Prompt
Créer un modèle de prompt avec variables dynamiques pour le LLM, prenant en charge les champs tels que {input}, {human_input}, {context}, {chat_history}, {syste...
Un chatbot en temps réel qui utilise la recherche Google restreinte à votre propre domaine, récupère le contenu web pertinent et exploite OpenAI LLM pour répondre aux questions des utilisateurs avec des informations à jour. Idéal pour fournir des réponses précises et spécifiques à un domaine dans le support client ou les portails d’information.
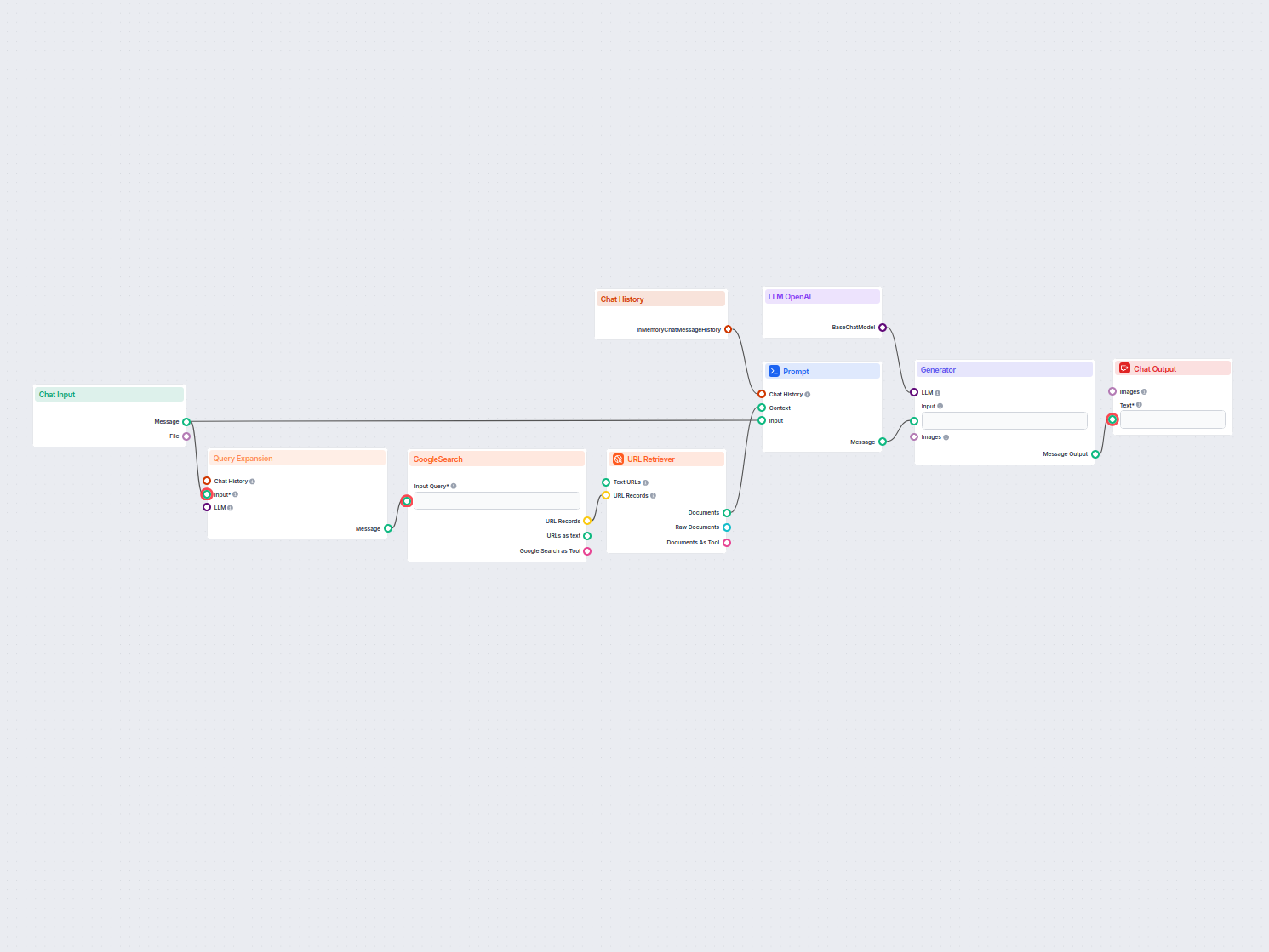

Flux
Créer un modèle de prompt avec variables dynamiques pour le LLM, prenant en charge les champs tels que {input}, {human_input}, {context}, {chat_history}, {syste...
Voici une liste complète de tous les composants utilisés dans ce flux pour atteindre sa fonctionnalité. Les composants sont les éléments de base de chaque Flux IA. Ils vous permettent de créer des interactions complexes et d'automatiser des tâches en connectant diverses fonctionnalités. Chaque composant sert un objectif spécifique, comme la gestion des entrées utilisateur, le traitement de données ou l'intégration avec des services externes.
Le composant Entrée de Chat dans FlowHunt initie les interactions utilisateur en capturant les messages depuis le Playground. Il sert de point de départ pour les flux, permettant au workflow de traiter aussi bien des entrées textuelles que des fichiers.
Découvrez le composant Chat Output dans FlowHunt — finalisez les réponses du chatbot avec des sorties flexibles et multiples. Essentiel pour une finalisation fluide des flux et la création de chatbots IA avancés et interactifs.
Le composant Widget Bouton dans FlowHunt transforme du texte ou une entrée en boutons interactifs et cliquables au sein de votre flux de travail. Parfait pour créer des interfaces utilisateur dynamiques, recueillir des choix d'utilisateurs et améliorer l'engagement dans des chatbots dopés à l'IA ou des processus automatisés.
Le composant Déclencheur d’ouverture de chat détecte le début d’une session de chat, permettant aux workflows de réagir instantanément dès qu’un utilisateur ouvre le chat. Il initie les flux avec le premier message, ce qui le rend essentiel pour créer des chatbots interactifs et réactifs.
Le composant d'Historique de Chat dans FlowHunt permet aux chatbots de se souvenir des messages précédents, assurant ainsi des conversations cohérentes et une expérience client améliorée tout en optimisant l’utilisation de la mémoire et des jetons.
Découvrez comment le composant Prompt de FlowHunt vous permet de définir le rôle et le comportement de votre bot IA, garantissant des réponses pertinentes et personnalisées. Personnalisez les prompts et modèles pour des flux de chatbot efficaces et sensibles au contexte.
Découvrez le composant Générateur dans FlowHunt : une génération de texte puissante pilotée par l’IA utilisant le modèle LLM de votre choix. Créez facilement des réponses dynamiques de chatbot en combinant des prompts, des instructions système optionnelles et même des images en entrée, en faisant un outil central pour construire des workflows intelligents et conversationnels.
FlowHunt prend en charge des dizaines de modèles de génération de texte, y compris ceux d’OpenAI. Voici comment utiliser ChatGPT dans vos outils IA et chatbots.
L'expansion de requête dans FlowHunt améliore la compréhension du chatbot en trouvant des synonymes, en corrigeant les fautes d'orthographe et en assurant des réponses cohérentes et précises aux requêtes des utilisateurs.
Le composant GoogleSearch de FlowHunt améliore la précision des chatbots grâce au Retrieval-Augmented Generation (RAG) pour accéder à des connaissances à jour depuis Google. Contrôlez les résultats avec des options comme la langue, le pays et les préfixes de requête pour des réponses précises et pertinentes.
Débloquez le contenu web dans vos flux de travail avec le composant Récupérateur d'URL. Extrayez et traitez sans effort le texte et les métadonnées de n'importe quelle liste d'URL—including articles web, documents, et plus encore. Prend en charge des options avancées comme l'OCR pour les images, l'extraction sélective de métadonnées et une mise en cache personnalisable, ce qui en fait l'outil idéal pour créer des flux et automatisations IA riches en connaissances.
Description du flux
Ce workflow met en œuvre un chatbot simple de type Retrieval-Augmented Generation (RAG) qui utilise la recherche Google en temps réel pour récupérer des informations à jour sur Internet — il peut notamment être personnalisé pour restreindre toutes les recherches à un domaine particulier. L’objectif principal est de créer un chatbot capable de répondre aux questions des utilisateurs en utilisant le contenu en ligne le plus pertinent et le plus récent, ce qui le rend particulièrement précieux dans les situations où les bases de connaissances statiques sont insuffisantes.
Le workflow est composé de plusieurs blocs modulaires, chacun représentant une capacité spécifique. Voici un aperçu de la structure et des fonctionnalités du workflow :
| Composant | Rôle |
|---|---|
| Saisie du chat | Reçoit les questions et messages des utilisateurs. |
| Historique du chat | Conserve l’historique de la conversation pour des réponses tenant compte du contexte. |
| Expansion de requête | Paraphrase l’entrée utilisateur en plusieurs requêtes alternatives pour améliorer la couverture de recherche. |
| Recherche Google | Effectue des recherches sur Google, restreintes par un préfixe de domaine personnalisable. |
| Récupérateur d’URL | Extrait le contenu des URL renvoyées par la recherche Google. |
| Modèle de prompt | Structure le contexte, l’entrée utilisateur et l’historique pour le modèle de langage. |
| OpenAI LLM | Génère des réponses à l’aide d’un modèle de langage (ex. : GPT-3/4). |
| Générateur | Interroge le LLM avec le prompt et le contexte pour produire la réponse. |
| Sortie du chat | Affiche les réponses du chatbot à l’utilisateur. |
| Widgets de boutons | Propose des exemples de requêtes rapides à essayer d’un simple clic. |
| Déclencheur d’ouverture du chat | Initialise la conversation et affiche les boutons de démarrage rapide. |
Lorsqu’un utilisateur ouvre le chat, le Déclencheur d’ouverture du chat s’active. Cela initialise l’interface de discussion et présente plusieurs Widgets de boutons avec des exemples de questions (ex. : “quel dinosaure a 500 dents ?”). Lorsqu’un utilisateur clique sur un bouton ou saisit un message personnalisé via la Saisie du chat, le workflow se déroule comme suit :
Expansion de la requête : L’entrée de l’utilisateur est paraphrasée en plusieurs versions pour maximiser les chances d’obtenir des résultats pertinents.
Recherche Google : Les requêtes développées sont envoyées à Google. Par défaut, la recherche est limitée à un domaine spécifique (défini par le champ query_prefix, ex. : site: www.VOTREDOMAINE.com), permettant de concentrer les connaissances du chatbot sur votre propre site ou toute source de confiance.
Récupérateur d’URL : Le workflow récupère le contenu des principaux résultats de recherche (URL) sous forme de documents complets.
Assemblage du prompt : Le contenu récupéré, l’entrée utilisateur et l’historique du chat sont combinés grâce au composant Modèle de prompt pour fournir un contexte riche à la réponse.
Génération par modèle de langage : Le prompt est envoyé au OpenAI LLM, qui génère une réponse cohérente et contextuelle.
Affichage de la réponse : La réponse générée est affichée à l’utilisateur via la Sortie du chat.
query_prefix, vous pouvez vous assurer que le chatbot source ses informations uniquement à partir de votre site ou base de connaissances de confiance, améliorant la fiabilité des réponses.| Étape | Description |
|---|---|
| Saisie utilisateur | L’utilisateur tape une question ou clique sur un bouton rapide |
| Expansion de la requête | L’entrée est paraphrasée pour une couverture de recherche plus large |
| Recherche Google | Les recherches sont effectuées sur Google, limitées à un domaine donné |
| Récupération du contenu des URL | Le contenu des premiers résultats de recherche est récupéré |
| Construction du prompt | L’entrée utilisateur, les résultats de recherche et l’historique de chat sont compilés dans un prompt |
| Génération LLM | OpenAI LLM génère une réponse en utilisant tout le contexte |
| Sortie | La réponse est affichée à l’utilisateur |
query_prefix dans le composant Recherche Google (ex. : site: www.VOTREDOMAINE.com).En automatisant la recherche, la récupération et la génération de réponses, ce workflow économise un temps de recherche manuel et garantit que les utilisateurs obtiennent toujours les informations les plus actuelles et pertinentes disponibles.
Nous aidons les entreprises comme la vôtre à développer des chatbots intelligents, des serveurs MCP, des outils d'IA ou d'autres types d'automatisation par IA pour remplacer l'humain dans les tâches répétitives de votre organisation.
Un chatbot alimenté par l’IA qui fournit des réponses précises aux questions des utilisateurs en se basant strictement sur le contenu d’un document Google fourn...
Un chatbot IA qui fournit instantanément des réponses actualisées à toute question en recherchant sur Google et en récupérant le contenu pertinent des sites web...
Un puissant chatbot IA qui répond aux questions des utilisateurs en temps réel en récupérant et synthétisant des informations depuis Google, Reddit, Wikipedia, ...
Consentement aux Cookies
Nous utilisons des cookies pour améliorer votre expérience de navigation et analyser notre trafic. See our privacy policy.