Kontekst Engineering: Den Ultimative Guide 2025 til at Mestre AI Systemdesign
Dyk dybt ned i kontekst engineering for AI. Denne guide dækker kerneprincipper – fra prompt vs. kontekst til avancerede strategier som memory management, context rot og multi-agent design.
AI
LLM
System Design
Agents
Context Engineering
Prompt Engineering
RAG
Landskabet for AI-udvikling har gennemgået en dyb transformation. Hvor vi tidligere fokuserede på at formulere den perfekte prompt, står vi nu over for en langt mere kompleks udfordring: at bygge hele informationsarkitekturer, der understøtter og styrker vores sprogmodeller.
Dette skifte markerer overgangen fra prompt engineering til kontekst engineering – og det repræsenterer intet mindre end fremtiden for praktisk AI-udvikling. De systemer, der leverer reel værdi i dag, bygger ikke på magiske prompts. De lykkes, fordi deres arkitekter har lært at orkestrere omfattende informationsøkosystemer.
Andrej Karpathy indfangede denne udvikling perfekt, da han beskrev kontekst engineering som en omhyggelig praksis, hvor man fylder kontekstvinduet med præcis den rigtige information på det nøjagtige rigtige tidspunkt. Denne tilsyneladende simple erklæring afslører en grundlæggende sandhed: LLM’en er ikke længere hovedpersonen. Den er en kritisk komponent i et omhyggeligt designet system, hvor hvert informationsstykke – hver hukommelsesbrik, hver værktøjsbeskrivelse, hvert hentet dokument – bevidst er placeret for at maksimere resultaterne.
Hvad er Kontekst Engineering?
Et Historisk Perspektiv
Rødderne til kontekst engineering går dybere, end de fleste tror. Selvom det brede fokus på prompt engineering eksploderede omkring 2022-2023, opstod de grundlæggende koncepter for kontekst engineering for over 20 år siden i forskning inden for ubiquitous computing og menneske-computer interaktion.
Allerede i 2001 fastlagde Anind K. Dey en definition, der skulle vise sig bemærkelsesværdig fremsynet: kontekst omfatter al information, der hjælper med at karakterisere en entitets situation. Denne tidlige ramme lagde grundlaget for vores opfattelse af maskiners forståelse af omgivelser.
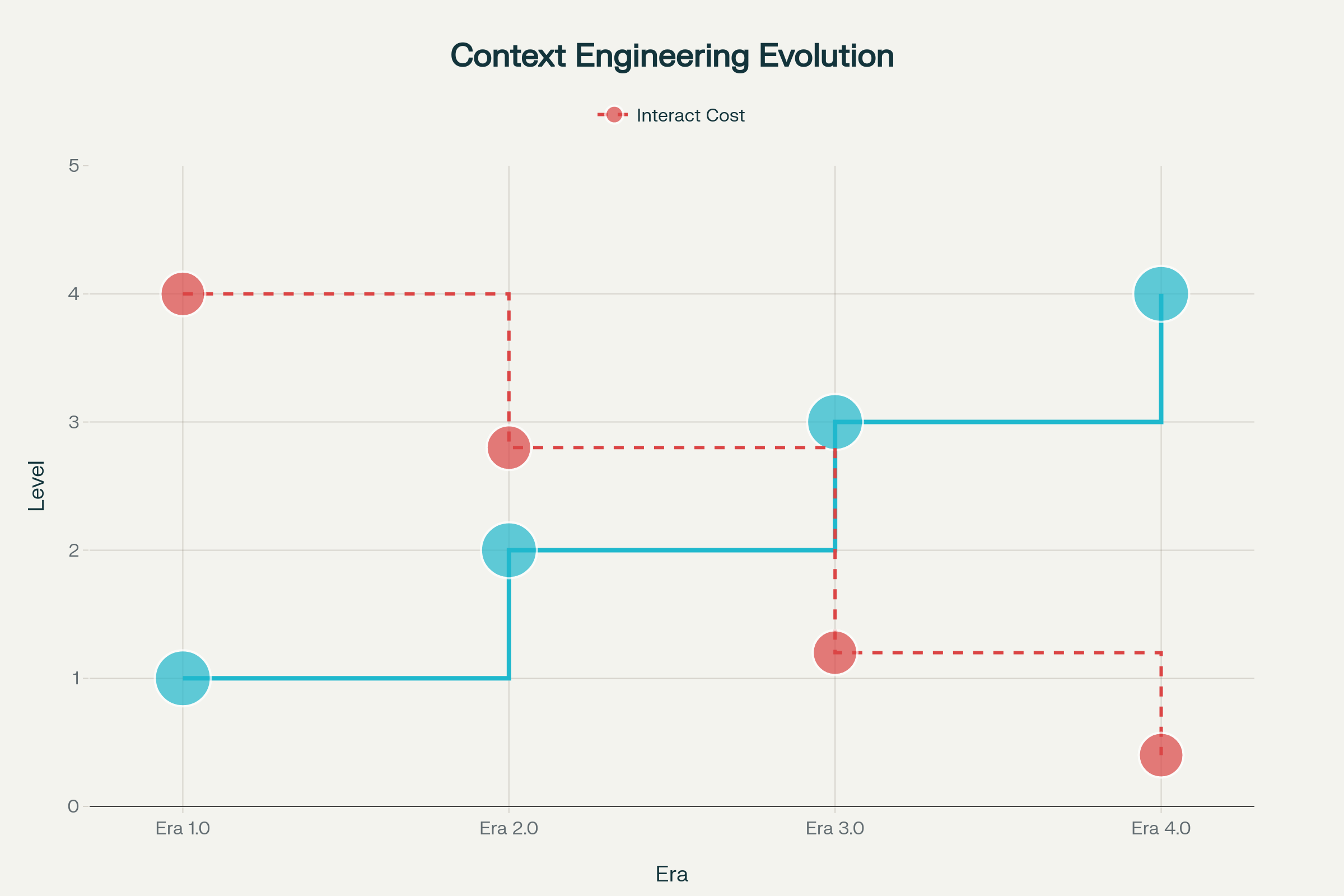
Udviklingen af kontekst engineering har udfoldet sig i markante faser, hver formet af fremskridt i maskinintelligens:
Æra 1.0: Primitiv Computation (1990’erne–2020) — I denne lange periode kunne maskiner kun håndtere strukturerede input og basale miljøsignaler. Mennesker bar hele byrden med at oversætte kontekster til formater, maskiner kunne forstå. Tænk på skrivebordsapplikationer, mobilapps med sensorinput og tidlige chatbots med stive svaretræer.
Æra 2.0: Agent-Centreret Intelligens (2020–Nu) — GPT-3’s udgivelse i 2020 udløste et paradigmeskifte. Store sprogmodeller bragte reel forståelse af naturligt sprog og evnen til at arbejde med implicitte intentioner. Denne æra muliggjorde autentisk menneske-agent samarbejde, hvor tvetydighed og ufuldstændig information blev håndterbart gennem avanceret sprogforståelse og in-context learning.
Æra 3.0 & 4.0: Menneskelig og Overmenneskelig Intelligens (Fremtid) — De næste bølger lover systemer, der kan sanse og behandle høj-entropy information med menneskelignende flydendehed, og som til sidst bevæger sig ud over reaktive svar til proaktivt at konstruere kontekst og forudse brugerbehov, før de bliver artikuleret.
Udviklingen af Kontekst Engineering Gennem Fire Æraer: Fra Primitiv Computing til Overmenneskelig Intelligens
En Formelt Definition
I sin essens repræsenterer kontekst engineering den systematiske disciplin at designe og optimere, hvordan kontekstuel information strømmer gennem AI-systemer – fra den første indsamling til lagring, styring og endelig anvendelse for at forbedre maskinforståelse og opgaveløsning.
Dette kan udtrykkes matematisk som en transformationsfunktion:
$CE: (C, T) \rightarrow f_{context}$
Hvor:
C repræsenterer rå kontekstuel information (entiteter og deres karakteristika)
T betegner den ønskede opgave eller applikationsdomæne
f_{context} giver den resulterende kontekstbehandlingsfunktion
Opdelt i praksis afsløres fire grundlæggende operationer:
Indsamling af relevante kontekstsignaler gennem forskellige sensorer og informationskanaler
Lagring af denne information effektivt på lokale systemer, netværksinfrastruktur og cloud-platforme
Styring af kompleksitet gennem intelligent behandling af tekst, multimodale input og komplekse relationer
Anvendelse af kontekst strategisk ved at filtrere for relevans, muliggøre deling på tværs af systemer og tilpasse ud fra brugerbehov
Hvorfor Kontekst Engineering Er Vigtigt: Entropi Reduktionsrammen
Kontekst engineering adresserer en grundlæggende asymmetri i menneske-maskine kommunikation. Når mennesker taler sammen, udfylder vi ubesværet samtalehuller gennem fælles kulturel viden, emotionel intelligens og situationsfornemmelse. Maskiner besidder ingen af disse evner.
Denne kløft viser sig som informationsentropi. Menneskelig kommunikation fungerer effektivt, fordi vi kan antage enorme mængder delt kontekst. Maskiner kræver, at alting repræsenteres eksplicit. Kontekst engineering handler i sin kerne om at forbehandle kontekst for maskiner – at komprimere menneskets høje entropi og kompleksitet af intentioner og situationer til lave entropi-repræsentationer, som maskiner kan behandle.
Efterhånden som maskinintelligens udvikler sig, bliver denne entropireduktion i stigende grad automatisk. I dag, i Æra 2.0, må ingeniører manuelt orkestrere meget af denne reduktion. I Æra 3.0 og fremefter vil maskiner selv påtage sig en større del af denne byrde. Men hovedudfordringen forbliver: at bygge bro mellem menneskelig kompleksitet og maskinel forståelse.
Prompt Engineering vs. Kontekst Engineering: Kritiske Forskelle
En almindelig misforståelse er at blande disse to discipliner. I virkeligheden repræsenterer de fundamentalt forskellige tilgange til AI-systemarkitektur.
Prompt engineering handler om at formulere enkeltstående instruktioner eller forespørgsler for at forme modeladfærd. Det handler om at optimere det sproglige udtryk for det, du kommunikerer til modellen – formulering, eksempler og ræsonnementsmønstre i en enkelt interaktion.
Kontekst engineering er en omfattende systemdisciplin, der styrer alt det, modellen møder under inferens – inklusive prompts, men også hentede dokumenter, hukommelsessystemer, værktøjsbeskrivelser, tilstandsoplysninger og mere.
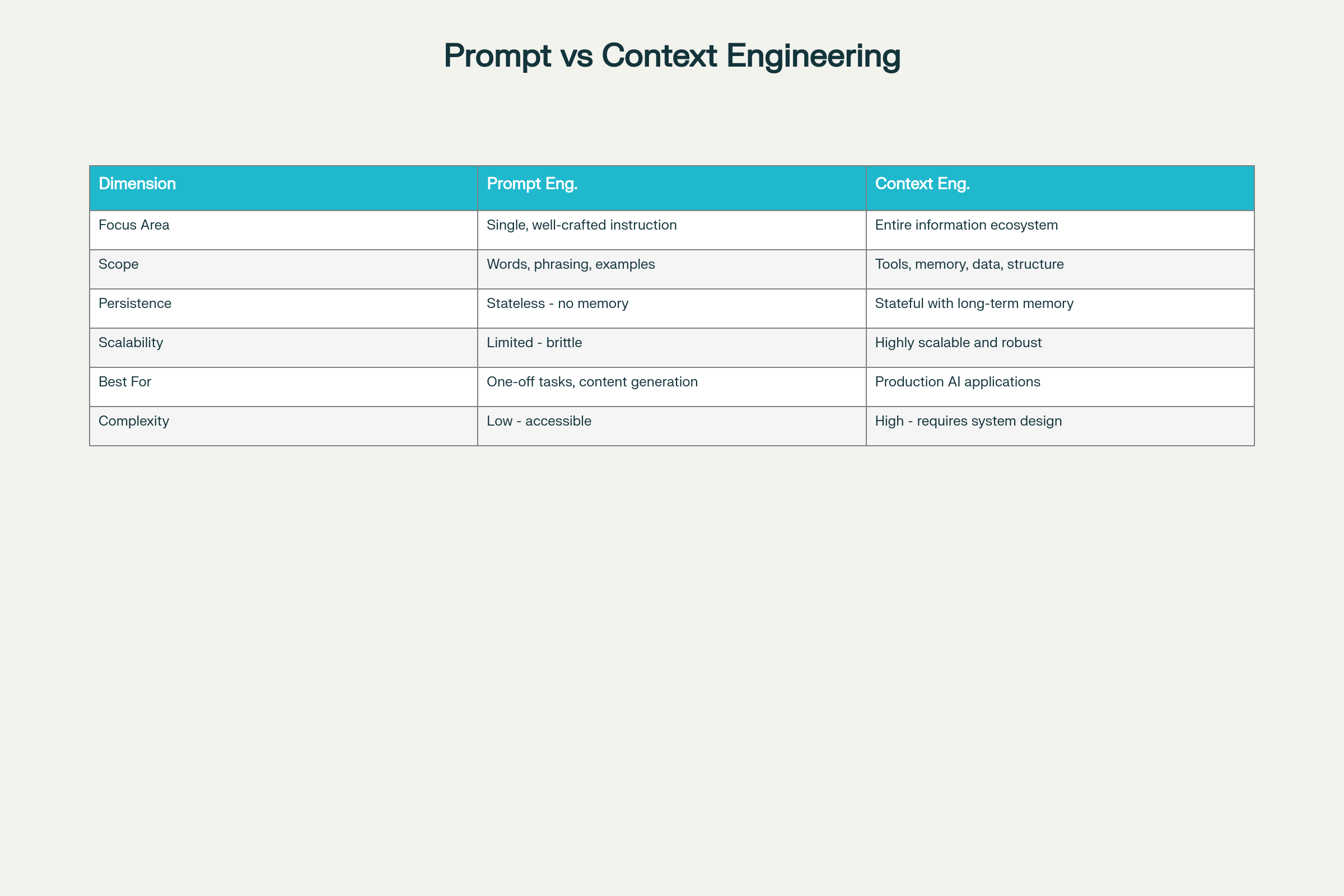
Prompt Engineering vs Context Engineering: Nøgleforskelle og Afvejninger
Tænk på denne forskel: At bede ChatGPT om at skrive en professionel e-mail er prompt engineering. At bygge en kundeserviceplatform, der holder samtalehistorik på tværs af flere sessioner, har adgang til brugeroplysninger og husker tidligere supportsager – det er kontekst engineering.
Vigtige Forskelle på Otte Dimensioner:
Dimension
Prompt Engineering
Kontekst Engineering
Fokusområde
Optimering af enkeltinstruktion
Omfattende informationsøkosystem
Omfang
Ord, formulering, eksempler
Værktøjer, hukommelse, dataarkitektur, struktur
Persistens
Uden hukommelse – stateless
Med tilstand og langtidshukommelse
Skalerbarhed
Begrænset og skrøbelig i stor skala
Meget skalerbar og robust
Bedst til
Éngangsopgaver, indholdsgenerering
Produktionsklare AI-applikationer
Kompleksitet
Lav adgangsbarriere
Høj – kræver systemdesign
Pålidelighed
Uforudsigelig i stor skala
Konsistent og pålidelig
Vedligeholdelse
Skrøbelig ved kravændringer
Modulær og vedligeholdelsesvenlig
Den afgørende indsigt: Produktionsklare LLM-applikationer kræver i overvældende grad kontekst engineering frem for blot smarte prompts. Som Cognition AI bemærkede, er kontekst engineering blevet den primære opgave for ingeniører, der bygger AI-agenter.
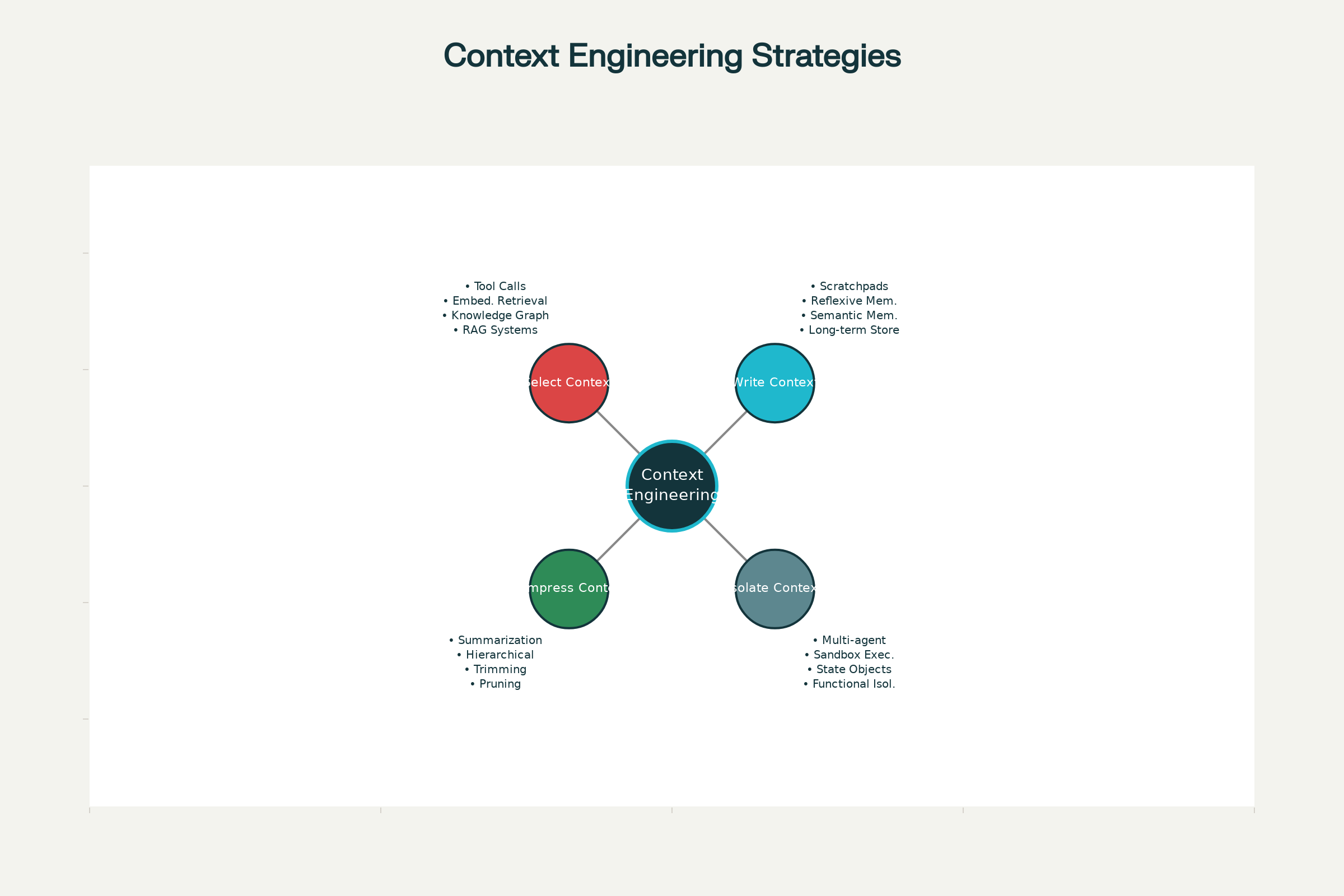
De Fire Kerne-Strategier for Kontekst Engineering
På tværs af førende AI-systemer – fra Claude og ChatGPT til specialiserede agenter udviklet hos Anthropic og andre frontlabs – har fire kerne-strategier krystalliseret sig for effektiv kontekststyring. Disse kan anvendes hver for sig eller kombineres for større effekt.
1. Write Context: Gem Information Uden for Kontekstvinduet
Det grundlæggende princip er elegant simpelt: tving ikke modellen til at huske alt. Gem i stedet kritisk information uden for kontekstvinduet, hvor den kan tilgås pålideligt, når den behøves.
Scratchpads er den mest intuitive implementering. Ligesom mennesker tager noter under løsningen af komplekse problemer, bruger AI-agenter scratchpads til at bevare information til fremtidig brug. Implementeringen kan være så enkel som et værktøj, agenten bruger til at gemme noter, eller så avanceret som felter i et runtime state-objekt, der bevares på tværs af eksekveringsskridt.
Anthropics multi-agent researcher demonstrerer dette smukt: LeadResearcher starter med at formulere en tilgang og gemmer sin plan i Memory for persistens, velvidende at hvis kontekstvinduet overstiger 200.000 tokens, vil der ske afkortning, og planen skal bevares.
Memories udvider scratchpad-konceptet på tværs af sessioner. I stedet for kun at fange information inden for en enkelt opgave (session-scoped memory), kan systemer bygge langtidshukommelser, der bevares og udvikles over mange bruger-agent-interaktioner. Dette mønster er blevet standard i produkter som ChatGPT, Claude Code, Cursor og Windsurf.
Forskningsinitiativer som Reflexion var pionerer for reflektive hukommelser – hvor agenten reflekterer over hvert skridt og genererer minder til fremtidig brug. Generative Agents udvidede denne tilgang ved periodisk at syntetisere hukommelser fra samlinger af tidligere feedback.
Tre Typer Hukommelse:
Episodisk: Konkrete eksempler på tidligere adfærd eller interaktioner (uvurderlig til few-shot learning)
Procedural: Instruktioner eller regler, der styrer adfærd (sikrer ensartet drift)
Semantisk: Fakta og relationer om verden (giver forankret viden)
2. Select Context: Hent Kun Relevant Information
Når information er bevaret, skal agenten hente kun det, der er relevant for den aktuelle opgave. Dårlig udvælgelse kan være lige så skadelig som ingen hukommelse overhovedet – irrelevant information kan forvirre modellen eller udløse hallucinationer.
Hukommelsesudvælgelsesmekanismer:
Enklere tilgange anvender snævre, altid inkluderede filer. Claude Code bruger en CLAUDE.md-fil til proceduremæssige minder, mens Cursor og Windsurf bruger rules-filer. Men denne tilgang har svært ved at skalere, når en agent har opsamlet hundreder af fakta og relationer.
For større hukommelsessamlinger anvendes embedding-baseret retrieval og vidensgrafer ofte. Systemet konverterer både minder og den aktuelle forespørgsel til vektor-repræsentationer og henter så de mest semantisk lignende minder.
Men som Simon Willison berømt demonstrerede på AIEngineer World’s Fair, kan denne tilgang fejle spektakulært. ChatGPT indsatte uventet hans placering fra minder i et genereret billede – hvilket viser, at selv avancerede systemer kan hente minder uhensigtsmæssigt. Dette understreger behovet for omhyggelig engineering.
Værktøjsudvælgelse byder også på udfordringer. Når agenter har adgang til adskillige værktøjer, kan simpel opremsning forvirre – overlappende beskrivelser får modeller til at vælge forkerte værktøjer. En effektiv løsning: brug RAG-principper på værktøjsbeskrivelser. Ved kun at hente semantisk relevante værktøjer er nøjagtigheden tredoblet i nogle systemer.
Videnshentning er måske det rigeste problemfelt. Code-agenter illustrerer denne udfordring i produktion. Som en Windsurf-ingeniør bemærkede, er indeksering af kode ikke lig med effektiv kontekst-hentning. De kombinerer indeksering og embedding-søgning med AST-parsing og chunking langs semantisk meningsfulde grænser. Men embedding-søgning bliver upålidelig, når kodebaser vokser. Succes kræver kombinerede teknikker som grep/fil-søgning, retrieval via vidensgrafer og en reranking-fase, hvor konteksten rangeres efter relevans.
3. Compress Context: Bevar Kun Det Nødvendige
Når agenter arbejder på langvarige opgaver, akkumuleres kontekst naturligt. Scratchpad-noter, værktøjsoutput og interaktionshistorik kan hurtigt overstige kontekstvinduet. Komprimeringsstrategier adresserer denne udfordring ved intelligent at destillere information og bevare det væsentlige.
Opsummering er den primære teknik. Claude Code implementerer “auto-compact” – når kontekstvinduet rammer 95% kapacitet, opsummeres hele bruger-agent-interaktionsforløbet. Dette kan gøres på flere måder:
Rekursiv opsummering: Laver opsummeringer af opsummeringer i kompakte hierarkier
Hierarkisk opsummering: Genererer opsummeringer på flere abstraktionsniveauer
Målrettet opsummering: Komprimerer specifikke komponenter (fx token-tunge søgeresultater) frem for hele konteksten
Cognition AI afslørede, at de bruger finetunede modeller til opsummering ved agent-agent-overgange for at reducere tokenforbrug under videnoverdragelse – hvilket viser, hvor dybt engineering kan gå.
Konteksttrimning er en supplerende tilgang. I stedet for at bruge en LLM til intelligent opsummering, trimmer man blot konteksten via hardcodede heuristikker – fjerner ældre beskeder, filtrerer efter vigtighed eller bruger trænede prunere som Provence til QA-opgaver.
Den vigtige pointe: Hvad du fjerner, kan være lige så vigtigt som, hvad du beholder. En fokuseret kontekst på 300 tokens overgår ofte en ufokuseret kontekst på 113.000 tokens i samtaleopgaver.
4. Isolate Context: Opdel Informationen på Tværs af Systemer
Endelig anerkender isolationsstrategier, at forskellige opgaver kræver forskellig information. I stedet for at presse al kontekst ind i ét models vindue, opdeler isolationsteknikker konteksten på tværs af specialiserede systemer.
Multi-agent Arkitekturer er den mest udbredte tilgang. OpenAI Swarm-biblioteket er bygget op om “separation of concerns” – hvor specialiserede subagenter håndterer specifikke opgaver med egne værktøjer, instruktioner og kontekstvinduer.
Anthropics forskning demonstrerer styrken i denne tilgang: mange agenter med isolerede kontekster overgik enkelt-agent-implementeringer, fordi hver subagents kontekstvindue kan tildeles en mere snæver opgave. Subagenter arbejder parallelt i egne kontekstvinduer og undersøger forskellige aspekter samtidig.
Dog indebærer multi-agent systemer afvejninger. Anthropic rapporterede op til femten gange højere tokenforbrug end enkelt-agent chat. Dette kræver omhyggelig orkestrering, prompt engineering til planlægning og avancerede koordinationsmekanismer.
Sandbox-miljøer er en anden isolationsstrategi. HuggingFace’s CodeAgent demonstrerer dette: I stedet for at returnere JSON, som modellen skal ræsonnere over, genererer agenten kode, der eksekveres i en sandkasse. Udvalgte outputs (returnværdier) sendes tilbage til LLM’en, så token-tunge objekter forbliver isoleret i eksekveringsmiljøet. Dette er særligt effektivt til visuel og lyddata.
State Object Isolation er måske den mest undervurderede teknik. En agents runtime state kan designes som et struktureret schema (fx en Pydantic-model) med flere felter. Ét felt (som messages) eksponeres for LLM’en ved hvert skridt, mens andre felter holdes isoleret til selektiv brug. Dette giver finjusteret kontrol uden arkitektonisk kompleksitet.
Fire Kerne-Strategier for Effektiv Kontekst Engineering i AI-agenter
Context Rot Problemet: En Kritisk Udfordring
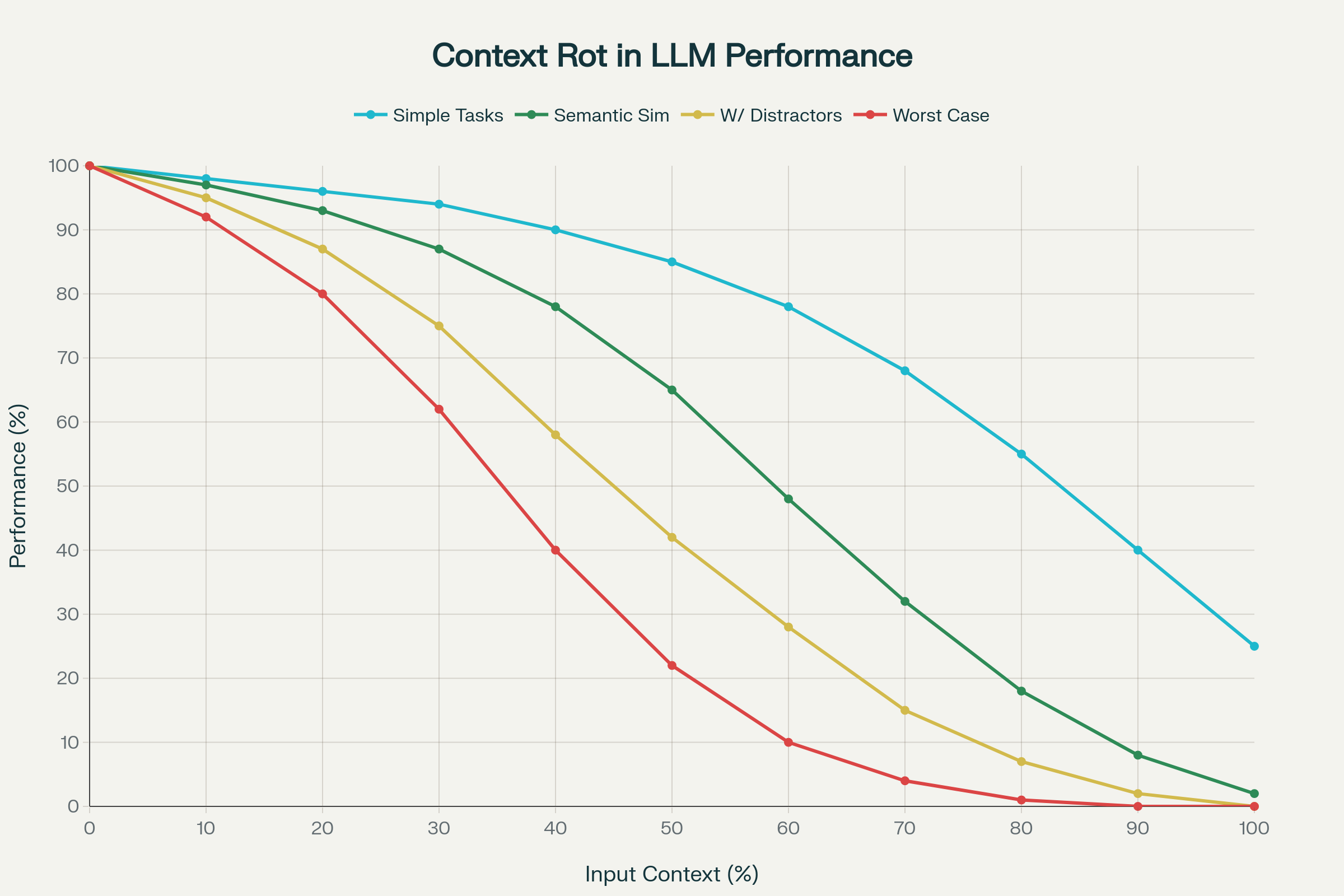
Selvom fremskridt i kontekstlængde er blevet fejret i branchen, afslører ny forskning en bekymrende virkelighed: længere kontekst betyder ikke automatisk bedre præstation.
Et banebrydende studie, der analyserede 18 førende LLM’er – herunder GPT-4.1, Claude 4, Gemini 2.5 og Qwen 3 – afdækkede et fænomen kaldet context rot: den uforudsigelige og ofte alvorlige forringelse af præstation, efterhånden som input-konteksten vokser.
Nøglefund om Context Rot
1. Ikke-lineær Præstationsforringelse
Præstationen falder ikke lineært eller forudsigeligt. Modeller viser pludselige, idiosynkratiske fald afhængigt af model og opgave. En model kan holde 95% nøjagtighed op til en vis kontekstlængde og så pludselig styrtdykke til 60%. Disse fald er uforudsigelige på tværs af modeller.
2. Semantisk Kompleksitet Forværrer Context Rot
Enkle opgaver (som at kopiere gentagne ord eller præcis semantisk retrieval) udviser moderat fald. Men når nålen i høstakken kræver semantisk lighed frem for eksakt match, falder præstationen dramatisk. Tilstedeværelsen af plausible distraktorer – information, der ligner men ikke er det rigtige – forværrer nøjagtigheden markant.
3. Positionsbias og Attention Collapse
Transformer attention skalerer ikke lineært med lange kontekster. Tokens i begyndelsen (primacy bias) og slutningen (recency bias) får uforholdsmæssig meget opmærksomhed. I ekstreme tilfælde kollapser opmærksomheden helt, så modellen ignorerer store dele af inputtet.
4. Modelspecifikke Fejlmønstre
Forskellige LLM’er udviser unikke mønstre i stor skala:
GPT-4.1: Har tendens til hallucination, gentager forkerte tokens
Gemini 2.5: Indfører uvedkommende fragmenter eller tegn
Claude Opus 4: Kan nægte opgaver eller blive overforsigtig
5. Virkelighedsnær Indvirkning i Samtaleindstillinger
Måske mest afslørende: I LongMemEval-benchmarken klarede modeller sig markant bedre med kun det fokuserede 300-token-udsnit end med hele samtalen (ca. 113k tokens). Det viser, at context rot forringer både retrieval og ræsonnement i reelle dialoger.
Context Rot: Præstationsforringelse når Input Token Længde Øges på Tværs af 18 LLM’er
Implikationer: Kvalitet Frem for Kvantitet
Hovedbudskabet fra context rot-forskningen er klart: Antallet af input-tokens er ikke den eneste kvalitetsfaktor. Hvordan konteksten konstrueres, filtreres og præsenteres er mindst lige så vigtigt.
Denne indsigt validerer hele kontekst engineering-disciplinen. I stedet for at betragte lange kontekstvinduer som en universalløsning, indser sofistikerede teams, at omhyggelig kontekst engineering – gennem komprimering, selektion og isolation – er afgørende for at opretholde præstation med store input.
Kontekst Engineering i Praksis: Virkelige Anvendelser
Case Study 1: Multi-Turn Agent-Systemer (Claude Code, Cursor)
Claude Code og Cursor repræsenterer state-of-the-art implementeringer af kontekst engineering til kodeassistance:
Indsamling: Disse systemer samler kontekst fra flere kilder – åbne filer, projektstruktur, redigeringshistorik, terminaloutput og brugerkommentarer.
Styring: I stedet for at dumpe alle filer i prompten, komprimerer de intelligent. Claude Code bruger hierarkiske opsummeringer. Kontekst tagges efter funktion (fx “aktuelt redigeret fil”, “refereret afhængighed”, “fejlmeddelelse”).
Anvendelse: Ved hvert skridt vælger systemet, hvilke filer og kontekstelementer der er relevante, præsenterer dem struktureret og holder separate spor for ræsonnement og synligt output.
Komprimering: Når kontekstgrænsen nærmer sig, aktiveres auto-compact, der opsummerer interaktionerne og bevarer nøglebeslutninger.
Resultat: Disse værktøjer forbliver brugbare i store projekter (tusindvis af filer) uden præstationsfald trods kontekstvindue-begrænsninger.
Case Study 2: Tongyi DeepResearch (Open-Source Deep Research Agent)
Tongyi DeepResearch viser, hvordan kontekst engineering muliggør komplekse research-opgaver:
Datasyntese-pipeline: I stedet for at stole på begrænsede menneskeannoterede data, bruger Tongyi en avanceret datasynthese-tilgang, der skaber PhD-niveau forskningsspørgsmål via iterative kompleksitetsforbedringer. Hver iteration uddyber viden og bygger mere komplekse ræsonnementopgaver.
Kontekststyring: Systemet bruger IterResearch-paradigmet – i hver forskningsrunde rekonstrueres workspace med kun de væsentlige outputs fra forrige runde. Dette forhindrer “kognitiv kvælning” fra ophobning af information i én kontekst.
Parallel Udforskning: Flere research-agenter arbejder parallelt med isolerede kontekster, hver undersøger forskellige aspekter. En synteseagent integrerer derefter resultaterne for helhedsbesvarelser.
Resultater: Tongyi DeepResearch opnår resultater på niveau med proprietære systemer som OpenAI’s DeepResearch, med score på 32,9 på Humanity’s Last Exam og 75 på brugercentrerede benchmarks.
Case Study 3: Anthropics Multi-Agent Researcher
Anthropics forskning demonstrerer, hvordan isolation og specialisering forbedrer præstation:
Arkitektur: Specialiserede subagenter håndterer specifikke research-opgaver (litteraturstudie, syntese, verifikation) med separate kontekstvinduer.
Fordele: Denne tilgang overgik enkelt-agent-systemer, da hver subagents kontekst er optimeret til dens snævre opgave.
Afvejning: Selvom kvaliteten var bedre, steg tokenforbrug op til femten gange sammenlignet med enkelt-agent-chat.
Dette fremhæver en vigtig indsigt: kontekst engineering indebærer ofte afvejninger mellem kvalitet, hastighed og omkostninger. Den rette balance afhænger af applikationens krav.
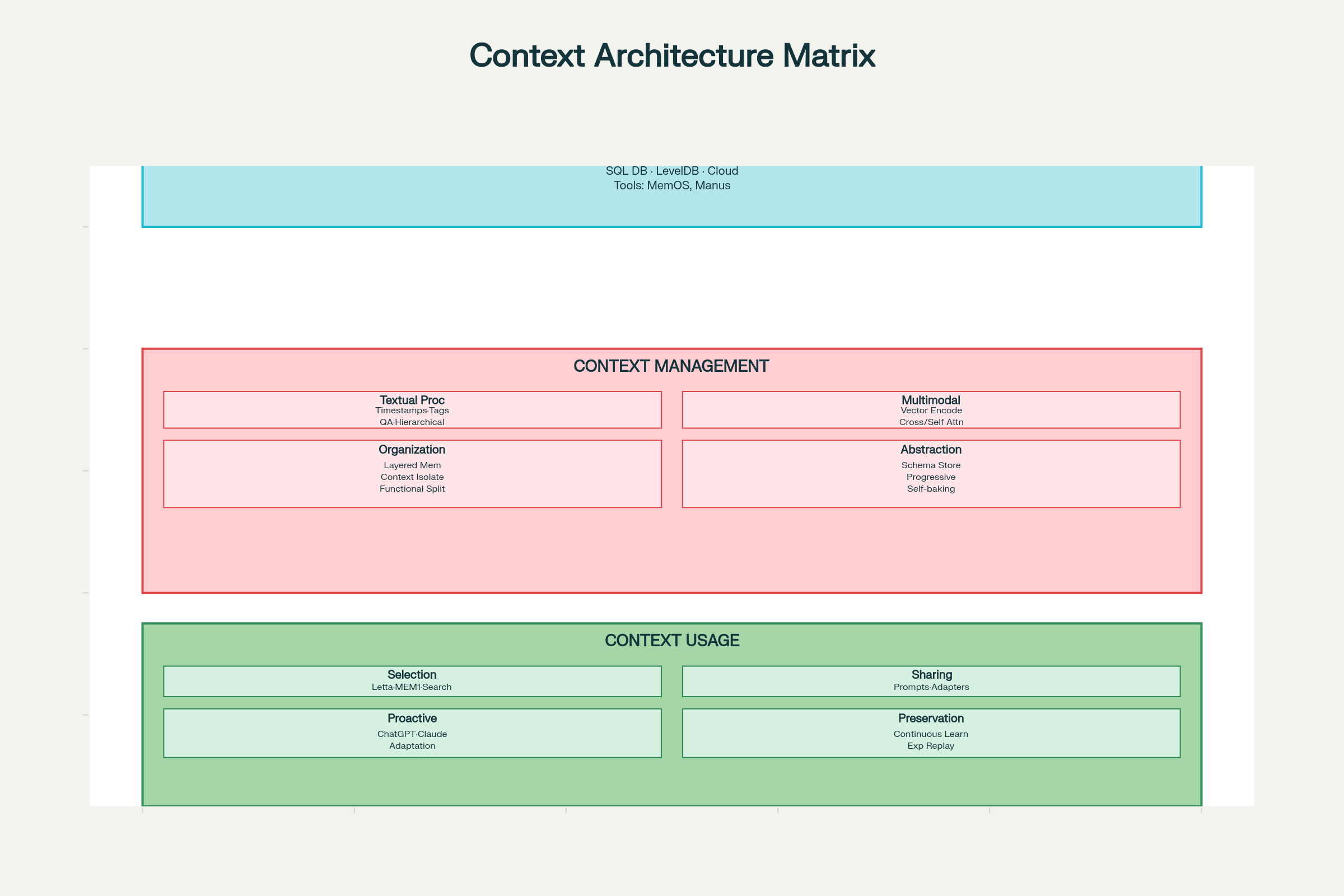
Designovervejelser: Rammeværk
Effektiv kontekst engineering kræver systemtænkning på tre områder: indsamling & lagring, styring og anvendelse.
Kontekst Engineering Designovervejelser: Fuld Systemarkitektur og Komponenter
Indsamling & Lagring: Designbeslutninger
Valg af lagringsteknologi:
Lokal lagring (SQLite, LevelDB): Hurtig, lav latenstid, egnet til klient-side agenter
Distribuerede systemer: Til massiv skala med redundans og fejltolerance
Designmønstre:
MemOS: Memory operating system til samlet hukommelsesstyring
Manus: Struktureret hukommelse med rollebaseret adgang
Hovedprincip: Design til effektiv hentning, ikke kun lagring. Det optimale lagringssystem er et, hvor du hurtigt kan finde det, du behøver.
Styring: Designbeslutninger
Tekstuel kontekstbehandling:
Tidsstempling: Simpelt, men begrænset. Bevarer kronologi men ingen semantisk struktur – skaleringsproblemer over tid.
Rolle-/funktionstagging: Mærk hvert kontekstelement med funktion – “mål”, “beslutning”, “handling”, “fejl” osv. Understøtter multidimensionel tagging (prioritet, kilde, sikkerhed). Nye systemer som LLM4Tag muliggør dette i stor skala.
Komprimering med QA-par: Konverter interaktioner til komprimerede spørgsmål-svar-par, hvilket bevarer essensen og reducerer tokens.
Hierarkiske noter: Progressiv komprimering til meningsvektorer, som i H-MEM-systemer, der fanger semantisk essens på flere niveauer.
Multimodal kontekstbehandling:
Sammenlignelige vektorrum: Kod alle modaliteter (tekst, billede, lyd) til sammenlignelige vektorrum med fælles embedding-modeller (som ChatGPT og Claude).
Cross-attention: Brug én modalitet til at guide opmærksomheden på en anden (som Qwen2-VL).
Uafhængig kodning med self-attention: Kod modaliteter hver for sig og kombiner dem med samlet opmærksomhed.
Ekstraher nøglefakta via faste skemaer (ChatSchema-tilgangen)
Progressivt komprimer til meningsvektorer (H-MEM-systemer)
Anvendelse: Designbeslutninger
Kontekstudvælgelse:
Embedding-baseret retrieval (mest udbredt)
Traversering i vidensgrafer (til komplekse relationer)
Semantisk lighedsscore
Vægtning efter recency/prioritet
Kontekstdeling:
Inden for et system:
Indlejring af udvalgt kontekst i prompts (AutoGPT, ChatDev)
Struktureret beskedudveksling mellem agenter (Letta, MemOS)
Delt hukommelse via indirekte kommunikation (A-MEM-systemer)
På tværs af systemer:
Adaptere, der konverterer kontekstformat (Langroid)
Delte repræsentationer mellem platforme (Sharedrop)
Proaktiv brugerforståelse:
ChatGPT og Claude analyserer interaktionsmønstre for at forudse brugerbehov
Kontekssystemer lærer at fremhæve information, før det eksplicit ønskes
Balance mellem hjælpsomhed og privatliv er fortsat en vigtig udfordring
Kontekst Engineering Kompetencer Teams Skal Mestre
Efterhånden som kontekst engineering bliver mere central i AI-udvikling, adskiller visse kompetencer effektive teams fra de øvrige.
1. Strategisk Kontekstopbygning
Teams skal forstå, hvilken information der tjener hver opgave. Det handler ikke kun om datainhentning – men om at forstå opgavens krav så dybt, at man kan skelne nødvendigt fra støj.
I praksis:
Analysér fejltyper for at identificere manglende kontekst
A/B-test forskellige kontekstkombinationer for at måle effekt
Byg observabilitet til at spore, hvilke kontekstelementer driver præstation
2. Hukommelsessystemarkitektur
Design af effektive hukommelsessystemer kræver forståelse for forskellige hukommelsestyper og deres samspil:
Hvornår bør information ligge i korttidshukommelse vs. langtidshukommelse?
Hvordan bør forskellige hukommelsestyper interagere?
Hvilke komprimeringsstrategier bevarer nøjagtighed og reducerer tokens?
3. Semantisk Søgning og Retrieval
Teams skal mestre mere end simpel ordsøgning:
Embedding-modeller og deres begrænsninger
Vektorsimilaritets-metrics og afvejninger
Reranking og filtreringsstrategier
Håndtering af tvetydige forespørgsler
4. Tokenøkonomi og Omkostningsanalyse
Hver byte kontekst indebærer afvejninger:
Overvåg tokenforbrug på tværs af kontekst engineering-tilgange
Forstå model-specifikke tokenomkostninger
Afvej kvalitet mod omkostning og latenstid
5. Systemorkestrering
Med flere agenter, værktøjer og hukommelsessystemer er omhyggelig orkestrering afgørende:
Koordination mellem subagenter
Håndtering og genopretning af fejl
Tilstandsstyring ved langvarige opgaver
6. Evaluering og Måling
Kontekst engineering er grundlæggende en optimeringsdisciplin:
Def
Ofte stillede spørgsmål
Prompt engineering fokuserer på at udforme en enkelt instruktion til en LLM. Kontekst engineering er en bredere disciplin, der styrer hele informationsøkosystemet for en AI-model, inklusiv hukommelse, værktøjer og hentede data, for at optimere præstation på komplekse, tilstandsbaserede opgaver.
Context rot er den uforudsigelige forringelse af en LLM's præstation, efterhånden som input-konteksten bliver længere. Modeller kan udvise drastiske fald i nøjagtighed, ignorere dele af konteksten eller hallucinere – hvilket understreger behovet for kvalitetsstyring af kontekst frem for blot kvantitet.
De fire kerne-strategier er: 1. Write Context (gemme information uden for kontekst-vinduet, som fx scratchpads eller hukommelse), 2. Select Context (hente kun relevant information), 3. Compress Context (opsummere eller trimme for at spare plads), og 4. Isolate Context (bruge multi-agent systemer eller sandkasser til at adskille information).
Arshia er AI Workflow Engineer hos FlowHunt. Med en baggrund inden for datalogi og en passion for AI, specialiserer han sig i at skabe effektive workflows, der integrerer AI-værktøjer i daglige opgaver og øger produktivitet og kreativitet.
Arshia Kahani
AI Workflow Engineer
Mestre Kontekst Engineering
Er du klar til at bygge næste generation af AI-systemer? Udforsk vores ressourcer og værktøjer for at implementere avanceret kontekst engineering i dine projekter.
Længe leve kontekst engineering: Byg produktionsklare AI-systemer med moderne vektordatabaser
Udforsk hvordan kontekst engineering omformer AI-udvikling, udviklingen fra RAG til produktionsklare systemer, og hvorfor moderne vektordatabaser som Chroma er ...
At overvinde ikke-determinisme i LLM’er: Løsning på AI’s reproducerbarhedskrise
Opdag hvordan Mira Muratis Thinking Machines Lab løser ikke-determinisme-problemet i store sprogmodeller og muliggør reproducerbare AI-resultater – en udvikling...
Giv din AI-assisterede udvikling et løft ved at integrere FlowHunt's LLM-kontekst. Injicer problemfrit relevant kode og dokumentationskontekst i dine foretrukne...
4 min læsning
AI
LLM
+4
Cookie Samtykke Vi bruger cookies til at forbedre din browsingoplevelse og analysere vores trafik. See our privacy policy.