Middleware Human-in-the-Loop en Python : Construire des Agents IA Sécurisés avec des Workflows d’Approbation
Découvrez comment implémenter un middleware human-in-the-loop en Python avec LangChain pour ajouter des capacités d’approbation, de modification et de rejet aux agents IA avant l’exécution d’un outil.
Construire des agents IA capables d’exécuter de façon autonome des outils et de prendre des décisions est puissant, mais comporte des risques inhérents. Que se passe-t-il lorsqu’un agent décide d’envoyer un e-mail avec des informations incorrectes, d’approuver une grosse transaction financière ou de modifier des données critiques ? Sans garde-fous adéquats, des agents autonomes peuvent causer d’importants dommages avant même que quiconque ne s’en rende compte. C’est là que le middleware human-in-the-loop devient essentiel. Dans ce guide complet, nous allons explorer comment implémenter un middleware human-in-the-loop en Python avec LangChain, afin de construire des agents IA qui s’arrêtent pour obtenir une validation humaine avant d’exécuter des opérations sensibles. Vous apprendrez à ajouter des workflows d’approbation, à intégrer des capacités de modification, et à gérer les rejets — tout en maintenant l’efficacité et l’intelligence de vos systèmes autonomes.
Comprendre la boucle agent IA et l’exécution d’outils
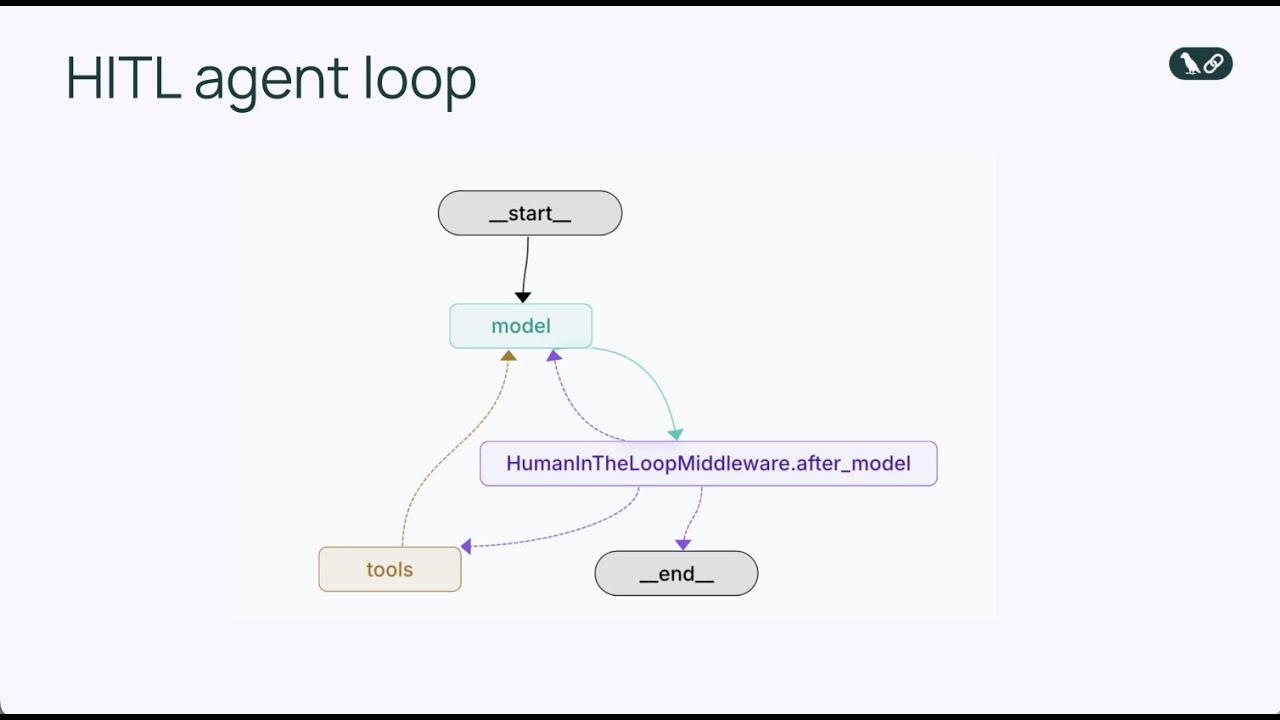
Avant de plonger dans le middleware human-in-the-loop, il est important de comprendre le fonctionnement fondamental des agents IA. Un agent IA opère via une boucle continue qui se répète jusqu’à ce qu’il estime avoir terminé sa tâche. Cette boucle repose sur trois composants principaux : un modèle de langage pour raisonner sur la prochaine action, un ensemble d’outils que l’agent peut invoquer, et un système de gestion d’état qui suit l’historique de la conversation et le contexte pertinent. L’agent commence par recevoir un message utilisateur, puis le modèle de langage analyse cette entrée avec les outils disponibles et décide d’appeler un outil ou de fournir une réponse finale. Si le modèle choisit d’utiliser un outil, celui-ci est exécuté et les résultats sont ajoutés à l’historique de la conversation. Ce cycle se poursuit — raisonnement du modèle, sélection d’outil, exécution, intégration du résultat — jusqu’à ce que le modèle juge qu’aucun autre appel d’outil n’est nécessaire et donne une réponse finale à l’utilisateur.
Ce schéma simple mais puissant est devenu la base de centaines de frameworks d’agents IA ces dernières années. L’élégance de la boucle agent réside dans sa flexibilité : en modifiant les outils disponibles pour un agent, vous pouvez lui permettre d’accomplir des tâches très variées. Un agent doté d’outils d’e-mail peut gérer les communications, un autre avec des outils de base de données peut interroger et mettre à jour des enregistrements, un autre encore avec des outils financiers peut traiter des transactions. Mais cette flexibilité introduit également un risque. Parce que la boucle agent fonctionne de manière autonome, il n’existe aucun mécanisme intégré pour faire une pause et demander à un humain si une action particulière doit réellement être prise. Le modèle peut décider d’envoyer un e-mail, d’exécuter une requête en base de données ou d’approuver une transaction financière, et au moment où un humain s’en aperçoit, l’action a déjà été réalisée. C’est là que les limites de la boucle agent basique apparaissent en production.
Prêt à développer votre entreprise?
Commencez votre essai gratuit aujourd'hui et voyez les résultats en quelques jours.
Pourquoi la supervision humaine est cruciale dans les systèmes IA en production
À mesure que les agents IA deviennent plus performants et sont déployés dans des environnements métier réels, le besoin de supervision humaine devient de plus en plus critique. Les enjeux des actions autonomes varient énormément selon le contexte. Certains appels d’outils sont peu risqués et peuvent être exécutés immédiatement sans revue humaine — par exemple, lire un e-mail ou extraire une information d’une base de données. D’autres sont à fort enjeu et potentiellement irréversibles, comme envoyer une communication au nom d’un utilisateur, transférer des fonds, supprimer des données ou prendre des engagements engageant l’organisation. En production, le coût d’une erreur sur une opération sensible peut être énorme. Un e-mail mal formulé envoyé au mauvais destinataire peut nuire à des relations d’affaires. Un budget approuvé à tort peut entraîner des pertes financières. Une suppression de données par erreur peut mener à une perte d’informations qui prendra des heures ou des jours à restaurer.
Au-delà des risques opérationnels immédiats, il existe aussi des exigences réglementaires et de conformité. De nombreux secteurs imposent que certains types de décisions fassent l’objet d’un jugement et d’une validation humaine. Les institutions financières doivent superviser les transactions dépassant certains seuils. Les systèmes de santé exigent la revue humaine de certaines décisions automatisées. Les cabinets juridiques doivent s’assurer que les communications sont relues avant envoi au nom des clients. Ces obligations ne sont pas de la simple bureaucratie — elles existent car les conséquences d’une prise de décision entièrement autonome peuvent être graves dans ces domaines. Par ailleurs, la supervision humaine offre un mécanisme de feedback qui améliore progressivement l’agent. Lorsqu’un humain revoit une action proposée et l’approuve ou la modifie, ce retour peut servir à ajuster les prompts de l’agent, sa logique de sélection d’outil ou à reentraîner ses modèles. Cela crée un cercle vertueux où l’agent devient plus fiable et mieux adapté aux besoins et à la tolérance au risque de l’organisation.
Qu’est-ce que le middleware human-in-the-loop ?
Le middleware human-in-the-loop est un composant spécialisé qui intercepte la boucle agent à un moment clé : juste avant l’exécution d’un outil. Au lieu de permettre à l’agent d’exécuter immédiatement un appel d’outil, le middleware suspend l’exécution et présente l’action proposée à un humain pour validation. L’humain dispose alors de plusieurs options : il peut approuver l’action, la laissant se dérouler telle que proposée ; la modifier, en ajustant les paramètres comme le destinataire d’un e-mail ou son contenu ; ou la rejeter complètement, en envoyant un retour expliquant pourquoi l’action n’est pas appropriée et en demandant à l’agent de revoir sa proposition. Ce mécanisme décisionnel en trois volets — approuver, modifier, rejeter — offre un cadre flexible adapté à différents besoins de supervision humaine.
Le middleware modifie la boucle agent standard en y ajoutant un point de décision supplémentaire. Dans la boucle basique : le modèle appelle les outils → les outils s’exécutent → les résultats reviennent au modèle. Avec le middleware human-in-the-loop, la séquence devient : le modèle appelle les outils → le middleware intercepte → l’humain revoit → l’humain décide (approuver/modifier/rejeter) → si approuvé ou modifié, l’outil s’exécute → les résultats retournent au modèle. L’ajout de ce point de décision humaine ne casse pas la boucle : il la renforce en ajoutant une soupape de sécurité. Le middleware est configurable : vous pouvez choisir précisément quels outils déclencheront une revue humaine et lesquels pourront s’exécuter automatiquement. Par exemple, vous pouvez interrompre tous les outils d’envoi d’e-mail mais autoriser les requêtes en lecture seule sans validation. Ce contrôle granulaire permet d’ajouter de la supervision humaine là où c’est nécessaire sans créer de goulets d’étranglement sur les opérations à faible risque.
Rejoignez notre newsletter
Recevez gratuitement les derniers conseils, tendances et offres.
Les trois types de réponse : Approbation, Modification, Rejet
Lorsqu’un middleware human-in-the-loop interrompt l’exécution d’un outil, le réviseur humain dispose de trois manières principales de répondre, chacune ayant un objectif précis dans le workflow d’approbation. Comprendre ces trois types de réponse est essentiel pour concevoir des systèmes efficaces.
Approbation est la réponse la plus simple. Lorsque le réviseur estime que l’appel d’outil proposé est approprié et doit être exécuté tel quel, il fournit une décision d’approbation. Le middleware exécute l’outil avec les paramètres exacts définis par l’agent. Dans le contexte d’un assistant e-mail, l’approbation signifie que le brouillon est correct et sera envoyé au destinataire indiqué avec l’objet et le texte proposés. L’approbation est la voie la plus rapide — elle permet à l’action d’avancer sans modification, appropriée lorsque l’agent a bien travaillé et que le réviseur humain est d’accord. Les décisions d’approbation sont généralement rapides, ce qui est important pour éviter que la revue humaine ne ralentisse tout le workflow.
Modification est une réponse plus nuancée qui reconnaît que la démarche générale de l’agent est correcte mais que certains détails nécessitent un ajustement avant exécution. En fournissant une réponse de modification, l’humain ne rejette pas l’action, mais affine ses modalités. Dans le cas d’un e-mail, cela peut consister à changer le destinataire, reformuler l’objet ou le texte, ajouter du contexte ou supprimer des formulations problématiques. L’essentiel est que la modification ajuste les paramètres de l’outil tout en gardant la même intention. L’agent décide d’envoyer un e-mail, l’humain est d’accord mais veut ajuster le contenu ou le destinataire. Après modification, l’outil est exécuté avec les nouveaux paramètres et les résultats sont transmis à l’agent. Ce type de réponse est très précieux car il permet à l’agent de proposer des actions tout en laissant à l’humain le soin de les finaliser selon son expertise métier ou sa connaissance du contexte.
Rejet est la réponse la plus significative car elle empêche l’exécution de l’action proposée et fournit un retour à l’agent sur la raison du refus. Quand un humain rejette un appel d’outil, il indique que l’action proposée ne doit pas être effectuée, et explique à l’agent pourquoi il doit revoir son approche. Par exemple, dans le cas d’un e-mail, le rejet peut se produire si l’agent propose d’approuver un important budget sans justification. Le réviseur rejette cette action et envoie à l’agent un message expliquant que plus de détails sont nécessaires. Ce message de rejet fait partie du contexte de l’agent, qui peut alors raisonner sur ce retour et proposer une nouvelle approche, comme envoyer un e-mail demandant plus d’informations. Les rejets sont essentiels pour éviter que l’agent ne répète la même action inappropriée. En fournissant un feedback clair, vous aidez l’agent à s’améliorer dans ses décisions.
Implémenter le middleware human-in-the-loop : un exemple concret
Illustrons l’implémentation du middleware human-in-the-loop avec LangChain et Python. Prenons l’exemple d’un assistant e-mail, un cas pratique qui démontre la valeur de la supervision humaine, tout en restant simple à comprendre. Cet assistant pourra envoyer des e-mails au nom de l’utilisateur, mais nous allons ajouter le middleware pour que chaque envoi soit validé.
Il faut d’abord définir l’outil d’e-mail utilisé par l’agent, qui prend trois paramètres : le destinataire, l’objet, le corps du message. L’outil est simple — il représente l’action d’envoyer un e-mail. Dans une vraie application, cela pourrait s’intégrer à Gmail ou Outlook, mais pour l’exemple, restons basiques :
defsend_email(recipient: str, subject: str, body: str) -> str:
"""Envoyer un e-mail au destinataire spécifié."""returnf"Email envoyé à {recipient} avec l’objet '{subject}'"
Ensuite, nous créons un agent qui utilise cet outil. Nous utilisons GPT-4 comme modèle de langage et fournissons un prompt système indiquant que l’agent est un assistant e-mail utile. L’agent est initialisé avec l’outil d’e-mail :
from langchain.agents import create_agent
from langchain_openai import ChatOpenAI
model = ChatOpenAI(model="gpt-4o")
tools = [send_email]
agent = create_agent(
model=model,
tools=tools,
system_prompt="Vous êtes un assistant e-mail utile pour Sydney. Vous pouvez envoyer des e-mails au nom de l’utilisateur.")
À ce stade, l’agent peut envoyer des e-mails, mais sans aucune supervision humaine. Ajoutons maintenant le middleware human-in-the-loop, ce qui est remarquablement simple, en seulement deux lignes de code :
from langchain.agents.middleware import HumanInTheLoopMiddleware
agent = create_agent(
model=model,
tools=tools,
system_prompt="Vous êtes un assistant e-mail utile pour Sydney. Vous pouvez envoyer des e-mails au nom de l’utilisateur.",
middleware=[
HumanInTheLoopMiddleware(
interrupt_on={"send_email": True}
)
]
)
En ajoutant HumanInTheLoopMiddleware et en spécifiant interrupt_on={"send_email": True}, on indique à l’agent de s’arrêter avant chaque appel à send_email et d’attendre une validation humaine. La valeur True signifie que tous les appels seront interrompus avec la configuration par défaut. Pour un contrôle plus fin, on peut spécifier quels types de décisions sont autorisés (approuver, modifier, rejeter) ou fournir des descriptions personnalisées.
Tester le middleware sur des scénarios à faible enjeu
Une fois le middleware en place, testons-le sur un scénario d’e-mail à faible enjeu. Par exemple, l’utilisateur demande à l’agent de répondre à une collègue, Alice, qui propose un café la semaine prochaine. L’agent traite la demande et propose un e-mail amical. Voici comment cela se déroule :
L’utilisateur envoie : « Merci de répondre à l’e-mail d’Alice pour un café la semaine prochaine. »
Le modèle de l’agent décide d’appeler l’outil avec recipient=“alice@example.com
”, subject=“Café la semaine prochaine ?”, body=“Avec plaisir pour un café la semaine prochaine !”
Avant l’envoi réel, le middleware intercepte l’appel.
Le réviseur humain voit l’e-mail, le trouve approprié — amical, professionnel, conforme à la demande.
L’humain approuve.
Le middleware autorise l’exécution et l’e-mail est envoyé.
Ce workflow illustre la voie d’approbation. La revue humaine ajoute une couche de sécurité sans ralentir le processus. Pour des opérations à faible enjeu, l’approbation se fait rapidement car l’action proposée est raisonnable.
Tester le middleware sur des scénarios à fort enjeu : la réponse de modification
Passons à un scénario plus conséquent où la modification prend toute sa valeur. Imaginons que l’agent doit répondre à un partenaire startup qui demande la validation d’un budget ingénierie d’un million d’euros pour le T1. L’agent propose alors un e-mail du type : « J’ai examiné et approuvé la proposition de budget de 1 million d’euros pour le T1. »
Lorsque cet e-mail est présenté au réviseur humain, celui-ci réalise qu’il s’agit d’un engagement financier majeur qui ne doit pas être validé à la légère. Il ne souhaite pas rejeter l’idée de répondre, mais modifie le message pour être plus prudent, par exemple : « Merci pour la proposition. Je souhaite examiner les détails avant de donner mon accord. Pouvez-vous me transmettre une ventilation du budget ? »
En code, une décision de modification ressemble à ceci :
edit_decision = {
"type": "edit",
"edited_action": {
"name": "send_email",
"args": {
"recipient": "partner@startup.com",
"subject": "Proposition de budget ingénierie T1",
"body": "Merci pour la proposition. Je souhaite examiner les détails avant de donner mon accord. Pouvez-vous me transmettre une ventilation du budget ?" }
}
}
Le middleware exécute alors l’outil avec ces paramètres modifiés. L’e-mail envoyé reprend le contenu révisé par l’humain, bien plus adapté pour une décision financière majeure. Cela démontre la puissance de la modification : permettre à l’humain d’ajuster les actions proposées par l’agent selon le contexte.
Tester le middleware avec rejet et feedback
Le rejet est particulièrement puissant car il bloque une action inappropriée tout en aidant l’agent à améliorer son raisonnement. Reprenons l’exemple du budget : l’agent propose un e-mail disant : « J’ai examiné et approuvé le budget de 1 million d’euros pour le T1. »
Le réviseur humain estime que c’est bien trop hâtif. Un tel engagement doit faire l’objet d’une revue approfondie. Plutôt que de modifier, il rejette l’approche et demande à l’agent de revoir sa proposition, par exemple :
reject_decision = {
"type": "reject",
"message": "Je ne peux pas approuver ce budget sans plus d’informations. Merci de rédiger un e-mail demandant une ventilation détaillée de la proposition, incluant la répartition des fonds et les livrables attendus."}
Le middleware ne lance pas l’action, mais renvoie ce message de rejet à l’agent dans le contexte de conversation. L’agent comprend le motif du refus et peut proposer une nouvelle approche, comme solliciter plus d’informations, ce qui est bien plus approprié pour une demande de budget conséquent. L’humain peut alors approuver, modifier ou rejeter à nouveau.
Ce processus itératif — proposer, revoir, rejeter avec feedback, proposer à nouveau — est l’un des apports majeurs du middleware human-in-the-loop. Il instaure une collaboration entre la rapidité de l’agent et le jugement humain.
Boostez votre workflow avec FlowHunt
Découvrez comment FlowHunt automatise la production de contenu et les workflows SEO par l’IA — de la recherche à la génération et à la publication/analyse — tout-en-un.
Configuration avancée : contrôle granulaire des interruptions
Si l’implémentation basique du middleware human-in-the-loop est simple, LangChain offre des options avancées permettant d’affiner précisément comment et quand les interruptions surviennent. Un paramètre important est de spécifier quels types de décisions sont autorisés pour chaque outil. Par exemple, vous pouvez permettre l’approbation et la modification pour les e-mails, mais pas le rejet. Ou autoriser les trois décisions pour les transactions financières, mais seulement l’approbation pour les requêtes en lecture.
Exemple de configuration granulaire :
from langchain.agents.middleware import HumanInTheLoopMiddleware
agent = create_agent(
model=model,
tools=tools,
middleware=[
HumanInTheLoopMiddleware(
interrupt_on={
"send_email": {
"allowed_decisions": ["approve", "edit", "reject"]
},
"read_database": False, # Exécution automatique, pas d’interruption"delete_record": {
"allowed_decisions": ["approve", "reject"] # Pas de modification pour les suppressions }
}
)
]
)
Dans cette configuration, l’envoi d’e-mails interrompt et permet les trois types de décisions. Les lectures sont exécutées sans interruption. Les suppressions interrompent mais sans possibilité de modification — l’humain peut seulement approuver ou rejeter. Ce contrôle granulaire permet d’ajuster la supervision humaine précisément là où elle est utile.
Autre fonctionnalité avancée : fournir des descriptions personnalisées pour les interruptions. Par défaut, le middleware affiche « L’exécution de l’outil requiert une approbation ». Vous pouvez personnaliser ce message pour plus de contexte :
HumanInTheLoopMiddleware(
interrupt_on={
"send_email": {
"allowed_decisions": ["approve", "edit", "reject"],
"description": "L’envoi d’e-mails requiert une approbation humaine avant exécution" }
}
)
Points d’attention importants : checkpointer et gestion d’état
Un aspect essentiel de l’implémentation du middleware human-in-the-loop, souvent négligé, est la nécessité d’un checkpointer. Un checkpointer sauvegarde l’état de l’agent au moment de l’interruption, permettant la reprise ultérieure du workflow. C’est indispensable car la revue humaine n’est pas instantanée — il peut y avoir un délai entre l’interruption et la décision. Sans checkpointer, l’état de l’agent serait perdu, impossible de reprendre correctement.
LangChain propose plusieurs options de checkpointer. Pour le développement et les tests, utilisez un checkpointer en mémoire :
En production, il faut généralement utiliser un checkpointer persistant (base de données ou fichier), garantissant la reprise même après redémarrage de l’application. Le checkpointer conserve l’historique complet à chaque étape, y compris la conversation, les appels d’outils et leurs résultats. Lorsqu’un humain fournit une décision (approuver, modifier, rejeter), le middleware utilise le checkpointer pour restaurer l’état, appliquer la décision et reprendre la boucle agent.
Cas d’usage réels et applications
Le middleware human-in-the-loop s’applique à de nombreux scénarios où des agents autonomes doivent agir mais où ces actions nécessitent une validation humaine. Dans la finance, les agents qui traitent des transactions, valident des crédits ou gèrent des investissements peuvent s’appuyer sur le middleware pour que les décisions majeures soient revues. En santé, les agents recommandant des traitements ou accédant aux dossiers patients peuvent garantir la conformité avec la réglementation et les protocoles. Dans le juridique, les agents rédigeant des communications ou accédant à des documents confidentiels peuvent assurer une supervision d’avocat. En service client, les agents pouvant accorder des remboursements ou prendre des engagements peuvent garantir l’alignement avec la politique de l’entreprise.
Au-delà de ces secteurs, le middleware est pertinent dans tout contexte où le coût d’une erreur est élevé : modération de contenu, RH (décisions d’embauche), logistique (commandes, inventaire), etc. Le point commun : les actions proposées par l’agent ont des conséquences réelles, suffisantes pour justifier une revue humaine.
Comparaison avec les approches alternatives
Il est utile de comparer le middleware human-in-the-loop à d’autres méthodes de supervision humaine. Une première alternative consiste à relire toutes les actions de l’agent après exécution, mais cette méthode a une limite majeure : quand l’action est revue, il est souvent trop tard (e-mail envoyé, donnée supprimée, transaction traitée). Le middleware empêche que ces actions irréversibles se produisent.
Une seconde alternative est de confier manuellement toutes les tâches à des humains, mais cela annule l’intérêt des agents : automatiser les tâches répétitives pour libérer du temps humain sur la décision. Le middleware vise un juste équilibre : laisser l’agent gérer l’exécution de routine, mais interrompre pour une validation humaine lorsque l’enjeu le justifie.
Une troisième alternative consiste à mettre en place des garde-fous ou règles de validation empêchant les actions inappropriées. Par exemple, interdire l’envoi d’e-mails hors de l’organisation ou la suppression de données sans confirmation. Ces garde-fous sont utiles mais ont leurs limites : ils sont souvent basés sur des règles et ne couvrent pas tous les cas contextuels. Le jugement humain reste plus flexible et pertinent, d’où la valeur du middleware human-in-the-loop.
Bonnes pratiques pour la mise en œuvre des workflows human-in-the-loop
Pour garantir l’efficacité de votre système, voici quelques bonnes pratiques. D’abord, soyez stratégique sur les outils à interrompre : tout interrompre crée des goulets d’étranglement. Ciblez les outils coûteux, risqués ou à fort enjeu. Les opérations en lecture seule n’ont généralement pas besoin d’interruption ; les écritures ou actions externes, si.
Ensuite, fournissez un contexte clair aux réviseurs. Lors d’une interruption, l’humain doit comprendre l’action proposée et ses raisons. Rédigez des descriptions explicites et montrez tout le contexte utile (contenu complet d’un e-mail, détails d’une suppression…).
Faites du processus d’approbation quelque chose de fluide : des options claires (approuver, modifier, rejeter), des modifications faciles à appliquer sans connaissance technique.
Utilisez le feedback de rejet à bon escient : expliquez la raison du refus et ce que l’agent doit faire à la place. Ce retour aide à affiner les décisions de l’agent au fil du temps.
Enfin, analysez les motifs d’interruption : quels outils sont le plus souvent interrompus ? Quelles décisions sont les plus fréquentes ? Combien de temps prend la validation ? Ces données permettent d’optimiser la configuration et d’affiner la logique de l’agent.
Intégrer le middleware human-in-the-loop avec FlowHunt
Pour les organisations souhaitant déployer à grande échelle, FlowHunt propose une plateforme intégrée avec les capacités du middleware LangChain. FlowHunt permet de construire, déployer et gérer des agents IA avec workflows d’approbation intégrés, de configurer précisément les outils à valider, de personnaliser l’interface d’approbation et de tracer toutes les décisions pour la conformité. La plateforme gère la complexité de la gestion d’état, du checkpointing et de l’orchestration des workflows, vous concentrant sur la construction d’agents efficaces et la définition des politiques d’approbation. Son intégration avec LangChain vous offre le plein potentiel du middleware human-in-the-loop, avec une interface conviviale et une fiabilité professionnelle.
Conclusion
Le middleware human-in-the-loop constitue un pont essentiel entre l’efficacité des agents IA autonomes et la nécessité de supervision humaine en production. En mettant en œuvre des workflows d’approbation, des capacités de modification et des mécanismes de feedback, vous pouvez bâtir des agents puissants et sûrs. Le modèle décisionnel en trois volets — approuver, modifier, rejeter — offre la flexibilité de gérer différents niveaux de supervision, des opérations bénignes aux décisions stratégiques nécessitant une attention particulière. Sa mise en œuvre est simple, quelques lignes de code suffisent à enrichir vos agents LangChain, mais l’impact sur la fiabilité et la sécurité du système est considérable. À mesure que les agents IA gagnent en puissance et en responsabilité, le middleware human-in-the-loop s’imposera comme un composant incontournable d’un déploiement IA responsable. Que vous bâtissiez des assistants e-mail, des systèmes financiers, des applications de santé ou tout autre domaine où les actions des agents ont des conséquences réelles, le middleware human-in-the-loop garantit que le discernement humain reste au cœur de vos workflows automatisés.
Questions fréquemment posées
Le middleware human-in-the-loop est un composant qui interrompt l’exécution de l’agent IA avant l’utilisation de certains outils, permettant à un humain d’approuver, modifier ou rejeter l’action proposée. Cela ajoute une couche de sécurité pour les opérations coûteuses ou risquées.
Utilisez-le pour les opérations à fort enjeu comme l’envoi d’e-mails, les transactions financières, les écritures en base de données, ou toute exécution d’outil nécessitant une supervision de conformité ou pouvant avoir des conséquences importantes en cas d’erreur.
Les trois principaux types de réponses sont : Approbation (exécuter l’outil tel que proposé), Modification (modifier les paramètres de l’outil avant exécution) et Rejet (refuser l’exécution et renvoyer un feedback au modèle pour révision).
Importez HumanInTheLoopMiddleware depuis langchain.agents.middleware, configurez-le avec les outils sur lesquels vous souhaitez intercepter, et passez-le à la fonction de création de l’agent. Vous aurez également besoin d’un checkpointer pour conserver l’état entre les interruptions.
Arshia est ingénieure en workflows d'IA chez FlowHunt. Avec une formation en informatique et une passion pour l’IA, elle se spécialise dans la création de workflows efficaces intégrant des outils d'IA aux tâches quotidiennes, afin d’accroître la productivité et la créativité.
Arshia Kahani
Ingénieure en workflows d'IA
Automatisez vos workflows IA en toute sécurité avec FlowHunt
Construisez des agents intelligents avec des workflows d’approbation intégrés et une supervision humaine. FlowHunt facilite la mise en œuvre de l’automatisation human-in-the-loop pour vos processus métier.
Construire des agents IA extensibles : plongée dans l’architecture middleware
Découvrez comment l’architecture middleware de LangChain 1.0 révolutionne le développement d’agents, permettant aux développeurs de créer de puissants agents pr...
L’ingénierie du contexte pour les agents IA : maîtriser l’art de fournir la bonne information aux LLM
Découvrez comment concevoir le contexte pour les agents IA en gérant les retours d’outils, en optimisant l’utilisation des tokens et en appliquant des stratégie...
Le Human-in-the-Loop (HITL) est une approche de l’IA et de l’apprentissage automatique qui intègre l’expertise humaine dans la formation, l’ajustement et l’appl...
2 min de lecture
AI
Human-in-the-Loop
+4
Consentement aux Cookies Nous utilisons des cookies pour améliorer votre expérience de navigation et analyser notre trafic. See our privacy policy.