Comment créer des pages de base de connaissances personnalisées dans Hugo à partir des tickets LiveAgent
Découvrez comment automatiser la création d’articles de base de connaissances dans Hugo directement à partir des tickets du support client grâce aux agents IA et à l’intégration GitHub.
Automation
Knowledge Base
Hugo
GitHub
AI Agents
Customer Support
Les équipes de support client génèrent chaque jour de précieuses informations via leurs interactions avec les clients. Ces questions, préoccupations et solutions représentent une mine d’or de connaissances qui pourraient profiter à l’ensemble de vos utilisateurs si elles étaient correctement documentées. Cependant, convertir manuellement les tickets de support en articles de base de connaissances bien rédigés demande du temps, est répétitif et souvent relégué au second plan face aux demandes immédiates. Et si vous pouviez automatiser tout ce processus, en transformant les demandes brutes des clients en pages de base de connaissances professionnelles et optimisées SEO, publiées directement sur votre site web ? C’est précisément ce que permettent aujourd’hui les workflows d’automatisation modernes. En connectant votre système de ticketing LiveAgent avec Hugo pour la génération de site statique et GitHub pour le contrôle de version, vous créez une chaîne automatisée qui transforme les questions clients en contenu de base de connaissances consultable, de façon automatique. Dans ce guide complet, nous verrons comment construire ce puissant système d’automatisation, son architecture technique et les étapes concrètes pour l’implémenter dans votre organisation.
Comprendre l’automatisation de la base de connaissances
Une base de connaissances est un référentiel centralisé d’informations conçu pour aider les utilisateurs à trouver des réponses aux questions courantes sans intervention directe du support. Traditionnellement, ces bases sont construites manuellement — les équipes de support rédigent les articles, les mettent en forme, les optimisent pour le référencement, puis les publient via un système de gestion de contenu. Ce processus, très chronophage, crée un goulot d’étranglement important, en particulier pour les entreprises en croissance qui reçoivent des centaines de demandes quotidiennes. L’automatisation de la base de connaissances révolutionne ce modèle en utilisant l’intelligence artificielle pour extraire les informations pertinentes des tickets de support, les structurer selon des modèles prédéfinis et les publier directement sur votre site web. Le système d’automatisation agit comme un intermédiaire intelligent entre votre équipe support et votre site, identifiant les tickets contenant des connaissances généralisables utiles à d’autres utilisateurs, puis transformant la conversation brute en documentation professionnelle et soignée. Cette approche fait gagner un temps précieux et garantit la cohérence du format, de la structure et de l’optimisation SEO sur tous vos articles. Le système peut être configuré pour comprendre le contexte spécifique de votre entreprise, éviter les doublons et maintenir une base qui s’enrichit naturellement à mesure que votre support traite de nouveaux sujets.
Prêt à développer votre entreprise?
Commencez votre essai gratuit aujourd'hui et voyez les résultats en quelques jours.
Pourquoi l’automatisation de la base de connaissances est-elle essentielle pour votre entreprise ?
L’automatisation de la base de connaissances présente de nombreux avantages stratégiques. D’abord, elle réduit considérablement le volume de sollicitations du support en permettant aux clients de trouver eux-mêmes des réponses. Les études montrent que les clients préfèrent l’auto-assistance quand elle est disponible et efficace, et une base bien entretenue peut réduire les tickets de 20 à 30 %. Ensuite, elle accroît la satisfaction client en fournissant des réponses instantanées sans attente. Troisièmement, elle génère d’importants bénéfices SEO — les articles sont indexés par les moteurs de recherche et peuvent attirer du trafic organique, augmentant votre visibilité et l’acquisition de nouveaux clients. Quatrièmement, elle permet de conserver la connaissance institutionnelle qui pourrait autrement se perdre lors des départs d’employés. Chaque interaction de support contient du contexte et des solutions précieuses qui, une fois documentées, enrichissent durablement votre entreprise. Cinquièmement, elle permet à votre équipe de se concentrer sur les problématiques complexes à forte valeur ajoutée plutôt que de répondre sans cesse aux mêmes questions. En automatisant la création de contenu à partir des tickets, vous multipliez l’efficacité de votre organisation : le temps passé par votre équipe devient une ressource documentaire accessible à tous vos futurs clients. Enfin, l’automatisation apporte des données précieuses sur les difficultés de vos clients, utiles pour le développement produit, le marketing ou la formation.
L’architecture de la génération automatisée de base de connaissances
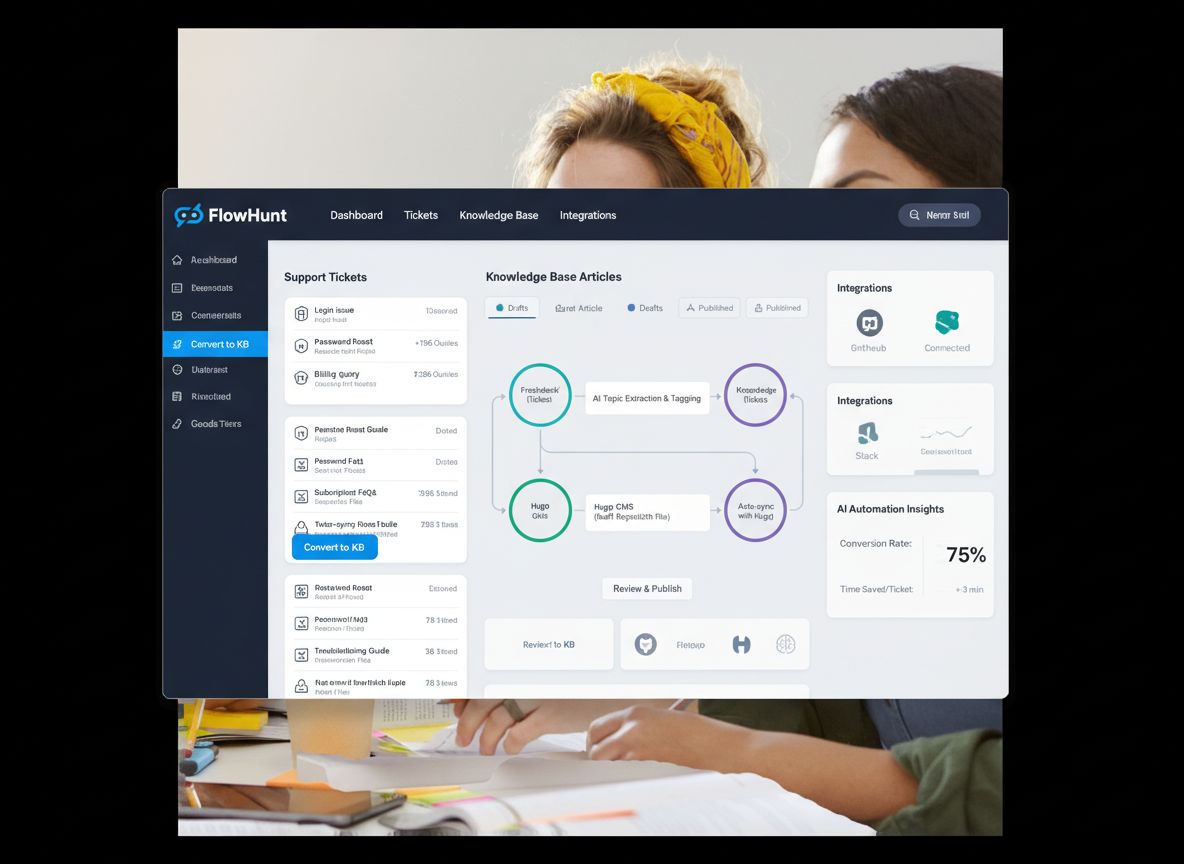
Construire un système automatisé de base de connaissances implique d’intégrer plusieurs outils dans un workflow cohérent. Le système s’appuie généralement sur quatre composants principaux : un système de ticketing (LiveAgent), un agent IA qui traite les tickets, un système de contrôle de version (GitHub) et un générateur de site statique (Hugo). LiveAgent est la source des demandes clients, stockant toutes les conversations avec des métadonnées (tags, catégories, dates). L’agent IA orchestre tout le processus : il reçoit un ID de ticket, récupère le contenu et l’historique de la conversation, analyse la pertinence pour la base de connaissances, vérifie les doublons, génère un contenu optimisé SEO au bon format et gère le workflow GitHub. GitHub sert à la gestion de contenu, au contrôle de version et à la validation des changements. Hugo transforme les fichiers markdown de GitHub en site web rapide, sécurisé et optimisé pour le référencement. Cette architecture sépare clairement les responsabilités : LiveAgent pour le support, l’agent IA pour l’intelligence et la décision, GitHub pour la gestion de version et la collaboration, et Hugo pour la présentation. Chaque composant peut évoluer indépendamment sans perturber l’ensemble.
Rejoignez notre newsletter
Recevez gratuitement les derniers conseils, tendances et offres.
Comment FlowHunt facilite l’automatisation de la base de connaissances
FlowHunt fournit la couche d’orchestration qui relie tous ces systèmes en un seul workflow fluide. Plutôt que de nécessiter des développements sur-mesure ou des intégrations complexes, FlowHunt permet de concevoir visuellement le processus d’automatisation, connectant LiveAgent, GitHub et Hugo via une interface simple et intuitive. La plateforme gère l’authentification, le traitement des erreurs, la logique de reprise et toute la complexité technique qui demanderait sinon une expertise d’ingénierie. Avec FlowHunt, vous pouvez créer des workflows sophistiqués sans coder, rendant l’automatisation accessible même sans équipe technique dédiée. La plateforme apporte aussi la gestion de la mémoire et du contexte, permettant à votre automatisation d’apprendre des exécutions précédentes et de décider intelligemment de créer ou mettre à jour un article. L’intégration avec GitHub permet la création automatique de pull requests, offrant à votre équipe la possibilité de relire les contenus avant publication. Cette approche « humain dans la boucle » garantit la qualité tout en conservant les gains d’efficacité de l’automatisation.
Le workflow complet : étape par étape
Le processus automatisé de génération d’articles suit une séquence d’étapes pensée pour aboutir à un article prêt à être publié. Comprendre ce workflow est essentiel pour le mettre en place efficacement dans votre organisation.
Première étape : récupération et validation du ticket
Le workflow débute lorsque vous fournissez un ID de ticket issu de LiveAgent. L’agent IA récupère immédiatement le contenu complet du ticket : sujet, corps, tags, et l’historique des échanges. Cette récupération exhaustive garantit à l’IA tout le contexte nécessaire pour générer un contenu pertinent et précis. L’agent vérifie aussi que le ticket est suffisamment détaillé et pertinent pour la base de connaissances. Par exemple, si votre organisation reçoit beaucoup de demandes de démo, vous pouvez configurer le système pour ignorer ces tickets afin d’éviter du contenu non généralisable. Ce filtrage évite d’encombrer la base de connaissances de contenus administratifs ou transactionnels sans valeur ajoutée pour les utilisateurs.
Deuxième étape : détection des doublons grâce à la mémoire
Avant de générer un nouvel article, le système vérifie via sa mémoire si un sujet similaire n’a pas déjà été traité. Ce mécanisme est crucial pour éviter la création de doublons qui pourraient nuire à l’expérience utilisateur et à votre SEO. L’agent IA parcourt les tickets et articles générés pour détecter les sujets proches. En cas de correspondance, il peut mettre à jour l’article existant avec de nouvelles informations ou sauter la création, selon la configuration. Si aucun sujet similaire n’existe, l’agent ajoute ce ticket à sa mémoire, créant ainsi une référence pour les futurs traitements. Ce fonctionnement rend le système de plus en plus intelligent avec le temps — plus vous traitez de tickets, plus la cartographie de votre base de connaissances s’affine.
Troisième étape : analyse de la structure de la base de connaissances
Le système analyse ensuite la structure, le format et l’organisation de votre base de connaissances existante. Cette étape est essentielle pour garantir la cohérence des articles. L’agent IA examine les fichiers markdown, les frontmatters, les structures de titres et les schémas de contenu afin de comprendre les conventions en place. Il observe la catégorisation, les métadonnées, la gestion des images et les éléments SEO utilisés. En s’appuyant sur votre contenu existant, le système apprend vos exigences de style et de structure, assurant que les nouveaux articles s’intègrent parfaitement à la base de connaissances, sans paraître générés automatiquement.
Quatrième étape : gestion des branches GitHub
Pour assurer un contrôle de version propre et une relecture efficace, le système crée ou utilise une branche GitHub dédiée à la mise à jour de la base de connaissances. Plutôt que de créer une branche pour chaque ticket, le système gère intelligemment les branches pour garder le dépôt organisé. Si une branche « base de connaissances » existe déjà, le système l’utilise et y ajoute le nouveau fichier. Cette approche évite la prolifération des branches tout en permettant de regrouper plusieurs mises à jour dans une seule pull request. Les conventions de nommage sont généralement explicites, comme « knowledge-base-updates » ou « kb-automation », pour faciliter la compréhension de tous.
Cinquième étape : génération et mise en forme du contenu
Avec tout le contexte réuni, l’agent IA génère l’article de base de connaissances. Le contenu comprend un frontmatter bien formaté avec titre, description, mots-clés, tags, catégories, date de publication et éléments d’appel à l’action. Le corps de l’article suit un format structuré, lisible et optimisé pour le SEO. Typiquement, cela inclut un titre principal, plusieurs sections H2 sous forme de questions (« Qu’est-ce que c’est ? », « Pourquoi faire cela ? », « Comment procéder ? »), et des réponses détaillées en paragraphes ou listes à puces. Cette structure est pensée pour les featured snippets et les moteurs de recherche qui valorisent les réponses claires et structurées. Le contenu est rédigé en markdown, standard pour Hugo et la plupart des générateurs de sites statiques.
Sixième étape : création du fichier et commit
Le système crée un nouveau fichier markdown dans le dossier de la base de connaissances, avec un nom basé sur le sujet de l’article. Le nom est généralement « slugifié » (minuscules, tirets) pour respecter les standards web. Le fichier contient le frontmatter complet et le corps généré à l’étape précédente. Une fois le fichier créé, le système effectue un commit sur la branche GitHub avec un message descriptif qui fait référence à l’ID du ticket original. Ce message permet de relier l’article à la demande client initiale, garantissant traçabilité et contexte.
Septième étape : création de la pull request et relecture
Enfin, le système crée une pull request de la branche dédiée vers la branche principale. Cette pull request inclut une description des changements, l’ID du ticket à l’origine de la création et tout contexte pertinent. Elle sert de point de contrôle pour que votre équipe puisse relire, corriger et valider l’article avant publication. Ce contrôle humain est crucial : même si le contenu généré par IA est de qualité, l’œil humain assure la justesse, la cohérence de marque et l’adéquation au contexte. Une fois la PR validée, elle est fusionnée, déclenchant la reconstruction du site par Hugo et la mise en ligne de l’article.
Implémentation pratique : trouver et utiliser les IDs de ticket
Pour utiliser ce workflow, il faut identifier le bon ID de ticket dans LiveAgent. L’interface affiche l’ID de deux façons. D’abord, directement dans LiveAgent, un libellé « Ticket » affiche l’ID en évidence — il suffit de le copier. Ensuite, et souvent plus pratique, l’ID apparaît dans l’URL de la page du ticket : ouvrez un ticket, l’URL contient un paramètre du type « ID=12345 » à la fin. C’est cet ID qu’il faut fournir au workflow d’automatisation. Une fois l’ID obtenu, il suffit de le saisir dans le workflow FlowHunt pour déclencher tout le processus. Le système récupère, analyse, vérifie les doublons, génère l’article, crée la branche et la pull request GitHub, puis notifie votre équipe pour relecture. Le tout se fait en quelques secondes ou minutes, selon la complexité du ticket et la taille de la base existante.
Dynamisez votre workflow avec FlowHunt
Découvrez comment FlowHunt automatise la création de votre base de connaissances à partir des tickets — de l’analyse à la génération de contenu, jusqu’à l’intégration GitHub et la publication Hugo — le tout dans un workflow fluide.
Une fois le workflow de base en place, plusieurs options avancées permettent d’optimiser le système selon vos besoins. Vous pouvez configurer le système pour ignorer certains types de tickets selon les tags, catégories ou mots-clés. Par exemple, vous pouvez choisir d’ignorer tous les tickets tagués « facturation » ou « compte », qui ne représentent pas des connaissances généralisables. Vous pouvez aussi fixer des seuils de qualité ou de longueur : si un ticket est trop court ou manque de détails, le système peut le passer et attendre une demande plus complète. La mémoire peut être configurée avec différents algorithmes de correspondance, du simple matching de mots-clés à l’analyse sémantique avancée. Vous pouvez également personnaliser le frontmatter et la structure de contenu, ajouter des champs sur mesure ou modifier le format de l’article. Certaines entreprises ajoutent des métadonnées comme le niveau de difficulté, la cible ou des articles liés. Il est aussi possible d’ajouter des images générées par IA ou issues de votre médiathèque. Le système peut créer des articles en plusieurs langues si vous ciblez l’international. Enfin, les notifications et validations sont configurables — par exemple, exiger la validation par certains membres pour des articles dans des catégories sensibles.
Exemple concret : erreur d’intégration WordPress
Prenons un exemple réel du workflow en action. Un client soumet un ticket concernant une erreur d’intégration WordPress. Le ticket comprend des messages d’erreur, des captures d’écran et une description détaillée des essais réalisés. L’équipe support répond avec des étapes de dépannage et résout le problème. Ce ticket est un candidat idéal pour l’automatisation. Lorsqu’on fournit l’ID au workflow, le système récupère la conversation, l’analyse et vérifie la mémoire. Aucun article similaire n’existant, le sujet est ajouté à la mémoire et l’article généré. Le système analyse votre base de connaissances et détecte un format spécifique pour les articles techniques (symptômes, causes, solutions, prévention). L’article suit ce format et devient un guide complet sur les erreurs d’intégration WordPress, aidant les futurs clients à résoudre le problème sans solliciter le support. L’article est créé dans une branche GitHub, une pull request est générée, votre équipe relit, ajuste si besoin et fusionne. En quelques minutes, l’article est en ligne, référencé par les moteurs de recherche et prêt à aider vos clients. La prochaine fois qu’un utilisateur cherchera « erreur intégration WordPress », il trouvera votre article et résoudra son problème sans contacter le support.
Mesurer le succès et le ROI
Pour justifier l’investissement dans l’automatisation, il est important de mesurer son impact. Les indicateurs clés incluent la baisse du volume de tickets sur les sujets couverts, l’augmentation du trafic organique, le temps économisé par l’équipe support, et l’amélioration de la satisfaction client. Vous pouvez suivre combien de clients consultent la base avant de contacter le support, combien de tickets y font référence, ou combien de clients trouvent leur réponse via la base. La qualité des articles générés peut se mesurer via l’engagement utilisateur : temps passé, profondeur de scroll, taux de rebond. Les articles utiles génèrent plus d’engagement. Vous pouvez aussi suivre le nombre d’articles produits, le temps gagné par rapport à une création manuelle, et les économies réalisées en support. La plupart des entreprises constatent un retour sur investissement en quelques mois grâce à la réduction des coûts et à la satisfaction accrue des clients.
Conclusion
Automatiser la création d’une base de connaissances à partir des tickets LiveAgent est une opportunité majeure pour améliorer l’efficacité du support, booster le SEO de votre site et bâtir une ressource durable au service de vos clients. En connectant LiveAgent, GitHub, Hugo et l’automatisation IA via FlowHunt, vous disposez d’un système qui transforme les demandes brutes en articles professionnels publiés automatiquement. Le workflow est simple : fournissez un ID de ticket, et le système gère tout, de la génération du contenu à l’intégration GitHub jusqu’à la création de la pull request. Le système de mémoire évite les doublons, et la validation humaine garantit qualité et cohérence. À mesure que votre base s’enrichit, elle devient un atout stratégique qui réduit les coûts de support, améliore la satisfaction et génère du trafic organique. L’implémentation est accessible même sans expertise technique, rendant cette automatisation puissante disponible pour toutes les organisations.
Questions fréquemment posées
Qu’est-ce qu’un ticket LiveAgent ?
Un ticket LiveAgent est une demande ou une question de support client enregistrée dans le système de ticketing LiveAgent. Chaque ticket contient un sujet, un corps de message, des tags et l’historique complet de la conversation, qui peuvent être utilisés pour générer du contenu pour la base de connaissances.
Comment trouver l’ID de mon ticket dans LiveAgent ?
Vous pouvez trouver l’ID de votre ticket de deux manières : (1) Cherchez le libellé 'Ticket' avec l’ID affiché dans l’interface LiveAgent, ou (2) regardez à la fin de l’URL où apparaît 'ID=ID-de-votre-ticket'. Copiez cet ID pour l’utiliser dans le workflow d’automatisation.
Le workflow peut-il ignorer certains types de tickets ?
Oui, le workflow peut être configuré pour ignorer certains types de tickets. Par exemple, vous pouvez choisir d’ignorer les demandes de planification de démo pour éviter la création de pages de base de connaissances en double sur des sujets similaires.
Que se passe-t-il si un article de base de connaissances similaire existe déjà ?
Le workflow utilise une mémoire pour vérifier si un sujet similaire a déjà été traité. S’il trouve une correspondance, il mettra à jour l’article existant si nécessaire ou passera la création pour éviter les doublons.
Comment le workflow s’intègre-t-il à GitHub ?
Le workflow crée ou utilise une branche GitHub existante, génère un fichier markdown avec le bon frontmatter, valide les changements et crée une pull request pour relecture avant fusion dans la branche principale.
Arshia est ingénieure en workflows d'IA chez FlowHunt. Avec une formation en informatique et une passion pour l’IA, elle se spécialise dans la création de workflows efficaces intégrant des outils d'IA aux tâches quotidiennes, afin d’accroître la productivité et la créativité.
Arshia Kahani
Ingénieure en workflows d'IA
Automatisez la création de votre base de connaissances
Transformez automatiquement les tickets de support client en articles SEO optimisés grâce aux workflows IA de FlowHunt.
Comment automatiser les réponses aux tickets dans LiveAgent avec FlowHunt
Découvrez comment intégrer les flux IA de FlowHunt à LiveAgent pour répondre automatiquement aux tickets clients grâce à des règles d’automatisation intelligent...
Des agents IA qui bloguent et codent pour vous : automatiser la création de contenu et les workflows GitHub
Découvrez comment des agents IA peuvent générer automatiquement des articles de blog optimisés SEO, créer des fichiers markdown et soumettre des pull requests G...
Workflows de contenu SEO automatisés pour WordPress : Guide complet pour faire évoluer votre stratégie de contenu
Découvrez comment mettre en place des workflows de contenu SEO automatisés pour WordPress afin de gagner du temps, garantir la cohérence et améliorer votre posi...
19 min de lecture
WordPress
SEO
+3
Consentement aux Cookies Nous utilisons des cookies pour améliorer votre expérience de navigation et analyser notre trafic. See our privacy policy.