
Agentes de IA: Cómo piensa GPT-4o
Explora los procesos de pensamiento de los Agentes de IA en esta evaluación integral de GPT-4o. Descubre cómo se desempeña en tareas como generación de contenid...
9 min de lectura
AI
GPT-4o
+6

Sumérgete en un análisis comparativo en profundidad de 20 modelos líderes de agentes de IA, evaluando sus fortalezas, debilidades y rendimiento en tareas como generación de contenido, resolución de problemas, resumen, comparación y escritura creativa.
Probamos 20 modelos diferentes de agentes de IA en cinco tareas principales, cada una diseñada para explorar diferentes capacidades:
Nuestro análisis se centró tanto en la calidad de la salida como en el proceso de pensamiento del agente, evaluando su capacidad para planificar, razonar, adaptarse y utilizar eficazmente las herramientas disponibles. Hemos clasificado los modelos según su desempeño como agente de IA, dando mayor importancia a sus procesos de pensamiento y estrategias.
Los veinte modelos demostraron una fuerte capacidad para generar artículos de alta calidad e informativos. Sin embargo, la lista de clasificación siguiente tiene en cuenta los procesos de pensamiento interno de cada agente y cómo llegaron a su resultado final:
Evaluamos las capacidades matemáticas de los modelos y sus estrategias de resolución de problemas:
Evaluamos la capacidad de los modelos para extraer información clave y producir resúmenes concisos:
Este análisis evalúa 20 modelos líderes de agentes de IA, valorando su rendimiento en tareas como generación de contenido, resolución de problemas, resumen, comparación y escritura creativa, con énfasis especial en el proceso de pensamiento y adaptabilidad de cada modelo.
Según las clasificaciones finales, Claude 3.5 Sonnet logró el mejor rendimiento global, destacándose en precisión, pensamiento estratégico y produciendo resultados de alta calidad de manera constante.
Cada modelo fue evaluado en cinco tareas principales: generación de contenido, resolución de problemas, resumen, comparación y escritura creativa. La evaluación consideró no solo la calidad de la salida, sino también el razonamiento, la planificación, el uso de herramientas y la adaptabilidad.
Sí, FlowHunt ofrece una plataforma para crear, evaluar y desplegar agentes de IA y chatbots personalizados, lo que te permite automatizar tareas, optimizar flujos de trabajo y aprovechar capacidades avanzadas de IA para tu negocio.
La publicación del blog proporciona desgloses detallados por tarea y clasificaciones finales para cada uno de los 20 modelos de agentes de IA, destacando sus fortalezas y debilidades únicas en diferentes tareas.
Comienza a construir tus propias soluciones de IA con la potente plataforma de FlowHunt. Compara, evalúa y despliega agentes de IA de alto rendimiento para las necesidades de tu negocio.
Explora los procesos de pensamiento de los Agentes de IA en esta evaluación integral de GPT-4o. Descubre cómo se desempeña en tareas como generación de contenid...

Explora las capacidades avanzadas del Agente de IA Claude 3. Este análisis en profundidad revela cómo Claude 3 va más allá de la generación de texto, mostrando ...
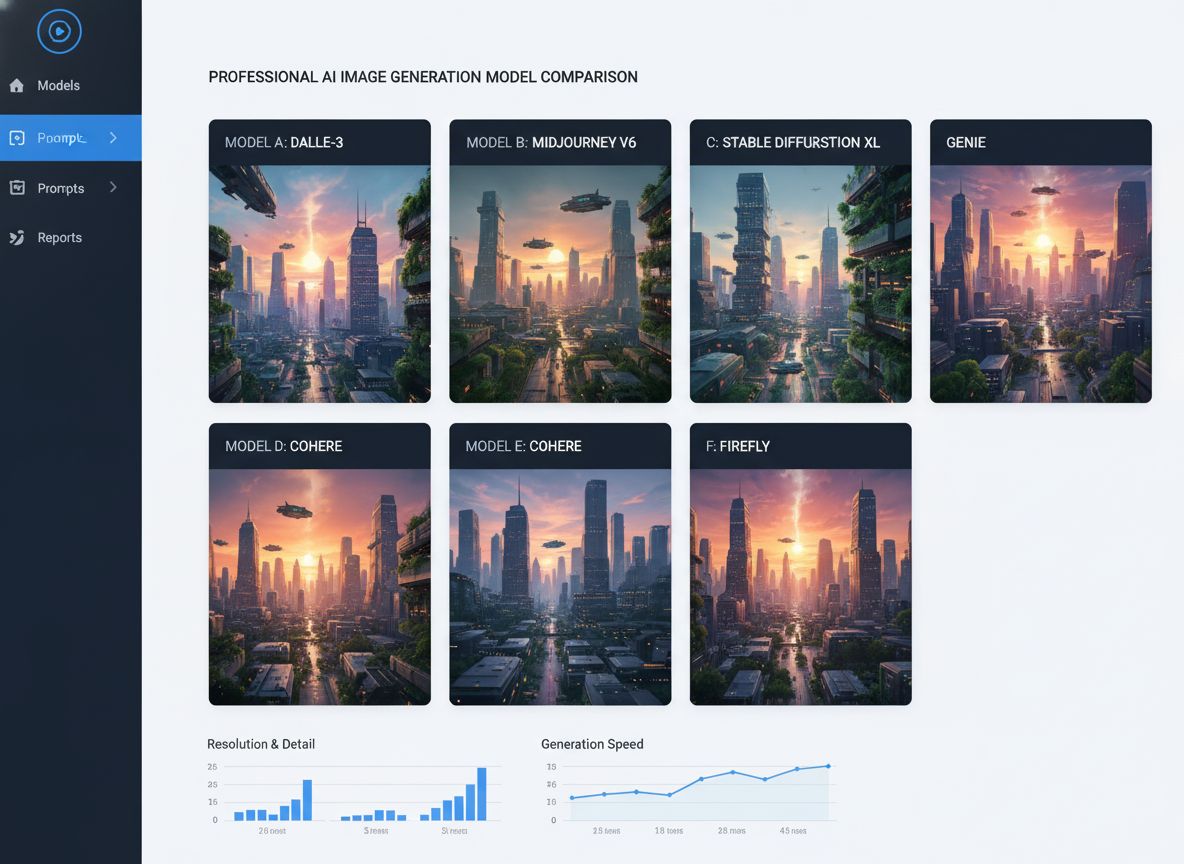
Comparativa exhaustiva de los principales modelos de generación de imágenes con IA, incluyendo Qwen ImageEdit Plus, Nano Banana, GPT Image 1 y Seadream. Descubr...
Consentimiento de Cookies
Usamos cookies para mejorar tu experiencia de navegación y analizar nuestro tráfico. See our privacy policy.