Intégration du serveur OpenSearch MCP
Le serveur OpenSearch MCP permet une intégration transparente d’OpenSearch avec FlowHunt et d’autres agents IA, offrant un accès programmatique aux fonctionnali...
5 min de lecture
AI
OpenSearch
+5

Connectez vos agents IA aux clusters Elasticsearch et OpenSearch pour une recherche fluide, la gestion des index et l’analytique en temps réel dans FlowHunt.
FlowHunt fournit une couche de sécurité supplémentaire entre vos systèmes internes et les outils d'IA, vous donnant un contrôle granulaire sur les outils accessibles depuis vos serveurs MCP. Les serveurs MCP hébergés dans notre infrastructure peuvent être intégrés de manière transparente avec le chatbot de FlowHunt ainsi qu'avec les plateformes d'IA populaires comme ChatGPT, Claude et divers éditeurs d'IA.
Le serveur Elasticsearch MCP est une implémentation du Model Context Protocol (MCP) qui permet une interaction fluide avec les clusters Elasticsearch et OpenSearch. Agissant comme un pont entre les assistants IA et ces puissants moteurs de recherche, il permet aux utilisateurs d’effectuer des requêtes de recherche avancées, d’analyser les index et de gérer les clusters par programmation. En exposant une suite d’outils, le serveur permet aux développeurs d’automatiser les recherches de documents, la gestion des index et les opérations de cluster directement depuis leurs workflows pilotés par l’IA. Cela améliore la productivité pour des tâches comme l’exploration de données, la surveillance et la récupération de contenu, faisant du serveur Elasticsearch MCP un atout précieux pour intégrer la recherche en temps réel et l’analytique dans les environnements de développement IA.
(Aucun modèle de prompt n’a été mentionné dans le dépôt. Section laissée intentionnellement vide.)
Commencez votre essai gratuit aujourd'hui et voyez les résultats en quelques jours.
(Aucune ressource MCP explicite n’est listée dans la documentation ou les fichiers du dépôt disponibles.)
Recevez gratuitement les derniers conseils, tendances et offres.
windsurf.json ou équivalent).mcpServers :{
"mcpServers": {
"elasticsearch-mcp": {
"command": "elasticsearch-mcp-server",
"args": ["serve"]
}
}
}
Sécurisation des clés API
Utilisez des variables d’environnement pour sécuriser les détails de connexion :
{
"elasticsearch-mcp": {
"command": "elasticsearch-mcp-server",
"args": ["serve"],
"env": {
"ELASTICSEARCH_URL": "${ELASTICSEARCH_URL}",
"ELASTICSEARCH_API_KEY": "${ELASTICSEARCH_API_KEY}"
}
}
}
mcpServers :{
"elasticsearch-mcp": {
"command": "elasticsearch-mcp-server",
"args": ["serve"]
}
}
Sécurisation des clés API
{
"elasticsearch-mcp": {
"command": "elasticsearch-mcp-server",
"args": ["serve"],
"env": {
"ELASTICSEARCH_URL": "${ELASTICSEARCH_URL}",
"ELASTICSEARCH_API_KEY": "${ELASTICSEARCH_API_KEY}"
}
}
}
cursor.json.{
"mcpServers": {
"elasticsearch-mcp": {
"command": "elasticsearch-mcp-server",
"args": ["serve"]
}
}
}
Sécurisation des clés API
{
"elasticsearch-mcp": {
"command": "elasticsearch-mcp-server",
"args": ["serve"],
"env": {
"ELASTICSEARCH_URL": "${ELASTICSEARCH_URL}",
"ELASTICSEARCH_API_KEY": "${ELASTICSEARCH_API_KEY}"
}
}
}
{
"mcpServers": {
"elasticsearch-mcp": {
"command": "elasticsearch-mcp-server",
"args": ["serve"]
}
}
}
Sécurisation des clés API
{
"elasticsearch-mcp": {
"command": "elasticsearch-mcp-server",
"args": ["serve"],
"env": {
"ELASTICSEARCH_URL": "${ELASTICSEARCH_URL}",
"ELASTICSEARCH_API_KEY": "${ELASTICSEARCH_API_KEY}"
}
}
}
Utilisation du MCP dans FlowHunt
Pour intégrer des serveurs MCP dans votre workflow FlowHunt, commencez par ajouter le composant MCP à votre flux et en le connectant à votre agent IA :

Cliquez sur le composant MCP pour ouvrir le panneau de configuration. Dans la section de configuration système MCP, insérez les détails de votre serveur MCP en utilisant ce format JSON :
{
"elasticsearch-mcp": {
"transport": "streamable_http",
"url": "https://yourmcpserver.example/pathtothemcp/url"
}
}
Une fois configuré, l’agent IA pourra utiliser ce MCP comme outil avec accès à toutes ses fonctions et capacités. N’oubliez pas de remplacer “elasticsearch-mcp” par le vrai nom de votre serveur MCP et l’URL par celle de votre propre serveur MCP.
| Section | Disponibilité | Détails/Remarques |
|---|---|---|
| Vue d’ensemble | ✅ | Présent dans le README.md |
| Liste des Prompts | ⛔ | Aucun modèle de prompt trouvé |
| Liste des ressources | ⛔ | Non listé dans le dépôt |
| Liste des outils | ✅ | Outils listés dans le README.md |
| Sécurisation des clés API | ✅ | .env.example et exemple d’environnement JSON |
| Support du Sampling (moins important) | ⛔ | Non mentionné |
Le serveur Elasticsearch MCP offre d’excellents outils pour intégrer la recherche et la gestion des index dans les workflows IA, avec une documentation claire pour l’installation et l’utilisation. Cependant, l’absence de modèles de prompt, de ressources MCP explicites et aucune mention de Roots ou Sampling limite légèrement ses capacités clés en main pour des workflows agentiques plus avancés.
| Dispose d’une LICENCE | ✅ (Apache-2.0) |
|---|---|
| Au moins un outil | ✅ |
| Nombre de Forks | 34 |
| Nombre d’Étoiles | 162 |
C’est un serveur Model Context Protocol qui permet aux agents IA et workflows d’interagir directement avec des clusters Elasticsearch ou OpenSearch. Vous pouvez rechercher des documents, gérer les index et automatiser les opérations du cluster depuis FlowHunt ou tout client compatible.
Le serveur propose des outils pour lister et gérer les index, effectuer des recherches de documents, récupérer les détails des index et effectuer des requêtes API HTTP générales vers les points de terminaison Elasticsearch/OpenSearch.
Utilisez toujours des variables d'environnement (comme ELASTICSEARCH_URL et ELASTICSEARCH_API_KEY) dans la configuration de votre serveur MCP. Cela permet de garder les informations sensibles hors du code et des fichiers de configuration.
Oui, le serveur est compatible avec les clusters Elasticsearch et OpenSearch, prenant en charge un large éventail d'opérations API pour chacun.
Les cas d’usage populaires incluent la recherche en temps réel dans les workflows IA, la gestion d’index, la surveillance automatisée de la santé du cluster, l’analytique et l’intégration de capacités de recherche avancées dans vos applications propulsées par l’IA.
Permettez à vos agents IA de rechercher, analyser et gérer les clusters Elasticsearch/OpenSearch par programmation. Commencez à créer dès aujourd’hui des workflows plus intelligents, propulsés par la recherche.
Le serveur OpenSearch MCP permet une intégration transparente d’OpenSearch avec FlowHunt et d’autres agents IA, offrant un accès programmatique aux fonctionnali...

Le serveur MCP mcp-google-search fait le lien entre les assistants IA et le web, permettant la recherche en temps réel et l'extraction de contenu via l'API Goog...
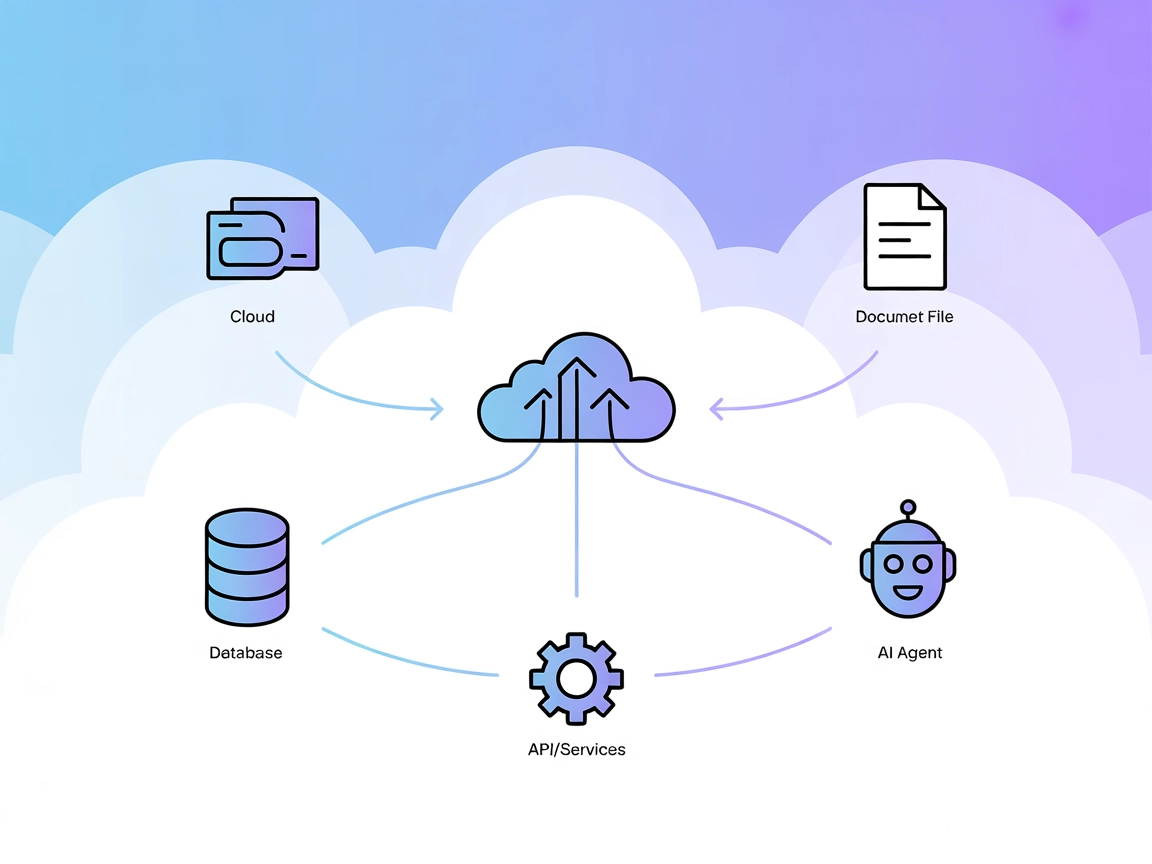
Le serveur Model Context Protocol (MCP) fait le lien entre les assistants IA et des sources de données externes, des API et des services, permettant une intégra...
Consentement aux Cookies
Nous utilisons des cookies pour améliorer votre expérience de navigation et analyser notre trafic. See our privacy policy.