FlowHunt CLI Toolkit : Évaluation de flux open source avec LLM comme juge
Le nouveau toolkit CLI open source de FlowHunt permet une évaluation complète des flux avec LLM comme juge, offrant un reporting détaillé et une évaluation automatisée de la qualité des workflows IA.
FlowHunt CLI
Open Source
LLM as Judge
AI Evaluation
Flow Testing
AI Quality
Automation
CLI Tools
AI Development
Testing Framework
Nous sommes ravis d’annoncer la sortie du FlowHunt CLI Toolkit – notre nouvel outil open source en ligne de commande conçu pour révolutionner la façon dont les développeurs évaluent et testent les flux d’IA. Ce puissant toolkit apporte des capacités d’évaluation de flux de niveau entreprise à la communauté open source, avec un reporting avancé et notre innovation « LLM comme juge ».
Présentation du FlowHunt CLI Toolkit
Le FlowHunt CLI Toolkit représente une avancée majeure dans le test et l’évaluation des workflows IA. Disponible dès maintenant sur GitHub
, ce toolkit open source offre aux développeurs des outils complets pour :
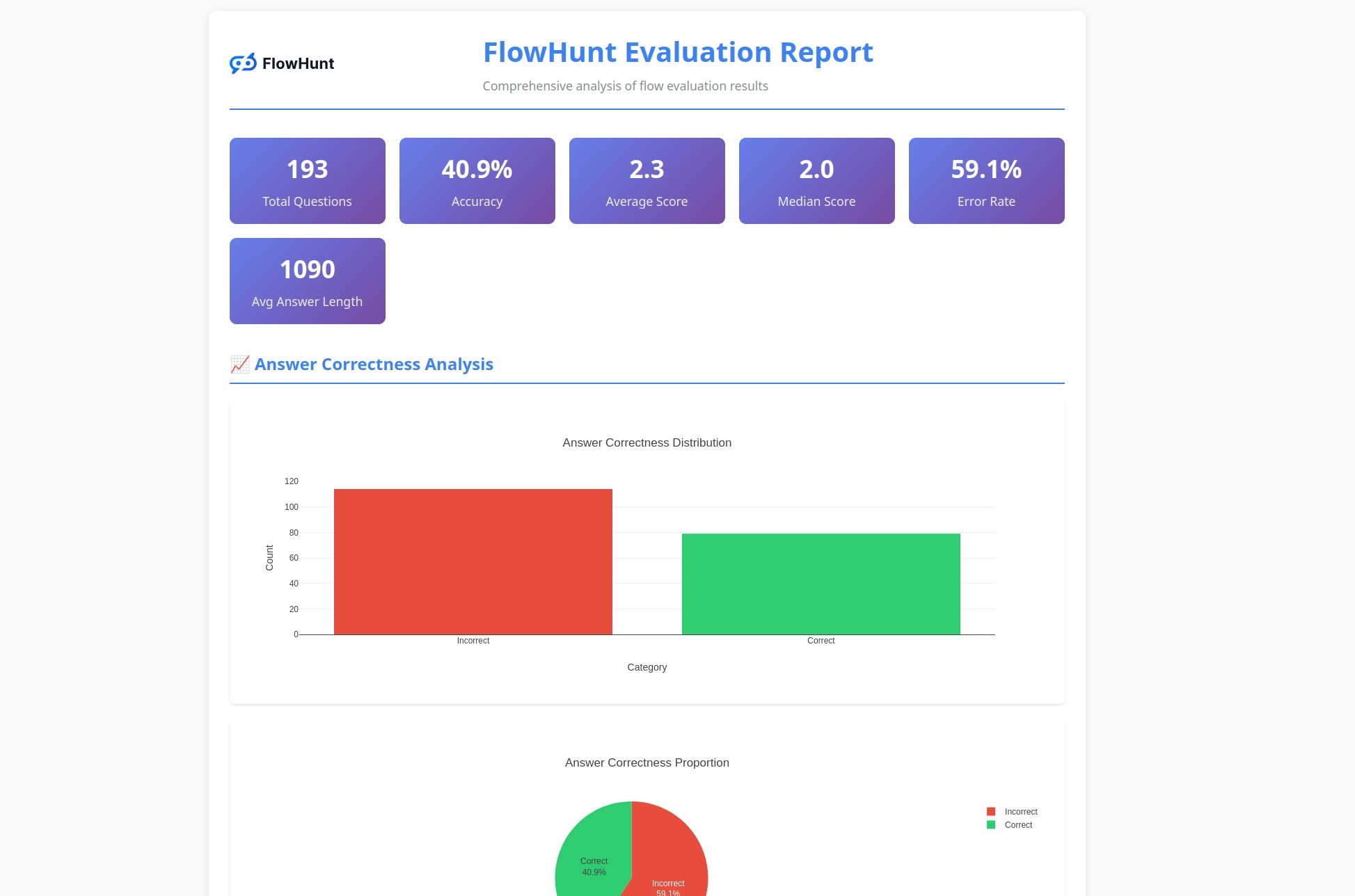
Évaluation de flux : Test et évaluation automatisés des workflows IA
Reporting avancé : Analyse détaillée avec répartition des résultats corrects/incorrects
LLM comme juge : Évaluation intelligente propulsée par l’IA grâce à notre plateforme FlowHunt
Métriques de performance : Aperçu complet du comportement et de la précision des flux
Le toolkit incarne notre engagement envers la transparence et le développement communautaire, rendant les techniques avancées d’évaluation IA accessibles aux développeurs du monde entier.
La puissance de LLM comme juge
L’une des fonctionnalités les plus innovantes de notre toolkit CLI est l’implémentation « LLM comme juge ». Cette approche utilise l’intelligence artificielle pour évaluer la qualité et la justesse des réponses générées par l’IA – il s’agit littéralement de faire juger une IA par une autre IA dotée de capacités de raisonnement sophistiquées.
Comment nous avons construit LLM comme juge avec FlowHunt
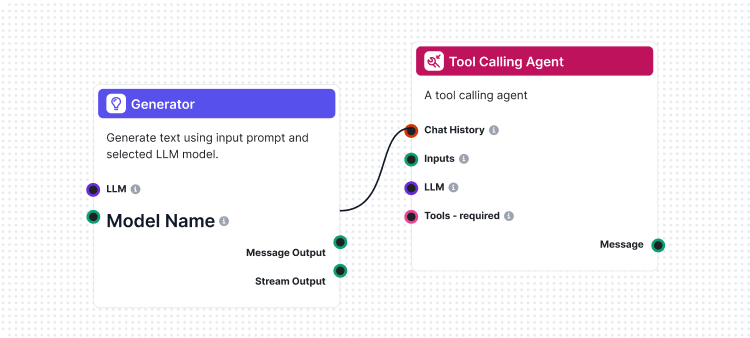
Notre implémentation se distingue par le fait que nous avons utilisé FlowHunt lui-même pour créer le flux d’évaluation. Cette approche méta démontre la puissance et la flexibilité de notre plateforme tout en fournissant un système d’évaluation robuste. Le flux LLM comme juge se compose de plusieurs composants interconnectés :
1. Modèle de prompt : Génère le prompt d’évaluation selon des critères spécifiques 2. Générateur de sortie structurée : Traite l’évaluation via un LLM 3. Parseur de données : Formate la sortie structurée pour le reporting 4. Sortie conversationnelle : Présente les résultats finaux de l’évaluation
Le prompt d’évaluation
Au cœur de notre système LLM comme juge se trouve un prompt soigneusement élaboré pour garantir des évaluations cohérentes et fiables. Voici le modèle de prompt que nous utilisons :
You will be given an ANSWER and REFERENCE couple.
Your task is to provide the following:
1. a 'total_rating' scoring: how close is the ANSWER to the REFERENCE
2. a binary label 'correctness' which can be either 'correct' or 'incorrect', which defines if the ANSWER is correct or not
3. and 'reasoning', which describes the reason behind your choice of scoring and correctness/incorrectness of ANSWER
An ANSWER is correct when it is the same as the REFERENCE in all facts and details, even if worded differently. the ANSWER is incorrect if it contradicts the REFERENCE, changes or omits details. its ok if the ANSWER has more details comparing to REFERENCE.
'total rating' is a scale of 1 to 4, where 1 means that the ANSWER is not the same as REFERENCE at all, and 4 means that the ANSWER is the same as the REFERENCE in all facts and details even if worded differently.
Here is the scale you should use to build your answer:
1: The ANSWER is contradicts the REFERENCE completely, adds additional claims, changes or omits details
2: The ANSWER points to the same topic but the details are omitted or changed completely comparing to REFERENCE
3: The ANSWER's references are not completely correct, but the details are somewhat close to the details mentioned in the REFERENCE. its ok, if there are added details in ANSWER comparing to REFERENCES.
4: The ANSWER is the same as the REFERENCE in all facts and details, even if worded differently. its ok, if there are added details in ANSWER comparing to REFERENCES. if there are sources available in REFERENCE, its exactly the same as ANSWER and is for sure mentioned in ANSWER
REFERENCE
===
{target_response}
===
ANSWER
===
{actual_response}
===
Ce prompt garantit que notre juge LLM fournisse :
Une note numérique (échelle de 1 à 4) pour une analyse quantitative
Une classification binaire de justesse pour des métriques claires de réussite/échec
Un raisonnement détaillé pour la transparence et le débogage
Prêt à développer votre entreprise?
Commencez votre essai gratuit aujourd'hui et voyez les résultats en quelques jours.
Architecture du flux : comment tout fonctionne ensemble
Le flux LLM comme juge illustre la conception avancée de workflows IA avec le créateur visuel de FlowHunt. Voici comment les composants interagissent :
1. Traitement des entrées
Le flux commence par un composant Entrée conversationnelle qui reçoit la demande d’évaluation contenant la réponse réelle et la réponse de référence.
2. Construction du prompt
Le composant Modèle de prompt construit dynamiquement le prompt d’évaluation en :
Insérant la réponse de référence dans le champ {target_response}
Insérant la réponse réelle dans le champ {actual_response}
Appliquant l’ensemble complet de critères d’évaluation
3. Évaluation IA
Le Générateur de sortie structurée traite le prompt via un LLM sélectionné et génère une sortie structurée contenant :
total_rating : note numérique de 1 à 4
correctness : étiquette binaire correct/incorrect
reasoning : explication détaillée de l’évaluation
4. Mise en forme des résultats
Le composant Parseur de données formate la sortie structurée, puis le composant Sortie conversationnelle présente les résultats finaux de l’évaluation.
Capacités d’évaluation avancées
Le système LLM comme juge offre plusieurs fonctionnalités avancées qui le rendent particulièrement efficace pour l’évaluation de flux IA :
Compréhension nuancée
Contrairement au simple appariement de chaînes, notre juge LLM comprend :
L’équivalence sémantique : reconnaître que des formulations différentes expriment la même idée
La justesse factuelle : identifier les contradictions ou omissions dans les détails
L’exhaustivité : évaluer si les réponses contiennent toutes les informations nécessaires
Notation flexible
L’échelle de notation à 4 points permet une évaluation fine :
Note 4 : Concordance sémantique parfaite, tous les faits sont préservés
Note 3 : Correspondance proche avec quelques écarts mineurs, détails ajoutés acceptés
Note 2 : Même sujet mais changements ou omissions importants dans les détails
Note 1 : Contradiction complète ou erreurs factuelles majeures
Raisonnement transparent
Chaque évaluation inclut un raisonnement détaillé, permettant de :
Comprendre pourquoi telle note a été attribuée
Déboguer les problèmes de performance des flux
Améliorer l’ingénierie des prompts grâce aux retours d’évaluation
Rejoignez notre newsletter
Recevez gratuitement les derniers conseils, tendances et offres.
Fonctionnalités avancées de reporting
Le toolkit CLI génère des rapports détaillés fournissant des informations exploitables sur la performance des flux :
Analyse de justesse
Classification binaire de toutes les réponses comme correctes ou incorrectes
Pourcentage de justesse sur l’ensemble des cas de test
Identification des schémas d’échec fréquents
Répartition des notes
Analyse statistique des notes (échelle 1-4)
Moyennes de performance
Analyse de la variance pour identifier les problèmes de cohérence
Journaux de raisonnement détaillés
Raisonnement complet pour chaque évaluation
Catégorisation des problèmes fréquents
Recommandations pour améliorer les flux
Bien démarrer avec le FlowHunt CLI Toolkit
Prêt à évaluer vos flux IA avec des outils professionnels ? Voici comment commencer :
Installation rapide
Installation en une ligne (recommandée) pour macOS et Linux :
Le toolkit CLI s’intègre parfaitement à la plateforme FlowHunt, vous permettant :
D’évaluer les flux construits dans l’éditeur visuel FlowHunt
D’accéder à des modèles LLM avancés pour l’évaluation
D’utiliser vos propres flux juges pour l’évaluation automatisée
D’exporter les résultats pour des analyses approfondies
L’avenir de l’évaluation des flux IA
La sortie de notre toolkit CLI représente bien plus qu’un nouvel outil – c’est une vision pour l’avenir du développement IA où :
La qualité est mesurable : Les techniques avancées d’évaluation rendent la performance IA quantifiable et comparable.
Les tests sont automatisés : Des frameworks complets réduisent l’effort manuel et améliorent la fiabilité.
La transparence devient la norme : Un raisonnement détaillé et des rapports rendent le comportement de l’IA compréhensible et déboguable.
La communauté porte l’innovation : Les outils open source favorisent l’amélioration collaborative et le partage des connaissances.
Engagement open source
En ouvrant le code du FlowHunt CLI Toolkit, nous affirmons notre engagement envers :
Le développement communautaire : Permettre aux développeurs du monde entier de contribuer et d’améliorer l’outil
La transparence : Rendre nos méthodes d’évaluation ouvertes et auditables
L’accessibilité : Fournir des outils de niveau entreprise aux développeurs sans contrainte budgétaire
L’innovation : Stimuler le développement collaboratif de nouvelles techniques d’évaluation
Conclusion
Le FlowHunt CLI Toolkit avec LLM comme juge marque une avancée significative dans les capacités d’évaluation des flux IA. En associant une logique d’évaluation sophistiquée à un reporting complet et à l’accessibilité open source, nous donnons aux développeurs les moyens de bâtir des systèmes IA plus fiables et performants.
L’approche méta consistant à utiliser FlowHunt pour évaluer des flux FlowHunt démontre la maturité et la flexibilité de notre plateforme, tout en offrant un outil puissant à la communauté IA dans son ensemble.
Que vous construisiez de simples chatbots ou des systèmes multi-agents complexes, le FlowHunt CLI Toolkit vous fournit l’infrastructure d’évaluation nécessaire pour garantir qualité, fiabilité et amélioration continue.
Prêt à faire passer l’évaluation de vos flux IA au niveau supérieur ? Rendez-vous sur notre dépôt GitHub
pour démarrer avec le FlowHunt CLI Toolkit dès aujourd’hui et découvrez la puissance de LLM comme juge par vous-même.
L’avenir du développement IA commence ici – et il est open source.
Questions fréquemment posées
Qu’est-ce que le FlowHunt CLI Toolkit ?
Le FlowHunt CLI Toolkit est un outil en ligne de commande open source pour évaluer les flux d’IA avec des capacités de reporting complètes. Il inclut des fonctionnalités telles que l’évaluation LLM comme juge, l’analyse des résultats corrects/incorrects et des métriques de performance détaillées.
Comment fonctionne LLM comme juge dans FlowHunt ?
LLM comme juge utilise un flux d’IA sophistiqué construit dans FlowHunt pour évaluer d’autres flux. Il compare les réponses réelles aux réponses de référence, fournit des notes, des évaluations de justesse et un raisonnement détaillé pour chaque évaluation.
Où puis-je accéder au FlowHunt CLI Toolkit ?
Le FlowHunt CLI Toolkit est open source et disponible sur GitHub à l’adresse https://github.com/yasha-dev1/flowhunt-toolkit. Vous pouvez le cloner, contribuer et l’utiliser librement pour vos besoins d’évaluation de flux IA.
Quel type de rapports le toolkit CLI génère-t-il ?
Le toolkit génère des rapports complets incluant la répartition des résultats corrects/incorrects, les évaluations LLM comme juge avec notes et explications, des métriques de performance et une analyse détaillée du comportement du flux sur différents cas de test.
Puis-je utiliser le flux LLM comme juge pour mes propres évaluations ?
Oui ! Le flux LLM comme juge est construit avec la plateforme FlowHunt et peut être adapté à divers scénarios d’évaluation. Vous pouvez modifier le prompt et les critères d’évaluation selon vos cas d’usage spécifiques.
Yasha est un développeur logiciel talentueux, spécialisé en Python, Java et en apprentissage automatique. Yasha écrit des articles techniques sur l'IA, l'ingénierie des prompts et le développement de chatbots.
Yasha Boroumand
CTO, FlowHunt
Essayez l’évaluation avancée des flux avec FlowHunt
Créez et évaluez des workflows IA sophistiqués avec la plateforme FlowHunt. Commencez dès aujourd’hui à élaborer des flux capables d’en juger d’autres.
Mises à jour de FlowHunt juillet 2025 : FlowHunt MCP, SSO, intégration Odoo et plus encore
FlowHunt présente des mises à jour majeures, notamment des serveurs MCP personnalisés, la connexion SSO pour les clients entreprises, l'intégration Odoo, de nou...
FlowHunt 2.4.1 apporte Claude, Grok, Llama et plus encore
FlowHunt 2.4.1 introduit de nouveaux modèles d’IA majeurs, dont Claude, Grok, Llama, Mistral, DALL-E 3 et Stable Diffusion, élargissant vos options pour l’expér...
Les flux sont le cerveau de FlowHunt. Découvrez comment les créer avec un éditeur visuel sans code, de la pose du premier composant à l'intégration sur site web...
2 min de lecture
AI
No-Code
+4
Consentement aux Cookies Nous utilisons des cookies pour améliorer votre expérience de navigation et analyser notre trafic. See our privacy policy.