FlowHunt CLI Toolkit: Evaluación de Flujos Open Source con LLM como Juez
La nueva herramienta CLI open source de FlowHunt permite una evaluación integral de flujos con LLM como Juez, ofreciendo reportes detallados y evaluación automática de calidad para flujos de trabajo de IA.
FlowHunt CLI
Open Source
LLM as Judge
AI Evaluation
Flow Testing
AI Quality
Automation
CLI Tools
AI Development
Testing Framework
Nos entusiasma anunciar el lanzamiento de la Herramienta CLI de FlowHunt: nuestra nueva herramienta de línea de comandos open source diseñada para revolucionar la forma en que los desarrolladores evalúan y prueban flujos de IA. Esta potente herramienta lleva capacidades de evaluación de flujos de nivel empresarial a la comunidad open source, con reportes avanzados y nuestra innovadora implementación de “LLM como Juez”.
Presentamos la Herramienta CLI de FlowHunt
La Herramienta CLI de FlowHunt representa un avance significativo en las pruebas y evaluación de flujos de trabajo de IA. Ya disponible en GitHub
, esta herramienta open source proporciona a los desarrolladores herramientas completas para:
Evaluación de Flujos: Pruebas y evaluaciones automatizadas de flujos de trabajo de IA
Reportes Avanzados: Análisis detallado con desglose de resultados correctos e incorrectos
LLM como Juez: Evaluación sofisticada impulsada por IA usando nuestra propia plataforma FlowHunt
Métricas de Desempeño: Información integral sobre el comportamiento y precisión de los flujos
La herramienta encarna nuestro compromiso con la transparencia y el desarrollo impulsado por la comunidad, haciendo accesibles técnicas avanzadas de evaluación de IA a desarrolladores de todo el mundo.
El Poder de LLM como Juez
Una de las características más innovadoras de nuestra herramienta CLI es la implementación de “LLM como Juez”. Este enfoque utiliza inteligencia artificial para evaluar la calidad y corrección de las respuestas generadas por IA; esencialmente, permite que una IA juzgue el desempeño de otra IA con capacidades de razonamiento sofisticadas.
Cómo Construimos LLM como Juez con FlowHunt
Lo que hace única a nuestra implementación es que usamos FlowHunt para crear el propio flujo de evaluación. Este enfoque meta demuestra la potencia y flexibilidad de nuestra plataforma, al tiempo que proporciona un sistema de evaluación robusto. El flujo LLM como Juez consta de varios componentes interconectados:
1. Plantilla de Prompt: Elabora el prompt de evaluación con criterios específicos 2. Generador de Salida Estructurada: Procesa la evaluación usando un LLM 3. Analizador de Datos: Formatea la salida estructurada para el reporte 4. Salida de Chat: Presenta los resultados finales de la evaluación
El Prompt de Evaluación
En el corazón de nuestro sistema LLM como Juez hay un prompt cuidadosamente diseñado que garantiza evaluaciones consistentes y fiables. Esta es la plantilla principal que utilizamos:
Se te dará una pareja de RESPUESTA y REFERENCIA.
Tu tarea es proporcionar lo siguiente:
1. una puntuación 'total_rating': qué tan cerca está la RESPUESTA de la REFERENCIA
2. una etiqueta binaria 'correctness', que puede ser 'correcta' o 'incorrecta', que define si la RESPUESTA es correcta o no
3. un 'reasoning', que describe la razón detrás de tu elección de puntuación y la corrección/incorrectitud de la RESPUESTA
Una RESPUESTA es correcta cuando es igual a la REFERENCIA en todos los hechos y detalles, aunque esté redactada de forma diferente. La RESPUESTA es incorrecta si contradice la REFERENCIA, cambia u omite detalles. Está bien si la RESPUESTA tiene más detalles que la REFERENCIA.
'Total rating' es una escala del 1 al 4, donde 1 significa que la RESPUESTA no es igual a la REFERENCIA en absoluto y 4 significa que la RESPUESTA es igual a la REFERENCIA en todos los hechos y detalles, aunque esté redactada de forma diferente.
Esta es la escala que debes usar para construir tu respuesta:
1: La RESPUESTA contradice completamente la REFERENCIA, añade afirmaciones adicionales, cambia u omite detalles
2: La RESPUESTA apunta al mismo tema pero los detalles se omiten o cambian completamente en comparación con la REFERENCIA
3: Las referencias de la RESPUESTA no son completamente correctas, pero los detalles son bastante cercanos a los mencionados en la REFERENCIA. Está bien si hay detalles añadidos en la RESPUESTA en comparación con la REFERENCIA.
4: La RESPUESTA es igual a la REFERENCIA en todos los hechos y detalles, aunque esté redactada de forma diferente. Está bien si hay detalles añadidos en la RESPUESTA en comparación con la REFERENCIA. Si hay fuentes disponibles en la REFERENCIA, deben estar exactamente igual en la RESPUESTA.
REFERENCIA
===
{target_response}
===
RESPUESTA
===
{actual_response}
===
Este prompt garantiza que nuestro juez LLM proporcione:
Puntuación numérica (escala 1-4) para análisis cuantitativo
Clasificación binaria de corrección para métricas claras de aprobado/reprobado
Razonamiento detallado para transparencia y depuración
¿Listo para hacer crecer tu negocio?
Comienza tu prueba gratuita hoy y ve resultados en días.
Nuestro flujo LLM como Juez demuestra un diseño sofisticado de flujos de IA usando el constructor visual de FlowHunt. Así funcionan los componentes en conjunto:
1. Procesamiento de Entrada
El flujo comienza con un componente Entrada de Chat que recibe la solicitud de evaluación, la cual contiene tanto la respuesta real como la de referencia.
2. Construcción del Prompt
El componente Plantilla de Prompt construye dinámicamente el prompt de evaluación:
Insertando la respuesta de referencia en el campo {target_response}
Insertando la respuesta real en el campo {actual_response}
Aplicando los criterios de evaluación integrales
3. Evaluación por IA
El Generador de Salida Estructurada procesa el prompt usando un LLM seleccionado y genera una salida estructurada que contiene:
El componente Analizar Datos formatea la salida estructurada en un formato legible, y el componente Salida de Chat presenta los resultados finales de la evaluación.
Capacidades Avanzadas de Evaluación
El sistema LLM como Juez ofrece varias capacidades avanzadas que lo hacen especialmente eficaz para la evaluación de flujos de IA:
Comprensión Matizada
A diferencia de la simple coincidencia de cadenas, nuestro juez LLM entiende:
Equivalencia semántica: Reconoce cuando diferentes redacciones transmiten el mismo significado
Precisión factual: Identifica contradicciones u omisiones en los detalles
Completitud: Evalúa si las respuestas contienen toda la información necesaria
Puntuación Flexible
La escala de 4 puntos proporciona una evaluación granular:
Puntuación 4: Coincidencia semántica perfecta con todos los hechos preservados
Puntuación 3: Coincidencia cercana con pequeñas discrepancias, pero detalles añadidos aceptables
Puntuación 2: Mismo tema pero cambios u omisiones significativos de detalles
Puntuación 1: Contradicción total o errores factuales graves
Razonamiento Transparente
Cada evaluación incluye razonamiento detallado, lo que permite:
Comprender por qué se asignaron puntuaciones específicas
Depurar problemas de desempeño de los flujos
Mejorar la ingeniería de prompts con base en la retroalimentación de la evaluación
Únete a nuestro boletín
Obtén los últimos consejos, tendencias y ofertas gratis.
Funciones de Reporte Integral
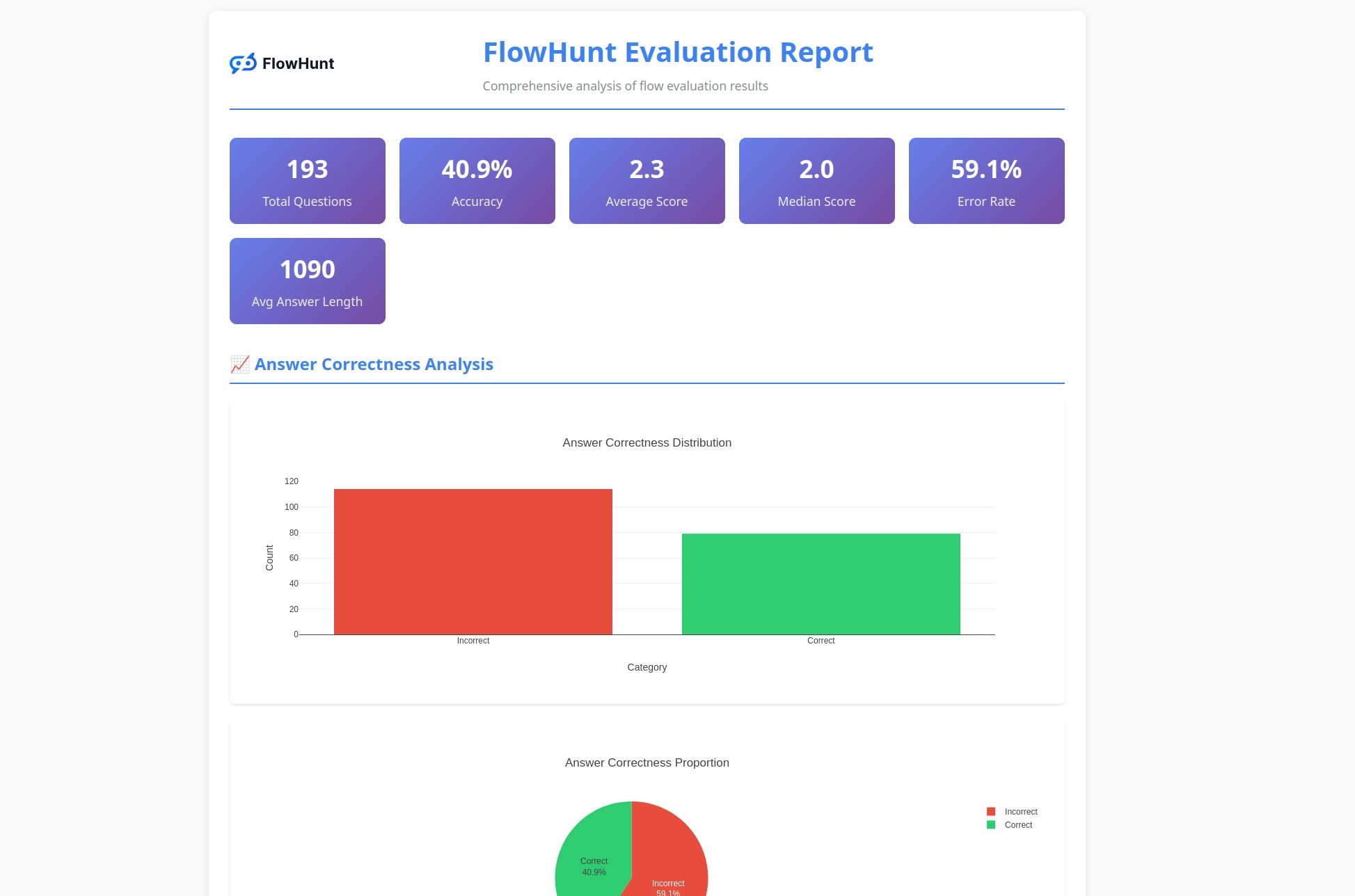
La herramienta CLI genera reportes detallados que ofrecen información práctica sobre el desempeño de los flujos:
Análisis de Corrección
Clasificación binaria de todas las respuestas como correctas o incorrectas
Porcentaje de precisión a través de los casos de prueba
Identificación de patrones comunes de fallos
Distribución de Puntuaciones
Análisis estadístico de las puntuaciones (escala 1-4)
Métricas promedio de desempeño
Análisis de varianza para identificar problemas de consistencia
Registros Detallados de Razonamiento
Razonamiento completo para cada evaluación
Categorización de problemas comunes
Recomendaciones para mejorar los flujos
Cómo Empezar con la Herramienta CLI de FlowHunt
¿Listo para empezar a evaluar tus flujos de IA con herramientas de nivel profesional? Así puedes comenzar:
Instalación Rápida
Instalación en una línea (Recomendada) para macOS y Linux:
La herramienta CLI se integra perfectamente con la plataforma FlowHunt, permitiéndote:
Evaluar flujos construidos en el editor visual de FlowHunt
Acceder a modelos avanzados de LLM para la evaluación
Usar tus flujos de juez existentes para evaluación automatizada
Exportar resultados para análisis posterior
El Futuro de la Evaluación de Flujos de IA
El lanzamiento de nuestra herramienta CLI representa más que una nueva herramienta: es una visión de futuro para el desarrollo de IA donde:
La calidad es medible: Técnicas avanzadas de evaluación hacen que el desempeño de la IA sea cuantificable y comparable.
Las pruebas son automáticas: Frameworks de pruebas integrales reducen el esfuerzo manual y mejoran la fiabilidad.
La transparencia es el estándar: Razonamientos y reportes detallados hacen que el comportamiento de la IA sea comprensible y depurable.
La comunidad impulsa la innovación: Las herramientas open source permiten la mejora colaborativa y el intercambio de conocimiento.
Compromiso Open Source
Al hacer open source la Herramienta CLI de FlowHunt, demostramos nuestro compromiso con:
Desarrollo Comunitario: Permitimos que desarrolladores de todo el mundo contribuyan y mejoren la herramienta
Transparencia: Hacemos nuestras metodologías de evaluación abiertas y auditables
Accesibilidad: Ofrecemos herramientas de nivel empresarial a desarrolladores sin importar el presupuesto
Innovación: Fomentamos el desarrollo colaborativo de nuevas técnicas de evaluación
Conclusión
La Herramienta CLI de FlowHunt con LLM como Juez representa un avance significativo en las capacidades de evaluación de flujos de IA. Al combinar lógica de evaluación sofisticada con reportes integrales y accesibilidad open source, empoderamos a los desarrolladores para construir sistemas de IA mejores y más fiables.
El enfoque meta de usar FlowHunt para evaluar flujos de FlowHunt demuestra la madurez y flexibilidad de nuestra plataforma, al tiempo que provee una herramienta poderosa para la comunidad de desarrollo de IA en general.
Ya sea que estés construyendo simples chatbots o sistemas multiagente complejos, la Herramienta CLI de FlowHunt te provee la infraestructura de evaluación que necesitas para asegurar calidad, fiabilidad y mejora continua.
¿Listo para llevar tu evaluación de flujos de IA al siguiente nivel? Visita nuestro repositorio en GitHub
para comenzar hoy mismo con la Herramienta CLI de FlowHunt y experimenta el poder de LLM como Juez por ti mismo.
El futuro del desarrollo de IA ya está aquí – y es open source.
Preguntas frecuentes
¿Qué es la Herramienta CLI de FlowHunt?
La Herramienta CLI de FlowHunt es una herramienta de línea de comandos open source para evaluar flujos de IA con capacidades de reporte integral. Incluye funciones como evaluación LLM como Juez, análisis de resultados correctos/incorrectos y métricas de desempeño detalladas.
¿Cómo funciona LLM como Juez en FlowHunt?
LLM como Juez utiliza un flujo de IA sofisticado construido en FlowHunt para evaluar otros flujos. Compara las respuestas reales con las respuestas de referencia, proporcionando puntuaciones, evaluaciones de corrección y razonamientos detallados para cada evaluación.
¿Dónde puedo acceder a la Herramienta CLI de FlowHunt?
La Herramienta CLI de FlowHunt es open source y está disponible en GitHub en https://github.com/yasha-dev1/flowhunt-toolkit. Puedes clonarla, contribuir y usarla libremente para tus necesidades de evaluación de flujos de IA.
¿Qué tipo de reportes genera la herramienta CLI?
La herramienta genera reportes integrales que incluyen desglose de resultados correctos/incorrectos, evaluaciones con LLM como Juez con puntuaciones y razonamientos, métricas de desempeño y análisis detallado del comportamiento de los flujos en distintos casos de prueba.
¿Puedo usar el flujo LLM como Juez para mis propias evaluaciones?
¡Sí! El flujo LLM como Juez está construido con la plataforma de FlowHunt y puede adaptarse a diversos escenarios de evaluación. Puedes modificar la plantilla de prompt y los criterios de evaluación según tus casos de uso específicos.
Yasha es un talentoso desarrollador de software especializado en Python, Java y aprendizaje automático. Yasha escribe artículos técnicos sobre IA, ingeniería de prompts y desarrollo de chatbots.
Yasha Boroumand
CTO, FlowHunt
Prueba la Evaluación Avanzada de Flujos de FlowHunt
Crea y evalúa flujos de IA sofisticados con la plataforma de FlowHunt. Empieza hoy mismo a crear flujos que puedan juzgar otros flujos.
Actualizaciones de FlowHunt Julio 2025: FlowHunt MCP, SSO, Integración con Odoo y Más
FlowHunt presenta importantes actualizaciones, incluyendo servidores MCP personalizados, inicio de sesión SSO para clientes empresariales, integración con Odoo,...
Este artículo explica cómo conectar FlowHunt con Langfuse para obtener una observabilidad integral, rastrear el rendimiento de los flujos de trabajo de IA y apr...
Automatiza la planificación de lecciones, revisiones de literatura, calificación y flujos de trabajo de investigación con agentes de IA, sin necesidad de código...
9 min de lectura
Consentimiento de Cookies Usamos cookies para mejorar tu experiencia de navegación y analizar nuestro tráfico. See our privacy policy.