Serveur MCP Databricks
Le serveur MCP Databricks permet une intégration transparente entre les assistants IA et la plateforme Databricks, offrant un accès en langage naturel aux resso...
5 min de lecture
AI
Databricks
+4

Connectez sans effort vos agents IA à Databricks pour une exploration autonome des métadonnées, l’exécution de requêtes SQL et une automatisation avancée des données grâce au serveur MCP Databricks.
FlowHunt fournit une couche de sécurité supplémentaire entre vos systèmes internes et les outils d'IA, vous donnant un contrôle granulaire sur les outils accessibles depuis vos serveurs MCP. Les serveurs MCP hébergés dans notre infrastructure peuvent être intégrés de manière transparente avec le chatbot de FlowHunt ainsi qu'avec les plateformes d'IA populaires comme ChatGPT, Claude et divers éditeurs d'IA.
Le serveur MCP Databricks agit comme un serveur Model Context Protocol (MCP) qui relie directement les assistants IA aux environnements Databricks, avec un accent particulier sur l’exploitation des métadonnées du Unity Catalog (UC). Sa fonction principale est de permettre aux agents IA d’accéder, de comprendre et d’interagir de façon autonome avec les actifs de données Databricks. Le serveur fournit des outils permettant aux agents d’explorer les métadonnées UC, de comprendre les structures de données et d’exécuter des requêtes SQL. Cela permet aux agents IA de répondre à des questions relatives aux données, d’effectuer des requêtes sur la base de données et de satisfaire des demandes complexes de données de manière indépendante, sans intervention manuelle à chaque étape. En rendant les métadonnées détaillées accessibles et exploitables, le serveur MCP Databricks optimise les workflows de développement pilotés par l’IA et soutient l’exploration et la gestion intelligente des données sur Databricks.
Aucun modèle de prompt spécifique n’est mentionné dans le dépôt ou la documentation.
Commencez votre essai gratuit aujourd'hui et voyez les résultats en quelques jours.
Aucune liste explicite de ressources MCP n’est fournie dans le dépôt ou la documentation.
Les outils et fonctionnalités suivants sont décrits dans la documentation comme disponibles :
Recevez gratuitement les derniers conseils, tendances et offres.
Aucune instruction spécifique à Windsurf ou extrait JSON n’est fourni.
Aucune instruction spécifique à Claude ou extrait JSON n’est fourni.
Le dépôt mentionne l’intégration avec Cursor :
requirements.txt.mcpServers :{
"databricks-mcp": {
"command": "python",
"args": ["main.py"]
}
}
Sécurisation des clés API à l’aide de variables d’environnement (exemple) :
{
"databricks-mcp": {
"command": "python",
"args": ["main.py"],
"env": {
"DATABRICKS_TOKEN": "VOTRE_CLÉ_API"
}
}
}
Aucune instruction spécifique à Cline ou extrait JSON n’est fourni.
Utiliser le MCP dans FlowHunt
Pour intégrer des serveurs MCP à votre workflow FlowHunt, commencez par ajouter le composant MCP à votre flux et connectez-le à votre agent IA :

Cliquez sur le composant MCP pour ouvrir le panneau de configuration. Dans la section de configuration MCP système, insérez les détails de votre serveur MCP en utilisant ce format JSON :
{
"databricks-mcp": {
"transport": "streamable_http",
"url": "https://votreserveurmcp.exemple/chemindu/mcp/url"
}
}
Une fois configuré, l’agent IA peut utiliser ce MCP comme outil avec accès à toutes ses fonctions et capacités. N’oubliez pas de remplacer “databricks-mcp” par le nom réel de votre serveur MCP et l’URL par celle de votre propre serveur MCP.
| Section | Disponibilité | Détails/Remarques |
|---|---|---|
| Vue d’ensemble | ✅ | Résumé et motivation clairs disponibles |
| Liste des prompts | ⛔ | Aucun modèle de prompt trouvé |
| Liste des ressources | ⛔ | Aucune ressource MCP explicitement listée |
| Liste des outils | ✅ | Outils de haut niveau décrits dans la documentation |
| Sécurisation des clés API | ✅ | Exemple avec "env" fourni dans la section Cursor |
| Support de l’échantillonnage (moins important) | ⛔ | Non mentionné |
D’après la documentation disponible, le serveur MCP Databricks est bien conçu pour l’intégration Databricks/UC et les workflows IA agentiques, mais il manque des modèles de prompt explicites, des listes de ressources et des mentions de roots ou de fonctionnalités d’échantillonnage. Sa configuration et la description des outils sont claires pour Cursor, mais moins pour les autres plateformes.
Le serveur MCP est ciblé et utile pour l’automatisation Databricks + IA, mais bénéficierait d’une documentation plus explicite sur les prompts, ressources et la configuration multi-plateformes. Pour ceux qui recherchent une intégration Databricks/UC, c’est une solution solide et pratique.
| Dispose d’une LICENCE | ✅ (MIT) |
|---|---|
| Au moins un outil | ✅ |
| Nombre de forks | 5 |
| Nombre d’étoiles | 11 |
Le serveur MCP Databricks est un serveur Model Context Protocol qui connecte les agents IA aux environnements Databricks, leur permettant d’accéder de manière autonome aux métadonnées du Unity Catalog, de comprendre les structures de données et d’exécuter des requêtes SQL pour une exploration et une automatisation avancées des données.
Il permet aux agents IA d’explorer les métadonnées du Unity Catalog, de comprendre les structures de données, d’exécuter des requêtes SQL et de fonctionner en mode agent autonome pour des tâches de données multi-étapes.
Les cas d’usage typiques incluent la découverte des métadonnées, la construction automatisée de requêtes SQL, l’aide à la documentation des données, l’exploration intelligente des données et l’automatisation de tâches complexes dans Databricks.
Vous devez utiliser des variables d’environnement pour les informations sensibles. Dans la configuration de votre serveur MCP, définissez le `DATABRICKS_TOKEN` comme variable d’environnement au lieu de le coder en dur.
Ajoutez le composant MCP à votre flux FlowHunt, configurez-le avec les détails de votre serveur et connectez-le à votre agent IA. Utilisez le format JSON fourni dans la section de configuration MCP système pour spécifier votre connexion au serveur MCP Databricks.
Permettez à vos flux de travail IA d’interagir directement avec les métadonnées du Unity Catalog de Databricks et d’automatiser les tâches liées aux données. Essayez-le dès aujourd’hui avec FlowHunt.
Le serveur MCP Databricks permet une intégration transparente entre les assistants IA et la plateforme Databricks, offrant un accès en langage naturel aux resso...

Le serveur MCP Unity Catalog permet aux assistants IA et aux développeurs de gérer, découvrir et manipuler de manière programmatique les fonctions d'Unity Catal...
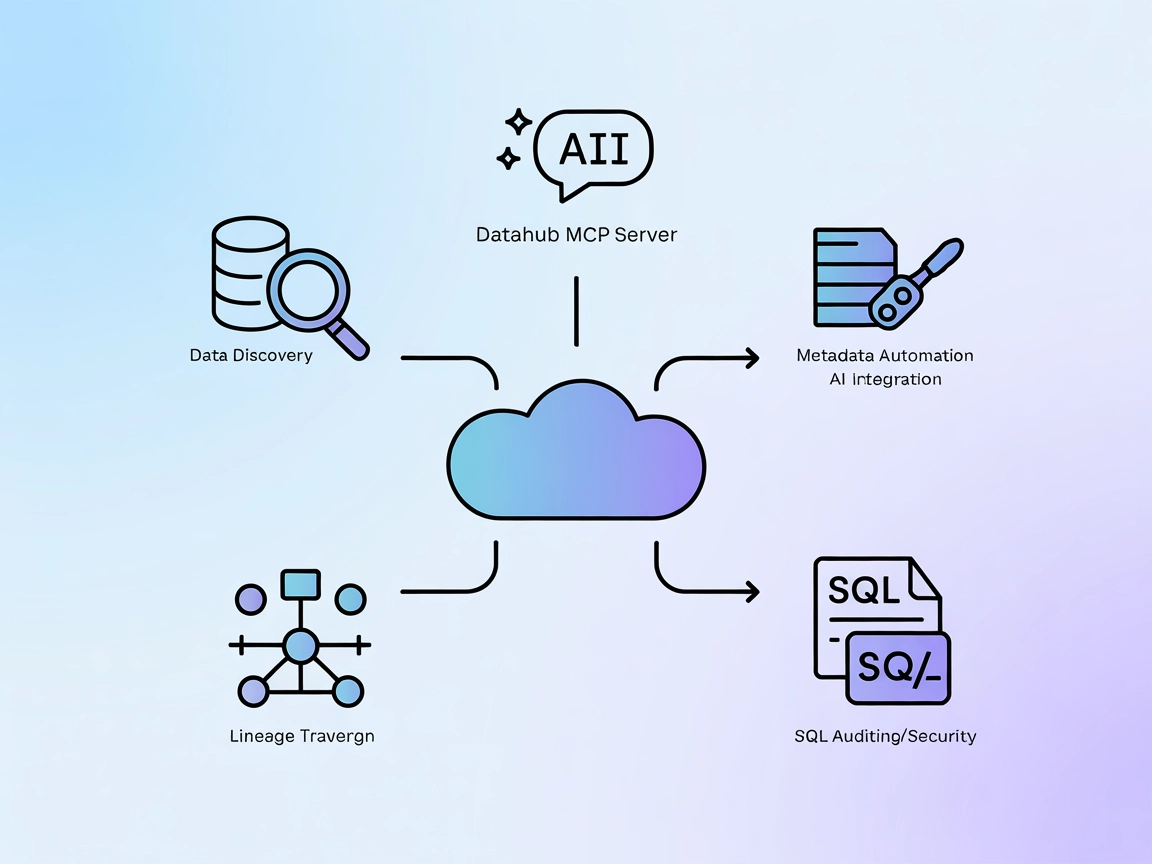
Le serveur DataHub MCP fait le lien entre les agents IA FlowHunt et la plateforme de métadonnées DataHub, permettant une découverte avancée des données, l’analy...
Consentement aux Cookies
Nous utilisons des cookies pour améliorer votre expérience de navigation et analyser notre trafic. See our privacy policy.