Wan 2.1 er en kraftfuld open source AI-videogenereringsmodel fra Alibaba, som leverer studie-kvalitetsvideoer ud fra tekst eller billeder – gratis og til lokal brug for alle.
AI Video Generation
Open Source
Wan 2.1
Alibaba
Generative AI
Video AI
AI Tools
Wan 2.1 (også kaldet WanX 2.1) baner nye veje som en fuldt open source AI-model til videogenerering udviklet af Alibaba’s Tongyi Lab. I modsætning til mange proprietære systemer til videogenerering, der kræver dyre abonnementer eller API-adgang, leverer Wan 2.1 sammenlignelig eller overlegen kvalitet, mens den forbliver helt gratis og tilgængelig for udviklere, forskere og kreative professionelle.
Det, der virkelig gør Wan 2.1 speciel, er kombinationen af tilgængelighed og ydeevne. Den mindre T2V-1.3B-variant kræver kun ~8,2 GB GPU-hukommelse, hvilket gør den kompatibel med de fleste moderne forbrugergrafikkort. Samtidig leverer den større version med 14 milliarder parametre state-of-the-art ydeevne, der overgår både åbne alternativer og mange kommercielle modeller på standardbenchmarks.
Nøglefunktioner der adskiller Wan 2.1
Multitask-understøttelse
Wan 2.1 er ikke begrænset til tekst-til-video-generering. Dens alsidige arkitektur understøtter:
Tekst-til-video (T2V)
Billede-til-video (I2V)
Video-til-video-redigering
Tekst-til-billede-generering
Video-til-lyd-generering
Denne fleksibilitet betyder, at du kan starte med en tekstprompte, et stillbillede eller endda en eksisterende video og omdanne det efter din kreative vision.
Flersproget tekstgenerering
Som den første videomodel, der kan gengive læsbar engelsk og kinesisk tekst i genererede videoer, åbner Wan 2.1 nye muligheder for internationale indholdsskabere. Denne funktion er især værdifuld til undertekster eller scenetekst i flersprogede videoer.
Revolutionerende Video VAE (Wan-VAE)
I hjertet af Wan 2.1’s effektivitet ligger dens 3D kausale Video Variational Autoencoder. Dette teknologiske gennembrud komprimerer effektivt rum-tidslig information, så modellen kan:
Komprimere videoer til hundrededele af den oprindelige størrelse
Bevare bevægelse og detaljeringsgrad
Understøtte høj opløsning op til 1080p
Enestående effektivitet og tilgængelighed
Den mindre 1.3B-model kræver kun 8,19 GB VRAM og kan producere en 5-sekunders 480p-video på ca. 4 minutter på et RTX 4090 grafikkort. Til trods for denne effektivitet matcher eller overgår kvaliteten langt større modeller, hvilket giver det perfekte kompromis mellem hastighed og billedkvalitet.
Branchens førende benchmarks & kvalitet
I offentlige evalueringer opnåede Wan 14B den højeste samlede score i Wan-Bench-tests og overgik konkurrenterne i:
Bevægelseskvalitet
Stabilitet
Præcis opfølgning af prompt
Klar til at vokse din virksomhed?
Start din gratis prøveperiode i dag og se resultater inden for få dage.
Hvordan Wan 2.1 adskiller sig fra andre videogenereringsmodeller
I modsætning til lukkede systemer som OpenAI’s Sora eller Runway’s Gen-2 er Wan 2.1 frit tilgængelig til lokal afvikling. Den overgår generelt tidligere open source-modeller (som CogVideo, MAKE-A-VIDEO og Pika) og endda mange kommercielle løsninger på kvalitetsbenchmarks.
En nyere brancherapport bemærkede, at “blandt mange AI-videomodeller skiller Wan 2.1 og Sora sig ud” – Wan 2.1 for sin åbenhed og effektivitet, og Sora for sin proprietære innovation. I brugertests har man rapporteret, at Wan 2.1’s billede-til-video-evner overgår konkurrenterne i klarhed og filmisk fornemmelse.
Teknologien bag Wan 2.1
Wan 2.1 bygger på et diffusion-transformer baggrundsnetværk med en ny rum-tidslig VAE. Sådan fungerer det:
Et input (tekst og/eller billede/video) kodes til en latent videorepræsentation af Wan-VAE
En diffusion-transformer (baseret på DiT-arkitekturen) denoiser denne latent trinvis
Processen styres af tekst-encoder (en flersproget T5-variant kaldet umT5)
Til sidst rekonstruerer Wan-VAE-dekoderen de færdige videorammer
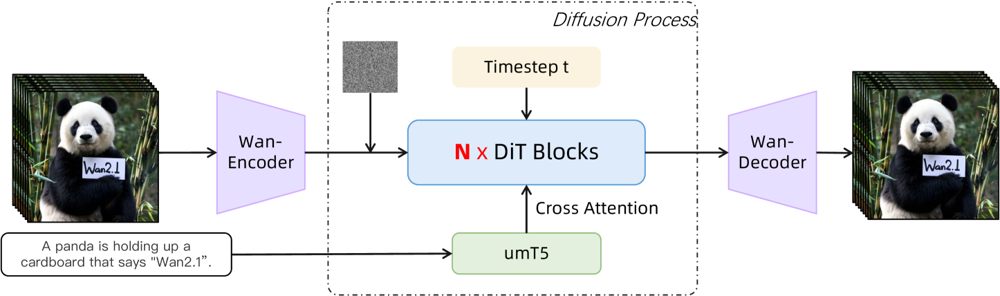
Figur: Wan 2.1’s overordnede arkitektur (tekst-til-video-case). En video (eller et billede) kodes først af Wan-VAE-encoderen til en latent. Denne latent sendes derefter gennem N diffusion-transformer-blokke, som via cross-attention tilgår tekst-embeddinget (fra umT5). Til sidst rekonstruerer Wan-VAE-dekoderen videorammerne. Dette design – med en “3D kausal VAE-encoder/decoder omkring en diffusion-transformer” (ar5iv.org
) – muliggør effektiv komprimering af rum-tidslig data og understøtter videooutput i høj kvalitet.
Denne innovative arkitektur – med en “3D kausal VAE-encoder/decoder omkring en diffusion-transformer” – muliggør effektiv komprimering af rum-tidslig data og understøtter videooutput i høj kvalitet.
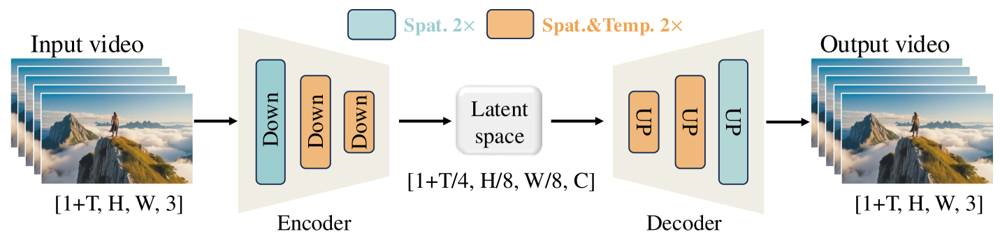
Wan-VAE er specielt designet til videoer. Den komprimerer inputtet med imponerende faktorer (4× tidsligt og 8× rumligt) til en kompakt latent, inden det dekodes tilbage til fuld video. Ved at bruge 3D-konvolutioner og kausale (tidsbevarende) lag sikres sammenhængende bevægelse gennem hele det genererede indhold.
Figur: Wan 2.1’s Wan-VAE-framework (encoder-decoder). Wan-VAE-encoderen (til venstre) anvender en række ned-samplingslag (“Down”) på inputvideoen (form [1+T, H, W, 3] frames), indtil den når en kompakt latent ([1+T/4, H/8, W/8, C]). Wan-VAE-dekoderen (til højre) opsampler (“UP”) derefter denne latent tilbage til de oprindelige videorammer. Blå blokke angiver rumlig komprimering, og orange blokke angiver kombineret rumlig+tidslig komprimering (ar5iv.org
). Ved at komprimere videoen 256× (i rum-tidsligt volumen) gør Wan-VAE højtopløst videomodellering muligt for den efterfølgende diffusionsmodel.
Tilmeld dig vores nyhedsbrev
Få de seneste tips, trends og tilbud gratis.
Sådan kører du Wan 2.1 på din egen computer
Klar til selv at prøve Wan 2.1? Sådan kommer du i gang:
Systemkrav
Python 3.8+
PyTorch ≥2.4.0 med CUDA-understøttelse
NVIDIA GPU (8GB+ VRAM for 1.3B-modellen, 16-24GB for 14B-modeller)
Yderligere biblioteker fra repositoriet
Installationsvejledning
Klon repositoriet og installer afhængigheder:
git clone https://github.com/Wan-Video/Wan2.1.git
cd Wan2.1
pip install -r requirements.txt
python generate.py --task t2v-14B --size 1280*720 \
--ckpt_dir ./Wan2.1-T2V-14B \
--prompt "A futuristic city skyline at sunset, with flying cars zooming overhead."
Ydeevnetips
Til computere med begrænset GPU-hukommelse, prøv den lettere t2v-1.3B-model
Brug flagene --offload_model True --t5_cpu for at flytte dele af modellen til CPU
Styr billedformatet med --size-parameteren (f.eks. 832*480 for 16:9 480p)
Wan 2.1 tilbyder prompt-udvidelse og “inspirationsmode” via ekstra muligheder
Til reference kan et RTX 4090 generere en 5-sekunders 480p-video på ca. 4 minutter. Multi-GPU-opsætninger og forskellige ydeevneoptimeringer (FSDP, kvantisering m.m.) understøttes til storskalabrug.
Hvorfor Wan 2.1 er vigtig for fremtidens AI-video
Som en open source-kraftudfordrer til giganterne i AI-videogenerering markerer Wan 2.1 et væsentligt skifte i tilgængelighed. Dens frie og åbne natur betyder, at alle med et nogenlunde moderne GPU kan udforske banebrydende videogenerering uden abonnementsgebyrer eller API-omkostninger.
For udviklere muliggør den åbne licens tilpasning og forbedring af modellen. Forskere kan udvide dens muligheder, mens kreative professionelle hurtigt og effektivt kan prototype videoinhold.
I en tid hvor proprietære AI-modeller i stigende grad gemmes bag betalingsmure, viser Wan 2.1, at state-of-the-art-ydeevne kan demokratiseres og deles med det brede fællesskab.
Ofte stillede spørgsmål
Hvad er Wan 2.1?
Wan 2.1 er en fuldt open source AI-model til videoproduktion udviklet af Alibaba’s Tongyi Lab, som kan skabe videoer i høj kvalitet ud fra tekstprompter, billeder eller eksisterende videoer. Den er gratis at bruge, understøtter flere opgaver og kører effektivt på almindelige GPU’er.
Wan 2.1 understøtter multitask-videogenerering (tekst-til-video, billede-til-video, videoredigering m.m.), flersproget tekstgengivelse i videoer, høj effektivitet med sin 3D kausale Video VAE og overgår mange kommercielle og open source-modeller i benchmarks.
Hvordan kan jeg køre Wan 2.1 på min egen computer?
Du skal bruge Python 3.8+, PyTorch 2.4.0+ med CUDA og et NVIDIA GPU (8GB+ VRAM til den lille model, 16-24GB til den store model). Klon GitHub-repositoriet, installer afhængigheder, download modelvægtfilerne, og brug de medfølgende scripts til at generere videoer lokalt.
Hvorfor er Wan 2.1 vigtig for AI-videogenerering?
Wan 2.1 demokratiserer adgang til state-of-the-art videogenerering ved at være open source og gratis, så udviklere, forskere og kreative kan eksperimentere og innovere uden betalingsmure og proprietære begrænsninger.
Hvordan sammenlignes Wan 2.1 med modeller som Sora eller Runway Gen-2?
I modsætning til lukkede alternativer som Sora eller Runway Gen-2 er Wan 2.1 fuldt open source og kan køres lokalt. Den overgår generelt tidligere open source-modeller og matcher eller overgår mange kommercielle løsninger på kvalitetsbenchmarks.
Arshia er AI Workflow Engineer hos FlowHunt. Med en baggrund inden for datalogi og en passion for AI, specialiserer han sig i at skabe effektive workflows, der integrerer AI-værktøjer i daglige opgaver og øger produktivitet og kreativitet.
Arshia Kahani
AI Workflow Engineer
Prøv FlowHunt og byg AI-løsninger
Begynd at bygge dine egne AI-værktøjer og workflows for videoproduktion med FlowHunt, eller book en demo for at se platformen i aktion.
Hvordan forvandler du indholdsproduktion med Wan 2.2 & 2.5 videogenerering?
FlowHunt understøtter nu Wan 2.2 og 2.5 videogenereringsmodeller til tekst-til-video, billede-til-video, persona-udskiftning og animation. Forvandl din indholds...
Udforsk Sora 2's banebrydende muligheder inden for AI-videogenerering – fra realistisk karaktergengivelse til fysiksimulering – og opdag, hvordan teknologien fo...
Udforsk Sora 2's banebrydende muligheder inden for AI-videogenerering, fra realistisk genskabelse af karakterer til fysik-simulering, og opdag, hvordan denne te...
17 min læsning
AI
Video Generation
+3
Cookie Samtykke Vi bruger cookies til at forbedre din browsingoplevelse og analysere vores trafik. See our privacy policy.