
Gehosteter MCP-Server für GitHub
Der GitHub MCP-Server ermöglicht eine nahtlose Integration zwischen KI-Tools und GitHub, sodass automatisierte Workflows Repositories, Issues und Pull Requests ...
5 Min. Lesezeit
AI
GitHub
+5

Das neue Open-Source-CLI-Toolkit von FlowHunt ermöglicht eine umfassende Flow-Bewertung mit LLM als Richter und bietet detaillierte Berichte sowie eine automatisierte Qualitätsprüfung für KI-Workflows.
Wir freuen uns, die Veröffentlichung des FlowHunt CLI Toolkits bekannt zu geben – unseres neuen Open-Source-Kommandozeilen-Tools, das die Art und Weise, wie Entwickler KI-Flows bewerten und testen, revolutioniert. Dieses leistungsstarke Toolkit bringt Flow-Bewertungsfunktionen auf Enterprise-Niveau in die Open-Source-Community – inklusive fortschrittlichem Reporting und unserer innovativen „LLM als Richter“-Implementierung.
Das FlowHunt CLI Toolkit stellt einen bedeutenden Fortschritt im Testen und Bewerten von KI-Workflows dar. Ab sofort auf GitHub verfügbar, bietet dieses Open-Source-Toolkit Entwicklern umfassende Werkzeuge für:
Das Toolkit steht für unser Bekenntnis zu Transparenz und Community-getriebener Entwicklung, indem es fortschrittliche KI-Bewertungstechniken Entwicklern weltweit zugänglich macht.
Eines der innovativsten Features unseres CLI Toolkits ist die Implementierung von „LLM als Richter“. Dieser Ansatz nutzt künstliche Intelligenz, um die Qualität und Richtigkeit von KI-generierten Antworten zu bewerten – KI beurteilt also KI-Leistung mit anspruchsvollen Begründungsfähigkeiten.
Was unsere Umsetzung besonders macht: Wir haben FlowHunt selbst genutzt, um den Bewertungs-Flow zu erstellen. Dieser Meta-Ansatz demonstriert die Leistungsfähigkeit und Flexibilität unserer Plattform und liefert gleichzeitig ein robustes Bewertungssystem. Der LLM-als-Richter-Flow besteht aus mehreren vernetzten Komponenten:
1. Prompt-Vorlage: Erstellt den Bewertungsprompt mit spezifischen Kriterien
2. Strukturierter Output-Generator: Verarbeitet die Bewertung mithilfe eines LLM
3. Datenparser: Formatiert den strukturierten Output für das Reporting
4. Chat-Ausgabe: Präsentiert die abschließenden Bewertungsergebnisse
Im Zentrum unseres LLM-als-Richter-Systems steht ein sorgfältig formulierter Prompt, der konsistente und zuverlässige Bewertungen sicherstellt. Hier ist die Kernvorlage, die wir verwenden:
You will be given an ANSWER and REFERENCE couple.
Your task is to provide the following:
1. a 'total_rating' scoring: how close is the ANSWER to the REFERENCE
2. a binary label 'correctness' which can be either 'correct' or 'incorrect', which defines if the ANSWER is correct or not
3. and 'reasoning', which describes the reason behind your choice of scoring and correctness/incorrectness of ANSWER
An ANSWER is correct when it is the same as the REFERENCE in all facts and details, even if worded differently. the ANSWER is incorrect if it contradicts the REFERENCE, changes or omits details. its ok if the ANSWER has more details comparing to REFERENCE.
'total rating' is a scale of 1 to 4, where 1 means that the ANSWER is not the same as REFERENCE at all, and 4 means that the ANSWER is the same as the REFERENCE in all facts and details even if worded differently.
Here is the scale you should use to build your answer:
1: The ANSWER is contradicts the REFERENCE completely, adds additional claims, changes or omits details
2: The ANSWER points to the same topic but the details are omitted or changed completely comparing to REFERENCE
3: The ANSWER's references are not completely correct, but the details are somewhat close to the details mentioned in the REFERENCE. its ok, if there are added details in ANSWER comparing to REFERENCES.
4: The ANSWER is the same as the REFERENCE in all facts and details, even if worded differently. its ok, if there are added details in ANSWER comparing to REFERENCES. if there are sources available in REFERENCE, its exactly the same as ANSWER and is for sure mentioned in ANSWER
REFERENCE
===
{target_response}
===
ANSWER
===
{actual_response}
===
Dieser Prompt stellt sicher, dass unser LLM-Richter Folgendes liefert:
Starten Sie heute Ihre kostenlose Testversion und sehen Sie innerhalb weniger Tage Ergebnisse.
Unser LLM-als-Richter-Flow demonstriert anspruchsvolles KI-Workflow-Design mithilfe des visuellen Flow-Builders von FlowHunt. So greifen die Komponenten ineinander:
Der Flow beginnt mit einer Chat Input-Komponente, die die Bewertungsanfrage mit tatsächlicher Antwort und Referenzantwort erhält.
Die Prompt-Vorlage-Komponente erstellt dynamisch den Bewertungsprompt, indem sie:
{target_response} einfügt{actual_response} einfügtDer Strukturierte Output-Generator verarbeitet den Prompt mit einem ausgewählten LLM und erzeugt einen strukturierten Output mit:
total_rating: numerische Skala von 1–4correctness: binäre Klassifikation korrekt/inkorrektreasoning: detaillierte Begründung der BewertungDie Parse Data-Komponente formatiert den strukturierten Output lesbar, und die Chat Output-Komponente präsentiert die finalen Ergebnisse.
Das LLM-als-Richter-System bietet mehrere fortschrittliche Funktionen, die es besonders effektiv für die Bewertung von KI-Flows machen:
Im Gegensatz zu einfachem String-Matching erkennt unser LLM-Richter:
Die 4-Punkte-Skala ermöglicht eine feingliedrige Bewertung:
Jede Bewertung enthält eine detaillierte Begründung, sodass Sie:
Erhalten Sie die neuesten Tipps, Trends und Angebote kostenlos.
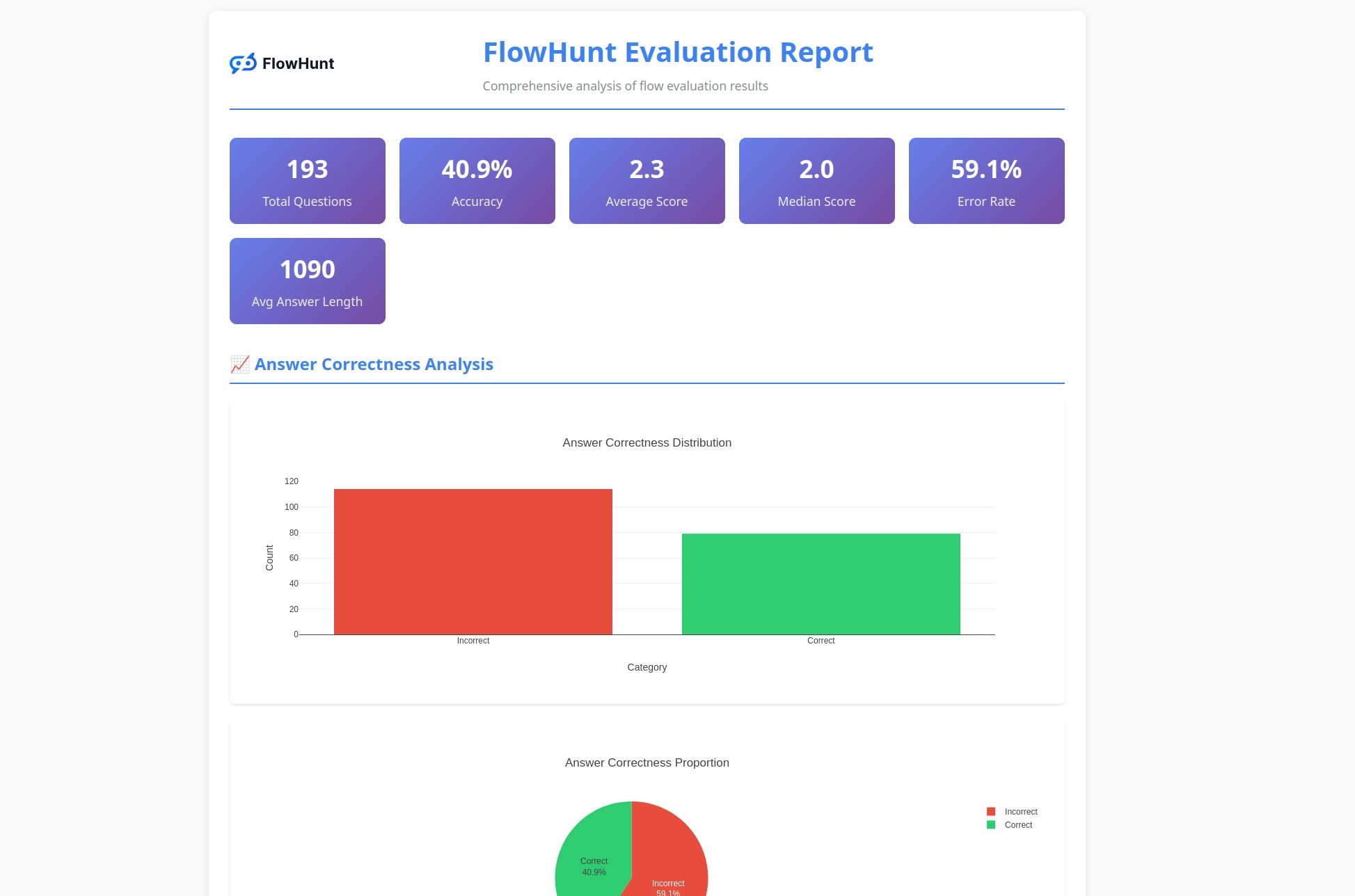
Das CLI-Toolkit erstellt detaillierte Berichte, die umsetzbare Erkenntnisse zum Flow-Verhalten liefern:
Bereit, Ihre KI-Flows mit Profi-Tools zu bewerten? So starten Sie:
One-Line-Installation (empfohlen) für macOS und Linux:
curl -sSL https://raw.githubusercontent.com/yasha-dev1/flowhunt-toolkit/main/install.sh | bash
Dies erledigt automatisch:
flowhunt-Befehls zu Ihrem PATHManuelle Installation:
# Repository klonen
git clone https://github.com/yasha-dev1/flowhunt-toolkit.git
cd flowhunt-toolkit
# Mit pip installieren
pip install -e .
Installation überprüfen:
flowhunt --help
flowhunt --version
1. Authentifizierung
Authentifizieren Sie sich zuerst mit Ihrer FlowHunt-API:
flowhunt auth
2. Flows auflisten
flowhunt flows list
3. Flow bewerten Erstellen Sie eine CSV-Datei mit Ihren Testdaten:
flow_input,expected_output
"What is 2+2?","4"
"What is the capital of France?","Paris"
Bewerten Sie mit LLM als Richter:
flowhunt evaluate your-flow-id path/to/test-data.csv --judge-flow-id your-judge-flow-id
4. Flows im Batch ausführen
flowhunt batch-run your-flow-id input.csv --output-dir results/
Das Bewertungssystem liefert umfassende Analysen:
flowhunt evaluate FLOW_ID TEST_DATA.csv \
--judge-flow-id JUDGE_FLOW_ID \
--output-dir eval_results/ \
--batch-size 10 \
--verbose
Features:
Das CLI-Toolkit integriert sich nahtlos in die FlowHunt-Plattform und ermöglicht Ihnen:
Die Veröffentlichung unseres CLI-Toolkits ist mehr als nur ein neues Werkzeug – sie steht für eine Vision der KI-Entwicklung, in der:
Qualität messbar ist: Fortschrittliche Bewertungsmethoden machen KI-Leistung quantifizierbar und vergleichbar.
Testen automatisiert ist: Umfassende Test-Frameworks reduzieren manuellen Aufwand und erhöhen die Zuverlässigkeit.
Transparenz Standard ist: Detaillierte Begründungen und Berichte machen KI-Verhalten verständlich und debugbar.
Die Community Innovation antreibt: Open-Source-Tools ermöglichen kollaborative Verbesserung und Wissenstransfer.
Mit der Open-Source-Stellung des FlowHunt CLI Toolkits zeigen wir unser Engagement für:
Das FlowHunt CLI Toolkit mit LLM als Richter ist ein bedeutender Fortschritt für die Bewertung von KI-Flows. Durch die Verbindung aus anspruchsvoller Bewertungslogik, umfassendem Reporting und Open-Source-Zugänglichkeit ermöglichen wir Entwicklern, bessere und zuverlässigere KI-Systeme zu bauen.
Der Meta-Ansatz, FlowHunt zur Bewertung von FlowHunt-Flows zu nutzen, demonstriert die Reife und Flexibilität unserer Plattform und liefert ein mächtiges Werkzeug für die KI-Community.
Egal ob Sie einfache Chatbots oder komplexe Multi-Agenten-Systeme bauen: Das FlowHunt CLI Toolkit bietet die Bewertungsinfrastruktur, die Sie für Qualität, Zuverlässigkeit und kontinuierliche Verbesserung benötigen.
Bereit, Ihre KI-Flow-Bewertung auf das nächste Level zu heben? Besuchen Sie unser GitHub-Repository , um direkt mit dem FlowHunt CLI Toolkit zu starten, und erleben Sie die Leistungsfähigkeit von LLM als Richter selbst.
Die Zukunft der KI-Entwicklung ist da – und sie ist Open Source.
Das FlowHunt CLI Toolkit ist ein Open-Source-Kommandozeilen-Tool zur Bewertung von KI-Flows mit umfassenden Reporting-Funktionen. Es beinhaltet Features wie die Bewertung durch LLM als Richter, Analyse von richtigen/falschen Ergebnissen und detaillierte Leistungsmetriken.
LLM als Richter nutzt einen ausgefeilten KI-Flow, der innerhalb von FlowHunt aufgebaut wurde, um andere Flows zu bewerten. Es vergleicht tatsächliche Antworten mit Referenzantworten und liefert Bewertungen, Korrektheitsanalysen und detaillierte Begründungen für jede Bewertung.
Das FlowHunt CLI Toolkit ist Open Source und auf GitHub unter https://github.com/yasha-dev1/flowhunt-toolkit verfügbar. Sie können es frei klonen, nutzen und daran mitarbeiten, um Ihre KI-Flows zu bewerten.
Das Toolkit generiert umfassende Berichte, darunter Aufschlüsselungen von richtigen/falschen Ergebnissen, LLM-als-Richter-Bewertungen mit Wertungen und Begründungen, Leistungskennzahlen und detaillierte Analysen des Flow-Verhaltens über verschiedene Testfälle hinweg.
Ja! Der LLM-als-Richter-Flow wurde mit der FlowHunt-Plattform erstellt und kann für verschiedene Bewertungsszenarien angepasst werden. Sie können die Prompt-Vorlage und die Bewertungskriterien nach Ihren Anforderungen modifizieren.
Yasha ist ein talentierter Softwareentwickler mit Spezialisierung auf Python, Java und Machine Learning. Yasha schreibt technische Artikel über KI, Prompt Engineering und Chatbot-Entwicklung.

Erstellen und bewerten Sie ausgefeilte KI-Workflows mit der FlowHunt-Plattform. Beginnen Sie noch heute mit der Entwicklung von Flows, die andere Flows bewerten können.
Der GitHub MCP-Server ermöglicht eine nahtlose Integration zwischen KI-Tools und GitHub, sodass automatisierte Workflows Repositories, Issues und Pull Requests ...
Integrieren Sie FlowHunt mit MCP Discovery, um die automatische MCP Server-Analyse, die Generierung von Dokumentation in mehreren Formaten und die Optimierung v...
Integrieren Sie FlowHunt mit GitHub Actions MCP, um das Management von CI/CD-Workflows zu optimieren, DevOps-Pipelines zu automatisieren und Teams mit KI-gestüt...
Cookie-Zustimmung
Wir verwenden Cookies, um Ihr Surferlebnis zu verbessern und unseren Datenverkehr zu analysieren. See our privacy policy.