Ingegneria del Contesto: La Guida Definitiva 2025 per Dominare la Progettazione di Sistemi AI
Approfondisci l’ingegneria del contesto per l’AI. Questa guida copre i principi fondamentali, dal prompt vs. contesto fino a strategie avanzate come gestione della memoria, degrado del contesto e design multi-agente.
AI
LLM
System Design
Agents
Context Engineering
Prompt Engineering
RAG
Il panorama dello sviluppo AI ha subito una profonda trasformazione. Se prima ci si concentrava sull’arte di scrivere il prompt perfetto, oggi la sfida è molto più complessa: costruire vere e proprie architetture informative che circondano e potenziano i modelli linguistici.
Questo cambiamento segna il passaggio dalla prompt engineering all’ingegneria del contesto—ed è il futuro stesso dello sviluppo AI applicato. I sistemi che oggi portano valore reale non si basano su prompt magici; hanno successo perché i loro architetti sanno orchestrare ecosistemi informativi completi.
Andrej Karpathy ha colto bene questa evoluzione quando ha descritto l’ingegneria del contesto come la pratica attenta di popolamento della finestra di contesto con l’informazione giusta al momento giusto. Questa affermazione, solo in apparenza semplice, svela una verità fondamentale: l’LLM non è più il protagonista assoluto, ma un elemento critico all’interno di un sistema dove ogni frammento di informazione—ogni memoria, descrizione di tool, documento recuperato—è stato posizionato deliberatamente per massimizzare il risultato.
Cos’è l’Ingegneria del Contesto?
Una Prospettiva Storica
Le radici dell’ingegneria del contesto sono più profonde di quanto si creda. Mentre le discussioni sul prompt engineering sono esplose nel 2022-2023, i concetti fondanti dell’ingegneria del contesto sono emersi oltre vent’anni fa nella ricerca su ubiquitous computing e interazione uomo-macchina.
Già nel 2001, Anind K. Dey propose una definizione sorprendentemente lungimirante: il contesto comprende qualsiasi informazione che aiuti a caratterizzare la situazione di un’entità. Questa cornice iniziale ha posto le basi per la nostra attuale concezione di comprensione ambientale da parte delle macchine.
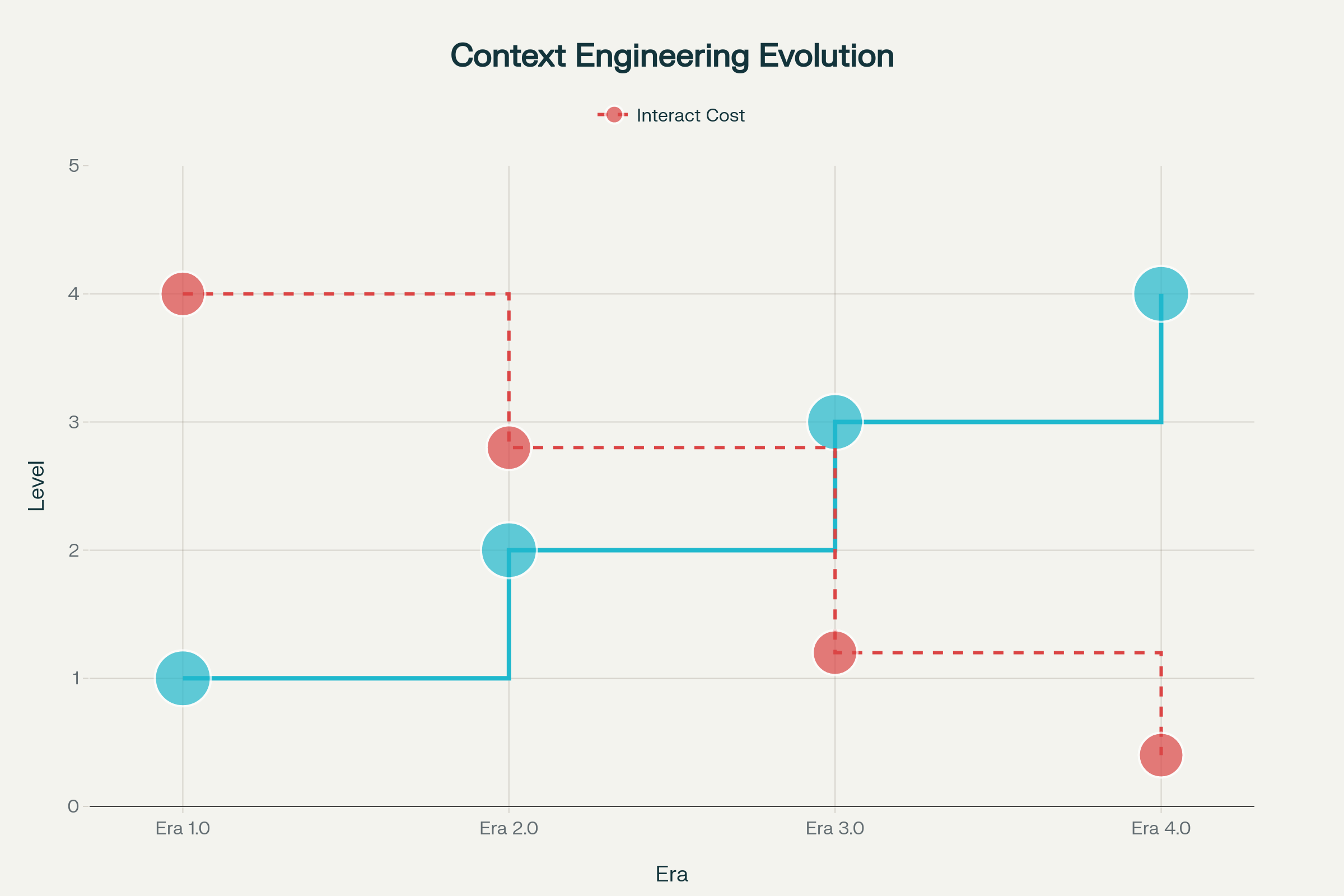
L’evoluzione dell’ingegneria del contesto si è articolata in fasi distinte, ciascuna plasmata dai progressi dell’intelligenza artificiale:
Era 1.0: Computazione Primitiva (anni ‘90–2020) — In questo lungo periodo, le macchine gestivano solo input strutturati e segnali ambientali basilari. Gli umani dovevano tradurre completamente i contesti in formati comprensibili dalle macchine. Pensiamo ad applicazioni desktop, app mobili con sensori, chatbot con risposte rigide.
Era 2.0: Intelligenza Centrata sull’Agente (2020–Presente) — Il rilascio di GPT-3 nel 2020 ha segnato una svolta. I grandi modelli linguistici hanno portato vera comprensione del linguaggio naturale e la capacità di gestire intenzioni implicite. Questa era ha reso possibile una collaborazione autentica uomo-agente, dove ambiguità e informazioni incomplete sono gestibili grazie alla sofisticata comprensione del linguaggio e all’apprendimento in contesto.
Era 3.0 & 4.0: Intelligenza Umana e Sovrumana (Futuro) — Le prossime ondate promettono sistemi capaci di percepire e processare informazioni ad alta entropia con fluidità umana, arrivando a costruire proattivamente contesti e anticipare bisogni non ancora espressi dagli utenti.
Evoluzione dell’Ingegneria del Contesto attraverso Quattro Ere: dalla Computazione Primitiva all’Intelligenza Sovrumana
Una Definizione Formale
Nel suo nucleo, l’ingegneria del contesto è la disciplina sistematica che progetta e ottimizza il flusso delle informazioni contestuali nei sistemi AI: dalla raccolta iniziale, passando per archiviazione e gestione, fino all’utilizzo per migliorare la comprensione e l’esecuzione dei compiti.
Possiamo esprimerla matematicamente come una funzione di trasformazione:
$CE: (C, T) \rightarrow f_{context}$
Dove:
C rappresenta le informazioni contestuali grezze (entità e loro caratteristiche)
T indica il compito target o dominio applicativo
f_{context} restituisce la funzione di processamento del contesto risultante
Scomponendo il tutto in termini pratici, emergono quattro operazioni fondamentali:
Raccogliere segnali contestuali rilevanti tramite sensori e canali informativi diversi
Archiviare tali informazioni in modo efficiente su sistemi locali, infrastrutture di rete e cloud
Gestire la complessità tramite elaborazione intelligente di testo, input multimodali e relazioni intricate
Utilizzare strategicamente il contesto filtrando per rilevanza, abilitando la condivisione tra sistemi e adattandolo alle esigenze dell’utente
Perché l’Ingegneria del Contesto è Fondamentale: Il Framework della Riduzione d’Entropia
L’ingegneria del contesto affronta una profonda asimmetria nella comunicazione uomo-macchina. Quando gli umani dialogano, colmano facilmente le lacune grazie a cultura, intelligenza emotiva e consapevolezza situazionale. Le macchine non possiedono nulla di tutto ciò.
Questa distanza si manifesta come entropia informativa. La comunicazione umana è efficiente perché presuppone enormi quantità di contesto condiviso. Le macchine esigono che tutto sia rappresentato esplicitamente. L’ingegneria del contesto consiste fondamentalmente nel pre-elaborare i contesti per le macchine—comprimendo la complessità ad alta entropia delle intenzioni e situazioni umane in rappresentazioni a bassa entropia processabili dalle macchine.
Con l’avanzare dell’intelligenza artificiale, questa riduzione dell’entropia viene sempre più automatizzata. Oggi, nell’Era 2.0, gli ingegneri devono orchestrare manualmente gran parte di questo processo. Nell’Era 3.0 e oltre, le macchine si assumeranno una quota crescente di questo carico. Eppure la sfida fondamentale rimarrà: colmare il divario tra complessità umana e comprensione artificiale.
Prompt Engineering vs. Context Engineering: Le Differenze Chiave
Un errore comune è confondere queste due discipline. In realtà, rappresentano approcci profondamente diversi all’architettura dei sistemi AI.
Prompt engineering si concentra sull’ottimizzazione di singole istruzioni o domande per plasmare il comportamento del modello. Si tratta di ottimizzare la struttura linguistica di ciò che si comunica al modello—formulazione, esempi, pattern di ragionamento di una singola interazione.
Ingegneria del contesto è una disciplina sistemica che gestisce tutto ciò che il modello incontra durante l’inferenza—including prompt, ma anche documenti recuperati, sistemi di memoria, descrizione di strumenti, stato, e molto altro.
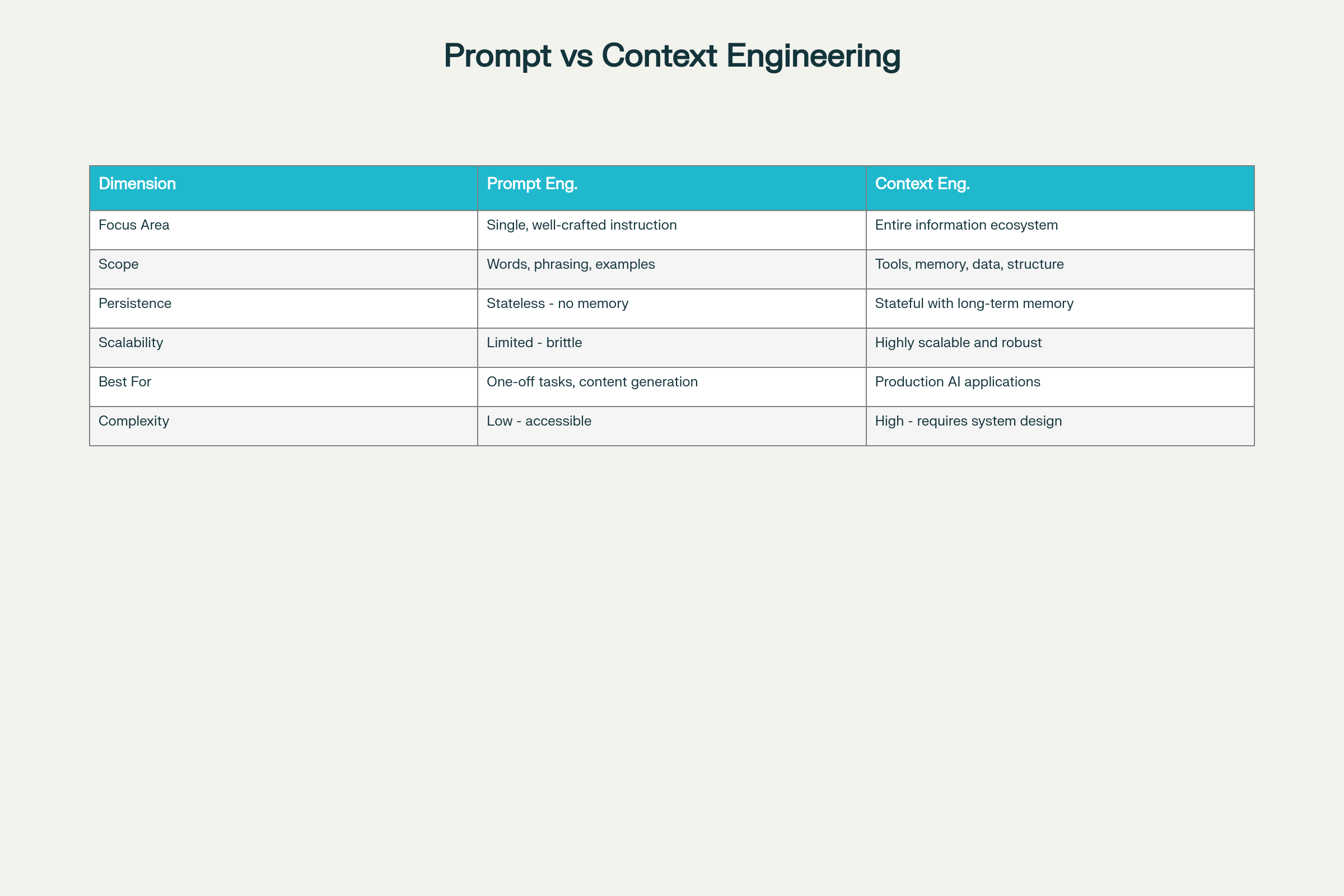
Prompt Engineering vs Context Engineering: Differenze e Tradeoff Chiave
Un esempio: Chiedere a ChatGPT di scrivere una mail professionale è prompt engineering. Costruire una piattaforma di assistenza clienti che mantiene la cronologia delle conversazioni, accede ai dati dell’utente e ricorda i ticket precedenti—questa è ingegneria del contesto.
Otto Dimensioni di Differenza:
Dimensione
Prompt Engineering
Ingegneria del Contesto
Area di Focus
Ottimizzazione di una singola istruzione
Ecosistema informativo completo
Ambito
Parole, formulazione, esempi
Strumenti, memoria, architettura dei dati, struttura
Persistenza
Senza stato—nessuna memoria
Con stato, memoria a lungo termine
Scalabilità
Limitata e fragile con la scala
Estremamente scalabile e robusta
Ideale per
Task una tantum, generazione contenuti
Applicazioni AI di livello produttivo
Complessità
Basso ingresso
Alta—richiede competenze di system design
Affidabilità
Imprevedibile con la scala
Affidabile e coerente
Manutenzione
Fragile ai cambi di requisiti
Modulabile e manutenibile
L’intuizione cruciale: Le applicazioni LLM di livello produttivo richiedono quasi sempre ingegneria del contesto, non solo prompt intelligenti. Come osservato da Cognition AI, l’ingegneria del contesto è ormai la principale responsabilità degli ingegneri che sviluppano agenti AI.
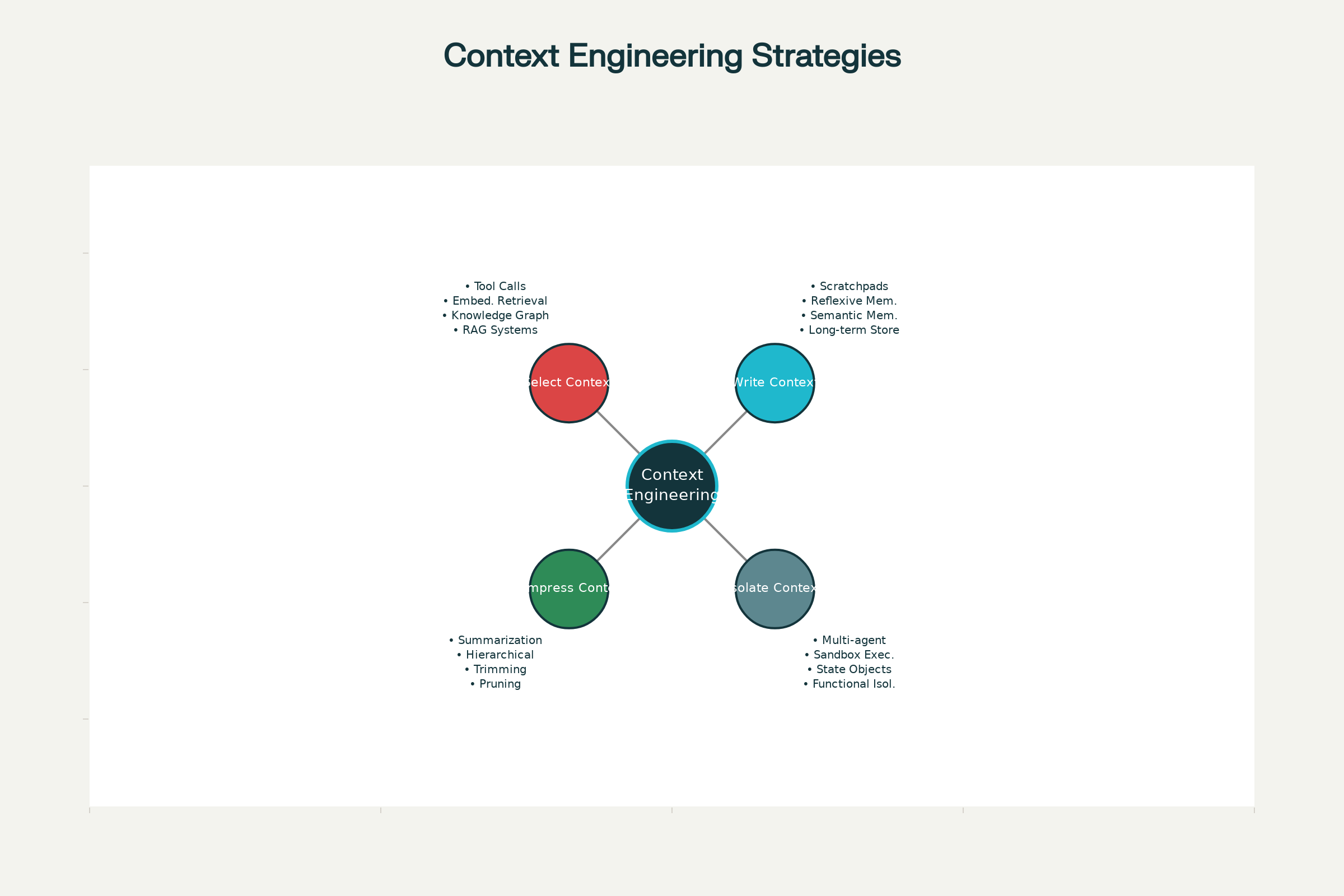
Le Quattro Strategie Fondamentali dell’Ingegneria del Contesto
Nei sistemi AI d’avanguardia—da Claude e ChatGPT ad agenti specializzati di Anthropic e altri laboratori—quattro strategie chiave si sono cristallizzate per una gestione efficace del contesto. Possono essere adottate singolarmente o combinate.
1. Scrivere il Contesto: Persistenza Fuori dalla Finestra di Contesto
Il principio fondamentale è semplice: non costringere il modello a ricordare tutto. Salva invece le informazioni critiche fuori dalla finestra di contesto, dove possono essere recuperate quando servono.
Scratchpad è l’implementazione più intuitiva. Come gli umani prendono appunti, anche gli agenti AI usano scratchpad per conservare informazioni future. L’implementazione può essere semplice (un tool che salva note) o sofisticata (campi in un oggetto di stato persistente tra vari step di esecuzione).
Il multi-agent researcher di Anthropic lo dimostra perfettamente: il LeadResearcher inizia formulando una strategia e la salva in Memoria, riconoscendo che se la finestra di contesto supera i 200.000 token, si verifica un taglio e il piano deve essere conservato.
Memorie estendono il concetto di scratchpad tra sessioni diverse. Invece di memorizzare solo informazioni temporanee (memoria di sessione), i sistemi possono costruire memorie a lungo termine che evolvono attraverso molte interazioni. Questo pattern è ormai standard in ChatGPT, Claude Code, Cursor e Windsurf.
Progetti come Reflexion hanno introdotto memorie riflessive: l’agente riflette su ogni turno e genera memorie per il futuro. Generative Agents estende questo approccio con sintesi periodiche delle memorie dagli input passati.
Tre Tipi di Memorie:
Episodica: Esempi concreti di comportamenti/interazioni passate (utile per few-shot learning)
Procedurale: Istruzioni o regole di comportamento (per la coerenza operativa)
Semantica: Fatti e relazioni sul mondo (per conoscenza radicata)
2. Selezionare il Contesto: Recuperare Solo l’Informazione Rilevante
Una volta salvate le informazioni, l’agente deve recuperare solo ciò che serve per il compito attuale. Una cattiva selezione può essere dannosa quanto non avere memoria: informazioni irrilevanti confondono o causano allucinazioni.
Meccanismi di Selezione della Memoria:
Approcci semplici usano file sempre inclusi. Claude Code usa CLAUDE.md per memorie procedurali, Cursor e Windsurf impiegano file rules. Tuttavia, questo metodo non scala se l’agente accumula centinaia di fatti.
Per raccolte più grandi, sono comuni retrieval basato su embedding e knowledge graph. Il sistema converte sia le memorie che la query attuale in vettori, recuperando le memorie semanticamente più simili.
Ma, come dimostrato da Simon Willison all’AIEngineer World’s Fair, questo metodo può fallire clamorosamente: ChatGPT ha inserito la sua posizione in un’immagine generata, mostrando che anche i sistemi sofisticati possono recuperare memorie sbagliate—l’ingegneria attenta è essenziale.
Selezione degli Strumenti: Quando gli agenti hanno accesso a decine o centinaia di tool, elencarli tutti causa confusione—descrizioni sovrapposte portano a scelte errate. Una soluzione efficace: applicare il RAG alle descrizioni dei tool, recuperando solo quelli semanticamente rilevanti. Così si triplica la precisione nella selezione.
Recupero della Conoscenza rappresenta forse la sfida più ricca. Gli agenti per il codice ne sono un esempio su scala produttiva. Un ingegnere Windsurf ha osservato che indicizzare il codice non equivale a recuperare il contesto efficace. Usano indicizzazione, embedding search con parsing AST e suddivisione semantica. Ma l’embedding search diventa inaffidabile su grandi codebase. Il successo richiede la combinazione di grep/search, retrieval da knowledge graph e un passaggio di riordino per rilevanza.
3. Comprimere il Contesto: Tenere Solo l’Essenziale
I task a lungo termine portano all’accumulo naturale di contesto: note, output di tool e cronologia possono rapidamente saturare la finestra. Le strategie di compressione permettono di distillare ciò che conta.
Riassunto è la tecnica principale. Claude Code implementa “auto-compact”: quando la finestra di contesto raggiunge il 95%, riassume l’intera traiettoria delle interazioni utente-agente. Si possono usare varie strategie:
Riassunto ricorsivo: si costruiscono riassunti di riassunti
Riassunto gerarchico: riassunti a più livelli di astrazione
Riassunto mirato: si comprimono solo parti specifiche (output voluminosi di ricerca), non tutto il contesto
Cognition AI ha rivelato di usare modelli fine-tuned per il riassunto ai confini tra agenti, riducendo i token nel passaggio di conoscenza—dimostrando la profondità ingegneristica di questo step.
Taglio del Contesto è un approccio complementare. Invece di usare LLM per riassumere, si elimina parte del contesto tramite euristiche: rimuovere messaggi vecchi, filtrare per importanza o usare pruners addestrati come Provence.
L’intuizione chiave: ciò che si rimuove conta quanto ciò che si tiene. Un contesto di 300 token focalizzato spesso supera uno dispersivo da 113.000 token nei compiti conversazionali.
4. Isolare il Contesto: Suddividere l’Informazione tra Sistemi
Le strategie di isolamento riconoscono che compiti diversi richiedono informazioni diverse. Invece di stipare tutto in una sola finestra, si partiziona il contesto su sistemi specializzati.
Architetture Multi-agente sono l’approccio più diffuso. La libreria Swarm di OpenAI si fonda esplicitamente sulla “separazione delle competenze”: sub-agenti specializzati gestiscono task con propri strumenti, istruzioni e finestre di contesto.
La ricerca di Anthropic dimostra la potenza di questo metodo: molti agenti con contesti isolati superano le implementazioni mono-agente, poiché la finestra di ciascun sub-agente è dedicata a un task specifico. Gli agenti operano in parallelo, esplorando simultaneamente aspetti diversi della domanda.
Tuttavia, i sistemi multi-agente comportano compromessi. Anthropic ha osservato fino a quindici volte più token rispetto alla chat mono-agente, imponendo orchestrazione attenta e meccanismi di coordinamento sofisticati.
Sandbox: HuggingFace CodeAgent, ad esempio, invece di restituire JSON da interpretare, genera codice da eseguire in sandbox. Solo gli output selezionati sono restituiti all’LLM, isolando oggetti pesanti. Ottimo per dati visuali e audio.
Isolamento dello Stato: tecnica spesso sottovalutata. Lo stato di runtime può essere progettato come schema strutturato (es. modello Pydantic) con diversi campi. Un campo (es. messages) è esposto all’LLM, gli altri restano isolati. Questo offre controllo granulare senza complessità architetturale.
Quattro Strategie Fondamentali per l’Ingegneria del Contesto negli Agenti AI
Il Problema del Degrado del Contesto
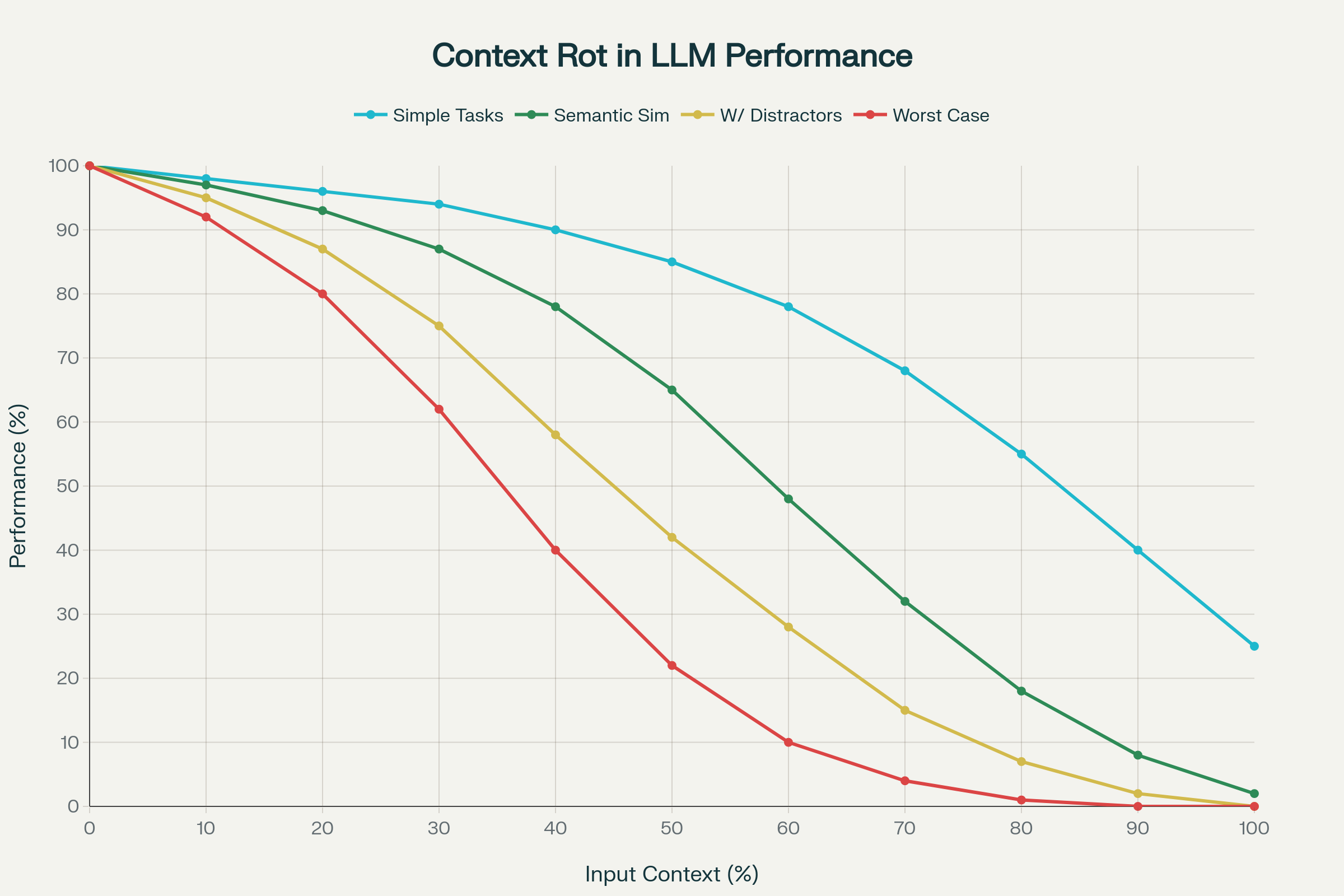
Nonostante i progressi nella lunghezza dei contesti, la ricerca recente rivela una realtà inquietante: una finestra più lunga non porta automaticamente a migliori prestazioni.
Uno studio su 18 LLM leader—tra cui GPT-4.1, Claude 4, Gemini 2.5 e Qwen 3—ha evidenziato il fenomeno del degrado del contesto: il peggioramento imprevedibile (e spesso grave) delle performance col crescere dell’input.
Risultati Chiave sul Degrado del Contesto
1. Decremento Non Uniforme
Le performance non calano in modo lineare. I modelli mostrano crolli improvvisi e idiosincratici a seconda del modello e del compito. Un modello può mantenere il 95% di accuratezza fino a una certa lunghezza, poi precipitare al 60%. Questi “cliff” sono imprevedibili e diversi per ogni modello.
2. La Complessità Semantica Amplifica il Degrado
Task semplici (come la copia di parole ripetute) mostrano cali moderati. Ma quando bisogna trovare “aghi nel pagliaio” tramite similarità semantica, il crollo è netto. L’aggiunta di distrattori plausibili peggiora ancora la precisione.
3. Bias di Posizione e Collasso dell’Attenzione
L’attenzione nei Transformer non scala linearmente: i token all’inizio (bias di primacy) e alla fine (bias di recency) ricevono attenzione sproporzionata. Nei casi estremi, l’attenzione collassa e il modello ignora porzioni rilevanti dell’input.
4. Pattern di Fallimento Specifici per Modello
Ogni LLM mostra comportamenti unici:
GPT-4.1: tende ad allucinare, ripetendo token errati
Gemini 2.5: introduce frammenti o punteggiatura fuori luogo
Claude Opus 4: può rifiutare compiti o diventare eccessivamente cauto
5. Impatto Reale nelle Conversazioni
Nel benchmark LongMemEval, i modelli con accesso alla conversazione completa (circa 113k token) hanno ottenuto prestazioni migliori con il solo segmento chiave da 300 token. Il degrado del contesto peggiora dunque retrieval e ragionamento nei dialoghi reali.
Degrado del Contesto: Peggioramento delle Performance all’Aumentare dei Token in 18 LLM
Implicazioni: Qualità sopra Quantità
Il messaggio della ricerca è netto: la quantità di token non determina la qualità. Come il contesto è costruito, filtrato e presentato è altrettanto (se non più) importante.
Questo risultato convalida l’intera disciplina dell’ingegneria del contesto. Le squadre più avanzate sanno che lunghe finestre di contesto non sono la soluzione magica: servono compressione, selezione e isolamento per mantenere alte le performance con input abbondanti.
Ingegneria del Contesto nella Pratica: Applicazioni Reali
Caso 1: Sistemi Multi-turno (Claude Code, Cursor)
Claude Code e Cursor rappresentano l’avanguardia nell’ingegneria del contesto per assistenza al codice:
Raccolta: Aggregano contesto da molte fonti—file aperti, struttura dei progetti, cronologia, output terminale, commenti.
Gestione: Non inseriscono tutti i file nel prompt, ma comprimono in modo intelligente. Claude Code usa riassunti gerarchici. Il contesto è etichettato per funzione (“file editato”, “dipendenza referenziata”, “messaggio di errore”).
Utilizzo: Ad ogni turno, selezionano file e elementi rilevanti, li presentano in formato strutturato e tengono tracce separate per ragionamento e output visibile.
Compressione: Avvicinandosi ai limiti di contesto, scatta l’auto-compact, riassumendo la traiettoria delle interazioni salvando le decisioni chiave.
Risultato: Questi tool restano usabili su progetti grandi senza perdita di performance, nonostante i limiti delle finestre di contesto.
Caso 2: Tongyi DeepResearch (Agente Open Source per la Ricerca Avanzata)
Tongyi DeepResearch mostra come l’ingegneria del contesto abiliti task di ricerca complessi:
Pipeline di Sintesi Dati: Invece di affidarsi a dati annotati manualmente, Tongyi usa una pipeline sofisticata che genera domande di livello PhD tramite iterazioni di complessità crescente, ampliando i confini della conoscenza.
Gestione del Contesto: Ad ogni round di ricerca, ricostruisce uno spazio di lavoro snello usando solo gli output essenziali dal round precedente, evitando la “soffocazione cognitiva” da accumulo di informazioni.
Esplorazione Parallela: Più agenti operano in parallelo con contesti isolati, ognuno esplora aspetti diversi; un agente di sintesi integra poi i risultati.
Risultati: Tongyi DeepResearch raggiunge performance paragonabili a sistemi proprietari come OpenAI DeepResearch, con punteggi di 32.9 all’Humanity’s Last Exam e 75 nei benchmark user-centrici.
Caso 3: Ricercatore Multi-agente di Anthropic
La ricerca di Anthropic mostra come isolamento e specializzazione migliorino le performance:
Architettura: Sub-agenti specializzati gestiscono task di ricerca specifici (review, sintesi, verifica) con finestre di contesto separate.
Benefici: Questo approccio supera i sistemi mono-agente, poiché ogni sub-agente usa il contesto ottimizzato per il proprio task.
Tradeoff: La qualità cresce, ma il consumo di token aumenta fino a quindici volte rispetto alla chat mono-agente.
Conclusione: l’ingegneria del contesto comporta spesso compromessi tra qualità, velocità e costo. L’equilibrio dipende dai requisiti applicativi.
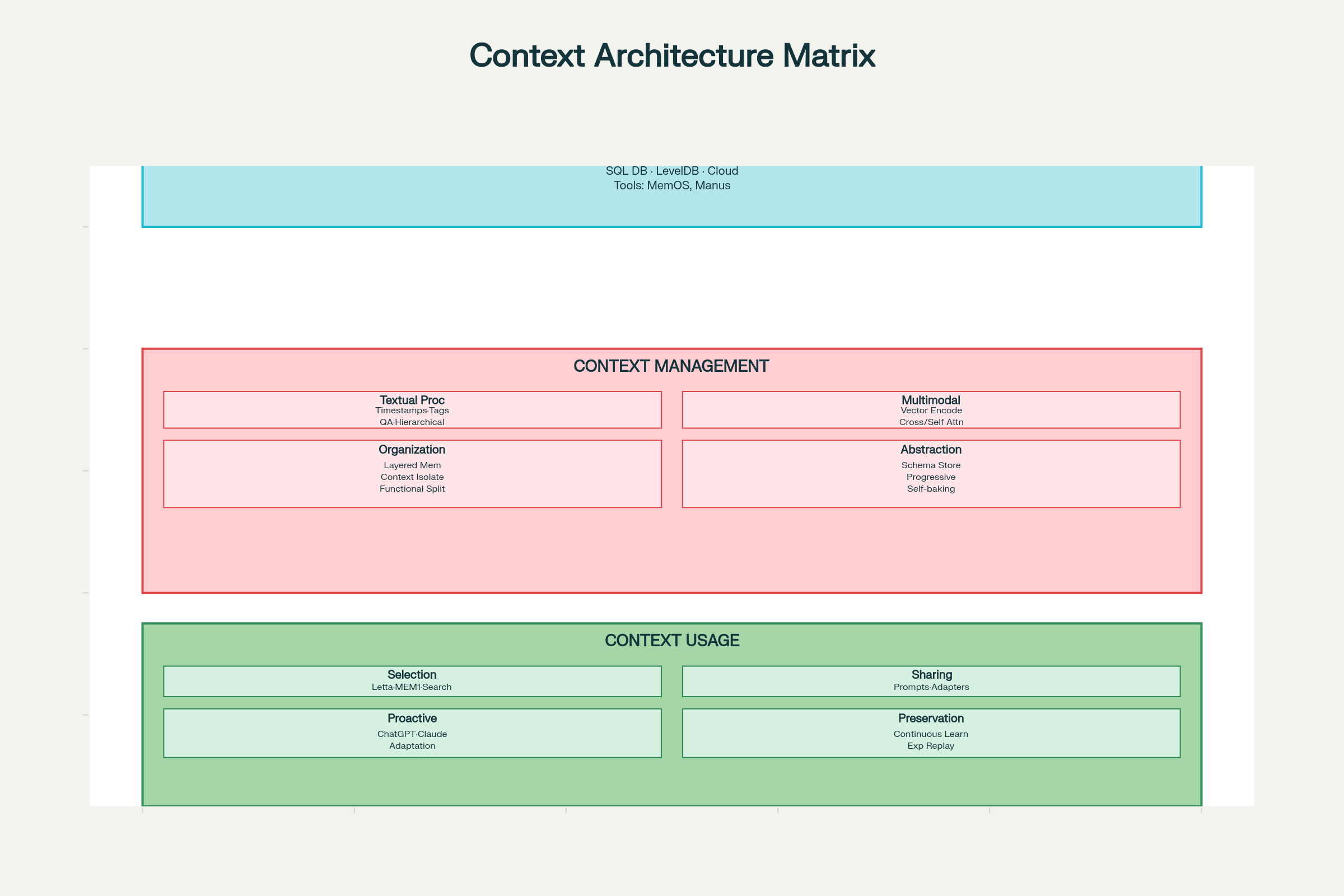
Framework per le Scelte Progettuali
Implementare ingegneria del contesto richiede pensiero sistemico su tre dimensioni: raccolta & archiviazione, gestione, utilizzo.
Considerazioni Progettuali per l’Ingegneria del Contesto: Architettura di Sistema e Componenti
Sistemi Distribuiti: Per la massima scala, ridondanza e tolleranza ai guasti
Pattern di Design:
MemOS: Sistema operativo di memoria per gestione unificata
Manus: Memoria strutturata con accesso basato su ruoli
Principio chiave: Progetta per il recupero efficiente, non solo per lo storage. Il sistema ottimale ti fa trovare subito ciò che serve.
Scelte per la Gestione
Processamento del Testo:
Marcatura temporale: Semplice ma limitata. Mantiene l’ordine cronologico, ma nessuna struttura semantica; problemi di scala.
Tagging per ruolo/funzione: Ogni elemento è etichettato per funzione—“obiettivo”, “decisione”, “azione”, “errore”, ecc. Supporto per tag multidimensionali (priorità, fonte, confidenza). LLM4Tag abilita questa scalabilità.
Compressione in Q&A: Interazioni trasformate in coppie domanda-risposta compresse, conservando l’essenziale e riducendo i token.
Note gerarchiche: Compressione progressiva in vettori di significato, come nei sistemi H-MEM.
Processamento Multimodale:
Spazi vettoriali comparabili: Tutte le modalità (testo, immagine, audio) codificate in vettori confrontabili tramite modelli di embedding condivisi (ChatGPT, Claude).
Cross-Attention: Una modalità guida l’attenzione su un’altra (Qwen2-VL).
Encoding indipendente con self-attention: Modalità codificate separatamente, poi combinate tramite attenzione unificata.
Organizzazione del Contesto:
Architettura a Memoria Stratificata: Separazione tra working memory (contesto attuale), memoria a breve termine (storia recente), memoria a lungo termine (fatti persistenti).
Isolamento Funzionale: Sub-agenti con finestre di contesto dedicate a funzioni diverse (Claude).
Astrazione del Contesto (Self-Baking):
“Self-baking” significa che il contesto migliora tramite rielaborazione ricorsiva. Pattern tipici:
Salvare contesto grezzo, poi aggiungere riassunti in linguaggio naturale (Claude Code, Gemini CLI)
Estrarre fatti chiave tramite schemi fissi (ChatSchema)
Compressione progressiva in vettori di significato (H-MEM)
Scelte per l’Utilizzo
Selezione del Contesto:
Retrieval tramite embedding (il più comune)
Traversal di knowledge graph (per relazioni complesse)
Scoring per similarità semantica
Pesi per recency/priorità
Condivisione del Contesto:
All’interno di un sistema:
Embed del contesto selezionato nei prompt (AutoGPT, ChatDev)
Scambio strutturato di messaggi tra agenti (Letta, MemOS)
Memoria condivisa tramite comunicazione indiretta (A-MEM)
Tra sistemi:
Adapter che convertono il formato del contesto (Langroid)
Rappresentazioni condivise tra piattaforme (Sharedrop)
Inferenza Proattiva delle Esigenze Utente:
ChatGPT e Claude analizzano i pattern di interazione per anticipare i bisogni
I sistemi imparano a mostrare informazioni prima che siano richieste esplicitamente
Il bilanciamento tra utilità e privacy resta una sfida progettuale chiave
Competenze e Mastery in Ingegneria del Contesto
L’ingegneria del contesto è sempre più centrale nello sviluppo AI; alcune competenze distinguono i team efficaci da quelli in difficoltà.
1. Assemblaggio Strategico del Contesto
Le squadre devono capire quali informazioni servono a ciascun compito. Non basta raccogliere dati: serve comprendere i requisiti abbastanza a fondo da distinguere l’essenziale dal rumore.
In pratica:
Analizzare i fallimenti per individuare contesti mancanti
A/B test su diverse combinazioni di contesto
Osservabilità per capire quali elementi guidano la performance
2. Architettura dei Sistemi di Memoria
Serve padronanza dei tipi di memoria e delle loro interazioni:
Quando usare breve vs lungo termine?
Come interagiscono i diversi tipi?
Come comprimere mantenendo fedeltà?
3. Ricerca e Retrieval Semantico
Oltre il semplice matching di parole chiave:
Conoscenza dei modelli di embedding e loro limiti
Metriche di similarità vettoriale e tradeoff
Strategie di riordino e filtraggio
Gestione di query ambigue
4. Economia dei Token e Analisi dei Costi
Ogni byte di contesto comporta compromessi:
Monitorare l’uso dei token per composizioni diverse
Comprendere i costi di processamento specifici per modello
Bilanciare qualità, costo e latenza
5. Orchestrazione di Sistema
Con più agenti, strumenti e sistemi di memoria, l’orchestrazione è essenziale:
Coordinamento tra sub-agenti
Gestione dei fallimenti e recupero
Stato persistente per task a lungo termine
6. Valutazione e Misurazione
L’ingegneria del contesto è un’attività di ottimizzazione:
Definire metriche significative
A/B test tra approcci di context engineering
Misurare l’impatto sul risultato utente, non solo l’accuratezza
Come osserva un ingegnere senior, il modo più rapido di portare AI di qualità ai clienti è incorporare piccoli concetti modulari dagli agenti nei prodotti esistenti.
Best Practice per l’Ingegneria del Contesto
1. Parti Semplice, Evolvi Deliberatamente
Inizia con prompt engineering e memoria tipo scratchpad. Aggiungi complessità (isolamento multi-agente, retrieval sofisticato) solo se ne hai chiara necessità.
2. Misura Tutto
Usa tool come LangSmith per osservabilità. Traccia:
Uso dei token per ogni approccio
Metriche di performance (accuratezza, correttezza, soddisfazione utente)
Tradeoff costo-latenza
3. Automatizza la Gestione della Memoria
La curation manuale non scala. Implementa:
Riassunti automatici ai confini del contesto
Filtraggio intelligente e scoring di rilevanza
Funzioni di decadimento per le informazioni vecchie
4. Progetta per Chiarezza e Auditabilità
La qualità del contesto cresce quando si capisce cosa vede il modello. Usa:
Formati chiari e strutturati (JSON, Markdown)
Contesto etichettato per ruolo
Separazione tra componenti del contesto
5. Metti il Contesto al Centro, Non L’LLM
Non partire da “quale LLM usare”, ma da “quale contesto serve a questo task?”. L’LLM è solo un componente di un sistema guidato dal contesto.
6. Abbraccia Architetture Stratificate
Separa:
Working memory (finestra di contesto attuale)
Memoria a breve termine (interazioni recenti)
Memoria a lungo termine (fatti persistenti)
Ogni layer serve scopi diversi e può essere ottimizzato in modo indipendente.
Sfide e Futuri Sviluppi
Sfide Attuali
1. Degrado del Contesto e Scalabilità
Esistono tecniche per mitigare il degrado, ma il problema resta irrisolto. Con input crescenti, selezione e compressione diventano sempre più critiche.
2. Coerenza e Consistenza della Memoria
Mantenere coerenza tra diversi tipi di memoria e tempi è sfidante. Confitti o dati obsoleti degradano le performance.
3. Privacy e Divulgazione Selettiva
Con sistemi che conservano contesti sempre più ricchi sugli utenti, bilanciare personalizzazione e privacy diventa centrale. Nas
Domande frequenti
Il prompt engineering si concentra sulla stesura di un singolo comando per un LLM. L’ingegneria del contesto è una disciplina di sistema più ampia che gestisce l’intero ecosistema informativo per un modello AI, inclusi memoria, strumenti e dati recuperati, per ottimizzare le prestazioni su compiti complessi e con stato.
Il degrado del contesto è il peggioramento imprevedibile delle prestazioni di un LLM man mano che il suo input contestuale si allunga. I modelli possono mostrare improvvisi cali di accuratezza, ignorare parti del contesto o generare allucinazioni, evidenziando la necessità di gestire la qualità e non solo la quantità del contesto.
Le quattro strategie fondamentali sono: 1. Scrivere il Contesto (salvare informazioni al di fuori della finestra di contesto, come scratchpad o memoria), 2. Selezionare il Contesto (recuperare solo le informazioni rilevanti), 3. Comprimere il Contesto (riassumere o snellire per risparmiare spazio), e 4. Isolare il Contesto (usare sistemi multi-agente o sandbox per separare le competenze).
Arshia è una AI Workflow Engineer presso FlowHunt. Con una formazione in informatica e una passione per l'IA, è specializzata nella creazione di workflow efficienti che integrano strumenti di intelligenza artificiale nelle attività quotidiane, migliorando produttività e creatività.
Arshia Kahani
AI Workflow Engineer
Diventa Maestro dell’Ingegneria del Contesto
Pronto a costruire la prossima generazione di sistemi AI? Esplora le nostre risorse e strumenti per implementare tecniche avanzate di ingegneria del contesto nei tuoi progetti.
Lunga vita all'Ingegneria del Contesto: Costruire Sistemi AI di Produzione con Database Vettoriali Moderni
Scopri come l'ingegneria del contesto sta rivoluzionando lo sviluppo AI, l’evoluzione dal RAG ai sistemi pronti per la produzione e perché database vettoriali m...
Sicurezza dell'IA e AGI: L'avvertimento di Anthropic sull'Intelligenza Artificiale Generale
Esplora le preoccupazioni di Jack Clark, co-fondatore di Anthropic, sulla sicurezza dell'IA, la consapevolezza situazionale nei grandi modelli linguistici e il ...
Esplorare l'Uso del Computer e del Browser con i LLM
Esplora come l'IA si sia evoluta dai modelli linguistici ai sistemi che navigano le interfacce grafiche e i browser web, con approfondimenti su innovazioni, sfi...
3 min di lettura
AI
Large Language Models
+4
Consenso Cookie Usiamo i cookie per migliorare la tua esperienza di navigazione e analizzare il nostro traffico. See our privacy policy.