Jak testovat AI chatbot
Poznejte komplexní strategie testování AI chatbotů včetně funkčního, výkonnostního, bezpečnostního a uživatelského testování. Objevte osvědčené postupy, nástroj...
10 min čtení
Naučte se komplexní metody měření přesnosti AI helpdesk chatbota v roce 2025. Objevte precision, recall, F1 skóre, metriky spokojenosti uživatelů a pokročilé hodnotící techniky s FlowHunt.
Přesnost AI helpdesk chatbota měřte pomocí více metrik včetně výpočtů precision a recall, konfuzní matice, skóre spokojenosti uživatelů, míry vyřešení dotazů a pokročilých metod hodnocení založených na LLM. FlowHunt poskytuje komplexní nástroje pro automatizované hodnocení přesnosti a sledování výkonu.
Měření přesnosti AI helpdesk chatbota je zásadní k zajištění spolehlivých a užitečných odpovědí na dotazy zákazníků. Na rozdíl od jednoduchých klasifikačních úloh zahrnuje přesnost chatbota více rozměrů, které je třeba hodnotit společně, abyste získali úplný obrázek o výkonu. Tento proces zahrnuje analýzu toho, jak dobře chatbot rozumí uživatelským dotazům, poskytuje správné informace, efektivně řeší problémy a udržuje spokojenost uživatelů po celou dobu interakce. Komplexní strategie měření přesnosti kombinuje kvantitativní metriky s kvalitativní zpětnou vazbou, aby identifikovala silné stránky i oblasti vyžadující zlepšení.
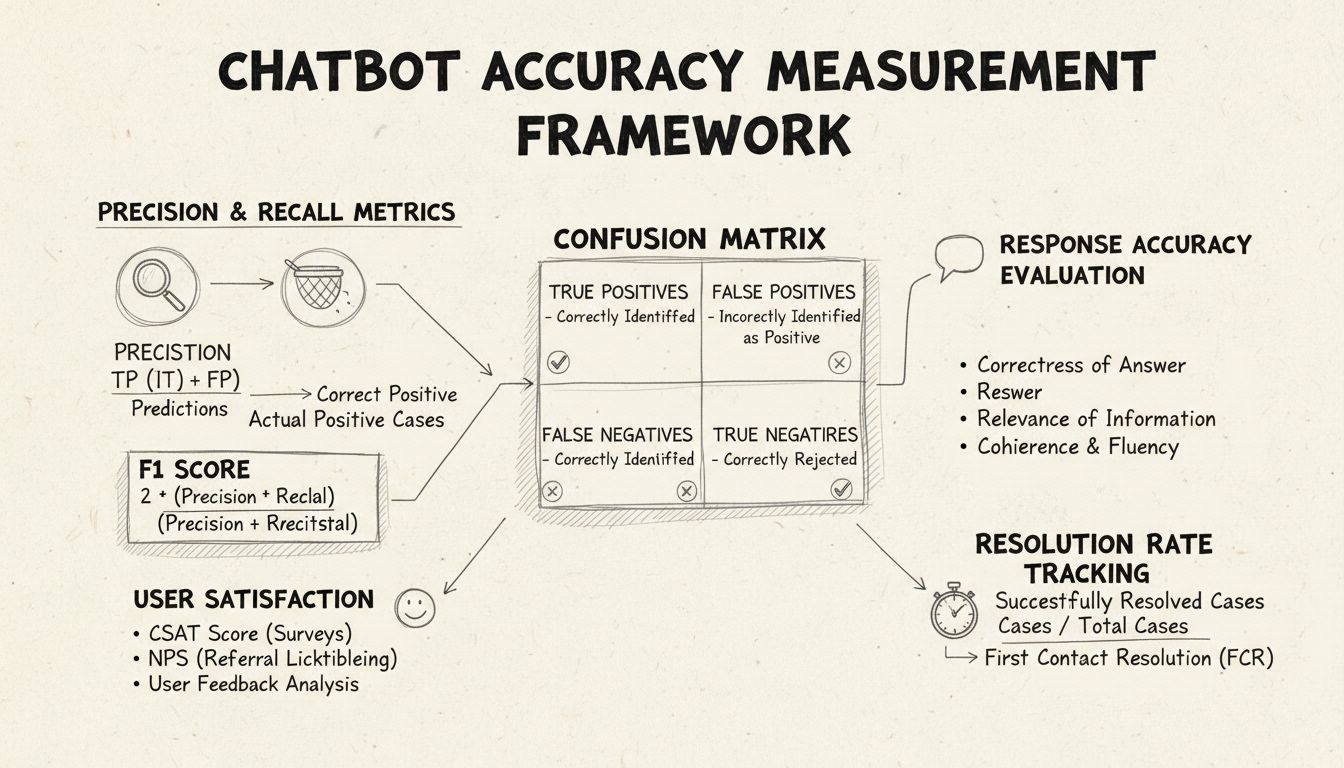
Precision a recall jsou základní metriky odvozené z konfuzní matice, které měří různé aspekty výkonu chatbota. Precision představuje podíl správných odpovědí ze všech odpovědí, které chatbot poskytl. Výpočet: Precision = True Positives / (True Positives + False Positives). Tato metrika odpovídá na otázku: “Když chatbot poskytne odpověď, jak často je správná?” Vysoké skóre precision znamená, že chatbot jen zřídka dává nesprávné informace, což je klíčové pro zachování důvěry uživatelů v helpdesk scénářích.
Recall, také nazývaný senzitivita, měří podíl správných odpovědí ze všech správných odpovědí, které měl chatbot poskytnout. Výpočet: Recall = True Positives / (True Positives + False Negatives). Tato metrika řeší, zda chatbot úspěšně identifikuje a reaguje na všechny legitimní zákaznické požadavky. V prostředí helpdesku vysoký recall zajistí, že zákazníci dostanou pomoc s jejich problémy, místo aby jim bylo řečeno, že chatbot nemůže pomoci, i když by mohl. Vztah mezi precision a recall vytváří přirozený kompromis: optimalizace jedné často snižuje druhou, což vyžaduje pečlivou rovnováhu dle konkrétních obchodních priorit.
F1 skóre poskytuje jedinou metriku, která vyvažuje precision i recall, vypočítanou jako harmonický průměr: F1 = 2 × (Precision × Recall) / (Precision + Recall). Tato metrika je zvláště cenná, když potřebujete sjednocený indikátor výkonu nebo při práci s nevyváženými daty, kde jedna třída významně převyšuje ostatní. Například pokud váš chatbot zpracovává 1 000 rutinních dotazů, ale jen 50 složitých eskalací, F1 skóre zabrání zkreslení metriky většinovou třídou. F1 skóre se pohybuje od 0 do 1, přičemž 1 znamená dokonalou precision i recall, což je pro zainteresované strany intuitivní ukazatel celkového výkonu chatbota.
Konfuzní matice je základní nástroj, který rozděluje výkon chatbota do čtyř kategorií: True Positives (správné odpovědi na platné dotazy), True Negatives (správné odmítnutí odpovědi na nerelevantní dotazy), False Positives (nesprávné odpovědi) a False Negatives (zmeškané příležitosti pomoci). Tato matice odhaluje konkrétní vzorce selhání chatbota, což umožňuje cílená zlepšení. Například pokud matice ukazuje vysoký počet false negatives u dotazů na fakturaci, můžete zjistit, že tréninková data chatbota postrádají dostatek příkladů z oblasti fakturace a je nutné je rozšířit.
| Metrika | Definice | Výpočet | Dopad na podnikání |
|---|---|---|---|
| True Positives (TP) | Správné odpovědi na platné dotazy | Přímé počítání | Posiluje důvěru zákazníků |
| True Negatives (TN) | Správné odmítnutí nerelevantních dotazů | Přímé počítání | Zabraňuje dezinformacím |
| False Positives (FP) | Nesprávné odpovědi | Přímé počítání | Poškozuje důvěryhodnost |
| False Negatives (FN) | Zmeškané příležitosti pomoci | Přímé počítání | Snižuje spokojenost |
| Precision | Kvalita pozitivních předpovědí | TP / (TP + FP) | Metrika spolehlivosti |
| Recall | Pokrytí skutečných pozitiv | TP / (TP + FN) | Metrika úplnosti |
| Accuracy | Celková správnost | (TP + TN) / Celkem | Obecný výkon |
Přesnost odpovědi měří, jak často chatbot poskytuje fakticky správné informace, které přímo odpovídají na uživatelský dotaz. Nejde jen o shodu vzorců, ale o zhodnocení, zda je obsah přesný, aktuální a vhodný pro daný kontext. Manuální kontrola zahrnuje lidské hodnotitele, kteří posuzují náhodný vzorek konverzací a porovnávají odpovědi chatbota s předdefinovanou znalostní bází správných odpovědí. Automatizované metody porovnání lze implementovat pomocí technik zpracování přirozeného jazyka, které porovnávají odpovědi s očekávanými uloženými odpověďmi ve vašem systému, ovšem tyto metody vyžadují pečlivé nastavení, aby nedocházelo k falešným negativním výsledkům, když chatbot poskytne správnou informaci jinými slovy než referenční odpověď.
Relevance odpovědi hodnotí, zda odpověď chatbota skutečně řeší, na co se uživatel ptal, i když odpověď není zcela správná. Tento rozměr zachycuje situace, kdy chatbot poskytne užitečné informace, které sice nejsou přesnou odpovědí, ale posunou konverzaci směrem k řešení. NLP metody jako kosinová podobnost mohou měřit sémantickou podobnost mezi uživatelskou otázkou a odpovědí chatbota a poskytovat automatizované skóre relevance. Mechanismy zpětné vazby od uživatelů, například hodnocení palcem nahoru/dolů po každé interakci, přinášejí přímé hodnocení relevance od těch nejdůležitějších – vašich zákazníků. Tyto signály zpětné vazby je třeba průběžně sbírat a analyzovat, abyste identifikovali vzory v typech dotazů, které chatbot zvládá dobře versus špatně.
Skóre spokojenosti zákazníka (CSAT) měří spokojenost uživatele s interakcí s chatbotem prostřednictvím přímých dotazníků, většinou na škále 1-5 nebo jednoduchým hodnocením spokojenosti. Po každé interakci jsou uživatelé požádáni, aby ohodnotili svou spokojenost, což poskytuje okamžitou zpětnou vazbu, zda chatbot splnil jejich potřeby. CSAT skóre nad 80 % obvykle znamená silný výkon, skóre pod 60 % signalizuje závažné problémy vyžadující prošetření. Výhodou CSAT je jednoduchost a přímost – uživatelé jasně sdělují, zda jsou spokojeni, ale skóre může být ovlivněno i jinými faktory, například složitostí problému nebo očekáváními uživatelů.
Net Promoter Score měří pravděpodobnost, s jakou uživatelé doporučí chatbota ostatním, vypočítanou na základě otázky „Jak byste doporučili tohoto chatbota kolegovi?“ na škále 0-10. Odpovědi 9-10 jsou promotéři, 7-8 pasivní uživatelé a 0-6 jsou kritici. NPS = (Promotéři - Kritici) / Celkový počet respondentů × 100. Tato metrika silně koreluje s dlouhodobou loajalitou zákazníků a poskytuje vhled, zda chatbot vytváří pozitivní zkušenosti, které chtějí uživatelé sdílet. NPS nad 50 je považován za vynikající, záporné NPS značí vážné problémy s výkonem.
Analýza sentimentu zkoumá emocionální tón uživatelských zpráv před a po interakci s chatbotem, aby bylo možné posoudit spokojenost. Pokročilé NLP techniky třídí zprávy na pozitivní, neutrální nebo negativní a ukazují, zda jsou uživatelé v průběhu konverzace více spokojeni, nebo naopak frustrováni. Pozitivní posun sentimentu znamená, že chatbot úspěšně vyřešil obavy, negativní posun naznačuje, že chatbot uživatele frustroval nebo nesplnil jejich potřeby. Tato metrika zachycuje emocionální rozměry, které tradiční metriky přesnosti často opomíjejí, a poskytuje cenný kontext pro pochopení kvality uživatelské zkušenosti.
First Contact Resolution měří procento zákaznických požadavků, které chatbot vyřeší bez nutnosti předání lidskému agentovi. Tato metrika má přímý dopad na efektivitu provozu i spokojenost zákazníků, protože ti dávají přednost okamžitému řešení problémů před přepojením. FCR nad 70 % znamená silný výkon chatbota, zatímco pod 50 % signalizuje, že chatbot postrádá dostatečné znalosti nebo schopnosti pro řešení běžných dotazů. Sledování FCR podle kategorií problémů ukazuje, které typy dotazů chatbot zvládá dobře a které vyžadují lidský zásah, což napomáhá zlepšování tréninku a znalostní báze.
Míra eskalace měří, jak často chatbot předává konverzace lidským agentům, zatímco frekvence fallbacku sleduje, jak často chatbot použije obecné odpovědi typu “Nerozumím” nebo “Prosím, přeformulujte svůj dotaz”. Vysoká míra eskalace (nad 30 %) ukazuje, že chatbot postrádá znalosti nebo jistotu v mnoha scénářích, častý fallback pak značí špatné rozpoznávání záměru nebo nedostatečná tréninková data. Tyto metriky odhalují konkrétní mezery ve schopnostech chatbota, které lze řešit rozšířením znalostní báze, přeškolením modelu či vylepšením komponent pro rozpoznávání přirozeného jazyka.
Doba odpovědi měří, jak rychle chatbot reaguje na uživatelské zprávy, obvykle v milisekundách až sekundách. Uživatelé očekávají téměř okamžité reakce; zpoždění nad 3–5 sekund významně snižuje spokojenost. Doba vyřízení měří celkový čas od zahájení kontaktu uživatelem až po vyřešení problému nebo jeho eskalaci, což poskytuje přehled o efektivitě chatbota. Kratší doby vyřízení znamenají, že chatbot rychle chápe a řeší dotazy, delší časy ukazují, že chatbot potřebuje víc upřesnění nebo má potíže se složitými dotazy. Tyto metriky je vhodné sledovat zvlášť podle kategorií problémů, protože složitější technické dotazy přirozeně vyžadují delší zpracování než jednoduché FAQ.
LLM As a Judge představuje sofistikovaný přístup, kdy jeden velký jazykový model hodnotí kvalitu výstupů jiného AI systému. Tato metodika je zvláště účinná pro hodnocení odpovědí chatbota napříč více kvalitativními rozměry současně, například přesnost, relevance, koherence, plynulost, bezpečnost, úplnost a tón. Výzkumy ukazují, že hodnotitelé LLM mohou dosáhnout až 85% shody s lidským hodnocením, což z nich činí škálovatelnou alternativu k ručním kontrolám. Přístup zahrnuje definování konkrétních hodnotících kritérií, vytvoření detailních hodnotících promptů s příklady, poskytnutí hodnotiteli jak původního uživatelského dotazu, tak odpovědi chatbota, a získání strukturovaných skóre nebo podrobné zpětné vazby.
Proces LLM As a Judge obvykle využívá dva hodnotící přístupy: hodnocení jednotlivého výstupu (single output evaluation), kdy hodnotitel skóruje jednotlivou odpověď buď bez referenční odpovědi (referenceless evaluation), nebo s porovnáním vůči očekávané odpovědi (reference-based comparison), a párové porovnání (pairwise comparison), kdy hodnotitel porovnává dva výstupy a určí lepší. Tato flexibilita umožňuje hodnotit jak absolutní výkon, tak relativní zlepšení při testování různých verzí nebo konfigurací chatbota. Platforma FlowHunt podporuje implementace LLM As a Judge prostřednictvím vizuálního rozhraní, integrace s předními LLM jako ChatGPT a Claude, a CLI nástrojů pro pokročilé reportování a automatizované hodnocení.
Nad rámec základních výpočtů přesnosti odhaluje detailní analýza konfuzní matice konkrétní vzorce chyb chatbota. Zkoumáním, jaké typy dotazů vedou k false positives versus false negatives, lze identifikovat systematické slabiny. Například pokud matice ukazuje, že chatbot často zaměňuje dotazy na fakturaci za technickou podporu, jde o nerovnováhu v tréninkových datech nebo problém s rozpoznáváním záměru v dané oblasti. Vytvoření samostatných konfuzních matic pro různé kategorie problémů umožňuje cílená zlepšení místo obecného přeškolení modelu.
A/B testování porovnává různé verze chatbota a určuje, která dosahuje lepších výsledků na klíčových metrikách. Může jít o testování různých odpovědních šablon, konfigurací znalostní báze nebo použitých jazykových modelů. Náhodným směrováním části provozu na každou verzi a porovnáním metrik, jako je FCR, CSAT či přesnost odpovědí, lze činit datově podložená rozhodnutí o implementaci vylepšení. A/B testování by mělo běžet dostatečně dlouho, aby zachytilo přirozenou variabilitu uživatelských dotazů a zajistilo statistickou významnost výsledků.
FlowHunt poskytuje integrovanou platformu pro stavbu, nasazení a hodnocení AI helpdesk chatbotů s pokročilými možnostmi měření přesnosti. Vizuální builder platformy umožňuje i netechnickým uživatelům vytvářet sofistikované chatbotové toky, zatímco AI komponenty se integrují s předními jazykovými modely jako ChatGPT a Claude. Nástroje pro hodnocení ve FlowHunt podporují implementaci metodiky LLM As a Judge, takže můžete definovat vlastní hodnotící kritéria a automaticky hodnotit výkon chatbota napříč celou konverzační databází.
Pro zavedení komplexního měření přesnosti s FlowHunt začněte definováním vašich hodnotících kritérií v souladu s obchodními cíli – ať už dáváte přednost přesnosti, rychlosti, spokojenosti uživatelů nebo míře vyřešení problémů. Nakonfigurujte hodnotící LLM platformy pomocí detailních promptů, které přesně popisují, jak odpovědi hodnotit, včetně konkrétních příkladů kvalitních i špatných odpovědí. Nahrajte svou konverzační databázi nebo propojte živý provoz, poté spusťte hodnocení a získejte podrobné reporty s výkonem napříč všemi metrikami. Dashboard FlowHunt poskytuje aktuální přehled o výkonu chatbota, což umožňuje rychlou identifikaci problémů i ověření vylepšení.
Zaveďte výchozí měření před implementací vylepšení, abyste měli referenční bod pro hodnocení dopadu změn. Měřte průběžně, nikoliv jen periodicky, což umožňuje včasné odhalení poklesu výkonu vlivem změny dat nebo zastarávání modelu. Zaveďte zpětnou vazbu, kdy uživatelská hodnocení a opravy automaticky vstupují do tréninkového procesu a průběžně zvyšují přesnost chatbota. Segmentujte metriky podle kategorie dotazu, typu uživatele a časového období, abyste identifikovali konkrétní oblasti vyžadující pozornost a nespoléhali se jen na agregované statistiky.
Zajistěte, aby hodnotící dataset reprezentoval skutečné uživatelské dotazy a očekávané odpovědi – vyhněte se umělým testovacím případům, které neodrážejí reálné vzorce používání. Pravidelně ověřujte automatizované metriky lidským posouzením vzorku konverzací, abyste udrželi kalibraci měřicího systému na skutečnou kvalitu. Jasně zdokumentujte metodiku měření a definice metrik, což umožní konzistentní hodnocení v čase a jasnou komunikaci výsledků stakeholderům. Nakonec stanovte cílové hodnoty pro každou metriku v souladu s obchodními cíli, čímž vytvoříte odpovědnost za průběžné zlepšování a jasné cíle pro optimalizační úsilí.
Pokročilá AI automatizační platforma FlowHunt vám pomůže vytvářet, nasazovat a hodnotit vysoce výkonné helpdesk chatboty s vestavěnými nástroji pro měření přesnosti a LLM-based hodnotícími možnostmi.
Poznejte komplexní strategie testování AI chatbotů včetně funkčního, výkonnostního, bezpečnostního a uživatelského testování. Objevte osvědčené postupy, nástroj...
Zjistěte nejlepší způsoby, jak v roce 2025 oslovovat asistenty AI chatbotů. Objevte formální, neformální i hravé styly komunikace, konvence pojmenování a jak ef...
Zjistěte, jak nejlépe zdravit AI chatboty a optimalizovat své konverzace. Objevte techniky pozdravů, tipy pro prompt engineering a komunikační strategie pro rok...
Souhlas s cookies
Používáme cookies ke zlepšení vašeho prohlížení a analýze naší návštěvnosti. See our privacy policy.