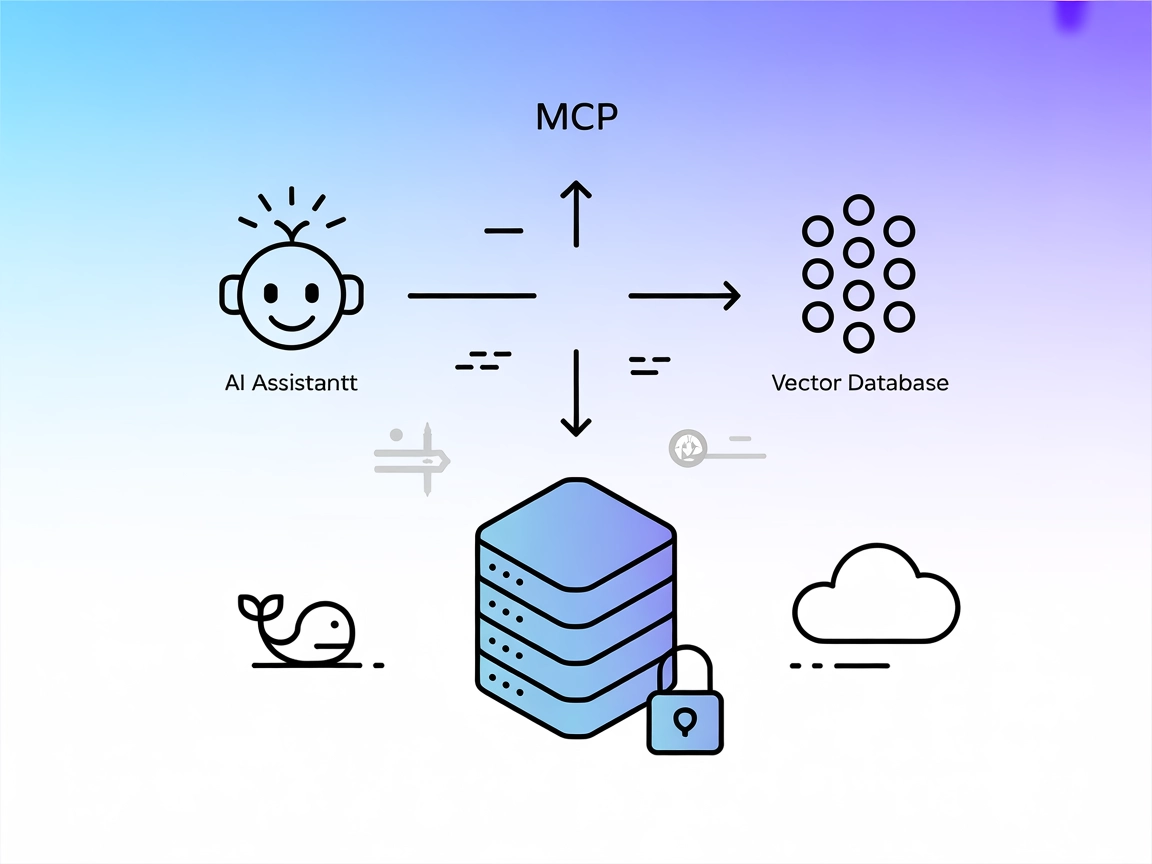
Pinecone Assistant MCP Server
Der Pinecone Assistant MCP Server verbindet KI-Assistenten mit Pinecone's Vektordatenbank und ermöglicht semantische Suche, Mehrfach-Ergebnisse und sicheres Abf...
4 Min. Lesezeit
AI
MCP Server
+5

Verbinden Sie FlowHunt mit Pinecone für fortschrittliche semantische Suche, Vektordatenverwaltung und KI-Anwendungen mit RAG.
FlowHunt bietet eine zusätzliche Sicherheitsschicht zwischen Ihren internen Systemen und KI-Tools und gibt Ihnen granulare Kontrolle darüber, welche Tools von Ihren MCP-Servern aus zugänglich sind. In unserer Infrastruktur gehostete MCP-Server können nahtlos mit FlowHunts Chatbot sowie beliebten KI-Plattformen wie ChatGPT, Claude und verschiedenen KI-Editoren integriert werden.
Der Pinecone MCP (Model Context Protocol) Server ist ein spezialisiertes Tool, das KI-Assistenten mit Pinecone-Vektordatenbanken verbindet und so das nahtlose Lesen und Schreiben von Daten für optimierte Entwicklungs-Workflows ermöglicht. Als Vermittler erlaubt der Pinecone MCP Server KI-Clients Aufgaben wie semantische Suche, Dokumentenabruf und Datenbankmanagement innerhalb eines Pinecone-Indexes auszuführen. Er unterstützt Operationen wie die Suche nach ähnlichen Einträgen, das Verwalten von Dokumenten sowie das Einfügen neuer Embeddings. Diese Fähigkeit ist besonders wertvoll für Anwendungen mit Retrieval-Augmented Generation (RAG), da sie die Integration kontextueller Daten in KI-Workflows vereinfacht und komplexe Dateninteraktionen automatisiert.
Im Repository werden keine expliziten Prompt-Vorlagen erwähnt.
Starten Sie heute Ihre kostenlose Testversion und sehen Sie innerhalb weniger Tage Ergebnisse.
Erhalten Sie die neuesten Tipps, Trends und Angebote kostenlos.
{
"mcpServers": {
"pinecone-mcp": {
"command": "mcp-pinecone",
"args": []
}
}
}
API-Schlüssel mit Umgebungsvariablen schützen:
{
"mcpServers": {
"pinecone-mcp": {
"command": "mcp-pinecone",
"env": {
"PINECONE_API_KEY": "your_api_key"
},
"inputs": {
"index_name": "your_index"
}
}
}
}
pip install mcp-pinecone).{
"mcpServers": {
"pinecone-mcp": {
"command": "mcp-pinecone",
"args": []
}
}
}
{
"mcpServers": {
"pinecone-mcp": {
"command": "mcp-pinecone",
"args": []
}
}
}
{
"mcpServers": {
"pinecone-mcp": {
"command": "mcp-pinecone",
"args": []
}
}
}
Hinweis: Schützen Sie API-Schlüssel und vertrauliche Werte immer mit Umgebungsvariablen, wie oben gezeigt.
MCP in FlowHunt verwenden
Um MCP-Server in Ihren FlowHunt-Workflow zu integrieren, fügen Sie die MCP-Komponente zu Ihrem Flow hinzu und verbinden Sie sie mit Ihrem KI-Agenten:

Klicken Sie auf die MCP-Komponente, um das Konfigurationsfeld zu öffnen. Im System-MCP-Konfigurationsbereich fügen Sie Ihre MCP-Server-Details in folgendem JSON-Format ein:
{
"pinecone-mcp": {
"transport": "streamable_http",
"url": "https://yourmcpserver.example/pathtothemcp/url"
}
}
Nach der Konfiguration kann der KI-Agent diesen MCP als Tool mit Zugriff auf alle Funktionen und Möglichkeiten verwenden. Denken Sie daran, “pinecone-mcp” durch den tatsächlichen Namen Ihres MCP-Servers zu ersetzen und die URL durch Ihre eigene MCP-Server-URL auszutauschen.
| Abschnitt | Verfügbarkeit | Details/Anmerkungen |
|---|---|---|
| Übersicht | ✅ | Beschreibt Pinecone MCPs Integration als Vektordatenbank |
| Liste der Prompts | ⛔ | Keine expliziten Prompt-Vorlagen gefunden |
| Liste der Ressourcen | ✅ | Pinecone-Index, Dokumente, Datensätze, Statistiken |
| Liste der Tools | ✅ | semantic-search, read-document, list-documents, pinecone-stats, process-document |
| Schutz von API-Schlüsseln | ✅ | Beispiel mit Umgebungsvariablen in der Konfiguration |
| Sampling-Unterstützung (weniger relevant bewertet) | ⛔ | Keine Erwähnung oder Hinweise gefunden |
Der Pinecone MCP Server ist gut dokumentiert, stellt klar definierte Ressourcen und Tools bereit und enthält solide Anweisungen für Integration und API-Key-Sicherheit. Es fehlen jedoch explizite Prompt-Vorlagen und Dokumentation zu Sampling oder Roots-Unterstützung. Insgesamt ist er ein praxisnaher und wertvoller Server für RAG- und Pinecone-Workflows, könnte aber durch weitere Workflow-Beispiele und fortgeschrittene Features noch verbessert werden.
Bewertung: 8/10
| Verfügt über eine LICENSE | ✅ (MIT) |
|---|---|
| Mindestens ein Tool | ✅ |
| Anzahl Forks | 25 |
| Anzahl Sterne | 124 |
Der Pinecone MCP Server verbindet KI-Assistenten mit Pinecone-Vektordatenbanken und ermöglicht semantische Suche, Dokumentenmanagement und Einbettungs-Workflows innerhalb von KI-Anwendungen wie FlowHunt.
Er bietet Tools für semantische Suche, Lesen und Auflisten von Dokumenten, Abrufen von Indexstatistiken sowie Verarbeitung von Dokumenten in Embeddings zum Hochladen in den Pinecone-Index.
Der Server ermöglicht es KI-Agenten, relevanten Kontext aus Pinecone abzurufen, sodass LLMs Antworten auf Basis externer Wissensquellen generieren können.
Speichern Sie Ihren Pinecone API-Schlüssel und den Indexnamen als Umgebungsvariablen in Ihrer Konfigurationsdatei, wie in den Integrationsanweisungen gezeigt, um Ihre Zugangsdaten zu schützen.
Typische Anwendungsfälle sind semantische Suche in großen Dokumentensammlungen, RAG-Pipelines, automatisches Chunking und Einbetten von Dokumenten sowie das Monitoring von Pinecone-Indexstatistiken.
Aktivieren Sie semantische Suche und Retrieval-Augmented Generation in FlowHunt, indem Sie Ihre KI-Agenten mit Pinecone-Vektordatenbanken verbinden.
Der Pinecone Assistant MCP Server verbindet KI-Assistenten mit Pinecone's Vektordatenbank und ermöglicht semantische Suche, Mehrfach-Ergebnisse und sicheres Abf...

Integrieren Sie FlowHunt mit dem Pinecone Model Context Protocol (MCP) Server für nahtlose, KI-gestützte Vektorsuche, Dokumentenverarbeitung und fortschrittlich...
Der Ragie MCP-Server ermöglicht KI-Assistenten die semantische Suche und das Abrufen relevanter Informationen aus Ragie-Wissensdatenbanken und verbessert so Ent...
Cookie-Zustimmung
Wir verwenden Cookies, um Ihr Surferlebnis zu verbessern und unseren Datenverkehr zu analysieren. See our privacy policy.