Transformer
A transformer model is a type of neural network specifically designed to handle sequential data, such as text, speech, or time-series data. Unlike traditional m...
3 min read
Transformer
Neural Networks
+3
Transformers are a revolutionary neural network architecture that has transformed artificial intelligence, especially in natural language processing. Introduced in 2017’s ‘Attention is All You Need’, they enable efficient parallel processing and have become foundational for models like BERT and GPT, impacting NLP, vision, and more.
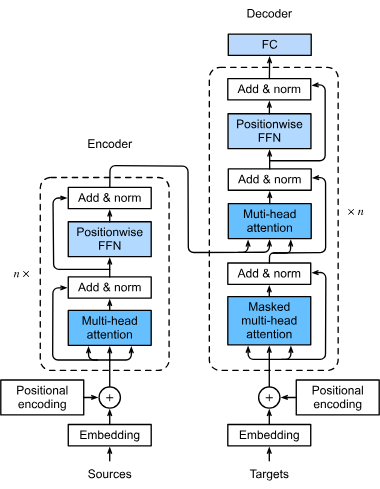
The first step in a transformer model’s processing pipeline involves converting words or tokens in an input sequence into numerical vectors, known as embeddings. These embeddings capture semantic meanings and are crucial for the model to understand the relationships between tokens. This transformation is essential as it allows the model to process text data in a mathematical form.
Transformers do not inherently process data in a sequential manner; therefore, positional encoding is used to inject information about the position of each token in the sequence. This is vital for maintaining the order of the sequence, which is crucial for tasks like language translation where context can be dependent on the sequence of words.
The multi-head attention mechanism is a sophisticated component of transformers that allows the model to focus on different parts of the input sequence simultaneously. By computing multiple attention scores, the model can capture various relationships and dependencies in the data, enhancing its ability to understand and generate complex data patterns.
Transformers typically follow an encoder-decoder architecture:
After the attention mechanism, the data passes through feedforward neural networks, which apply non-linear transformations to the data, helping the model learn complex patterns. These networks further process the data to refine the output generated by the model.
These techniques are incorporated to stabilize and speed up the training process. Layer normalization ensures that the outputs remain within a certain range, facilitating efficient training of the model. Residual connections allow gradients to flow through the networks without vanishing, which enhances the training of deep neural networks.
Start your free trial today and see results within days.
Transformers operate on sequences of data, which could be words in a sentence or other sequential information. They apply self-attention to determine the relevance of each part of the sequence concerning others, enabling the model to focus on crucial elements that affect the output.
In self-attention, every token in the sequence is compared with every other token to compute attention scores. These scores indicate the significance of each token in the context of others, allowing the model to focus on the most relevant parts of the sequence. This is pivotal for understanding context and meaning in language tasks.
These are the building blocks of a transformer model, consisting of self-attention and feedforward layers. Multiple blocks are stacked to form deep learning models capable of capturing intricate patterns in data. This modular design allows transformers to scale efficiently with the complexity of the task.
Transformers are more efficient than RNNs and CNNs due to their ability to process entire sequences at once. This efficiency enables scaling up to very large models, such as GPT-3, which has 175 billion parameters. The scalability of transformers allows them to handle vast amounts of data effectively.
Traditional models struggle with long-range dependencies due to their sequential nature. Transformers overcome this limitation through self-attention, which can consider all parts of the sequence simultaneously. This makes them particularly effective for tasks that require understanding context over long text sequences.
While initially designed for NLP bridges human-computer interaction. Discover its key aspects, workings, and applications today!") tasks, transformers have been adapted for various applications, including computer vision, protein folding, and even time-series forecasting. This versatility showcases the broad applicability of transformers across different domains.
Get latest tips, trends, and deals for free.
Transformers have significantly improved the performance of NLP tasks such as translation, summarization, and sentiment analysis. Models like BERT and GPT are prominent examples that leverage transformer architecture to understand and generate human-like text, setting new benchmarks in NLP.
In machine translation, transformers excel by understanding the context of words within a sentence, allowing for more accurate translations compared to previous methods. Their ability to process entire sentences at once enables more coherent and contextually accurate translations.
Transformers can model the sequences of amino acids in proteins, aiding in the prediction of protein structures, which is crucial for drug discovery and understanding biological processes. This application underscores the potential of transformers in scientific research.
By adapting the transformer architecture, it is possible to predict future values in time-series data, such as electricity demand forecasting, by analyzing past sequences. This opens new possibilities for transformers in fields like finance and resource management.
BERT models are designed to understand the context of a word by looking at its surrounding words, making them highly effective for tasks that require understanding word relationships in a sentence. This bidirectional approach allows BERT to capture context more effectively than unidirectional models.
GPT models are autoregressive, generating text by predicting the next word in a sequence based on the preceding words. They are widely used in applications like text completion and dialogue generation, demonstrating their capability to produce human-like text.
Initially developed for NLP, transformers have been adapted for computer vision tasks. Vision transformers process image data as sequences, allowing them to apply transformer techniques to visual inputs. This adaptation has led to advancements in image recognition and processing.
Training large transformer models requires substantial computational resources, often involving vast datasets and powerful hardware like GPUs. This presents a challenge in terms of cost and accessibility for many organizations.
As transformers become more prevalent, issues such as bias in AI models and ethical use of AI-generated content are becoming increasingly important. Researchers are working on methods to mitigate these issues and ensure responsible AI development, highlighting the need for ethical frameworks in AI research.
The versatility of transformers continues to open new avenues for research and application, from enhancing AI-driven chatbots to improving data analysis in fields like healthcare and finance. The future of transformers holds exciting possibilities for innovation across various industries.
In conclusion, transformers represent a significant advancement in AI technology, offering unparalleled capabilities in processing sequential data. Their innovative architecture and efficiency have set a new standard in the field, propelling AI applications to new heights. Whether it’s language understanding, scientific research, or visual data processing, transformers continue to redefine what’s possible in the realm of artificial intelligence.
Transformers have revolutionized the field of artificial intelligence, particularly in natural language processing bridges human-computer interaction. Discover its key aspects, workings, and applications today!") and understanding. The paper “AI Thinking: A framework for rethinking artificial intelligence in practice” by Denis Newman-Griffis (published in 2024) explores a novel conceptual framework called AI Thinking. This framework models key decisions and considerations involved in AI use across disciplinary perspectives, addressing competencies in motivating AI use, formulating AI methods, and situating AI in sociotechnical contexts. It aims to bridge divides between academic disciplines and reshape the future of AI in practice. Read more .
Another significant contribution is seen in “Artificial intelligence and the transformation of higher education institutions” by Evangelos Katsamakas et al. (published in 2024), which uses a complex systems approach to map for evaluating object detection models in computer vision, ensuring precise detection and localization.") the causal feedback mechanisms of AI transformation in higher education institutions (HEIs). The study discusses the forces driving AI transformation and its impact on value creation, emphasizing the need for HEIs to adapt to AI technology advances while managing academic integrity and employment changes. Read more .
In the realm of software development, the paper “Can Artificial Intelligence Transform DevOps?” by Mamdouh Alenezi and colleagues (published in 2022) examines the intersection of AI and DevOps. The study highlights how AI can enhance the functionality of DevOps processes, facilitating efficient software delivery. It underscores the practical implications for software developers and businesses in leveraging AI to transform DevOps practices. Read more
Transformers are a neural network architecture introduced in 2017 that uses self-attention mechanisms for parallel processing of sequential data. They have revolutionized artificial intelligence, particularly in natural language processing and computer vision.
Unlike RNNs and CNNs, transformers process all elements of a sequence simultaneously using self-attention, enabling greater efficiency, scalability, and the ability to capture long-range dependencies.
Transformers are widely used in NLP tasks like translation, summarization, and sentiment analysis, as well as in computer vision, protein structure prediction, and time-series forecasting.
Notable transformer models include BERT (Bidirectional Encoder Representations from Transformers), GPT (Generative Pre-trained Transformers), and Vision Transformers for image processing.
Transformers require significant computational resources to train and deploy. They also raise ethical considerations such as potential bias in AI models and responsible use of generative AI content.
Smart Chatbots and AI tools under one roof. Connect intuitive blocks to turn your ideas into automated Flows.
A transformer model is a type of neural network specifically designed to handle sequential data, such as text, speech, or time-series data. Unlike traditional m...
A Generative Pre-trained Transformer (GPT) is an AI model that leverages deep learning techniques to produce text closely mimicking human writing. Based on the ...
Bidirectional Long Short-Term Memory (BiLSTM) is an advanced type of Recurrent Neural Network (RNN) architecture that processes sequential data in both forward ...
Cookie Consent
We use cookies to enhance your browsing experience and analyze our traffic. See our privacy policy.