Wan 2.1: Open-source revoluce v generování AI videa
Wan 2.1 je výkonný open-source model AI pro generování videa od Alibaby, který vytváří studiová videa z textu nebo obrázků a je zdarma pro každého k použití na vlastním zařízení.
AI Video Generation
Open Source
Wan 2.1
Alibaba
Generative AI
Video AI
AI Tools
Wan 2.1 (známý také jako WanX 2.1) je průlomový plně open-source model pro generování AI videa, vyvinutý v laboratoři Tongyi Lab společnosti Alibaba. Na rozdíl od mnoha proprietárních systémů pro generování videa, které vyžadují drahé předplatné nebo API přístup, Wan 2.1 nabízí srovnatelnou či lepší kvalitu a zároveň je zcela zdarma a dostupný vývojářům, výzkumníkům i kreativním profesionálům.
Co dělá Wan 2.1 skutečně výjimečným, je kombinace dostupnosti a výkonu. Menší varianta T2V-1.3B vyžaduje jen přibližně 8,2 GB paměti GPU, což ji činí kompatibilní s většinou moderních spotřebitelských GPU. Větší verze s 14 miliardami parametrů nabízí špičkový výkon, který překonává jak open-source alternativy, tak i mnohé komerční modely v běžných benchmarcích.
Klíčové vlastnosti, které Wan 2.1 odlišují
Podpora multitaskingu
Wan 2.1 není omezen jen na generování videa z textu. Jeho všestranná architektura podporuje:
Text-na-video (T2V)
Obrázek-na-video (I2V)
Editaci video-na-video
Generování obrázku z textu
Generování audia z videa
Díky této flexibilitě můžete začít s textovým zadáním, statickým obrázkem nebo dokonce s existujícím videem a proměnit je podle své kreativní vize.
Vícejazyčné generování textu
Jako první video model, který dokáže vygenerovat čitelný anglický i čínský text přímo ve videích, otevírá Wan 2.1 nové možnosti pro mezinárodní tvůrce obsahu. Tato funkce je zvlášť cenná pro titulky nebo scénický text ve vícejazyčných videích.
Revoluční Video VAE (Wan-VAE)
Srdcem efektivity Wan 2.1 je jeho 3D kauzální Video Variational Autoencoder. Tento technologický průlom efektivně komprimuje prostorově-časové informace a umožňuje modelu:
Komprimovat videa až stonásobně
Zachovávat pohyb a detailní věrnost
Podporovat výstupy ve vysokém rozlišení až 1080p
Výjimečná efektivita a dostupnost
Menší model o velikosti 1.3B vyžaduje pouze 8,19 GB VRAM a zvládne vytvořit 5sekundové video v rozlišení 480p přibližně za 4 minuty na RTX 4090. Přestože je tak efektivní, jeho kvalita se vyrovná či překonává mnohem větší modely, což je perfektní vyvážení rychlosti a vizuální kvality.
Špičkové benchmarky & kvalita
V veřejných srovnáních získal Wan 14B nejvyšší celkové skóre v testu Wan-Bench a překonal konkurenty v oblastech:
Kvalita pohybu
Stabilita
Přesnost dodržení zadání
Připraveni rozšířit své podnikání?
Začněte svou bezplatnou zkušební verzi ještě dnes a viďte výsledky během několika dní.
Jak si Wan 2.1 stojí vůči ostatním modelům pro generování videa
Na rozdíl od uzavřených systémů, jako je Sora od OpenAI nebo Gen-2 od Runway, je Wan 2.1 zdarma a lze jej provozovat lokálně. Obecně překonává starší open-source modely (jako CogVideo, MAKE-A-VIDEO a Pika) a v kvalitativních testech se vyrovná či překonává i mnohá komerční řešení.
Nedávný průzkum v oboru uvedl, že „mezi mnoha AI video modely vynikají Wan 2.1 a Sora“ – Wan 2.1 pro svou otevřenost a efektivitu, Sora pro proprietární inovace. Ve srovnáních komunity uživatelé uvádějí, že schopnost Wan 2.1 převádět obrázky na video předčí konkurenci v ostrosti a filmovém dojmu.
Technologie za Wan 2.1
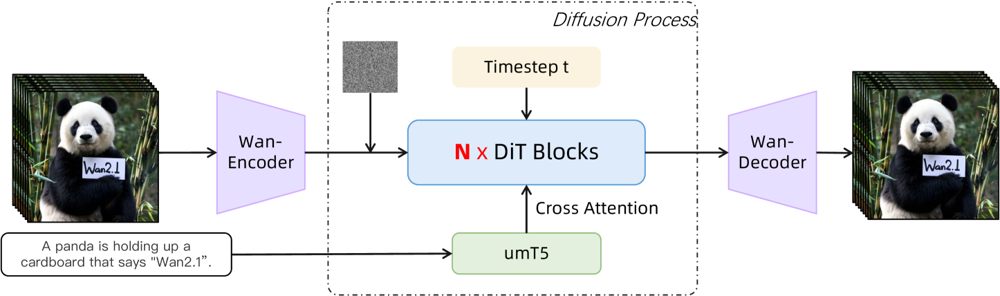
Wan 2.1 staví na páteři diffusion-transformer s inovativním prostorově-časovým VAE. Jak to funguje:
Vstup (text a/nebo obrázek/video) je zakódován do latentní video reprezentace pomocí Wan-VAE
Diffuzní transformer (na bázi architektury DiT) tuto latentní reprezentaci opakovaně denoizuje
Proces je řízen textovým enkodérem (vícejazyčná varianta T5 zvaná umT5)
Nakonec dekodér Wan-VAE rekonstruuje výstupní video snímky
Obrázek: Vysoce úrovňová architektura Wan 2.1 (případ text-na-video). Video (nebo obrázek) je nejprve zakódováno Wan-VAE enkodérem do latentního prostoru. Ten je pak předán přes N bloků diffusion transformeru, které využívají textové vektory (z umT5) přes cross-attention. Nakonec Wan-VAE dekodér zrekonstruuje video snímky. Toto řešení – „3D kauzální VAE enkodér/dekodér obklopující diffusion transformer“ (ar5iv.org
) – umožňuje efektivní kompresi prostorově-časových dat a podporuje kvalitní video výstupy.
Tato inovativní architektura – „3D kauzální VAE enkodér/dekodér obklopující diffusion transformer“ – umožňuje efektivní kompresi prostorově-časových dat a podporuje kvalitní video výstupy.
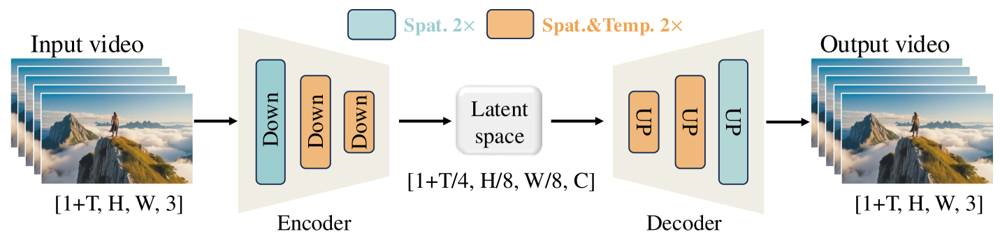
Wan-VAE je speciálně navržen pro video. Komprimuje vstup o působivé faktory (časově 4× a prostorově 8×) do kompaktního latentu, který je následně dekódován zpět do plného videa. Využití 3D konvolucí a kauzálních (časově zachovávajících) vrstev zajišťuje soudržný pohyb v celém generovaném obsahu.
Obrázek: Framework Wan-VAE ve Wan 2.1 (enkodér-dekodér). Wan-VAE enkodér (vlevo) aplikuje řadu vrstev pro zmenšení (“Down”) na vstupní video (tvar [1+T, H, W, 3] snímků) až do kompaktního latentu ([1+T/4, H/8, W/8, C]). Wan-VAE dekodér (vpravo) pak tento latent symetricky rozšiřuje (“UP”) zpět do původního videa. Modré bloky znamenají prostorovou kompresi, oranžové kombinovanou prostorovou a časovou kompresi (ar5iv.org
). Díky kompresi videa 256× (v prostorově-časovém objemu) umožňuje Wan-VAE zvládnutí vysoce kvalitního videa pro následný diffusion model.
Přihlaste se k odběru newsletteru
Získejte nejnovější tipy, trendy a nabídky zdarma.
Jak spustit Wan 2.1 na vlastním počítači
Chcete si Wan 2.1 vyzkoušet sami? Takto začnete:
Systémové požadavky
Python 3.8+
PyTorch ≥2.4.0 s podporou CUDA
NVIDIA GPU (8GB+ VRAM pro model 1.3B, 16–24GB pro modely 14B)
Další knihovny z repozitáře
Postup instalace
Naklonujte repozitář a nainstalujte závislosti:
git clone https://github.com/Wan-Video/Wan2.1.git
cd Wan2.1
pip install -r requirements.txt
python generate.py --task t2v-14B --size 1280*720 \
--ckpt_dir ./Wan2.1-T2V-14B \
--prompt "Futuristická městská silueta při západu slunce, nad hlavou létají auta."
Tipy pro výkon
Pro počítače s omezenou pamětí GPU zkuste lehčí model t2v-1.3B
Použijte parametry --offload_model True --t5_cpu pro přesunutí části modelu na CPU
Poměr stran nastavíte pomocí parametru --size (např. 832*480 pro 16:9 480p)
Wan 2.1 nabízí rozšíření promptů a “inspiration mode” přes další volby
Pro představu: RTX 4090 zvládne vygenerovat 5sekundové video v 480p asi za 4 minuty. Pro rozsáhlé použití je podporováno více GPU i další optimalizace výkonu (FSDP, kvantizace atd.).
Proč je Wan 2.1 důležitý pro budoucnost AI videa
Jako open-source tahoun, který vyzývá giganty v generování AI videa, představuje Wan 2.1 zásadní posun v dostupnosti. Díky své otevřenosti a bezplatnosti může kdokoliv s dobrým GPU zkoumat špičkové generování videa bez poplatků za předplatné nebo API.
Pro vývojáře open-source licence umožňuje model upravovat a vylepšovat. Výzkumníci mohou rozšiřovat jeho schopnosti a kreativci rychle a efektivně prototypovat video obsah.
V době, kdy jsou proprietární AI modely stále častěji uzamčeny za platebními zdmi, Wan 2.1 dokazuje, že špičkový výkon lze demokratizovat a sdílet se širokou komunitou.
Často kladené otázky
Co je Wan 2.1?
Wan 2.1 je plně open-source model pro generování AI videa vyvinutý v laboratoři Tongyi Lab společnosti Alibaba, schopný vytvářet vysoce kvalitní videa z textových zadání, obrázků nebo existujících videí. Je zdarma k použití, podporuje více úloh a běží efektivně na běžných GPU.
Jaké vlastnosti dělají Wan 2.1 výjimečným?
Wan 2.1 podporuje multitasking při generování videa (text-na-video, obrázek-na-video, úpravy videa apod.), vícejazyčný text ve videích, vysokou efektivitu díky 3D kauzální Video VAE a překonává mnoho komerčních i open-source modelů v benchmarcích.
Jak mohu spustit Wan 2.1 na vlastním počítači?
Potřebujete Python 3.8+, PyTorch 2.4.0+ s CUDA a NVIDIA GPU (8GB+ VRAM pro menší model, 16-24GB pro velký model). Naklonujte GitHub repozitář, nainstalujte závislosti, stáhněte váhy modelu a použijte přiložené skripty pro generování videí lokálně.
Proč je Wan 2.1 důležitý pro AI generování videa?
Wan 2.1 demokratizuje přístup k nejmodernějšímu generování videa tím, že je open-source a zdarma, takže vývojáři, výzkumníci i kreativci mohou experimentovat a inovovat bez platebních zdí či proprietárních omezení.
Jak si Wan 2.1 stojí ve srovnání s modely jako Sora nebo Runway Gen-2?
Na rozdíl od uzavřených alternativ jako Sora nebo Runway Gen-2 je Wan 2.1 zcela open-source a lze ho spustit lokálně. Obecně překonává předchozí open-source modely a v kvalitativních testech se vyrovná či překonává i mnohá komerční řešení.
Arshia je inženýr AI pracovních postupů ve FlowHunt. Sxa0vzděláním vxa0oboru informatiky a vášní pro umělou inteligenci se specializuje na vytváření efektivních workflow, které integrují AI nástroje do každodenních úkolů a zvyšují tak produktivitu i kreativitu.
Arshia Kahani
Inženýr AI pracovních postupů
Vyzkoušejte FlowHunt a tvořte AI řešení
Začněte tvořit své AI nástroje a pracovní toky pro generování videa s FlowHunt nebo si domluvte demo a uvidíte platformu v akci.
Jak proměnit tvorbu obsahu pomocí generování videí Wan 2.2 & 2.5?
FlowHunt nyní podporuje generování videí modely Wan 2.2 a 2.5 pro převod textu na video, obrázku na video, nahrazení persony a animaci. Proměňte svou tvorbu obs...
Google Gemini 2.5 Flash: Revoluce v generování AI obrázků
Objevte, jak model Gemini 2.5 Flash od Googlu mění kreativní odvětví díky pokročilé úpravě obrázků, 3D extrakci, obnově fotografií a AI-vizuálním návrhům, které...
Říjen 2025: Výkonné nové video & obrazové AI modely
Říjnový update FlowHunt 2025 přináší revoluční modely Wan 2.2 a 2.5 pro generování videí z textu, obrázků i animací, pokročilé možnosti generování a úprav obráz...
4 min čtení
AI
Video Generation
+7
Souhlas s cookies Používáme cookies ke zlepšení vašeho prohlížení a analýze naší návštěvnosti. See our privacy policy.