Comment Tester un Chatbot IA
Découvrez des stratégies complètes de test de chatbots IA incluant des tests fonctionnels, de performance, de sécurité et d’utilisabilité. Explorez les meilleur...
13 min de lecture
Découvrez des méthodes complètes pour mesurer la précision d’un chatbot d’assistance IA en 2025. Découvrez la précision, le rappel, les scores F1, les indicateurs de satisfaction utilisateur et des techniques d’évaluation avancées avec FlowHunt.
Mesurez la précision d’un chatbot d’assistance IA grâce à des indicateurs multiples incluant les calculs de précision et de rappel, les matrices de confusion, les scores de satisfaction utilisateur, les taux de résolution et des méthodes d’évaluation avancées basées sur les LLM. FlowHunt fournit des outils complets pour l’évaluation automatisée de la précision et le suivi des performances.
Mesurer la précision d’un chatbot d’assistance IA est essentiel pour garantir qu’il fournisse des réponses fiables et utiles aux demandes des clients. Contrairement aux tâches de classification simples, la précision d’un chatbot englobe plusieurs dimensions qui doivent être évaluées ensemble pour obtenir une vision complète des performances. Le processus consiste à analyser la capacité du chatbot à comprendre les requêtes utilisateur, fournir des informations correctes, résoudre efficacement les problèmes, et maintenir la satisfaction des utilisateurs tout au long des interactions. Une stratégie de mesure complète combine des indicateurs quantitatifs avec des retours qualitatifs pour identifier les points forts et les axes d’amélioration.
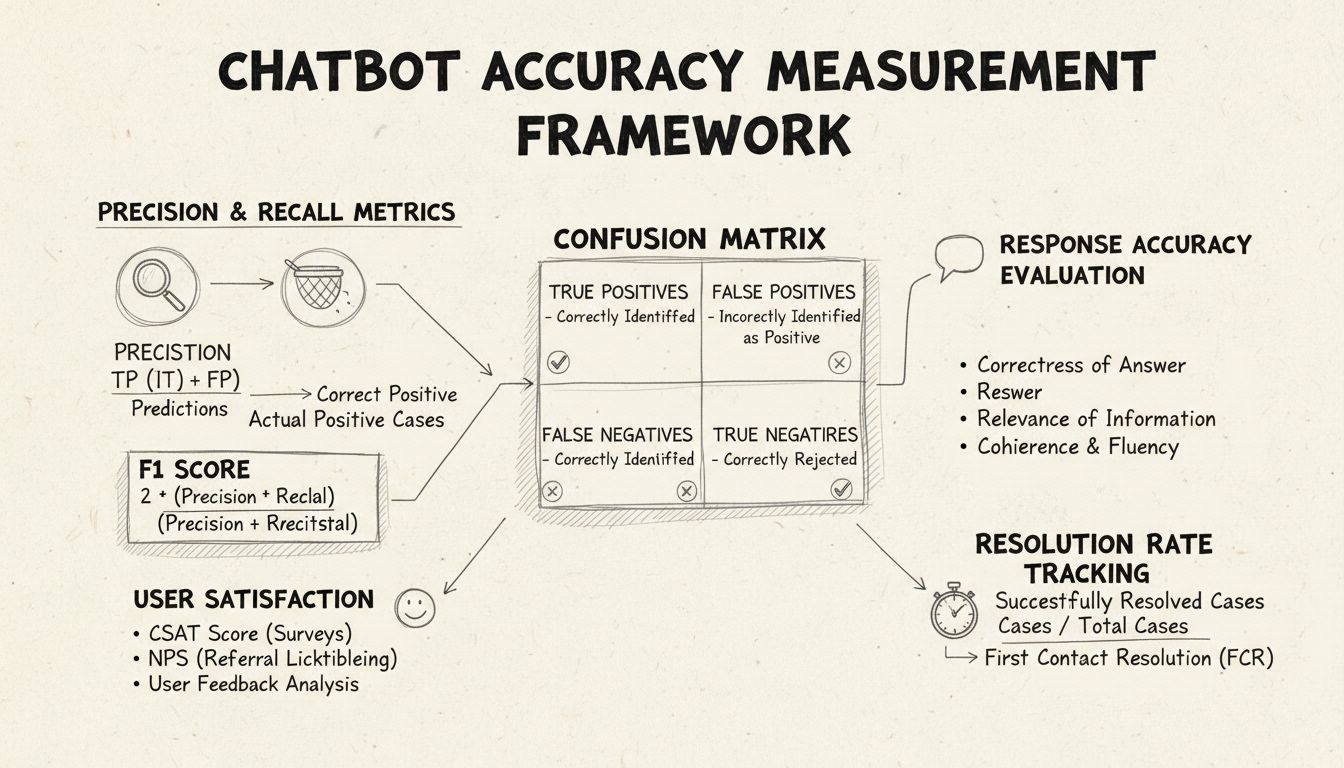
La précision et le rappel sont des indicateurs fondamentaux issus de la matrice de confusion, mesurant différents aspects des performances du chatbot. La précision représente la proportion de réponses correctes parmi toutes les réponses fournies par le chatbot, calculée par la formule : Précision = Vrais positifs / (Vrais positifs + Faux positifs). Cette mesure répond à la question : « Lorsque le chatbot fournit une réponse, à quelle fréquence est-elle correcte ? » Un score de précision élevé indique que le chatbot donne rarement des informations incorrectes, ce qui est critique pour maintenir la confiance utilisateur dans le contexte de l’assistance.
Le rappel, également appelé sensibilité, mesure la proportion de réponses correctes parmi toutes les réponses correctes que le chatbot aurait dû fournir, selon la formule : Rappel = Vrais positifs / (Vrais positifs + Faux négatifs). Cet indicateur permet de savoir si le chatbot parvient à identifier et traiter toutes les problématiques légitimes des clients. Dans les contextes d’assistance, un rappel élevé garantit que les clients reçoivent de l’aide pour leurs problèmes au lieu d’être informés à tort que le chatbot ne peut pas les aider alors qu’il en serait capable. La relation entre précision et rappel crée un compromis naturel : optimiser l’un se fait souvent au détriment de l’autre, exigeant un équilibre en fonction de vos priorités métier.
Le score F1 offre un indicateur unique qui équilibre précision et rappel, calculé comme la moyenne harmonique : F1 = 2 × (Précision × Rappel) / (Précision + Rappel). Ce score est particulièrement précieux lorsque vous souhaitez un indicateur de performance unifié ou lorsque vous traitez des jeux de données déséquilibrés où une classe est beaucoup plus représentée que l’autre. Par exemple, si votre chatbot traite 1 000 demandes courantes et seulement 50 demandes complexes, le score F1 empêche que l’indicateur ne soit biaisé par la classe majoritaire. Le score F1 varie de 0 à 1, 1 représentant une précision et un rappel parfaits, ce qui le rend intuitif pour que les parties prenantes saisissent d’un coup d’œil la performance globale du chatbot.
La matrice de confusion est un outil fondamental qui décompose les performances du chatbot en quatre catégories : vrais positifs (réponses correctes à des requêtes valides), vrais négatifs (refus corrects de répondre à des questions hors-sujet), faux positifs (réponses incorrectes), et faux négatifs (opportunités manquées d’aider). Cette matrice permet de révéler des schémas précis d’échecs du chatbot, ouvrant la voie à des améliorations ciblées. Par exemple, si la matrice révèle un taux élevé de faux négatifs pour les demandes de facturation, cela indique que les données d’entraînement du chatbot manquent d’exemples pertinents et nécessitent un enrichissement dans ce domaine.
| Indicateur | Définition | Calcul | Impact métier |
|---|---|---|---|
| Vrai positif (VP) | Réponses correctes à des requêtes valides | Compté directement | Renforce la confiance client |
| Vrai négatif (VN) | Refus correct de répondre à des questions hors-sujet | Compté directement | Évite la désinformation |
| Faux positif (FP) | Réponses incorrectes fournies | Compté directement | Porte atteinte à la crédibilité |
| Faux négatif (FN) | Opportunités manquées d’aider | Compté directement | Réduit la satisfaction |
| Précision | Qualité des prédictions positives | VP / (VP + FP) | Indicateur de fiabilité |
| Rappel | Couverture des positifs réels | VP / (VP + FN) | Indicateur d’exhaustivité |
| Exactitude | Justesse globale | (VP + VN) / Total | Performance générale |
La précision des réponses mesure la fréquence à laquelle le chatbot fournit des informations exactes et directement adaptées à la requête de l’utilisateur. Cela va au-delà de la simple correspondance de motifs : il s’agit d’évaluer si le contenu est exact, à jour et pertinent dans le contexte. Les processus de revue manuelle consistent à faire évaluer un échantillon aléatoire de conversations par des humains, en comparant les réponses du chatbot à une base de connaissances de réponses correctes. Des méthodes automatiques peuvent être mises en œuvre via des techniques de traitement automatique du langage pour comparer les réponses aux attendus stockés dans votre système, bien que cela nécessite un calibrage précis pour éviter les faux négatifs lorsque le chatbot donne une bonne réponse avec des mots différents de la référence.
La pertinence des réponses évalue si la réponse du chatbot s’adresse réellement à la question posée par l’utilisateur, même si la réponse n’est pas parfaitement exacte. Cette dimension prend en compte les situations où le chatbot fournit des informations utiles qui, bien que n’étant pas la réponse exacte, font progresser la résolution. Des méthodes NLP telles que la similarité cosinus permettent de mesurer la similarité sémantique entre la question de l’utilisateur et la réponse du chatbot, offrant un score de pertinence automatisé. Les mécanismes de retour utilisateur, comme les évaluations « pouce en l’air/pouce en bas » après chaque interaction, permettent une évaluation directe de la pertinence par les personnes les plus concernées : vos clients. Ces retours doivent être collectés et analysés en continu pour identifier les types de requêtes bien traitées par le chatbot et celles posant problème.
Le score de satisfaction client (CSAT) mesure la satisfaction des utilisateurs à travers des enquêtes directes, généralement sur une échelle de 1 à 5 ou via des évaluations simples. Après chaque interaction, l’utilisateur est invité à noter sa satisfaction, fournissant un retour immédiat sur la capacité du chatbot à répondre à ses besoins. Un CSAT supérieur à 80 % indique généralement de bonnes performances, tandis qu’un score inférieur à 60 % signale des problèmes importants à investiguer. L’avantage du CSAT réside dans sa simplicité et son caractère direct : l’utilisateur exprime explicitement sa satisfaction, mais celle-ci peut être influencée par d’autres facteurs que la précision du chatbot, comme la complexité du problème ou les attentes de l’utilisateur.
Le Net Promoter Score mesure la probabilité que les utilisateurs recommandent le chatbot à d’autres, en posant la question « Recommanderiez-vous ce chatbot à un collègue ? » sur une échelle de 0 à 10. Les notes de 9-10 désignent les promoteurs, 7-8 les passifs, et 0-6 les détracteurs. NPS = (Promoteurs - Détracteurs) / Nombre total de répondants × 100. Cet indicateur est fortement corrélé à la fidélité client sur le long terme et renseigne sur la capacité du chatbot à générer des expériences positives que les utilisateurs souhaitent partager. Un NPS supérieur à 50 est considéré comme excellent, tandis qu’un NPS négatif signale de graves problèmes de performance.
L’analyse de sentiment examine le ton émotionnel des messages utilisateur avant et après l’interaction avec le chatbot pour évaluer la satisfaction. Les techniques NLP avancées classent les messages comme positifs, neutres ou négatifs, révélant si l’utilisateur est devenu plus satisfait ou frustré au fil de la conversation. Une évolution positive du sentiment indique que le chatbot a su répondre aux préoccupations, tandis qu’une évolution négative suggère que le chatbot a frustré l’utilisateur ou n’a pas répondu à ses besoins. Cet indicateur capte la dimension émotionnelle que les mesures classiques de précision ne couvrent pas, apportant un contexte précieux pour comprendre la qualité de l’expérience utilisateur.
La résolution au premier contact mesure le pourcentage de problèmes clients résolus par le chatbot sans transfert à un agent humain. Cet indicateur a un impact direct sur l’efficacité opérationnelle et la satisfaction client, car les clients préfèrent que leurs problèmes soient résolus immédiatement plutôt que d’être transférés. Un taux FCR supérieur à 70 % indique un chatbot performant, tandis qu’un taux inférieur à 50 % suggère que le chatbot manque de connaissances ou de capacités pour traiter les demandes courantes. Le suivi du FCR par catégorie de problème met en évidence les domaines maîtrisés par le chatbot et ceux nécessitant l’intervention humaine, ce qui guide l’enrichissement de la base de connaissances et la formation.
Le taux d’escalade mesure la fréquence à laquelle le chatbot transfère des conversations à des agents humains, tandis que la fréquence des retours par défaut indique à quelle fréquence le chatbot répond de manière générique (« Je ne comprends pas », « Veuillez reformuler votre question »). Un taux d’escalade élevé (supérieur à 30 %) indique que le chatbot manque de connaissances ou de confiance dans de nombreux scénarios, tandis qu’un taux de retours par défaut élevé suggère une mauvaise reconnaissance des intentions ou des données d’entraînement insuffisantes. Ces indicateurs mettent en évidence des lacunes spécifiques dans les capacités du chatbot pouvant être corrigées via l’expansion de la base de connaissances, la réentraînement du modèle ou l’amélioration des composants de compréhension du langage.
Le temps de réponse mesure la rapidité avec laquelle le chatbot répond à l’utilisateur, généralement en millisecondes ou secondes. Les utilisateurs attendent des réponses quasi instantanées ; des délais supérieurs à 3-5 secondes impactent fortement la satisfaction. Le temps de traitement mesure la durée totale entre le début de l’échange et la résolution ou l’escalade du problème, renseignant sur l’efficacité du chatbot. Un temps de traitement court traduit une compréhension rapide et une résolution efficace, tandis qu’un temps long signale des besoins fréquents de clarification ou une difficulté à traiter les demandes complexes. Ces indicateurs doivent être suivis séparément par catégorie de problème, car les problématiques techniques complexes nécessitent naturellement plus de temps que les questions FAQ classiques.
La méthode « LLM As a Judge » représente une approche d’évaluation sophistiquée où un grand modèle de langage évalue les réponses d’un autre système IA. Cette méthodologie est particulièrement efficace pour évaluer simultanément plusieurs dimensions de qualité, telles que la précision, la pertinence, la cohérence, la fluidité, la sécurité, l’exhaustivité et le ton. Les études montrent que les juges LLM peuvent atteindre jusqu’à 85 % d’alignement avec les évaluations humaines, en faisant une alternative évolutive à la revue manuelle. L’approche consiste à définir des critères d’évaluation précis, rédiger des consignes détaillées avec exemples, fournir au juge la requête utilisateur et la réponse du chatbot, puis à recevoir des scores structurés ou des retours détaillés.
Le processus LLM As a Judge utilise généralement deux approches : l’évaluation de sortie unique, où le juge note une réponse individuelle via une évaluation sans référence (sans vérité terrain) ou une comparaison à une réponse attendue, et la comparaison par paires, où le juge compare deux réponses pour identifier la meilleure. Cette flexibilité permet d’évaluer à la fois la performance absolue et les améliorations relatives lors de tests de différentes versions de chatbot. La plateforme FlowHunt permet de mettre en œuvre cette méthodologie via son interface visuelle, l’intégration avec des LLMs de pointe comme ChatGPT et Claude, et un toolkit CLI pour des rapports avancés et des évaluations automatisées.
Au-delà des calculs de précision de base, une analyse détaillée de la matrice de confusion révèle des schémas spécifiques d’échec du chatbot. En examinant quels types de requêtes produisent des faux positifs ou des faux négatifs, vous pouvez identifier des faiblesses systématiques. Par exemple, si la matrice montre que le chatbot classe souvent des questions de facturation comme des demandes de support technique, cela révèle un déséquilibre des données d’entraînement ou un problème de reconnaissance d’intention spécifique à la facturation. Créer des matrices de confusion distinctes par catégorie de problème permet d’engager des améliorations ciblées plutôt qu’un simple réentraînement global.
Les tests A/B consistent à comparer différentes versions du chatbot pour déterminer laquelle performe le mieux sur des indicateurs clés. Cela peut concerner des modèles de réponse, des configurations de base de connaissances ou des modèles de langage sous-jacents. En dirigeant aléatoirement une partie du trafic vers chaque version et en comparant des indicateurs comme le taux FCR, les scores CSAT ou la précision des réponses, vous pouvez prendre des décisions éclairées sur les améliorations à adopter. Les tests A/B doivent être menés sur une durée suffisante pour capter la variation naturelle des requêtes et garantir la significativité statistique des résultats.
FlowHunt propose une plateforme intégrée pour créer, déployer et évaluer des chatbots d’assistance IA avec des capacités avancées de mesure de précision. Le constructeur visuel de la plateforme permet aux non-techniciens de concevoir des flux sophistiqués, tandis que ses composants IA s’intègrent avec les LLMs de pointe comme ChatGPT et Claude. La boîte à outils d’évaluation de FlowHunt permet d’implémenter la méthodologie LLM As a Judge, vous permettant de définir vos critères d’évaluation personnalisés et d’évaluer automatiquement la performance du chatbot sur l’ensemble de vos conversations.
Pour mettre en œuvre une mesure complète avec FlowHunt, commencez par définir vos critères d’évaluation en lien avec les objectifs métier : que vous privilégiez la précision, la rapidité, la satisfaction utilisateur ou le taux de résolution. Configurez le LLM « juge » avec des consignes détaillées spécifiant les modalités d’évaluation, accompagnées d’exemples de bonnes et mauvaises réponses. Importez votre jeu de conversations ou connectez le trafic en temps réel, puis lancez les évaluations pour générer des rapports détaillés sur tous les indicateurs. Le tableau de bord FlowHunt offre une visibilité en temps réel sur la performance du chatbot, facilitant l’identification rapide des problèmes et la validation des améliorations.
Établissez une mesure de référence avant toute amélioration pour disposer d’un point de comparaison. Collectez les mesures de façon continue plutôt que ponctuelle, afin de détecter précocement toute dégradation due à la dérive des données ou à l’obsolescence du modèle. Mettez en place des boucles de rétroaction où les évaluations et corrections utilisateur alimentent automatiquement le processus d’entraînement, améliorant continuellement la précision du chatbot. Segmentez les indicateurs par catégorie de problème, type d’utilisateur et période pour cibler les axes d’amélioration au lieu de se limiter aux statistiques globales.
Assurez-vous que votre jeu d’évaluation reflète les véritables requêtes et réponses attendues des utilisateurs, en évitant les cas de test artificiels qui ne correspondent pas aux usages réels. Validez régulièrement les indicateurs automatisés par une évaluation humaine d’un échantillon de conversations pour garantir l’alignement du système de mesure avec la qualité réelle. Documentez clairement votre méthodologie de mesure et la définition des indicateurs pour assurer la cohérence dans le temps et faciliter la communication des résultats aux parties prenantes. Enfin, fixez des objectifs de performance pour chaque indicateur en cohérence avec les attentes métier, afin d’assurer l’amélioration continue et d’orienter vos efforts d’optimisation.
La plateforme avancée d’automatisation IA de FlowHunt vous aide à créer, déployer et évaluer des chatbots d’assistance performants avec des outils intégrés de mesure de précision et des capacités d’évaluation basées sur les LLM.
Découvrez des stratégies complètes de test de chatbots IA incluant des tests fonctionnels, de performance, de sécurité et d’utilisabilité. Explorez les meilleur...
Découvrez des méthodes éprouvées pour vérifier l’authenticité d’un chatbot IA en 2025. Explorez les techniques de vérification technique, les contrôles de sécur...
Maîtrisez l'utilisation des chatbots IA grâce à notre guide complet. Découvrez des techniques de formulation efficaces, les meilleures pratiques et comment tire...
Consentement aux Cookies
Nous utilisons des cookies pour améliorer votre expérience de navigation et analyser notre trafic. See our privacy policy.