Ingénierie du Contexte : Le Guide Définitif 2025 pour Maîtriser la Conception de Systèmes IA
Plongez au cœur de l’ingénierie du contexte pour l’IA. Ce guide aborde les principes clés, du prompt vs contexte aux stratégies avancées comme la gestion de la mémoire, le context rot et la conception multi-agents.
AI
LLM
System Design
Agents
Context Engineering
Prompt Engineering
RAG
Le paysage du développement IA a connu une profonde transformation. Là où l’on se concentrait autrefois sur la création du prompt parfait, nous faisons aujourd’hui face à un défi bien plus complexe : construire des architectures d’information complètes qui entourent et renforcent nos modèles de langage.
Ce changement marque l’évolution du prompt engineering vers l’ingénierie du contexte—et représente rien de moins que l’avenir du développement IA appliqué. Les systèmes qui apportent une réelle valeur aujourd’hui ne reposent pas sur des prompts magiques. Ils réussissent parce que leurs architectes orchestrent des écosystèmes d’information complets.
Andrej Karpathy a parfaitement résumé cette évolution en décrivant l’ingénierie du contexte comme l’art de remplir soigneusement la fenêtre de contexte avec l’information la plus pertinente, au moment le plus opportun. Cette déclaration apparemment simple révèle une vérité fondamentale : le LLM n’est plus la vedette. Il est un composant critique d’un système soigneusement conçu, où chaque information—chaque fragment de mémoire, chaque description d’outil, chaque document récupéré—a été placé délibérément pour maximiser les résultats.
Qu’est-ce que l’Ingénierie du Contexte ?
Perspective Historique
Les racines de l’ingénierie du contexte sont plus anciennes qu’on ne le pense. Alors que les discussions autour du prompt engineering ont explosé entre 2022 et 2023, les concepts fondateurs de l’ingénierie du contexte sont apparus il y a plus de vingt ans, issus de l’informatique omniprésente et de la recherche sur l’interaction homme-machine.
Dès 2001, Anind K. Dey posait une définition remarquablement visionnaire : le contexte englobe toute information aidant à caractériser la situation d’une entité. Ce cadre précoce a jeté les bases de notre réflexion sur la compréhension machine des environnements.
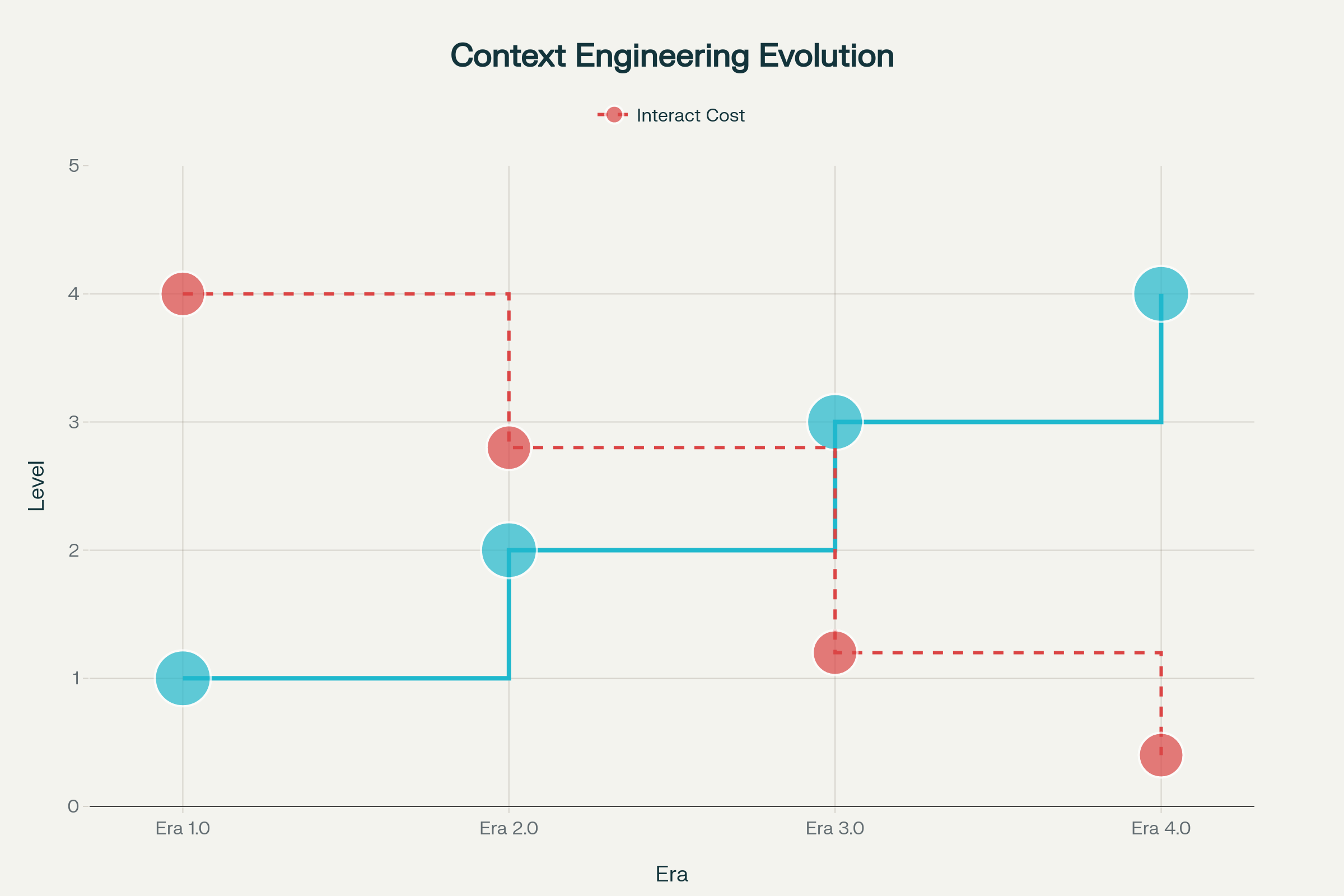
L’évolution de l’ingénierie du contexte s’est déroulée en plusieurs phases, chacune façonnée par les avancées de l’intelligence machine :
Ère 1.0 : Calcul Primitif (années 1990–2020) — Durant cette longue période, les machines ne traitaient que des entrées structurées et des signaux environnementaux simples. La charge de traduction du contexte en formats adaptés aux machines reposait entièrement sur l’humain. Pensez aux applications bureautiques, applis mobiles avec capteurs, ou chatbots rigides à arbres de réponses.
Ère 2.0 : Intelligence Centrée sur l’Agent (2020–Aujourd’hui) — La sortie de GPT-3 en 2020 a provoqué un changement de paradigme. Les grands modèles de langage ont apporté une véritable compréhension du langage naturel et la capacité à gérer des intentions implicites. Cette ère permet une collaboration authentique humain-agent, où ambiguïté et informations incomplètes deviennent gérables via des techniques avancées de compréhension du langage et d’apprentissage en contexte.
Ères 3.0 & 4.0 : Intelligence Humaine et Surhumaine (Futur) — Les prochaines vagues promettent des systèmes capables de percevoir et traiter des informations à haute entropie avec la fluidité humaine, puis d’aller au-delà de la simple réaction pour construire proactivement le contexte et révéler des besoins encore inexprimés par l’utilisateur.
Évolution de l’ingénierie du contexte à travers quatre ères : du calcul primitif à l’intelligence surhumaine
Définition Formelle
Au fond, l’ingénierie du contexte est la discipline systémique qui consiste à concevoir et optimiser la circulation des informations contextuelles à travers les systèmes IA—depuis la collecte initiale, leur stockage et gestion, jusqu’à leur utilisation pour améliorer la compréhension machine et l’exécution des tâches.
On peut exprimer cela mathématiquement comme une fonction de transformation :
$CE: (C, T) \rightarrow f_{context}$
Où :
C représente l’information contextuelle brute (entités et leurs caractéristiques)
T désigne la tâche cible ou le domaine applicatif
f_{context} produit la fonction de traitement du contexte résultante
Décomposer cela en termes pratiques révèle quatre opérations fondamentales :
Collecter les signaux contextuels pertinents via divers capteurs et canaux d’information
Stocker efficacement ces informations sur des systèmes locaux, infrastructures réseaux et plates-formes cloud
Gérer la complexité via le traitement intelligent du texte, des entrées multimodales et des relations complexes
Utiliser le contexte de manière stratégique, par filtrage de la pertinence, partage entre systèmes et adaptation aux besoins utilisateur
Pourquoi l’Ingénierie du Contexte est-elle Importante : Le Cadre de Réduction de l’Entropie
L’ingénierie du contexte répond à une asymétrie fondamentale dans la communication homme-machine. Lorsque nous dialoguons, nous comblons sans effort les lacunes conversationnelles grâce à la culture partagée, l’intelligence émotionnelle et la conscience situationnelle. Les machines, elles, n’ont aucune de ces capacités.
Ce fossé se manifeste sous forme d’entropie informationnelle. La communication humaine est efficace car nous supposons un vaste contexte partagé. Les machines requièrent que tout soit explicitement représenté. L’ingénierie du contexte vise fondamentalement à prétraiter le contexte pour les machines—compresser la complexité à haute entropie des intentions et situations humaines en représentations à faible entropie compréhensibles par la machine.
À mesure que l’intelligence machine progresse, cette réduction d’entropie s’automatise. Aujourd’hui, en ère 2.0, les ingénieurs orchestrent manuellement l’essentiel de cette réduction. Demain, les machines en prendront la charge de façon autonome. Mais le défi central reste : combler l’écart entre la complexité humaine et la compréhension machine.
Prompt Engineering vs Ingénierie du Contexte : Distinctions Clés
Une erreur fréquente est de confondre ces deux disciplines. En réalité, elles représentent des approches fondamentalement différentes de l’architecture des systèmes IA.
Le prompt engineering vise à optimiser l’instruction ou la requête individuelle pour façonner le comportement du modèle. Il s’agit d’optimiser la formulation, les exemples, et les schémas de raisonnement dans une interaction donnée.
L’ingénierie du contexte est une discipline systémique globale gérant tout ce que le modèle reçoit lors de l’inférence—y compris les prompts, mais aussi les documents récupérés, systèmes de mémoire, descriptions d’outils, informations d’état, etc.
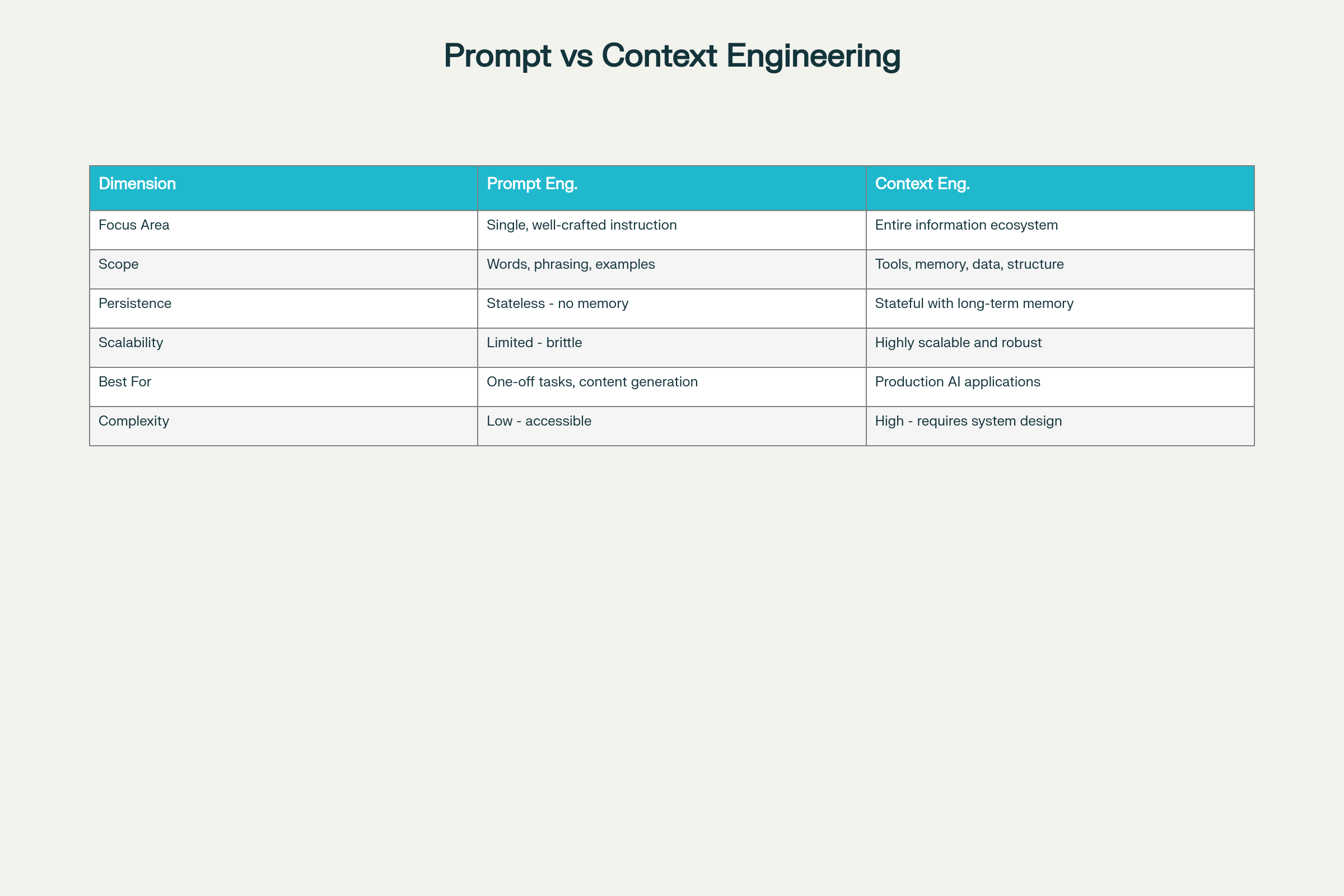
Prompt Engineering vs Ingénierie du Contexte : Principales différences et compromis
Exemple : Demander à ChatGPT de rédiger un courriel professionnel relève du prompt engineering. Construire une plateforme de service client qui conserve l’historique des conversations, accède aux informations de compte utilisateur et se souvient des tickets précédents—c’est de l’ingénierie du contexte.
Différences Clés sur Huit Dimensions :
Dimension
Prompt Engineering
Ingénierie du Contexte
Domaine
Optimisation d’une instruction
Écosystème d’information global
Portée
Mots, formulation, exemples
Outils, mémoire, architecture de données, structure
Persistance
Sans état—pas de mémoire
Avec état et mémoire à long terme
Scalabilité
Limité et fragile à grande échelle
Très scalable et robuste
Idéal pour
Tâches ponctuelles, génération de contenu
Applications IA en production
Complexité
Faible barrière à l’entrée
Élevée—demande expertise en conception de systèmes
Fiabilité
Imprévisible à l’échelle
Cohérent et fiable
Maintenance
Fragile aux changements
Modulaire et maintenable
Point crucial : Les applications LLM de production nécessitent essentiellement l’ingénierie du contexte, bien plus que des prompts ingénieux. Comme l’a observé Cognition AI, l’ingénierie du contexte est devenue la responsabilité principale des ingénieurs agents IA.
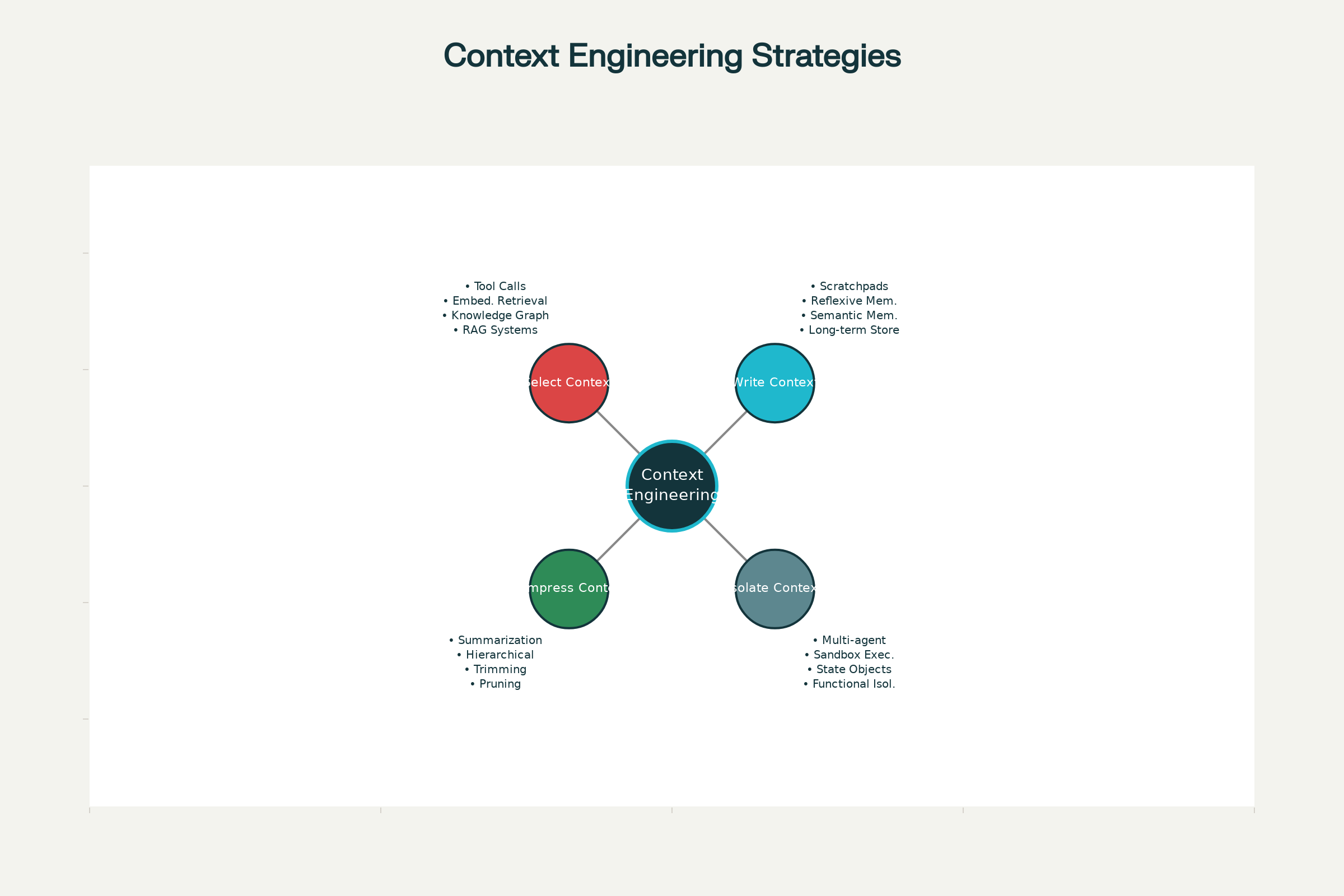
Les Quatre Stratégies Fondamentales de l’Ingénierie du Contexte
Dans les systèmes IA de pointe—de Claude et ChatGPT aux agents spécialisés d’Anthropic et autres laboratoires—quatre stratégies majeures de gestion du contexte se sont imposées. Elles peuvent être utilisées indépendamment ou combinées.
1. Écrire le Contexte : Persister l’Information hors de la Fenêtre de Contexte
Principe fondamental et élégant : inutile de demander au modèle de tout mémoriser. Conservez plutôt les informations critiques hors de la fenêtre de contexte, accessibles au besoin.
Les brouillons (scratchpads) offrent l’implémentation la plus intuitive. Comme les humains prennent des notes, les agents IA utilisent des brouillons pour sauvegarder des informations utiles ultérieurement. Cela peut aller d’un simple outil de prise de notes à des champs sophistiqués dans un objet d’état persistant à chaque étape d’exécution.
Le multi-agent researcher d’Anthropic en donne un bel exemple : le LeadResearcher élabore une stratégie et la sauvegarde en mémoire, sachant qu’au-delà de 200 000 tokens, la troncature surviendra et le plan doit être conservé.
Les mémoires étendent ce concept à travers les sessions. Au lieu de capturer l’information dans une tâche unique (mémoire session-scoped), les systèmes bâtissent des mémoires long terme qui persistent et évoluent au fil des interactions. Ce schéma est devenu la norme dans ChatGPT, Claude Code, Cursor, Windsurf, etc.
Des projets comme Reflexion ont introduit les mémoires réflexives—l’agent réfléchit à chaque tour et génère des souvenirs pour référence future. Les agents génératifs synthétisent périodiquement des mémoires à partir de retours passés.
Trois Types de Mémoires :
Épisodique : Exemples concrets de comportements/interactions passés (précieux pour few-shot learning)
Procédurale : Instructions/règles de comportement (garantissent la cohérence)
Sémantique : Faits et relations sur le monde (apportent des connaissances ancrées)
2. Sélectionner le Contexte : Récupérer la Bonne Information
Une fois l’information conservée, l’agent doit extraire ce qui est pertinent pour la tâche. Une mauvaise sélection peut être aussi néfaste qu’une absence de mémoire—le bruit perturbe le modèle ou provoque des hallucinations.
Mécanismes de Sélection Mémoire :
Les approches les plus simples incluent des fichiers toujours présents. Claude Code utilise CLAUDE.md pour les mémoires procédurales, Cursor et Windsurf des fichiers rules. Mais cette méthode ne passe pas à l’échelle quand l’agent accumule des centaines de faits et relations.
Pour de plus larges collections, on utilise le retraitement par embeddings et les graphes de connaissances. Le système encode mémoires et requête en vecteurs, puis retrouve les plus proches sémantiquement.
Or, comme Simon Willison l’a démontré à l’AIEngineer World’s Fair, cela peut échouer spectaculairement. ChatGPT a injecté inopinément sa localisation dans une image générée, illustrant qu’une ingénierie méticuleuse est cruciale.
La sélection d’outils pose aussi problème. Avec des dizaines/centaines d’outils, tout énumérer génère de la confusion—les descriptions se chevauchent, les modèles choisissent mal. Une solution efficace : appliquer RAG sur les descriptions. En ne récupérant que les outils pertinents, la précision de sélection triple.
La récupération de connaissances est le cas le plus riche. Les agents de code illustrent ce défi à grande échelle. Comme le note un ingénieur Windsurf, indexer le code ne suffit pas. Ils combinent indexation, recherche par embedding, parsing AST, chunking sémantique, recherche grep, graphe de connaissances et reranking par pertinence.
3. Compresser le Contexte : Garder l’Essentiel
Sur des tâches longues, le contexte s’accumule naturellement. Notes, sorties d’outils, historique… tout cela peut saturer la fenêtre de contexte. Les stratégies de compression distillent l’information en conservant l’essentiel.
La synthèse (summarization) est la technique principale. Claude Code propose « auto-compact »—à 95% de la fenêtre, il résume tout l’historique. Plusieurs stratégies existent :
Synthèse récursive : Résumer les résumés pour bâtir une hiérarchie compacte
Synthèse hiérarchique : Générer des résumés à plusieurs niveaux d’abstraction
Synthèse ciblée : Compresser des parties spécifiques (ex : résultats de recherche volumineux)
Cognition AI utilise des modèles fine-tunés pour la synthèse entre agents, montrant la profondeur de l’ingénierie requise.
La coupe du contexte (trimming) complète la synthèse. Plutôt que d’utiliser un LLM pour résumer, la coupe enlève des éléments selon des heuristiques—messages anciens, filtrage par importance, ou pruners entraînés comme Provence.
Point clé : Ce que vous retirez compte autant que ce que vous gardez. Un contexte ciblé de 300 tokens surpasse souvent un contexte non filtré de 113 000 tokens pour la conversation.
4. Isoler le Contexte : Répartir l’Information
Enfin, les stratégies d’isolation admettent que chaque tâche requiert des informations différentes. Plutôt que de tout concentrer dans une seule fenêtre, isolez le contexte dans des sous-systèmes spécialisés.
Les architectures multi-agents sont l’approche la plus courante. La librairie OpenAI Swarm est conçue autour de la « séparation des préoccupations »—chaque sous-agent gère des tâches dédiées avec ses outils, instructions et contexte.
Anthropic a montré que plusieurs agents à contextes isolés surpassent les systèmes mono-agent, chaque fenêtre étant optimisée pour une sous-tâche. Les sous-agents œuvrent en parallèle, explorant divers aspects d’une question.
Mais cela a un coût : Anthropic a observé une consommation de tokens jusqu’à 15 fois supérieure par rapport au mono-agent. Cela requiert orchestration, prompt engineering pour la planification, et coordination sophistiquée.
Les environnements sandbox offrent une autre stratégie. Chez HuggingFace, CodeAgent ne retourne pas du JSON à raisonner mais du code exécuté en sandbox. Seuls les retours utiles sont renvoyés au LLM, gardant les objets volumineux hors du contexte. Idéal pour les données visuelles et audio.
L’isolation par objet d’état est sans doute la technique la plus sous-estimée. L’état d’exécution d’un agent peut être un schéma structuré (ex : modèle Pydantic) à plusieurs champs. Un champ (ex : messages) est exposé au LLM, d’autres sont isolés pour un usage sélectif. Cela permet un contrôle précis sans complexité architecturale.
Quatre stratégies pour une ingénierie du contexte efficace dans les agents IA
Le Problème du Context Rot : Un Défi Majeur
Si l’augmentation de la longueur du contexte a été saluée, des recherches récentes révèlent une réalité troublante : une fenêtre plus longue n’entraîne pas nécessairement de meilleures performances.
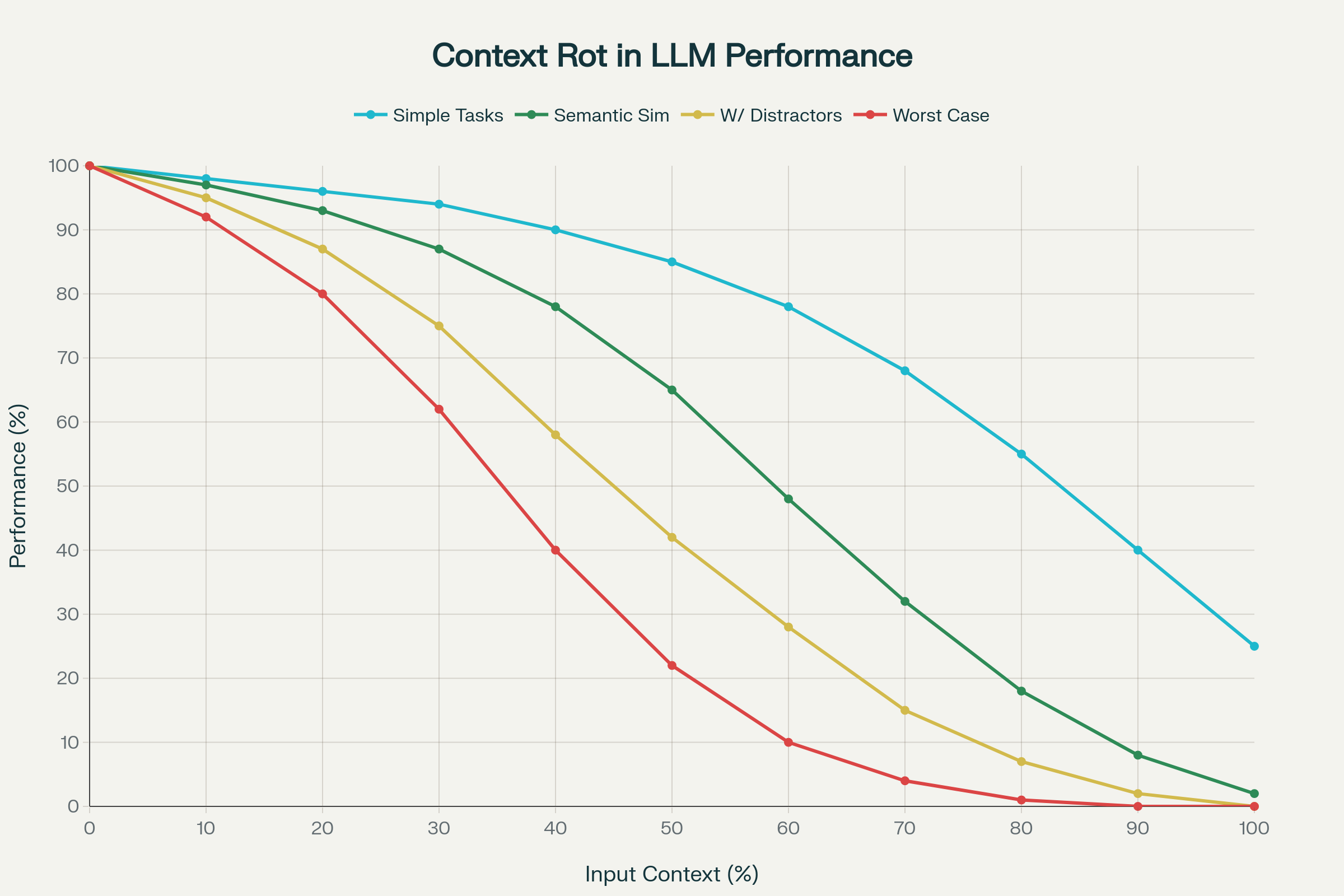
Une étude de référence sur 18 LLMs majeurs (dont GPT-4.1, Claude 4, Gemini 2.5, Qwen 3) a mis en évidence le context rot : la dégradation imprévisible et souvent sévère des performances à mesure que le contexte s’allonge.
Points Clés sur le Context Rot
1. Dégradation Non Linéaire
La performance ne décline pas de façon linéaire et prévisible. Des chutes brutales, propres au modèle et à la tâche, sont observées. Un modèle peut maintenir 95% de précision jusqu’à une certaine longueur, puis chuter soudainement à 60%. Ces « cliffs » sont imprévisibles et varient selon le modèle.
2. La Complexité Sémantique Amplifie le Context Rot
Des tâches simples (copie de mots répétés, récupération exacte) déclinent modérément. Mais quand il faut retrouver une information sémantiquement proche (« aiguille dans la botte de foin »), la performance plonge. Ajouter des distracteurs plausibles—proches mais incorrects—aggrave la précision.
3. Biais de Position et Effondrement de l’Attention
L’attention des transformers ne s’étend pas linéairement. Les tokens du début (effet de primauté) et de la fin (effet de récence) reçoivent plus d’attention. Dans les cas extrêmes, l’attention s’effondre et le modèle ignore une grande partie de l’entrée.
4. Comportements Spécifiques selon le Modèle
Chaque LLM manifeste des échecs particuliers à l’échelle :
GPT-4.1: hallucinations, répétition de tokens incorrects
Gemini 2.5: fragments ou ponctuations hors sujet
Claude Opus 4: refus de tâche, prudence excessive
5. Impact Réel en Conversation
Plus grave encore : sur le benchmark LongMemEval, les modèles accédant à la conversation complète (113k tokens) font mieux avec le segment ciblé de 300 tokens. Le context rot détériore récupération et raisonnement dans les dialogues réels.
Context Rot : Dégradation des performances avec l’augmentation du nombre de tokens sur 18 LLMs
Conséquences : La Qualité avant la Quantité
Le principal enseignement du context rot est sans appel : la quantité de tokens n’est pas le seul facteur de qualité. La manière dont le contexte est construit, filtré et présenté est tout aussi, sinon plus, essentielle.
Cela valide toute la discipline de l’ingénierie du contexte. Plutôt que de voir les grandes fenêtres comme une panacée, les meilleures équipes savent que la compression, la sélection et l’isolation du contexte sont indispensables pour maintenir la performance.
Ingénierie du Contexte en Pratique : Applications Réelles
Cas 1 : Systèmes Agents Multi-Tours (Claude Code, Cursor)
Claude Code et Cursor illustrent l’ingénierie du contexte de pointe pour l’assistance au code :
Collecte : Ces systèmes rassemblent le contexte de diverses sources—fichiers ouverts, structure du projet, historique d’édition, sortie du terminal, commentaires utilisateur.
Gestion : Plutôt que d’injecter tous les fichiers dans le prompt, ils compressent intelligemment. Claude Code utilise des résumés hiérarchiques. Le contexte est tagué par fonction (« fichier édité », « dépendance référencée », « message d’erreur »).
Utilisation : À chaque tour, le système sélectionne les fichiers/contenus pertinents, les présente de façon structurée et maintient des pistes séparées pour le raisonnement et la sortie visible.
Compression : À l’approche des limites, l’auto-compact résume la trajectoire des interactions en conservant les décisions clés.
Résultat : Ces outils restent utilisables sur de grands projets sans perte de performance, malgré les limites de fenêtre.
Cas 2 : Tongyi DeepResearch (Agent de Recherche Open Source)
Tongyi DeepResearch montre comment l’ingénierie du contexte permet des tâches complexes de recherche :
Pipeline de Synthèse de Données : Plutôt que de s’appuyer sur des données annotées humaines limitées, Tongyi utilise une synthèse sophistiquée pour créer des questions de niveau doctorat, avec complexification itérative.
Gestion du Contexte : Le système suit le paradigme IterResearch : à chaque étape, il reconstruit un espace de travail épuré avec seulement les sorties essentielles de l’étape précédente, évitant l’« asphyxie cognitive » due à l’accumulation de contexte.
Exploration Parallèle : Plusieurs agents opèrent en parallèle, chacun dans son contexte isolé, puis un agent de synthèse agrège leurs résultats.
Résultats : Tongyi DeepResearch rivalise avec des systèmes propriétaires comme DeepResearch d’OpenAI (score de 32,9 à Humanity’s Last Exam, 75 sur des benchmarks utilisateurs).
Cas 3 : Multi-Agent Researcher d’Anthropic
La recherche d’Anthropic illustre comment isolation et spécialisation améliorent les performances :
Architecture : Des sous-agents spécialisés s’occupent chacun d’une tâche (revue de littérature, synthèse, vérification) avec des fenêtres distinctes.
Bénéfices : Cette approche surpasse le mono-agent, chaque sous-agent ayant un contexte optimisé pour sa tâche.
Compromis : La qualité est supérieure, mais la consommation de tokens monte jusqu’à 15 fois celle du chat mono-agent.
En résumé : l’ingénierie du contexte implique des compromis entre qualité, rapidité et coût. Le bon équilibre dépend de l’application.
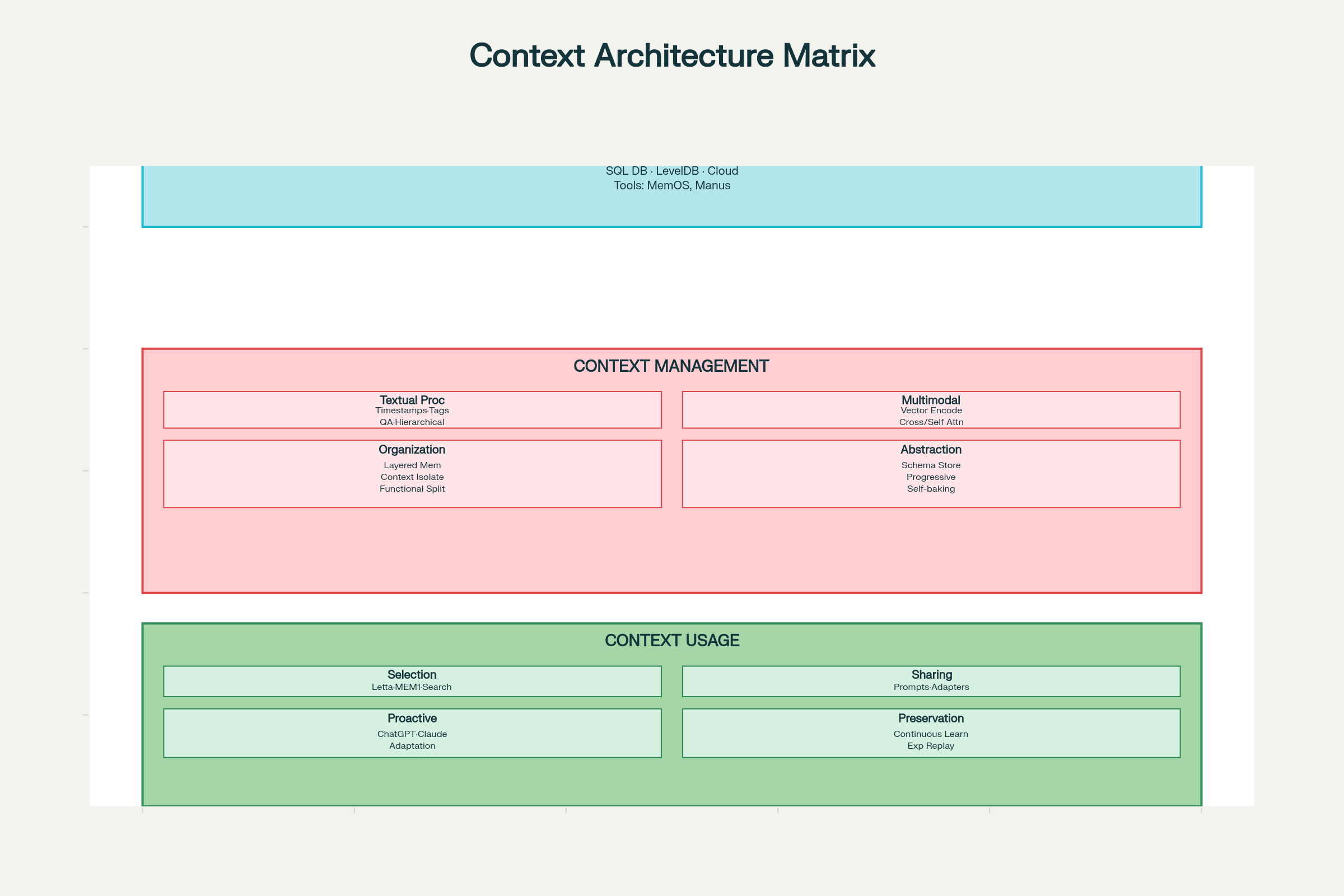
Le Cadre des Considérations de Conception
Mettre en œuvre une ingénierie du contexte efficace requiert une réflexion systématique sur trois axes : collecte et stockage, gestion, utilisation.
Considérations de conception en Ingénierie du Contexte : architecture et composants complets
Collecte & Stockage : Choix de Conception
Choix Technologiques :
Stockage Local (SQLite, LevelDB) : rapide, faible latence, agents côté client
Systèmes Distribués : pour l’échelle massive, redondance et tolérance aux pannes
Schémas de Conception :
MemOS : OS mémoire pour gestion unifiée
Manus : mémoire structurée à accès par rôle
Principe clé : Concevoir pour une récupération efficace, pas seulement un stockage efficace.
Gestion : Décisions de Conception
Traitement du Contexte Textuel :
Marquage par Timestamp : simple mais limité, préserve la chronologie mais pas la structure sémantique, peu scalable.
Tagging Rôle/Fonction : chaque élément reçoit un tag « objectif », « décision », « action », « erreur », etc. Supporte multi-tagging (priorité, source, confiance). LLM4Tag le permet à l’échelle.
Compression par Paires QA : transformer les interactions en paires question-réponse synthétiques pour l’essentiel.
Notes Hiérarchiques : compression progressive en vecteurs de sens, comme dans H-MEM.
Traitement Multi-modal :
Espaces Vectoriels Comparables : encoder texte, image, audio dans des espaces communs (ChatGPT, Claude).
Cross-Attention : guider l’attention d’un mode sur un autre (Qwen2-VL).
Encodage Indépendant/Self-Attention : encoder séparément puis combiner via attention unifiée.
Organisation du Contexte :
Architecture Mémoire en Couches : séparer mémoire de travail (contexte courant), mémoire court terme (historique récent), mémoire long terme (faits persistants).
Isolation Fonctionnelle : sous-agents à fenêtres séparées (Claude).
Abstraction du Contexte (Self-Baking) :
« Self-baking » désigne la capacité d’un contexte à s’améliorer par traitement itératif. Exemples :
Stocker le contexte brut puis ajouter des synthèses en langage naturel (Claude Code, Gemini CLI)
Extraire les faits clés via des schémas fixes (ChatSchema)
Compression progressive en vecteurs de sens (H-MEM)
Utilisation : Décisions de Conception
Sélection du Contexte :
Récupération par embeddings (la plus courante)
Parcours de graphe de connaissances
Scoring de similarité sémantique
Pondération récence/priorité
Partage du Contexte :
Dans un système :
Embedding du contexte dans les prompts (AutoGPT, ChatDev)
Messages structurés entre agents (Letta, MemOS)
Mémoire partagée via communication indirecte (A-MEM)
Entre systèmes :
Adaptateurs de format (Langroid)
Représentations partagées (Sharedrop)
Inférence Utilisateur Proactive :
ChatGPT/Claude anticipent les besoins utilisateurs à partir des interactions
Les systèmes contextuels apprennent à faire surface avant la demande explicite
L’équilibre entre utilité et vie privée reste un défi
Compétences en Ingénierie du Contexte et Maîtrise d’Équipe
À mesure que l’ingénierie du contexte devient centrale, certaines compétences sont déterminantes.
1. Assemblage Stratégique du Contexte
Comprendre ce qui est nécessaire pour chaque tâche. Ce n’est pas juste collecter des données—c’est comprendre la tâche pour distinguer l’essentiel du bruit.
En Pratique :
Analyser les échecs pour identifier le contexte manquant
Tester différentes combinaisons de contexte
Mettre en place l’observabilité pour détecter les éléments clés
2. Architecture des Systèmes de Mémoire
Comprendre les types de mémoire et leur usage :
Quand court terme vs long terme ?
Comment les types interagissent-ils ?
Quelles stratégies de compression garder la fidélité ?
3. Recherche Sémantique et Récupération
Aller au-delà du mot-clé :
Modèles d’embedding et limites
Métriques de similarité vectorielle
Stratégies de reranking et filtrage
Gestion des requêtes ambiguës
4. Économie de Tokens et Analyse de Coût
Chaque byte a un coût :
Suivre la consommation de tokens selon la composition
Comprendre les coûts de traitement propres au modèle
Trouver l’équilibre entre qualité, coût et latence
5. Orchestration Système
Avec de multiples agents, outils, mémoires, l’orchestration est vitale :
Coordination entre sous-agents
Gestion des échecs et reprise
Gestion d’état sur des tâches longues
6. Évaluation et Mesure
L’ingénierie du contexte est une discipline d’optimisation :
Définir des métriques pertinentes
Tester les approches contextuelles
Mesurer l’impact sur l’expérience utilisateur, pas seulement l’exactitude
Comme l’a dit un ingénieur senior, l’approche la plus rapide pour livrer un logiciel IA de qualité est d’incorporer des concepts modulaires de l’agent dans les produits existants.
Bonnes Pratiques pour l’Ingénierie du Contexte
1. Commencer Simple, Évoluer Progressivement
Démarrez avec le prompt engineering de base et la mémoire type brouillon. N’ajoutez la complexité (isolation multi-agent, récupération avancée) que si nécessaire.
2. Tout Mesurer
Utilisez des outils comme LangSmith. Suivez :
Consommation de tokens selon l’approche
Performances (précision, satisfaction)
Compromis coût/latence
3. Automatiser la Gestion Mémoire
La curation manuelle ne passe pas à l’échelle. Mettez en place :
Synthèse automatique aux limites de contexte
Filtrage intelligent et scoring de pertinence
Décroissance pour l’information ancienne
4. Concevoir pour la Clarté et l’Auditabilité
La qualité du contexte importe plus si vous comprenez ce que voit le modèle. Utilisez :
Formats clairs et structurés (JSON, Markdown)
Contexte tagué avec rôles explicites
Séparation des préoccupations
5. Priorité au Contexte, Non au LLM
Ne commencez pas par « quel LLM utiliser », mais par « quel contexte la tâche requiert-elle ? » Le LLM devient un composant d’un système contextuel.
6. Adopter les Architectures en Couches
Séparez :
Mémoire de travail (contexte courant)
Mémoire court terme (interactions récentes)
Mémoire long terme (faits persistants)
Chaque couche a un but propre, optimisable indépendamment.
Défis et Perspectives
Défis Actuels
1. Context Rot et Scalabilité
Bien que des techniques existent pour le limiter, le problème fondamental subsiste. Plus l’entrée grandit, plus la sélection/compaction devient cruciale.
2. Cohérence Mémoire
Maintenir la cohérence entre types de mémoire et échelles de temps est complexe. Les contradictions ou informations obsolètes dégradent la performance.
3. Vie Privée et Divulgation Sélective
Plus le contexte utilisateur est riche, plus l’équilibre personnalisation/vie privée est délicat. Le « la fenêtre de contexte ne leur appartient plus » survient quand surgit de l’information inattendue.
4. Surcharge de Calcul
L’ingénierie du contexte sophistiquée a un coût. Sélection, compression, récupération consomment des ressources. Trouver le bon équilibre reste ouvert.
Pistes d’Avenir
1. Context Engineers Apprenants
Au lieu de tout coder à la main, les systèmes pourraient apprendre automatiquement les meilleures stratégies de gestion du contexte (meta-learning, RL).
2. Émergence de Mécanismes Symboliques
Des recherches récentes montrent que les LLMs développent des mécanismes symboliques émergents. Les exploiter permettrait une abstraction/conceptualisation du contexte accrue.
3. Outils Cognitifs et Programmation de Prompts
Des frameworks comme « Cognitive Tools » d’IBM traitent le raisonnement comme des composants modulaires, rendant l’ingénierie du contexte plus logicielle et réutilisable.
4. Neural Field Theory pour le Contexte
Plutôt que des éléments discrets, modéliser le contexte comme un champ neuronal continu faciliterait une gestion plus adaptative.
5. Sémantique Quantique et Superposition
Des recherches explorent la superposition quantique : l’information existerait dans plusieurs états jusqu’à utilisation, révolutionnant stockage et récupération.
Conclusion : Pourquoi l’Ingénierie du Contexte Compte Maintenant
Nous sommes à un tournant du développement IA. Pendant des années, l’enjeu était d’agrandir et d’améliorer les modèles. La question était : « Comment améliorer le LLM ? »
Aujourd’hui la question est différente : « Comment concevoir des systèmes autour des LLMs pour exploiter tout leur potentiel ? »
L’ingénierie du contexte répond à cette question. Ce n’est pas un hack technique marginal—c’est une discipline clé pour bâtir des systèmes IA fiables, scalables, vraiment utiles en production.
Les preuves abondent. Anthropic, Alibaba (Tongyi) et d’autres ont montré que l’ingénierie du contexte bat la simple taille du modèle. Une petite équipe bien organisée, avec un modèle moins puissant mais une gestion contextuelle soignée, surpasse régulièrement de grandes équipes dotées de LLMs de pointe mais d’un contexte mal conçu.
Cela a de profondes implications :
L’ingénierie du contexte démocratise l’IA : Pas besoin du plus gros modèle, il faut le contexte le mieux adapté à la tâche.
C’est une compétence centrale : Les équipes qui maîtrisent l’ingénierie du contexte auront un impact démesuré.
C’est la base des agents : À mesure que l’IA passe à des raisonnements longs, multi-étapes, l’ingénierie du contexte devient indispensable.
C’est durable : Peu importe l’évolution des modèles, le défi de remplir intelligemment la fenêtre de contexte restera.
La prochaine génération de systèmes IA sera définie non par le
Questions fréquemment posées
Le prompt engineering se concentre sur la formulation d’une instruction unique pour un LLM. L’ingénierie du contexte est une discipline systémique plus large qui gère tout l’écosystème d’informations autour d’un modèle IA, incluant la mémoire, les outils et les données récupérées, afin d’optimiser les performances sur des tâches complexes et à état.
Le context rot désigne la dégradation imprévisible des performances d’un LLM à mesure que son contexte d’entrée s’allonge. Les modèles peuvent connaître des chutes brutales de précision, ignorer des parties du contexte ou halluciner, soulignant la nécessité d’une gestion de la qualité du contexte plutôt que de sa simple quantité.
Les quatre stratégies sont : 1. Écrire le Contexte (conserver des informations hors de la fenêtre de contexte, comme des brouillons ou des mémoires), 2. Sélectionner le Contexte (récupérer uniquement l’information pertinente), 3. Compresser le Contexte (résumer ou réduire pour économiser de l’espace), et 4. Isoler le Contexte (utiliser des systèmes multi-agents ou des sandboxes pour séparer les préoccupations).
Arshia est ingénieure en workflows d'IA chez FlowHunt. Avec une formation en informatique et une passion pour l’IA, elle se spécialise dans la création de workflows efficaces intégrant des outils d'IA aux tâches quotidiennes, afin d’accroître la productivité et la créativité.
Arshia Kahani
Ingénieure en workflows d'IA
Maîtrisez l’Ingénierie du Contexte
Prêt à construire la prochaine génération de systèmes IA ? Explorez nos ressources et outils pour mettre en œuvre une ingénierie du contexte avancée dans vos projets.
La Décennie des Agents IA : Karpathy sur la feuille de route de l'AGI
Explorez la perspective nuancée d'Andrej Karpathy sur les échéances de l'AGI, les agents IA et pourquoi la prochaine décennie sera décisive pour le développemen...
Comment utiliser les prompts de chatbot IA : Guide complet pour une ingénierie de prompt efficace
Maîtrisez les prompts de chatbot IA avec notre guide complet. Découvrez le cadre CARE, les techniques d’ingénierie de prompt et les meilleures pratiques pour ob...
L’ingénierie du contexte pour les agents IA : maîtriser l’art de fournir la bonne information aux LLM
Découvrez comment concevoir le contexte pour les agents IA en gérant les retours d’outils, en optimisant l’utilisation des tokens et en appliquant des stratégie...
20 min de lecture
AI Agents
LLM
+3
Consentement aux Cookies Nous utilisons des cookies pour améliorer votre expérience de navigation et analyser notre trafic. See our privacy policy.