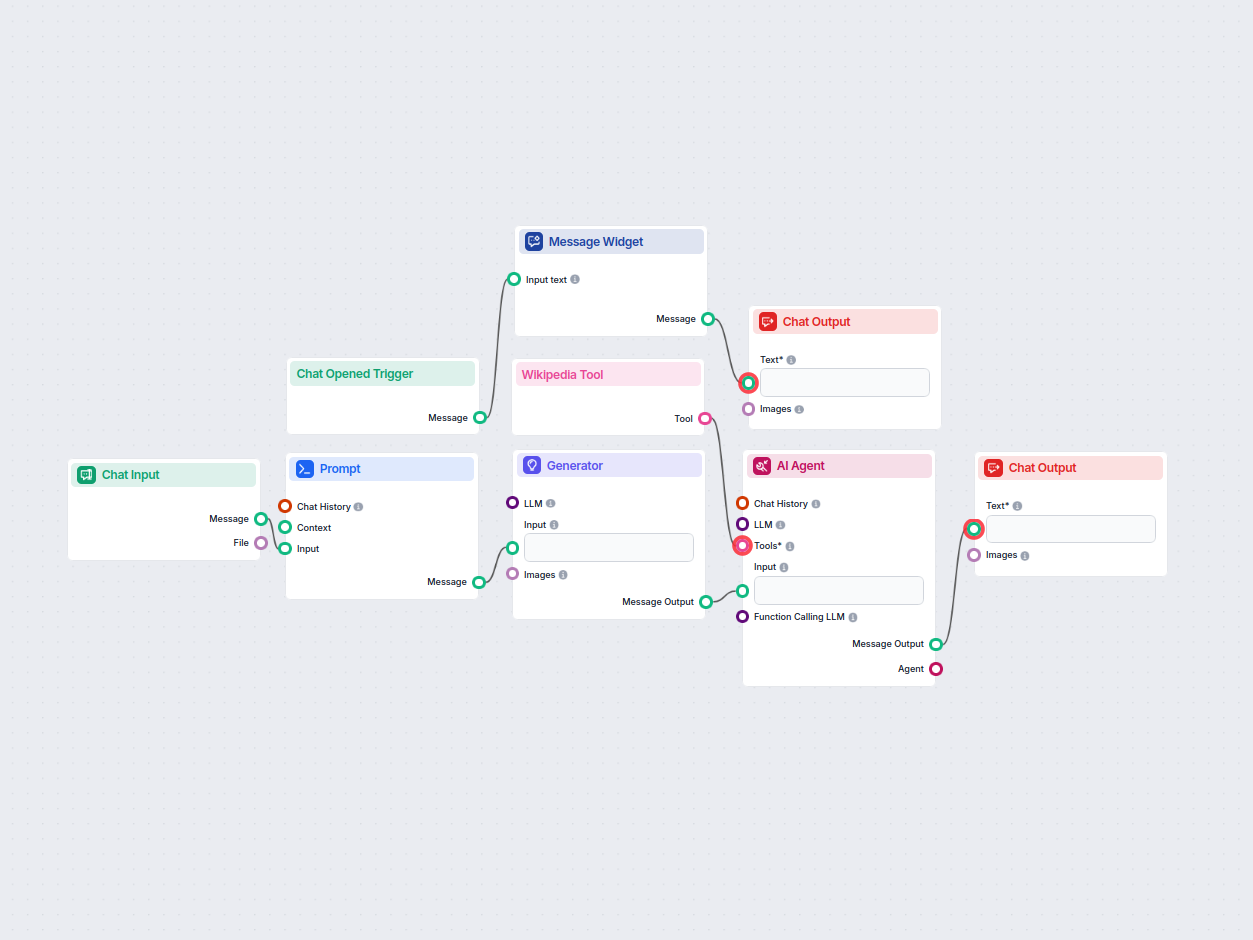
Aperçu
L’assistant Wikipedia RIG (Retrieval Interleaved Generator) est un flux de travail automatisé conçu pour répondre aux questions des utilisateurs en générant des réponses initiales, en identifiant les données factuelles nécessaires, en récupérant des informations depuis Wikipedia et en affinant ses réponses avec des citations précises pour chaque section. Son objectif principal est de fournir des réponses fondées sur des sources vérifiables et de spécifier exactement quelles sections et sources ont été utilisées, ce qui le rend particulièrement utile pour la recherche, la vérification des faits et l’enseignement.
Fonctionnement du flux de travail
Démarrage du chat & message de bienvenue
- Lorsqu’une session de chat est ouverte, l’utilisateur reçoit un message de bienvenue expliquant l’objectif du flux : fournir des réponses fiables et sourcées. Cela permet de définir les attentes concernant la qualité et la transparence des réponses.
Saisie de la question utilisateur
- L’utilisateur soumet une question via le champ de saisie du chat. Cette entrée est capturée et transmise pour traitement.
Génération du prompt
- Le flux de travail inclut un modèle de prompt qui prend la question de l’utilisateur et construit un prompt détaillé. Ce prompt instruit le système de :
- Générer une réponse brouillon, même en utilisant des données fictives si besoin.
- Pour chaque section de la réponse, spécifier quelle source externe (comme Wikipedia) ou base de connaissances interne doit être utilisée pour vérifier et affiner cette section.
- Inclure des requêtes de recherche pour Wikipedia afin de récupérer la bonne information pour chaque section.
Exemple :
Saisie utilisateur : Quels pays sont en tête en termes d'énergie renouvelable ?
Sortie brouillon : Les pays en tête sont la Norvège, la Suède, le Portugal [Recherche sur Wikipedia : "Top Countries in renewable Energy"]...
Génération de la réponse initiale
- À l’aide d’un générateur de modèle linguistique, le système crée un brouillon de réponse basé sur le prompt, en mettant en évidence les endroits où des données factuelles doivent être insérées et quelles sources utiliser pour leur vérification.
Récupération des données & Affinage de la réponse
- Un agent IA reçoit la réponse brouillon et utilise l’outil Wikipedia pour rechercher sur Wikipedia les requêtes spécifiées.
- Pour chaque section de la réponse, l’agent récupère les données factuelles pertinentes depuis Wikipedia et remplace le contenu brouillon ou fictif.
- Chaque section est affinée pour inclure un lien direct vers l’article Wikipedia exact ou la section utilisée, assurant ainsi transparence et facilité de vérification.
L’agent est instruit d’éviter les phrases génériques ou inutiles, en se concentrant uniquement sur le contenu concis et factuel.
Sortie finale
- La réponse entièrement affinée, avec chaque section ancrée dans une source Wikipedia spécifique (et liens fournis en ligne), est affichée à l’utilisateur dans l’interface de chat.
Structure du flux de travail
| Étape | Composant | Rôle |
|---|
| 1 | Déclencheur d’ouverture du chat | Détecte une nouvelle session de chat et déclenche le message de bienvenue |
| 2 | Widget de message | Affiche la salutation initiale et les instructions |
| 3 | Saisie de chat | Accepte la question de l’utilisateur |
| 4 | Modèle de prompt | Formate le prompt avec instructions pour la réponse brouillon + sources |
| 5 | Générateur | Produit la réponse brouillon initiale (avec espaces réservés) |
| 6 | Outil Wikipedia | Permet la récupération de données depuis Wikipedia |
| 7 | Agent IA | Affine le brouillon, récupère les faits, insère citations/liens |
| 8 | Sortie de chat | Présente la réponse finale, ancrée, à l’utilisateur |
Fonctionnalités clés et avantages
- Transparence des sources : Chaque section de la réponse précise clairement quelle page ou section Wikipedia a été utilisée, avec des liens directs pour vérification.
- Automatisation et passage à l’échelle : Le flux automatise la rédaction, la vérification et l’affinage des réponses, ce qui permet de traiter efficacement de nombreux besoins en questions-réponses.
- Qualité de sortie pour la recherche : En ancrant chaque affirmation à une source externe vérifiable, le système produit des réponses adaptées à des contextes académiques, professionnels et d’entreprise.
- Personnalisation : Si besoin, des sources internes peuvent être intégrées en complément de Wikipedia, rendant le système adaptable à la récupération de données spécifiques à une organisation.
Cas d’utilisation
- Assistants pédagogiques : Fournir aux étudiants des réponses toujours sourcées.
- Bots de vérification des faits : Vérifier instantanément les informations et présenter les sources sans recherche manuelle.
- Support client : Fournir des informations sur l’entreprise ou les produits avec une provenance des données claire.
- Création de contenu : Les rédacteurs et journalistes peuvent obtenir des brouillons de contenu avec références intégrées pour un développement ultérieur.
Résumé
Ce flux de travail permet aux utilisateurs d’obtenir des réponses fiables et bien référencées en alternant étapes de génération et de récupération d’informations. Il est particulièrement utile partout où l’exactitude factuelle, la transparence et l’attribution des sources sont primordiales. Sa conception modulaire et automatisée le rend hautement évolutif pour les organisations souhaitant automatiser la recherche et les tâches de questions-réponses à grande échelle.