Human-in-the-Loop middleware v Pythonu: Vytváření bezpečných AI agentů se schvalovacími workflowy
Naučte se implementovat human-in-the-loop middleware v Pythonu pomocí LangChainu a přidat možnost schvalování, úprav a zamítnutí akcí AI agentů před spuštěním nástrojů.
Vytváření AI agentů, kteří mohou autonomně spouštět nástroje a provádět akce, je mocné, ale přináší s sebou i určitá rizika. Co se stane, když se agent rozhodne odeslat e-mail s chybnými informacemi, schválit velkou finanční transakci nebo upravit klíčové databázové záznamy? Bez správných ochranných opatření mohou autonomní agenti způsobit výrazné škody dříve, než si toho někdo všimne. Právě zde je human-in-the-loop middleware klíčový. V tomto podrobném průvodci si ukážeme, jak implementovat human-in-the-loop middleware v Pythonu pomocí LangChainu, abyste mohli stavět AI agenty, kteří před vykonáním citlivých operací čekají na schválení člověkem. Naučíte se přidávat schvalovací workflowy, implementovat možnosti úprav i zamítnutí — a to vše při zachování efektivity a inteligence vašich autonomních systémů.
Pochopení AI agentní smyčky a spouštění nástrojů
Než se pustíme do human-in-the-loop middleware, je důležité pochopit, jak AI agenti v základu fungují. AI agent pracuje v nepřetržité smyčce, která se opakuje, dokud nerozhodne, že svůj úkol dokončil. Základní agentní smyčka se skládá ze tří hlavních komponent: jazykového modelu, který rozhoduje o dalším kroku, sady nástrojů, které agent může použít k provedení akce, a systému správy stavu, který uchovává historii konverzace a relevantní kontext. Agent začne tím, že přijme vstupní zprávu od uživatele, jazykový model analyzuje tento vstup spolu s dostupnými nástroji a rozhodne, zda zavolá nástroj, nebo rovnou poskytne výstup. Pokud model rozhodne o volání nástroje, nástroj se provede a výsledek se přidá zpět do historie rozhovoru. Tento cyklus pokračuje — úvaha modelu, výběr nástroje, spuštění nástroje, integrace výsledků — dokud model nerozhodne, že další volání nástroje nejsou potřeba, a poskytne finální odpověď uživateli.
Tento jednoduchý, avšak mocný vzor se stal základem stovek frameworků pro AI agenty v posledních letech. Elegance agentní smyčky spočívá v její flexibilitě: změnou nástrojů dostupných agentovi můžete umožnit provádění zcela odlišných úloh. Agent s e-mailovými nástroji může spravovat komunikaci, agent s databázovými nástroji může dotazovat a upravovat záznamy, a agent s finančními nástroji může zpracovávat transakce. Tato flexibilita však zároveň přináší rizika. Protože agentní smyčka funguje autonomně, není zde zabudován žádný mechanismus pro pozastavení a dotaz člověka, zda by se konkrétní akce skutečně měla provést. Model se může rozhodnout odeslat e-mail, spustit databázový dotaz nebo schválit finanční transakci — a když to člověk zjistí, je už akce dávno provedena. Právě zde se limity základní agentní smyčky v produkčním prostředí ukazují naplno.
Připraveni rozšířit své podnikání?
Začněte svou bezplatnou zkušební verzi ještě dnes a viďte výsledky během několika dní.
Proč je lidský dohled v produkčních AI systémech důležitý
S tím, jak jsou AI agenti stále schopnější a nasazují se v reálných firemních prostředích, potřeba lidského dohledu rychle narůstá. Význam autonomních akcí agenta se dramaticky liší podle kontextu. Některá volání nástrojů jsou nízkoriziková a mohou se provést ihned bez lidské kontroly — například čtení e-mailu nebo získání informace z databáze. Jiná volání jsou však vysoce riziková a často nevratná, jako odeslání komunikace jménem uživatele, převod peněz, mazání záznamů nebo učinění závazků jménem organizace. V produkčních systémech může chyba agenta u vysoce rizikové operace znamenat obrovské náklady. Špatně formulovaný e-mail nesprávnému příjemci může poškodit obchodní vztahy. Nesprávně schválený rozpočet může vést ke ztrátám. Mazání databáze omylem může znamenat ztrátu dat, jejíž obnova trvá hodiny nebo dny.
Kromě okamžitých provozních rizik zde hrají roli i požadavky na compliance a regulace. Mnoho oborů má striktní pravidla, že určitá rozhodnutí musí zahrnovat lidský úsudek a schválení. Finanční instituce musí mít lidský dohled nad transakcemi nad určitou částkou. Zdravotnické systémy vyžadují lidskou revizi některých automatizovaných rozhodnutí. Právní firmy musí zajistit, že komunikace je schválena před odesláním klientům. Tato pravidla nejsou zbytečná byrokracie — existují proto, že důsledky plně autonomního rozhodování v těchto oblastech mohou být vážné. Lidský dohled navíc poskytuje mechanismus zpětné vazby, která pomáhá agenta časem vylepšovat. Když člověk revizí návrhu agenta akci schválí nebo upraví, tato zpětná vazba může být využita k úpravě promptů, logiky výběru nástrojů nebo přeškolení modelů. Vzniká tak pozitivní smyčka, kde je agent spolehlivější a lépe přizpůsobený potřebám a rizikovému profilu organizace.
Co je Human-in-the-Loop Middleware?
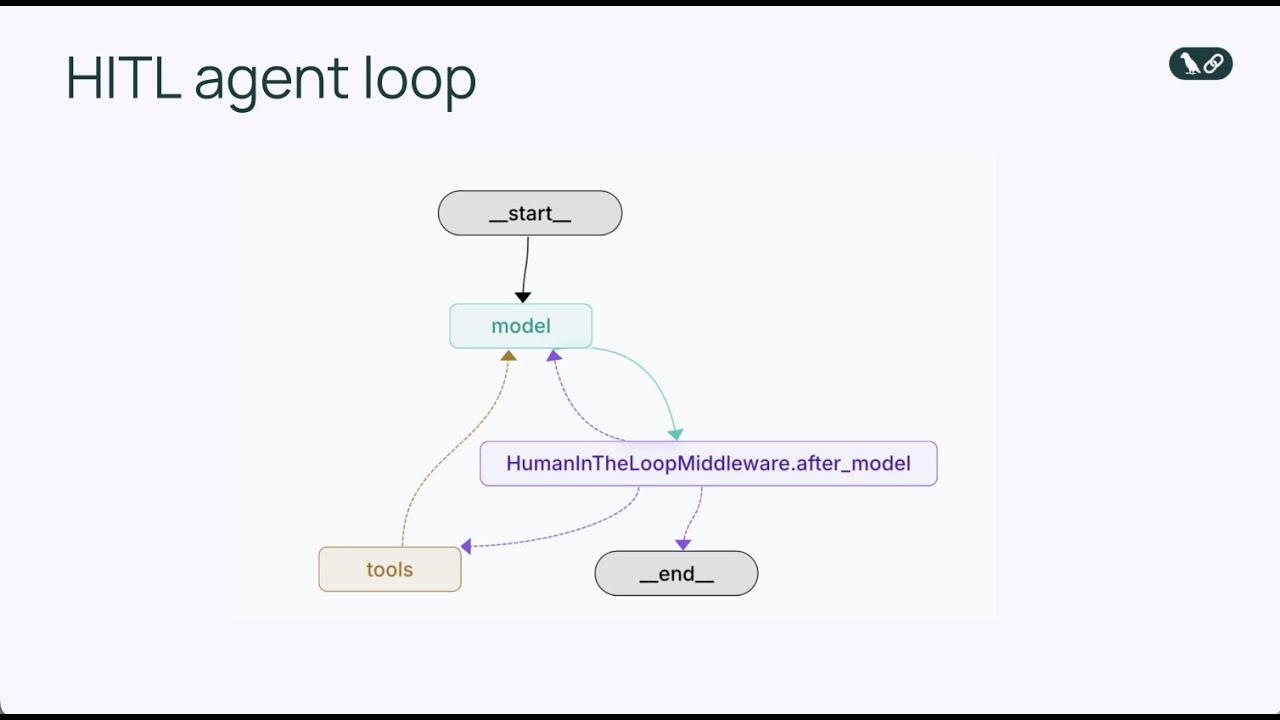
Human-in-the-loop middleware je specializovaná komponenta, která zachytí agentní smyčku v kritickém okamžiku: těsně před spuštěním nástroje. Místo okamžitého provedení volání nástroje middleware zastaví proces a předloží navrženou akci k revizi člověku. Ten má na výběr několik možností. Akci může schválit a umožnit její provedení přesně tak, jak agent navrhl. Akci může upravit, například změnit parametry (adresáta e-mailu, obsah zprávy atd.) před provedením. Nebo může akci zcela zamítnout a poslat agentovi zpětnou vazbu s vysvětlením, proč byla akce nevhodná, a požádat o přepracování. Tento třícestný rozhodovací mechanismus — schválit, upravit, zamítnout — vytváří flexibilní rámec pro různé požadavky na lidský dohled.
Middleware funguje tak, že upraví standardní agentní smyčku o další rozhodovací bod. V základní smyčce je postup: model zavolá nástroje → nástroje se provedou → výsledky se vrátí modelu. S human-in-the-loop middleware je postup: model zavolá nástroje → middleware zachytí → člověk zreviduje → člověk rozhodne (schválit/upravit/zamítnout) → pokud schváleno nebo upraveno, nástroj se provede → výsledky se vrátí modelu. Vložení lidského rozhodovacího bodu agentní smyčku nenaruší — naopak ji obohatí o bezpečnostní pojistku. Middleware je konfigurovatelný, takže můžete určit, které nástroje mají spouštět lidskou revizi a které se mohou provádět automaticky. Například můžete vyžadovat kontrolu pro všechny e-mailové nástroje, ale povolit přímé provádění pouze pro čtení z databáze. Tato granulární kontrola umožňuje přidat lidský dohled přesně tam, kde je třeba, bez zbytečných průtahů u nízkorizikových operací.
Přihlaste se k odběru newsletteru
Získejte nejnovější tipy, trendy a nabídky zdarma.
Tři typy odpovědí: Schválení, Úprava a Zamítnutí
Když human-in-the-loop middleware přeruší spuštění nástroje, má člověk tři základní možnosti odpovědi, z nichž každá má své místo v procesu schvalování.
Schválení je nejjednodušší typ odpovědi. Pokud člověk návrh nástroje zreviduje a rozhodne, že je vhodný a má být proveden přesně podle návrhu agenta, vybere schválení. To signalizuje middleware, že nástroj má být proveden s přesně těmi parametry, které agent navrhl. U e-mailového asistenta to znamená, že návrh e-mailu je v pořádku a má být odeslán určenému příjemci s daným předmětem a textem. Schválení je cesta nejmenšího odporu — umožňuje provést návrh agenta bez změn. Je vhodné tam, kde agent odvedl dobrou práci a člověk s návrhem souhlasí. Schválení je obvykle rychlé, což je důležité, protože nechcete, aby lidská revize zpomalovala celý workflow.
Úprava je jemnější typ odpovědi, který říká, že agentův návrh je správný v principu, ale některé detaily je třeba změnit před provedením. Člověk tedy návrh neupravuje v tom, zda se má akce provést, ale jak konkrétně. U e-mailu to může být změna adresáta, úprava předmětu nebo doplnění či odstranění textu. Klíčem je, že úprava mění parametry nástroje, ale zachovává jeho původní volání. Agent rozhodl o odeslání e-mailu, člověk s tím souhlasí, ale chce doladit obsah nebo adresáta. Po provedení úprav se nástroj spustí s upravenými parametry a výsledek se vrátí agentovi. Tento postup je obzvláště cenný, protože umožňuje agentovi navrhovat akce a zároveň dává lidem možnost je doladit podle odbornosti a znalosti firemního kontextu.
Zamítnutí je nejzásadnější odpověď, protože nejen zastaví provedení navrhované akce, ale také poskytne agentovi zpětnou vazbu s vysvětlením, proč byla akce nevhodná. Pokud člověk zamítne volání nástroje, znamená to, že navržená akce nemá být provedena a je třeba, aby agent svůj přístup přehodnotil. U e-mailu může jít například o návrh schválit významný rozpočet bez dostatečných podkladů. Člověk zamítne tuto akci a vrátí agentovi zprávu, že je třeba více detailů. Tato zamítavá zpráva se stane součástí kontextu agenta, který na základě zpětné vazby může navrhnout jiný postup. Tímto způsobem se agent učí a zlepšuje své rozhodování.
Pojďme si projít konkrétní implementaci human-in-the-loop middleware s využitím LangChainu a Pythonu. Příklad bude e-mailový asistent — praktický scénář, na kterém je hodnota lidského dohledu dobře vidět. Asistent bude schopen jménem uživatele odesílat e-maily, přičemž přidáme human-in-the-loop middleware, aby všechna odesílání byla předem schválena.
Nejprve definujeme e-mailový nástroj, který bude agent používat. Přijímá tři parametry: adresu příjemce, předmět a tělo e-mailu. Nástroj je jednoduchý — pouze reprezentuje akci odeslání e-mailu. V reálném nasazení by šlo například o propojení s Gmail/Outlook, zde postačí základní ukázka:
defsend_email(recipient: str, subject: str, body: str) -> str:
"""Odešle e-mail zadanému příjemci."""returnf"E-mail odeslán na {recipient} s předmětem '{subject}'"
Následně vytvoříme agenta, který tento nástroj využívá. Použijeme GPT-4 jako jazykový model a poskytneme systémový prompt, že agent je nápomocný e-mailový asistent. Agent je inicializován s e-mailovým nástrojem a připraven reagovat na požadavky uživatele:
from langchain.agents import create_agent
from langchain_openai import ChatOpenAI
model = ChatOpenAI(model="gpt-4o")
tools = [send_email]
agent = create_agent(
model=model,
tools=tools,
system_prompt="Jste nápomocný e-mailový asistent pro Sydney. Můžete odesílat e-maily jménem uživatele.")
Nyní máme základního agenta, který může odesílat e-maily. Ale chybí lidský dohled – agent může e-maily odesílat bez kontroly. Přidáme tedy human-in-the-loop middleware. Implementace je překvapivě jednoduchá, stačí dva řádky kódu:
from langchain.agents.middleware import HumanInTheLoopMiddleware
agent = create_agent(
model=model,
tools=tools,
system_prompt="Jste nápomocný e-mailový asistent pro Sydney. Můžete odesílat e-maily jménem uživatele.",
middleware=[
HumanInTheLoopMiddleware(
interrupt_on={"send_email": True}
)
]
)
Přidáním HumanInTheLoopMiddleware a nastavením interrupt_on={"send_email": True} říkáme agentovi, aby před každým voláním send_email pozastavil činnost a počkal na lidské schválení. Hodnota True znamená, že všechna volání budou přerušena s výchozí konfigurací. Pokud bychom chtěli jemnější kontrolu, lze určit typy povolených rozhodnutí (schválit, upravit, zamítnout) či vlastní popis přerušení.
Testování middleware na nízkorizikových scénářích
Jakmile máme middleware, otestujeme jej na nízkorizikovém příkladu. Představme si, že uživatel požádá agenta o odpověď na neformální e-mail od kolegyně Alice, která navrhuje kávu příští týden. Agent tento požadavek zpracuje a rozhodne se odeslat přátelskou odpověď. Proběhne následující:
Model agenta to zpracuje a zavolá nástroj send_email s parametry jako recipient=“alice@example.com
”, subject=“Káva příští týden?”, body=“Rád bych šel na kávu příští týden!”
Před odesláním middleware zachytí volání nástroje a přeruší tok.
Člověk zreviduje navrhovaný e-mail. E-mail je vhodný — přátelský, profesionální, splňuje požadavek uživatele.
Člověk schválí akci.
Middleware umožní provedení nástroje a e-mail se odešle.
Tento workflow demonstruje základní schvalovací cestu. Lidská revize přidává bezpečnostní vrstvu bez výrazného zpomalení procesu. U nízkorizikových operací bývá schválení rychlé, protože návrh agenta je rozumný a nepotřebuje úpravy.
Testování middleware na vysoce rizikových scénářích: Odpověď s úpravou
Nyní si představme závažnější situaci, kde je úprava žádoucí. Agent dostane požadavek na odpověď na e-mail od startupového partnera, který žádá uživatele o schválení rozpočtu na $1 milion na Q1. To je vysoce rizikové rozhodnutí, které vyžaduje pečlivé zvážení. Agent může navrhnout e-mail typu: “Zkontroloval(a) jsem a schvaluji návrh rozpočtu $1 milion na Q1.”
Když tento návrh dorazí člověku přes middleware, ten si uvědomí, že jde o zásadní finanční závazek, který nelze schválit bez detailnějšího prověření. Člověk nechce celý nápad odpovídat zamítnout, ale chce být opatrnější. Proto zvolí odpověď s úpravou a změní tělo e-mailu například na: “Děkuji za návrh. Rád(a) bych si podrobněji prošel(a) detaily před schválením. Můžete mi zaslat rozpis využití rozpočtu?”
Takto vypadá odpověď s úpravou v kódu:
edit_decision = {
"type": "edit",
"edited_action": {
"name": "send_email",
"args": {
"recipient": "partner@startup.com",
"subject": "Návrh rozpočtu na Q1",
"body": "Děkuji za návrh. Rád(a) bych si podrobněji prošel(a) detaily před schválením. Můžete mi zaslat rozpis využití rozpočtu?" }
}
}
Po přijetí této odpovědi middleware spustí nástroj s upravenými parametry. E-mail se odešle s revidovaným obsahem, který je vhodnější pro finanční rozhodnutí. To ukazuje sílu úpravy — agent navrhuje, člověk doladí výstup podle svých znalostí a firemních standardů.
Testování middleware s odmítnutím a zpětnou vazbou
Odmítnutí je obzvlášť silné, protože nejen zastaví nevhodnou akci, ale poskytne agentovi zpětnou vazbu, která mu pomáhá se zlepšit. Představme si opět scénář s rozpočtem. Agent navrhne e-mail: “Zkontroloval(a) jsem a schvaluji rozpočet $1 milion na Q1.”
Člověk vidí, že takové schválení je ukvapené. Rozhodne se nejen úpravu, ale odmítnout celou cestu a požádat agenta o jiný přístup:
reject_decision = {
"type": "reject",
"message": "Tento rozpočet nemohu schválit bez dalších informací. Navrhni, prosím, e-mail s žádostí o detailní rozpis návrhu, včetně rozdělení prostředků mezi týmy a očekávaných výstupů."}
Middleware v tomto případě nástroj nespustí, ale odešle zamítavou zprávu zpět agentovi do kontextu konverzace. Agent vidí, že akce byla odmítnuta, a proč. Může tedy na základě zpětné vazby navrhnout jiný postup, například e-mail žádající o více detailů. Člověk může revidovaný návrh schválit, upravit, nebo opět odmítnout.
Tento iterativní proces — návrh, revize, odmítnutí se zpětnou vazbou, nový návrh — je jedním z největších přínosů human-in-the-loop middleware. Vzniká kolaborativní workflow, kde se kombinuje rychlost a uvažování agenta s lidským úsudkem a odborností.
Zrychlete své workflowy s FlowHunt
Vyzkoušejte, jak FlowHunt automatizuje vaše AI a SEO workflowy — od výzkumu a generování obsahu po publikaci a analytiku — vše na jednom místě.
Pokročilá konfigurace: Granulární řízení přerušení
Ačkoliv základní implementace human-in-the-loop middleware je jednoduchá, LangChain umožňuje pokročilou konfiguraci, kde můžete přesně určit, jak a kdy mají být přerušení spouštěna. Důležitou možností je určení, jaké typy rozhodnutí lze pro daný nástroj povolit. Například můžete povolit schválení a úpravu pro e-maily, ale ne zamítnutí, nebo povolit všechny tři typy pro finanční transakce, ale jen schválení pro čtení z databáze.
Příklad pokročilé konfigurace:
from langchain.agents.middleware import HumanInTheLoopMiddleware
agent = create_agent(
model=model,
tools=tools,
middleware=[
HumanInTheLoopMiddleware(
interrupt_on={
"send_email": {
"allowed_decisions": ["approve", "edit", "reject"]
},
"read_database": False, # Automatické schválení, bez přerušení"delete_record": {
"allowed_decisions": ["approve", "reject"] # Mazání bez možnosti úpravy }
}
)
]
)
V tomto nastavení e-maily vyžadují přerušení a umožňují všechny tři typy rozhodnutí. Čtecí operace se provedou automaticky bez přerušení. Mazání bude přerušeno, ale nepůjde upravit — člověk může pouze schválit nebo zamítnout. Tato granulární kontrola umožňuje přidat dohled tam, kde je skutečně potřeba, a vyhnout se průtahům u nízkorizikových operací.
Další pokročilou funkcí je možnost přidat vlastní popis přerušení. Ve výchozím stavu middleware poskytuje obecný popis typu “Spuštění nástroje vyžaduje schválení.” Můžete jej upravit pro konkrétní kontext:
HumanInTheLoopMiddleware(
interrupt_on={
"send_email": {
"allowed_decisions": ["approve", "edit", "reject"],
"description": "Odeslání e-mailu vyžaduje lidské schválení před provedením" }
}
)
Důležité implementační aspekty: Checkpointery a správa stavu
Klíčovým aspektem implementace human-in-the-loop middleware, na který se snadno zapomíná, je potřeba checkpointeru. Checkpointer je mechanismus, který ukládá stav agenta v okamžiku přerušení, aby bylo možné workflow později obnovit. Je to zásadní, protože lidská revize nebývá okamžitá — může dojít ke zpoždění mezi přerušením a rozhodnutím člověka. Bez checkpointeru by se stav agenta během čekání ztratil a workflow by nešlo správně obnovit.
LangChain nabízí několik možností checkpointeru. Pro vývoj a testování lze použít in-memory checkpointer:
V produkci obvykle použijete perzistentní checkpointer ukládající stav do databáze či souboru, abyste zvládli obnovu i po restartu aplikace. Checkpointer udržuje kompletní záznam o stavu agenta v každém kroku, včetně historie konverzace, provedených volání nástrojů i jejich výsledků. Když člověk rozhodne (schválit, upravit, zamítnout), middleware použije checkpointer k načtení uloženého stavu, aplikaci rozhodnutí a obnovení agentní smyčky od tohoto bodu.
Reálné aplikace a použití
Human-in-the-loop middleware najde uplatnění v celé řadě situací, kde autonomní agenti vykonávají akce, které však vyžadují lidský dohled. Ve finančních službách mohou agenti zpracovávat transakce, schvalovat půjčky nebo spravovat investice s garancí lidské revize u klíčových rozhodnutí. Ve zdravotnictví mohou agenti doporučovat léčbu nebo přistupovat k záznamům pacientů s ohledem na regulace a klinické postupy. V právních službách agenti připravující komunikaci či přístup ke klientským dokumentům zajistí zachování advokátního dohledu. V zákaznickém servisu agenti vydávající refundace, činící závazky nebo eskalující případy zaručí, že akce odpovídají firemním pravidlům.
Kromě těchto oborových aplikací je middleware cenný všude tam, kde chyba agenta může mít vážné následky. Patří sem moderace obsahu (odstraňování příspěvků uživatelů), HR systémy (zpracování rozhodnutí o zaměstnání), nebo řízení dodavatelského řetězce (objednávky, úpravy zásob). Společným jmenovatelem je, že návrhy agenta mají reálný dopad, který je natolik významný, že si zaslouží lidskou kontrolu před provedením.
Porovnání s alternativními přístupy
Stojí za to zvážit, jak si human-in-the-loop middleware stojí ve srovnání s jinými způsoby začlenění lidského dohledu. Jednou možností je revize všech výstupů agenta až po provedení, ale zde je problém, že akce už je nevratně provedena — e-mail již odešel, záznam byl smazán, transakce dokončena. Human-in-the-loop middleware tomuto zabrání.
Další možností je nechat všechny úkony vykonávat ručně člověka, což však popírá smysl agentů — jejich hodnota je v efektivitě a uvolnění lidské kapacity pro strategická rozhodnutí. Smyslem middleware je najít rovnováhu: agent zvládne rutinu, člověk kontroluje vše důležité.
Třetí možností je implementace ochranných pravidel (guardrails), která agentům zamezí v chybných akcích. Například zakázat odesílání e-mailů mimo firmu nebo mazání záznamů bez potvrzení. Guardrails jsou užitečné a měly by být použity spolu s middleware, ale mají limity — jsou pravidlové a nemohou pokrýt všechny kontexty. Lidský úsudek je flexibilnější, což zvyšuje hodnotu human-in-the-loop middleware.
Osvědčené postupy pro zavádění human-in-the-loop workflowů
Při implementaci human-in-the-loop middleware v aplikacích dodržujte několik zásad pro efektivitu. Za prvé, strategicky vybírejte, které nástroje vyžadují přerušení — přerušovat každé volání by workflow brzdilo. Zaměřte se na drahé, rizikové nebo těžko vratné operace. Čtení obvykle přerušení nevyžaduje, zápisy a externí akce ano.
Za druhé, poskytujte jasný kontext revizorům. Při přerušení musí člověk vidět, co agent navrhuje a proč. Zajistěte, aby popisy přerušení byly srozumitelné a obsahovaly relevantní informace (například celý návrh e-mailu, detaily mazání záznamu atd.). Čím lepší kontext, tím rychlejší a přesnější rozhodnutí.
Za třetí, udělejte schvalovací proces co nejpohodlnější. Lidé schvalují rychleji, pokud je proces jednoduchý a nevyžaduje zbytečné klikání či vyplňování. Nabídněte jasné volby (schválit, upravit, zamítnout). Pokud je povolena úprava, umožněte ji jednoduše bez nutnosti znalosti kódu.
Za čtvrté, využívejte odmítavé zpětné vazby strategicky. Při zamítnutí návrhu dejte agentovi jasný důvod a návod, co má udělat jinak. Taková zpětná vazba agenta časem zlepšuje, protože se učí z konkrétních situací a požadavků organizace.
Za páté, sledujte a analyzujte vzory přerušení. Sledujte, které nástroje jsou nejčastěji přerušovány, jaká rozhodnutí (schválení, úprava, zamítnutí) převládají a jak dlouho schvalování trvá. Tato data vám pomohou odstranit úzká hrdla, vyladit konfiguraci přerušení a případně vylepšit promptování nebo logiku výběru nástrojů.
Propojení human-in-the-loop middleware s FlowHunt
Organizacím, které chtějí zavést human-in-the-loop workflowy ve větším měřítku, nabízí FlowHunt komplexní platformu s přímou integrací do middleware LangChainu. FlowHunt umožňuje stavět, nasazovat a spravovat AI agenty s vestavěnými schvalovacími workflowy, takže snadno přidáte lidský dohled do svých automatizačních procesů. Můžete si nastavit, které nástroje vyžadují schválení, uzpůsobit schvalovací rozhraní i sledovat všechny schválení a zamítnutí pro účely compliance a auditu. Platforma řeší složitost správy stavu, checkpointování a orchestraci workflowu, takže se můžete soustředit na efektivní agenty a správné schvalovací politiky. Díky integraci s LangChainem využijete naplno sílu human-in-the-loop middleware a zároveň pohodlné rozhraní a podnikové vlastnosti FlowHunt.
Závěr
Human-in-the-loop middleware představuje zásadní most mezi efektivitou autonomních AI agentů a nutností lidského dohledu v produkčních systémech. Díky schvalovacím workflowům, možnostem úprav i zamítání a zpětné vazbě můžete vytvářet agenty, kteří jsou nejen výkonnější, ale především bezpečnější. Třícestný model rozhodování — schválit, upravit, zamítnout — nabízí flexibilitu, jak zvl
Často kladené otázky
Human-in-the-loop middleware je komponenta, která pozastaví provedení AI agenta před spuštěním určitých nástrojů a umožní člověku navrhovanou akci schválit, upravit nebo zamítnout. Přidává tak bezpečnostní vrstvu pro nákladné či rizikové operace.
Použijte ho pro operace s vysokým rizikem, například odesílání e-mailů, finanční transakce, zápis do databáze nebo jakékoli spuštění nástroje, které vyžaduje dozor z hlediska souladu nebo může mít významné důsledky při nesprávném provedení.
Tři hlavní typy odpovědí jsou: Schválení (provedení nástroje tak, jak bylo navrženo), Úprava (změna parametrů nástroje před spuštěním) a Zamítnutí (odmítnutí provedení a zaslání zpětné vazby modelu k přepracování).
Importujte HumanInTheLoopMiddleware z langchain.agents.middleware, nakonfigurujte ho s nástroji, které chcete přerušovat, a předávejte ho do funkce pro vytvoření agenta. Budete také potřebovat checkpointer pro udržení stavu během přerušení.
Arshia je inženýr AI pracovních postupů ve FlowHunt. Sxa0vzděláním vxa0oboru informatiky a vášní pro umělou inteligenci se specializuje na vytváření efektivních workflow, které integrují AI nástroje do každodenních úkolů a zvyšují tak produktivitu i kreativitu.
Arshia Kahani
Inženýr AI pracovních postupů
Automatizujte své AI workflowy bezpečně s FlowHunt
Vytvářejte inteligentní agenty s vestavěnými schvalovacími workflowy a lidským dohledem. FlowHunt vám usnadní zavedení human-in-the-loop automatizace do vašich firemních procesů.
Budování rozšiřitelných AI agentů: Hloubkový pohled na middleware architekturu
Zjistěte, jak middleware architektura v LangChain 1.0 revolučně mění vývoj agentů a umožňuje vývojářům stavět výkonné, rozšiřitelné deep agenty s plánováním, so...
Human-in-the-Loop (HITL) je přístup v AI a strojovém učení, který zapojuje lidskou odbornost do trénování, ladění a aplikace AI systémů, čímž zvyšuje přesnost, ...
Integrujte FlowHunt s ForeverVM MCP Serverem pro dynamické vytváření Python REPL, bezpečné spouštění kódu a automatizovanou správu relací pro AI poháněné SaaS a...
3 min čtení
AI
ForeverVM
+4
Souhlas s cookies Používáme cookies ke zlepšení vašeho prohlížení a analýze naší návštěvnosti. See our privacy policy.