Databricks Genie MCP Server
Databricks Genie MCP Server gør det muligt for store sprogmodeller at interagere med Databricks-miljøer via Genie API'et og understøtter samtalebaseret dataudfo...
4 min læsning
AI
Databricks
+6
Forbind dine AI-agenter med Databricks for automatiseret SQL, jobovervågning og workflow-styring ved brug af Databricks MCP Server i FlowHunt.
FlowHunt giver et ekstra sikkerhedslag mellem dine interne systemer og AI-værktøjer, hvilket giver dig granulær kontrol over hvilke værktøjer der er tilgængelige fra dine MCP-servere. MCP-servere hostet i vores infrastruktur kan problemfrit integreres med FlowHunts chatbot samt populære AI-platforme som ChatGPT, Claude og forskellige AI-editorer.
Databricks MCP (Model Context Protocol) Server er et specialiseret værktøj, der forbinder AI-assistenter med Databricks-platformen og muliggør problemfri interaktion med Databricks-ressourcer via naturligt sprog. Denne server fungerer som en bro mellem store sprogmodeller (LLM’er) og Databricks API’er, så LLM’er kan eksekvere SQL-forespørgsler, vise jobs, hente jobstatusser og få detaljeret jobinformation. Ved at eksponere disse funktioner via MCP-protokollen gør Databricks MCP Server det muligt for udviklere og AI-agenter at automatisere data-workflows, styre Databricks-jobs og strømline databaseoperationer, hvilket øger produktiviteten i datadrevne udviklingsmiljøer.
Ingen promptskabeloner er beskrevet i repositoryet.
Start din gratis prøveperiode i dag og se resultater inden for få dage.
Ingen eksplicitte ressourcer er angivet i repositoryet.
Få de seneste tips, trends og tilbud gratis.
pip install -r requirements.txt..env-fil med dine Databricks-legitimationsoplysninger.{
"mcpServers": {
"databricks": {
"command": "python",
"args": ["main.py"]
}
}
}
Eksempel på sikring af API-nøgler:
{
"mcpServers": {
"databricks": {
"command": "python",
"args": ["main.py"],
"env": {
"DATABRICKS_HOST": "${DATABRICKS_HOST}",
"DATABRICKS_TOKEN": "${DATABRICKS_TOKEN}",
"DATABRICKS_HTTP_PATH": "${DATABRICKS_HTTP_PATH}"
}
}
}
}
.env-filen med Databricks-legitimationsoplysninger.{
"mcpServers": {
"databricks": {
"command": "python",
"args": ["main.py"]
}
}
}
.env med legitimationsoplysninger.{
"mcpServers": {
"databricks": {
"command": "python",
"args": ["main.py"]
}
}
}
.env.{
"mcpServers": {
"databricks": {
"command": "python",
"args": ["main.py"]
}
}
}
Bemærk: Sørg altid for at sikre dine API-nøgler og hemmeligheder ved at benytte miljøvariabler som vist i konfigurationseksemplerne ovenfor.
Brug af MCP i FlowHunt
For at integrere MCP-servere i dit FlowHunt-workflow, skal du starte med at tilføje MCP-komponenten til dit flow og forbinde den til din AI-agent:

Klik på MCP-komponenten for at åbne konfigurationspanelet. I systemets MCP-konfigurationssektion indsætter du dine MCP-serveroplysninger i dette JSON-format:
{
"databricks": {
"transport": "streamable_http",
"url": "https://yourmcpserver.example/pathtothemcp/url"
}
}
Når det er konfigureret, kan AI-agenten nu bruge denne MCP som et værktøj med adgang til alle dens funktioner og muligheder. Husk at ændre “databricks” til det faktiske navn på din MCP-server og udskifte URL’en med din egen MCP-server-URL.
| Sektion | Tilgængelighed | Detaljer/Noter |
|---|---|---|
| Oversigt | ✅ | |
| Liste over Prompts | ⛔ | Ingen promptskabeloner angivet i repo |
| Liste over Ressourcer | ⛔ | Ingen eksplicitte ressourcer defineret |
| Liste over Værktøjer | ✅ | 4 værktøjer: run_sql_query, list_jobs, get_job_status, get_job_details |
| Sikring af API-nøgler | ✅ | Via miljøvariabler i .env og config JSON |
| Sampling Support (mindre vigtigt i evaluering) | ⛔ | Ikke nævnt |
| Roots Support | ⛔ | Ikke nævnt |
Baseret på tilgængeligheden af kernefunktioner (værktøjer, opsætning og sikkerhedsvejledning, men ingen ressourcer eller promptskabeloner) er Databricks MCP Server effektiv til Databricks API-integration, men mangler nogle avancerede MCP-primitiver. Jeg vil vurdere denne MCP-server til 6 ud af 10 for samlet fuldstændighed og nytte i MCP-økosystemet.
| Har en LICENSE | ⛔ (ikke fundet) |
|---|---|
| Har mindst ét værktøj | ✅ |
| Antal forks | 13 |
| Antal stjerner | 33 |
Databricks MCP Server er en bro mellem AI-assistenter og Databricks, der eksponerer Databricks-funktioner som SQL-eksekvering og jobstyring via MCP-protokollen til automatiserede workflows.
Den understøtter eksekvering af SQL-forespørgsler, visning af alle jobs, hentning af jobstatusser og detaljeret information om specifikke Databricks-jobs.
Brug altid miljøvariabler, for eksempel ved at placere dem i en `.env`-fil eller konfigurere dem i din MCP-serveropsætning, i stedet for at hardkode følsomme oplysninger.
Ja, tilføj blot MCP-komponenten til dit flow, konfigurer den med dine Databricks MCP-serveroplysninger, og dine AI-agenter får adgang til alle understøttede Databricks-funktioner.
Baseret på tilgængelige værktøjer, opsætningsvejledning og sikkerhedsstøtte, men manglende ressourcer og promptskabeloner, vurderes denne MCP Server til 6 ud af 10 for fuldstændighed i MCP-økosystemet.
Automatiser SQL-forespørgsler, overvåg jobs og administrer Databricks-ressourcer direkte fra konversationsbaserede AI-grænseflader. Integrer Databricks MCP Server i dine FlowHunt-flows for næste niveau af produktivitet.
Databricks Genie MCP Server gør det muligt for store sprogmodeller at interagere med Databricks-miljøer via Genie API'et og understøtter samtalebaseret dataudfo...

Databricks MCP-serveren forbinder AI-assistenter med Databricks-miljøer, hvilket muliggør autonom udforskning, forståelse og interaktion med Unity Catalog metad...
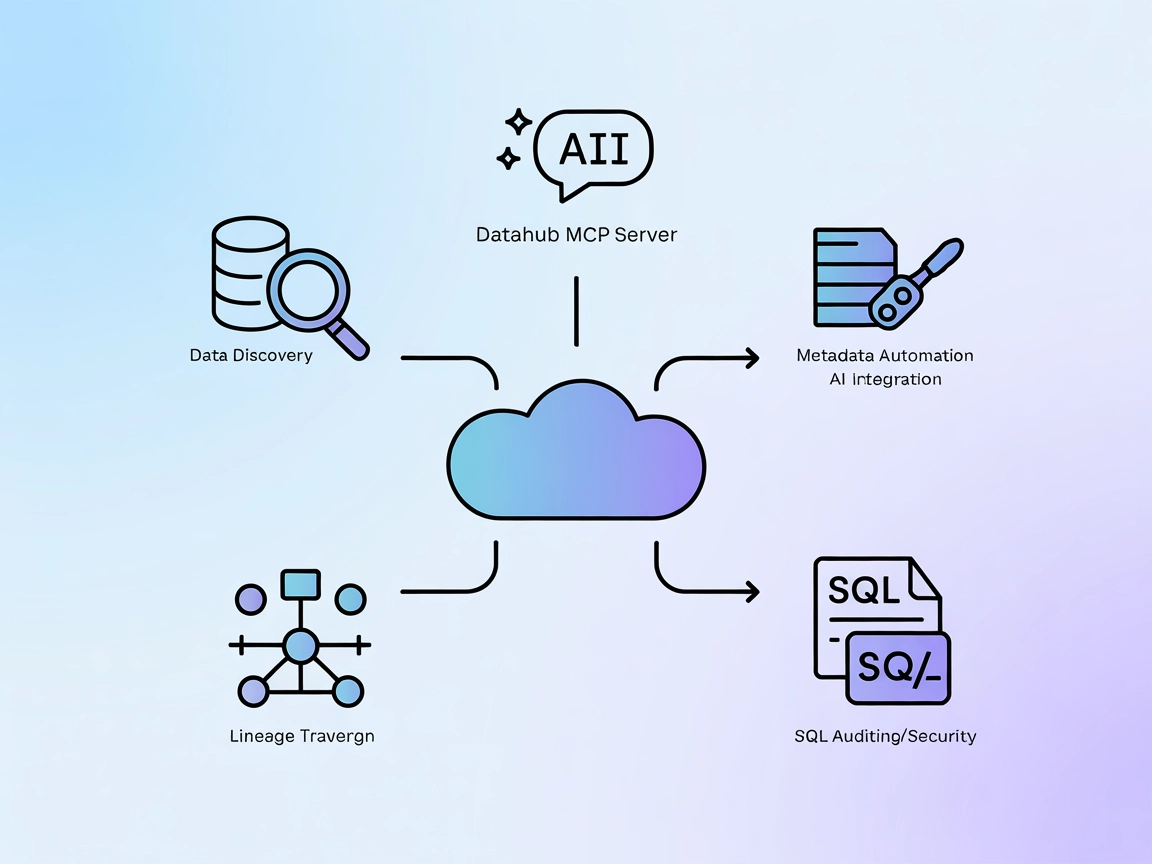
DataHub MCP Server forbinder FlowHunt AI-agenter med DataHub-metadataplatformen og muliggør avanceret dataopdagelse, lineage-analyse, automatiseret metadatahent...
Cookie Samtykke
Vi bruger cookies til at forbedre din browsingoplevelse og analysere vores trafik. See our privacy policy.