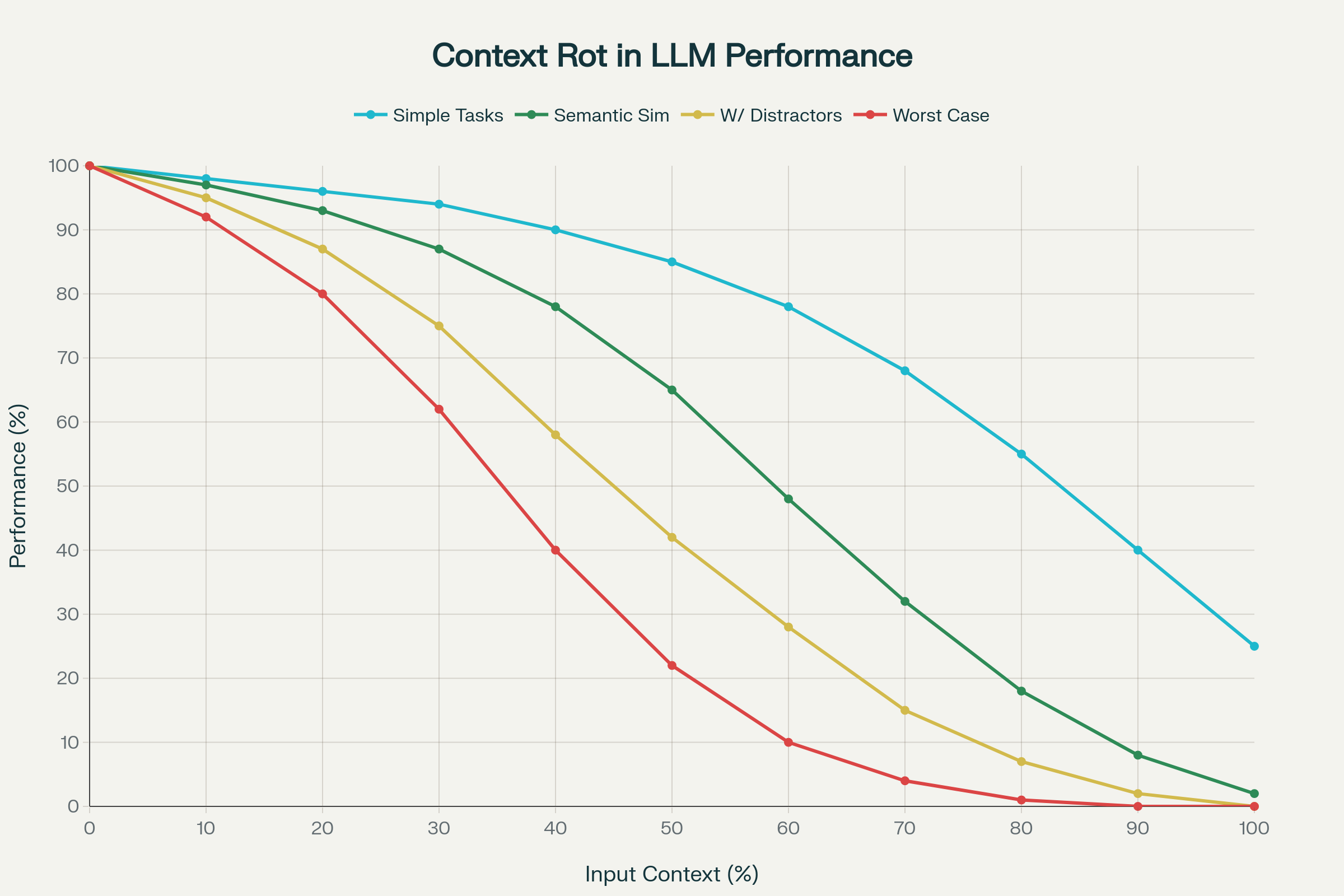
Zatímco prodlužování kontextu je oslavováno napříč oborem, nedávný výzkum odhalil znepokojivou realitu: delší kontext automaticky neznamená lepší výkon.
Průlomová studie 18 předních LLM (včetně GPT-4.1, Claude 4, Gemini 2.5 a Qwen 3) popsala jev nazvaný rozklad kontextu: nepředvídatelné a často závažné zhoršování výkonu s rostoucím vstupním kontextem.
Klíčová zjištění o rozkladu kontextu
1. Nerovnoměrné zhoršování výkonu
Výkon neklesá lineárně, ale nárazově, idiosynkraticky podle modelu a úlohy. Model může udržet 95 % přesnosti do určité délky kontextu a pak náhle klesnout na 60 %. Tyto “útesy” jsou napříč modely nevyzpytatelné.
2. Sémantická složitost rozklad umocňuje
Jednoduché úlohy (kopírování slov, přesné vyhledání) znamenají mírný pokles. Pokud však “jehlu v kupce sena” určuje sémantická podobnost, výkon prudce padá. Přidání relevantních, ale ne zcela správných informací situaci ještě zhoršuje.
3. Pozicové zkreslení a kolaps pozornosti
Pozornost transformátorů neroste lineárně s délkou kontextu. Začátek (primární zkreslení) a konec (recency bias) získávají neúměrnou pozornost. V extrému pozornost kolabuje a model ignoruje podstatné části vstupu.
4. Modelově specifické vzory selhání
Různé LLM vykazují při škále unikátní chování:
GPT-4.1: Halucinuje opakováním chybných tokenů
Gemini 2.5: Vkládá nesouvisející fragmenty či interpunkci
Claude Opus 4: Někdy odmítá úlohu nebo je přehnaně opatrný
5. Dopad v reálných konverzacích
Největší překvapení: v benchmarku LongMemEval dosahovaly modely s celými konverzacemi (~113k tokenů) horšího výkonu než při použití zaměřeného 300tokenového segmentu. Kontextový rozklad tedy degraduje jak retrieval, tak reasoning i v praxi.
Rozklad kontextu: Zhoršení výkonu s rostoucím počtem vstupních tokenů u 18 LLM
Důsledky: Kvalita před kvantitou
Hlavní závěr výzkumu rozkladu kontextu je jasný: množství tokenů není samo o sobě určující pro kvalitu. Stejně důležité je, jak je kontext sestaven, filtrován a prezentován.
To dává za pravdu celému oboru kontextového inženýrství. Místo spoléhání na dlouhá okna si vyspělé týmy uvědomují, že pečlivé kontextové inženýrství—skrze kompresi, výběr a izolaci—je nezbytné pro udržení výkonu i při velkých vstupech.
Kontextové inženýrství v praxi: příklady z reálného světa
Případová studie 1: Multi-turn agentní systémy (Claude Code, Cursor)
Claude Code a Cursor představují špičku kontextového inženýrství pro asistenci s kódem:
Sběr: Systémy shromažďují kontext z více zdrojů—otevřené soubory, struktura projektu, historie úprav, terminálový výstup, komentáře uživatele.
Správa: Místo vkládání všech souborů do promptu inteligentně komprimují. Claude Code využívá hierarchická shrnutí a kontext taguje podle funkce (“právě editovaný soubor”, “referencovaná závislost”, “chybová hláška”).
Využití: V každém kroku systém vybírá relevantní soubory a kontextové prvky, prezentuje je ve strukturovaném formátu a odděluje reasoning a viditelný výstup.
Kompresní mechanismy: Při blížícím se limitu automaticky spouští shrnutí interakční trajektorie se zachováním klíčových rozhodnutí.
Výsledek: Tyto nástroje jsou použitelné i ve velkých projektech (tisíce souborů) bez zhoršení výkonu, a to navzdory omezení kontextového okna.
Případová studie 2: Tongyi DeepResearch (open-source deep research agent)
Tongyi DeepResearch ukazuje, jak kontextové inženýrství umožňuje komplexní výzkumné úlohy:
Pipeline syntézy dat: Místo omezení na lidsky anotovaná data Tongyi používá sofistikovaný pipeline generující otázky na PhD úrovni iterativním zvyšováním složitosti. Každé kolo prohlubuje znalostní hranice a vytváří komplexnější úlohy.
Správa kontextu: Systém využívá paradigma IterResearch—v každém kole rekonstruuje pracovní prostor pouze ze zásadních výstupů předchozího kola. Tak se zabrání “kognitivnímu udušení” z přílišného množství informací v jednom okně.
Paralelní průzkum: Více agentů zkoumá paralelně různé aspekty s oddělenými kontexty. Syntetizující agent pak integruje jejich poznatky.
Výsledky: Tongyi DeepResearch dosahuje výkonu srovnatelného s proprietárními systémy typu OpenAI DeepResearch (score 32,9 na Humanity’s Last Exam a 75 na uživatelských benchmarcích).
Případová studie 3: Multiagentní výzkumník Anthropic
Výzkum Anthropic ukazuje, jak izolace a specializace zlepšují výkon:
Architektura: Specializovaní subagenti řeší konkrétní úkoly (literární rešerše, syntéza, ověřování) s oddělenými okny.
Přínosy: Tento přístup překonal jednoagentní systémy, neboť každý subagent má kontext optimalizovaný pro svůj úkol.
Kompromis: Kvalita je vyšší, ale spotřeba tokenů až patnáctkrát větší než u jednoagentního chatu.
To ilustruje klíčovou myšlenku: Kontextové inženýrství často znamená hledání rovnováhy mezi kvalitou, rychlostí a náklady podle požadavků aplikace.
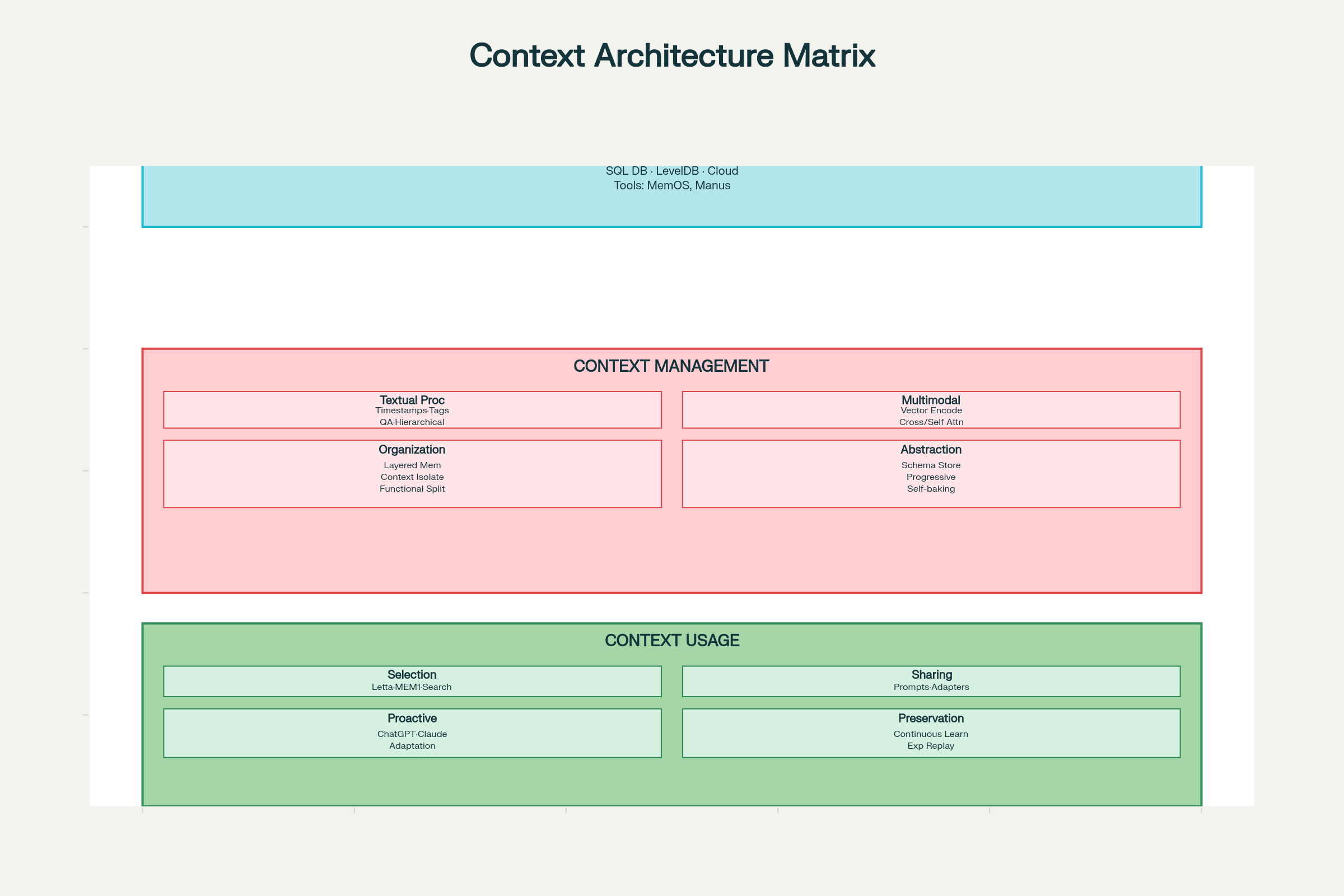
Rámec návrhových úvah pro kontextové inženýrství
Implementace efektivního kontextového inženýrství vyžaduje systematické myšlení ve třech dimenzích: sběr a ukládání, správa a využití.
Návrhové úvahy kontextového inženýrství: Architektura a komponenty systému
Návrh sběru a ukládání
Volba technologie ukládání:
Lokální úložiště (SQLite, LevelDB): Rychlé, s nízkou latencí, vhodné pro klientské agenty
Distribuované systémy: Pro masivní škálu, redundanci a odolnost vůči chybám
Návrhové vzory:
MemOS: Operační systém pro sjednocenou správu paměti
Manus: Strukturovaná paměť s řízením přístupových práv
Klíčový princip: Navrhujte pro efektivní vyhledávání, nejen ukládání. Optimální úložiště je to, ve kterém rychle najdete, co potřebujete.
Návrh správy
Zpracování textového kontextu:
Časové značky: Jednoduché, ale omezené. Zachovají chronologii, ale ne sémantiku; při akumulaci interakcí škáluje špatně.
Tagování rolí/funkcí: Každý kontextový prvek označit funkcí—“cíl”, “rozhodnutí”, “akce”, “chyba” apod. Podporuje vícedimenzionální tagování (priorita, zdroj, důvěra). Moderní systémy jako LLM4Tag to umožňují ve velkém.
Kompresní QA páry: Převod interakcí do kompaktních otázek a odpovědí, zachování podstaty při snížení spotřeby tokenů.
Hierarchické poznámky: Postupná komprese do sémantických vektorů (H-MEM systémy), zachycení významu na různých úrovních.
Zpracování multimodálního kontextu:
Srovnatelné vektorové prostory: Zakódování všech modalit (text, obraz, audio) do společných embeddingů (ChatGPT, Claude).
Cross-Attention: Jedna modalita řídí pozornost druhé (Qwen2-VL).
Nezávislé kódování se self-attention: Modalita kódována zvlášť, pak kombinována sjednocenou pozorností.
Organizace kontextu:
Vrstvená paměťová architektura: Oddělení pracovní paměti (aktuální kontext), krátkodobé paměti (nedávná historie) a dlouhodobé paměti (trvalá fakta).
Funkční izolace kontextu: Subagenti s oddělenými kontextovými okny pro různé funkce (Claude).
Abstrakce kontextu (Self-baking):
“Self-baking” znamená, že se kontext zlepšuje opakovaným zpracováním. Vzory:
Uložit syrový kontext, pak přidávat shrnutí v přirozeném jazyce (Claude Code, Gemini CLI)
Extrahovat klíčová fakta dle schématu (ChatSchema)
Postupně komprimovat do významových vektorů (H-MEM)
Návrh využití
Výběr kontextu:
Retrieval na základě embeddingů (nejběžnější)
Procházení znalostního grafu (pro složité vztahy)
Sémantické skórování podobnosti
Váhování podle aktuálnosti/priority
Sdílení kontextu:
Uvnitř systému:
Embedování vybraného kontextu do promptů (AutoGPT, ChatDev)
Strukturovaná výměna zpráv mezi agenty (Letta, MemOS)
Sdílená paměť přes nepřímou komunikaci (A-MEM systémy)
ChatGPT a Claude analyzují vzorce interakcí a předvídají potřeby uživatele
Kontextové systémy se učí poskytovat informace dříve, než si je uživatel vyžádá
Rovnováha mezi užitečností a soukromím je klíčová výzva
Dovednosti v kontextovém inženýrství a co se týmy musí naučit
S tím, jak se kontextové inženýrství stává ústřední pro vývoj AI, oddělují některé dovednosti úspěš
Často kladené otázky
Prompt engineering se zaměřuje na sestavení jednoho zadání pro LLM. Kontextové inženýrství je širší systémová disciplína, která spravuje celý informační ekosystém pro AI model, včetně paměti, nástrojů a načítaných dat, aby optimalizovala výkon při komplexních, stavových úlohách.
Rozklad kontextu je nepředvídatelné zhoršení výkonu LLM, jakmile se jeho vstupní kontext prodlužuje. Modely mohou vykazovat prudký pokles přesnosti, ignorovat části kontextu nebo halucinovat, což ukazuje na nutnost kvality a pečlivé správy kontextu namísto prostého navyšování množství.
Čtyři základní strategie jsou: 1. Zápis kontextu (ukládání informací mimo kontextové okno, jako poznámky nebo paměť), 2. Výběr kontextu (načítání pouze relevantních informací), 3. Komprese kontextu (shrnutí nebo ořezání pro úsporu místa) a 4. Izolace kontextu (využití multiagentních systémů nebo sandboxů pro oddělení oblastí).
Arshia je inženýr AI pracovních postupů ve FlowHunt. Sxa0vzděláním vxa0oboru informatiky a vášní pro umělou inteligenci se specializuje na vytváření efektivních workflow, které integrují AI nástroje do každodenních úkolů a zvyšují tak produktivitu i kreativitu.
Arshia Kahani
Inženýr AI pracovních postupů
Ovládněte kontextové inženýrství
Připraveni stavět novou generaci AI systémů? Prozkoumejte naše zdroje a nástroje pro implementaci pokročilého kontextového inženýrství ve vašich projektech.
Ať žije kontextové inženýrství: Stavba produkčních AI systémů s moderními vektorovými databázemi
Prozkoumejte, jak kontextové inženýrství mění vývoj AI, evoluci od RAG k produkčně připraveným systémům a proč jsou moderní vektorové databáze jako Chroma klíčo...
Inženýrství kontextu pro AI agenty: Mistrovství v optimalizaci tokenů a výkonu agentů
Zjistěte, jak inženýrství kontextu optimalizuje výkon AI agentů strategickým řízením tokenů, eliminací nadbytečného kontextu a zaváděním pokročilých technik jak...
Inženýrství kontextu pro AI agenty: Jak správně předávat LLM správné informace
Naučte se, jak navrhovat kontext pro AI agenty správou zpětné vazby nástrojů, optimalizací využití tokenů a implementací strategií jako offloading, komprese a i...
15 min čtení
AI Agents
LLM
+3
Souhlas s cookies Používáme cookies ke zlepšení vašeho prohlížení a analýze naší návštěvnosti. See our privacy policy.