Middleware Human-in-the-Loop in Python: Costruire Agenti AI Sicuri con Workflow di Approvazione
Scopri come implementare il middleware human-in-the-loop in Python usando LangChain per aggiungere funzionalità di approvazione, modifica e rifiuto agli agenti AI prima dell’esecuzione degli strumenti.
Costruire agenti AI che possano eseguire strumenti e compiere azioni in autonomia è potente, ma comporta rischi intrinseci. Cosa succede quando un agente decide di inviare una mail con informazioni errate, approvare una grossa transazione finanziaria o modificare dati critici nel database? Senza adeguate misure di sicurezza, agenti autonomi possono causare danni significativi prima che qualcuno se ne accorga. Qui entra in gioco il middleware human-in-the-loop. In questa guida completa, esploreremo come implementare il middleware human-in-the-loop in Python utilizzando LangChain, permettendoti di costruire agenti AI che si fermano per l’approvazione umana prima di eseguire operazioni sensibili. Imparerai ad aggiungere workflow di approvazione, implementare funzionalità di modifica e gestire i rifiuti—tutto mantenendo efficienza e intelligenza dei tuoi sistemi autonomi.
Comprendere i Cicli degli Agenti AI e l’Esecuzione degli Strumenti
Prima di addentrarci nel middleware human-in-the-loop, è fondamentale capire come funzionano gli agenti AI alla base. Un agente AI opera tramite un ciclo continuo che si ripete finché l’agente decide di aver completato il suo compito. Il ciclo principale dell’agente è costituito da tre componenti principali: un modello linguistico che ragiona su cosa fare dopo, un insieme di strumenti che l’agente può richiamare per agire, e un sistema di gestione dello stato che tiene traccia della cronologia della conversazione e di ogni contesto rilevante. L’agente inizia ricevendo un messaggio dall’utente, poi il modello linguistico analizza questo input insieme agli strumenti disponibili e decide se chiamare uno strumento o fornire una risposta finale. Se il modello decide di chiamare uno strumento, questo viene eseguito e i risultati vengono reintegrati nella cronologia della conversazione. Questo ciclo continua—ragionamento del modello, selezione dello strumento, esecuzione dello strumento, integrazione del risultato—finché il modello determina che non sono necessarie ulteriori chiamate a strumenti e fornisce una risposta finale all’utente.
Questo schema semplice ma potente è diventato la base per centinaia di framework di agenti AI negli ultimi anni. L’eleganza del ciclo dell’agente sta nella sua flessibilità: cambiando gli strumenti disponibili a un agente, gli si permette di eseguire compiti molto diversi. Un agente con strumenti email può gestire comunicazioni, uno con strumenti database può interrogare e aggiornare record, uno con strumenti finanziari può processare transazioni. Tuttavia, questa flessibilità introduce anche rischi. Poiché il ciclo dell’agente opera in autonomia, non c’è un meccanismo integrato che metta in pausa e chieda a un umano se una particolare azione debba effettivamente essere compiuta. Il modello potrebbe decidere di inviare una mail, eseguire una query su database o approvare una transazione finanziaria, e quando un umano se ne accorge, l’azione è già stata completata. Qui emergono i limiti del ciclo base dell’agente in ambienti di produzione.
Pronto a far crescere il tuo business?
Inizia oggi la tua prova gratuita e vedi i risultati in pochi giorni.
Perché la Supervisione Umana è Importante nei Sistemi AI in Produzione
Man mano che gli agenti AI diventano più capaci e vengono implementati in contesti aziendali reali, la necessità di supervisione umana cresce in modo critico. L’impatto delle azioni autonome degli agenti varia enormemente a seconda del contesto. Alcune chiamate di strumenti sono a basso rischio e possono essere eseguite immediatamente senza revisione umana—ad esempio leggere un’email o recuperare informazioni da un database. Altre chiamate sono ad alto rischio e potenzialmente irreversibili, come inviare comunicazioni a nome dell’utente, trasferire fondi, cancellare record o prendere decisioni che vincolano l’organizzazione. In sistemi di produzione, il costo di un errore su un’operazione critica può essere enorme. Una mail mal scritta inviata al destinatario sbagliato può danneggiare rapporti commerciali. Un budget approvato erroneamente può portare a perdite finanziarie. Una cancellazione di dati eseguita per errore può causare una perdita di informazioni che richiede ore o giorni per essere recuperata da backup.
Oltre ai rischi operativi immediati, ci sono anche aspetti normativi e di conformità. Molti settori hanno requisiti stringenti che impongono che certe decisioni vengano prese con giudizio e approvazione umana. Le istituzioni finanziarie devono garantire la supervisione umana per transazioni sopra certe soglie. I sistemi sanitari devono prevedere la revisione umana di alcune decisioni automatizzate. Gli studi legali devono assicurare che le comunicazioni siano riviste prima di essere inviate a nome dei clienti. Questi requisiti non sono solo burocrazia: esistono perché le conseguenze di decisioni completamente autonome in questi ambiti possono essere gravi. Inoltre, la supervisione umana fornisce un meccanismo di feedback che aiuta a migliorare l’agente nel tempo. Quando un umano rivede un’azione proposta dall’agente e la approva o la modifica, quel feedback può essere usato per affinare i prompt dell’agente, regolare la logica di selezione degli strumenti o riaddestrare i modelli sottostanti. Si crea così un circolo virtuoso in cui l’agente diventa più affidabile e meglio calibrato sulle esigenze e la tolleranza al rischio dell’organizzazione.
Cos’è il Middleware Human-in-the-Loop?
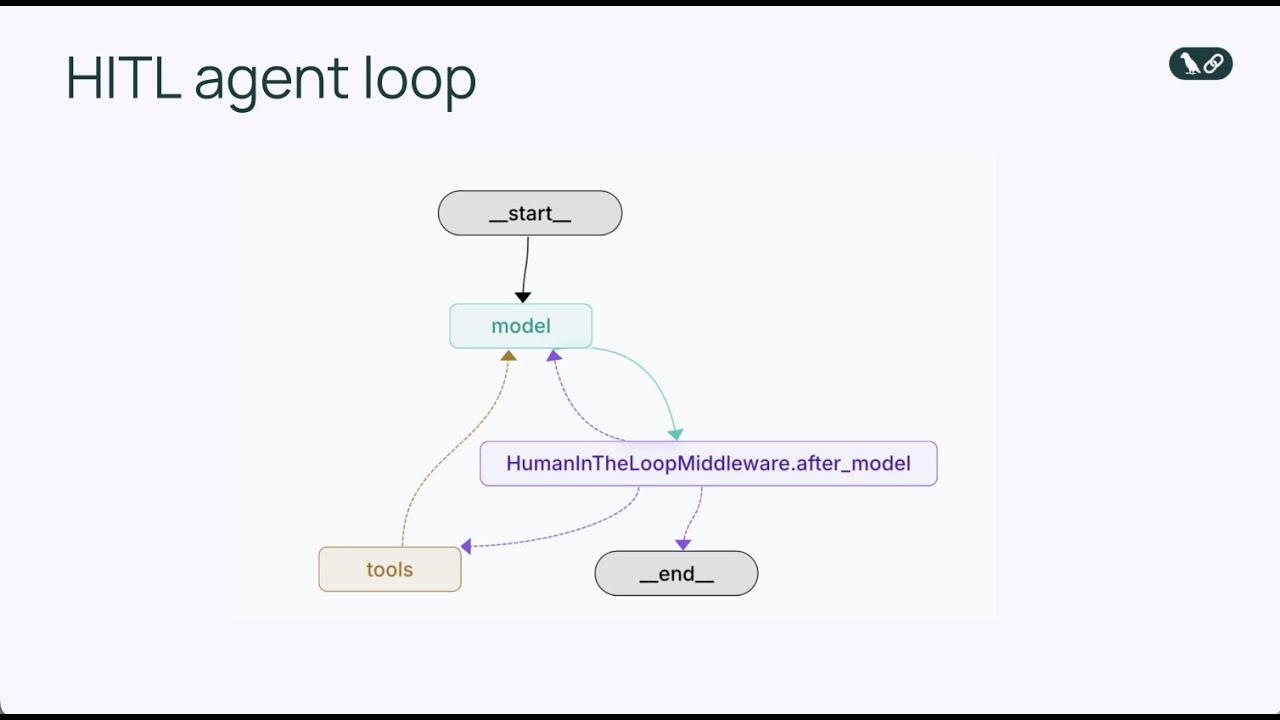
Il middleware human-in-the-loop è una componente specializzata che intercetta il ciclo dell’agente in un momento cruciale: subito prima dell’esecuzione di uno strumento. Invece di consentire all’agente di eseguire direttamente la chiamata allo strumento, il middleware mette in pausa l’esecuzione e presenta l’azione proposta a un umano perché la esamini. L’umano ha quindi diverse opzioni: può approvare l’azione, permettendone l’esecuzione così come proposta dall’agente; può modificarla, regolando i parametri (ad esempio cambiando il destinatario di una mail o il contenuto del messaggio) prima dell’esecuzione; oppure può rifiutare l’azione, inviando un feedback all’agente che spiega perché l’azione non sia appropriata e chiedendo di riconsiderare l’approccio. Questo meccanismo decisionale a tre vie—approva, modifica, rifiuta—offre una struttura flessibile che si adatta a diverse necessità di supervisione umana.
Il middleware opera modificando il ciclo standard dell’agente, includendo un punto decisionale aggiuntivo. Nel ciclo base, la sequenza è: il modello chiama strumenti → gli strumenti eseguono → i risultati tornano al modello. Con il middleware human-in-the-loop, la sequenza diventa: il modello chiama strumenti → il middleware intercetta → l’umano rivede → l’umano decide (approva/modifica/rifiuta) → se approvato o modificato, lo strumento esegue → i risultati tornano al modello. L’inserimento di un punto decisionale umano non rompe il ciclo dell’agente; lo arricchisce aggiungendo una valvola di sicurezza. Il middleware è configurabile: puoi specificare esattamente quali strumenti devono attivare la revisione umana e quali possono eseguire automaticamente. Potresti voler interrompere tutte le chiamate per invio email ma permettere le query di sola lettura su database senza revisione. Questo controllo granulare assicura che la supervisione umana venga aggiunta dove serve senza creare colli di bottiglia per operazioni a basso rischio.
Iscriviti alla nostra newsletter
Ricevi gratuitamente gli ultimi consigli, tendenze e offerte.
I Tre Tipi di Risposta: Approvazione, Modifica e Rifiuto
Quando il middleware human-in-the-loop interrompe l’esecuzione di uno strumento dell’agente, il revisore umano ha tre modalità principali di risposta, ognuna con uno scopo diverso nel workflow di approvazione. Comprendere questi tre tipi di risposta è essenziale per progettare sistemi human-in-the-loop efficaci.
Approvazione è il tipo di risposta più semplice. Quando un umano rivede una chiamata a uno strumento e determina che è appropriata e deve procedere esattamente come proposta, fornisce una decisione di approvazione. Questo segnala al middleware che lo strumento deve essere eseguito con i parametri esatti specificati dall’agente. Nel contesto di un’assistente email, l’approvazione significa che la bozza della mail è corretta e può essere inviata al destinatario specificato con oggetto e corpo indicati. L’approvazione è il percorso più rapido—consente all’azione proposta dall’agente di procedere senza modifiche. È appropriato quando l’agente ha svolto bene il suo lavoro e il revisore umano concorda con l’azione. Le decisioni di approvazione sono tipicamente veloci da prendere, importante perché non si vuole che la revisione umana diventi un collo di bottiglia che rallenta l’intero workflow.
Modifica è una risposta più articolata, che riconosce che l’approccio generale dell’agente è corretto, ma alcuni dettagli vanno aggiustati prima dell’esecuzione. Quando un umano fornisce una risposta di modifica, non sta rifiutando la decisione dell’agente di agire, ma sta raffinando le specifiche di come quell’azione dovrebbe essere compiuta. In uno scenario email, modificare potrebbe significare cambiare il destinatario, rendere più professionale l’oggetto, o modificare il testo del corpo per aggiungere contesto o rimuovere frasi problematiche. La caratteristica chiave di una risposta di modifica è che cambia i parametri dello strumento mantenendo la stessa chiamata. L’agente ha deciso di inviare una mail, e l’umano concorda, ma vuole aggiustare il contenuto o il destinatario. Dopo la modifica, lo strumento esegue con i parametri aggiornati e i risultati tornano all’agente. Questo approccio è particolarmente prezioso perché consente all’agente di proporre azioni, lasciando agli umani la possibilità di perfezionarle in base alla propria esperienza o conoscenza del contesto aziendale.
Rifiuto è il tipo di risposta più incisivo, perché non solo blocca l’azione proposta ma invia anche un feedback all’agente spiegando perché l’azione non era appropriata. Quando un umano rifiuta una chiamata a uno strumento, dichiara che l’azione proposta non deve essere eseguita e fornisce indicazioni su come l’agente dovrebbe riconsiderare il suo approccio. Nell’esempio email, il rifiuto può avvenire se l’agente propone di approvare un budget importante senza dettagli sufficienti. L’umano rifiuta e spiega che sono necessarie più informazioni prima di approvare. Questo messaggio di rifiuto diventa parte del contesto dell’agente, che può ragionare su tale feedback e proporre un nuovo approccio. Magari l’agente propone allora un’email che chiede dettagli aggiuntivi sulla proposta di budget prima di approvare. I rifiuti sono fondamentali per evitare che l’agente riproponga ripetutamente azioni inadeguate. Fornendo un feedback chiaro sul motivo del rifiuto, si aiuta l’agente ad apprendere e migliorare le sue decisioni.
Implementare il Middleware Human-in-the-Loop: Un Esempio Pratico
Vediamo ora una reale implementazione del middleware human-in-the-loop usando LangChain e Python. L’esempio sarà un’assistente email—uno scenario pratico che mostra il valore della supervisione umana ed è facile da comprendere. L’assistente potrà inviare email per conto di un utente, e aggiungeremo il middleware human-in-the-loop per assicurarci che ogni invio sia revisionato prima dell’esecuzione.
Per prima cosa, definiamo lo strumento email che l’agente userà. Questo richiede tre parametri: indirizzo email destinatario, oggetto e corpo. Lo strumento è semplice—rappresenta l’azione di inviare una mail. In una reale implementazione, potrebbe integrarsi con servizi come Gmail o Outlook, ma qui lo manteniamo semplice. Ecco la struttura base:
defsend_email(recipient: str, subject: str, body: str) -> str:
"""Invia una email al destinatario specificato."""returnf"Email inviata a {recipient} con oggetto '{subject}'"
Poi creiamo un agente che usa questo strumento email. Utilizzeremo GPT-4 come modello linguistico e forniremo un prompt di sistema che indica all’agente di essere un assistente email disponibile. L’agente è inizializzato con lo strumento email ed è pronto a rispondere alle richieste utente:
from langchain.agents import create_agent
from langchain_openai import ChatOpenAI
model = ChatOpenAI(model="gpt-4o")
tools = [send_email]
agent = create_agent(
model=model,
tools=tools,
system_prompt="Sei un assistente email disponibile per Sydney. Puoi inviare email per conto dell'utente.")
A questo punto abbiamo un agente base che può inviare email, ma senza supervisione umana—l’agente può inviare email senza alcuna revisione. Ora aggiungiamo il middleware human-in-the-loop. L’implementazione è sorprendentemente semplice, richiedendo solo due righe di codice:
from langchain.agents.middleware import HumanInTheLoopMiddleware
agent = create_agent(
model=model,
tools=tools,
system_prompt="Sei un assistente email disponibile per Sydney. Puoi inviare email per conto dell'utente.",
middleware=[
HumanInTheLoopMiddleware(
interrupt_on={"send_email": True}
)
]
)
Aggiungendo HumanInTheLoopMiddleware e specificando interrupt_on={"send_email": True}, diciamo all’agente di mettere in pausa prima di ogni chiamata allo strumento send_email e attendere l’approvazione umana. Il valore True significa che tutte le chiamate a send_email attiveranno un’interruzione con configurazione predefinita. Se volessimo un controllo più granulare, potremmo specificare quali tipi di decisioni sono consentite (approva, modifica, rifiuta) o fornire descrizioni personalizzate per l’interruzione.
Testare il Middleware in Scenari a Basso Rischio
Una volta inserito il middleware, testiamolo con uno scenario email a basso rischio. Immagina che un utente chieda all’agente di rispondere a una mail informale di una collega, Alice, che propone di prendere un caffè la prossima settimana. L’agente processa la richiesta e decide di inviare una risposta amichevole. Ecco cosa succede:
L’utente invia il messaggio: “Per favore rispondi all’email di Alice sull’andare a prendere un caffè la prossima settimana.”
Il modello dell’agente elabora e decide di chiamare lo strumento send_email con parametri tipo recipient=“alice@example.com
”, subject=“Caffè la prossima settimana?”, body=“Mi piacerebbe prendere un caffè con te la prossima settimana!”
Prima che la mail venga inviata, il middleware intercetta la chiamata allo strumento e solleva un’interruzione.
Il revisore umano vede la mail proposta e la valuta. L’email sembra appropriata—amichevole, professionale e in linea con la richiesta.
L’umano approva l’azione fornendo una decisione di approvazione.
Il middleware permette l’esecuzione dello strumento e la mail viene inviata.
Questo workflow dimostra il percorso base dell’approvazione. La revisione umana aggiunge un livello di sicurezza senza rallentare troppo il processo. Per operazioni a basso rischio come questa, l’approvazione è tipicamente rapida perché l’azione proposta dall’agente è ragionevole e non necessita modifiche.
Testare il Middleware in Scenari ad Alto Rischio: La Risposta di Modifica
Consideriamo ora uno scenario più delicato in cui la modifica diventa preziosa. Immagina che l’agente riceva la richiesta di rispondere a una mail di un partner di startup che chiede all’utente di approvare un budget di un milione di dollari per il Q1. Questa è una decisione importante che richiede attenzione. L’agente potrebbe proporre una mail che dice: “Ho esaminato e approvato la proposta per il budget di 1 milione di dollari per il Q1.”
Quando questa mail arriva al revisore umano tramite l’interruzione del middleware, l’umano si rende conto che si tratta di un impegno finanziario significativo che non dovrebbe essere approvato con leggerezza. L’umano non vuole rifiutare l’intera idea di rispondere, ma vuole modificare la risposta per essere più cauto. Fornisce quindi una risposta di modifica che cambia il testo della mail, ad esempio: “Grazie per la proposta. Vorrei esaminare i dettagli più accuratamente prima di approvare. Puoi inviarmi una ripartizione di come verrà allocato il budget?”
Ecco come appare una risposta di modifica nel codice:
edit_decision = {
"type": "edit",
"edited_action": {
"name": "send_email",
"args": {
"recipient": "partner@startup.com",
"subject": "Proposta Budget Engineering Q1",
"body": "Grazie per la proposta. Vorrei esaminare i dettagli più accuratamente prima di approvare. Puoi inviarmi una ripartizione di come verrà allocato il budget?" }
}
}
Quando il middleware riceve questa decisione di modifica, esegue lo strumento con i parametri aggiornati. La mail viene inviata con il contenuto rivisto dall’umano, più adatto a una decisione finanziaria delicata. Questo dimostra la potenza della risposta di modifica: consente agli umani di sfruttare la capacità dell’agente di redigere comunicazioni, assicurando che l’output finale rifletta il giudizio umano e gli standard organizzativi.
Testare il Middleware con Rifiuto e Feedback
La risposta di rifiuto è particolarmente potente perché non solo blocca un’azione inadeguata, ma fornisce anche un feedback che aiuta l’agente a migliorare il proprio ragionamento. Consideriamo ancora lo scenario della mail sul budget. Supponiamo che l’agente proponga una mail che dice: “Ho esaminato e approvato il budget di 1 milione di dollari per il Q1.”
Il revisore umano vede questa proposta e capisce che è troppo affrettata. Un impegno di 1 milione non deve essere approvato senza una revisione approfondita, discussione con gli stakeholder e comprensione dei dettagli. L’umano non vuole solo modificare la mail, ma rifiutare l’intero approccio e chiedere all’agente di riconsiderare. Fornisce quindi una risposta di rifiuto con feedback:
reject_decision = {
"type": "reject",
"message": "Non posso approvare questo budget senza ulteriori informazioni. Per favore, redigi una mail chiedendo una ripartizione dettagliata della proposta, includendo come i fondi saranno allocati tra i diversi team di ingegneria e quali deliverable specifici sono previsti."}
Quando il middleware riceve questa decisione di rifiuto, non esegue lo strumento. Invia invece il messaggio di rifiuto all’agente come parte del contesto della conversazione. L’agente vede che la sua azione è stata respinta e ne comprende il motivo. Può quindi ragionare su questo feedback e proporre un nuovo approccio. In questo caso, potrebbe proporre una nuova mail che chiede maggiori dettagli sulla proposta, risposta più appropriata a una richiesta finanziaria di rilievo. L’umano può poi rivedere questa nuova proposta e approvarla, modificarla ulteriormente o rifiutarla ancora se necessario.
Questo processo iterativo—proponi, revisiona, rifiuta con feedback, riproponi—è uno degli aspetti più preziosi del middleware human-in-the-loop. Crea un workflow collaborativo in cui la velocità e le capacità di ragionamento dell’agente si uniscono al giudizio umano e alla competenza di dominio.
Potenzia il tuo Workflow con FlowHunt
Scopri come FlowHunt automatizza i tuoi workflow di contenuti AI e SEO: dalla ricerca e generazione di contenuti fino alla pubblicazione e analisi, tutto in un'unica piattaforma.
Configurazione Avanzata: Controllo Granulare sulle Interruzioni
Sebbene l’implementazione base del middleware human-in-the-loop sia semplice, LangChain offre opzioni di configurazione avanzate che permettono di affinare con precisione come e quando avvengono le interruzioni. Una configurazione importante è specificare quali tipi di decisioni sono consentiti per ciascuno strumento. Ad esempio, potresti voler permettere approvazione e modifica per l’invio di email, ma non il rifiuto. Oppure potresti voler tutte e tre le decisioni per transazioni finanziarie, ma solo approvazione per query di sola lettura su database.
In questa configurazione, l’invio di email interrompe e consente tutte e tre le decisioni. Le operazioni di sola lettura vengono eseguite automaticamente senza interruzione. Le cancellazioni vengono interrotte ma non consentono la modifica—l’umano può solo approvare o rifiutare, non modificare i parametri di cancellazione. Questo controllo granulare assicura supervisione umana dove serve evitando colli di bottiglia su operazioni a basso rischio.
Un’altra funzione avanzata è la possibilità di fornire descrizioni personalizzate per le interruzioni. Di default, il middleware fornisce una descrizione generica come “L’esecuzione dello strumento richiede approvazione.” Puoi personalizzare questa descrizione per offrire informazioni più contestuali:
Considerazioni Importanti sull’Implementazione: Checkpointer e Gestione dello Stato
Un aspetto critico nell’implementazione del middleware human-in-the-loop, spesso trascurato, è la necessità di un checkpointer. Un checkpointer è un meccanismo che salva lo stato dell’agente al momento dell’interruzione, permettendo la ripresa del workflow in seguito. Questo è essenziale perché la revisione umana non avviene istantaneamente—potrebbe esserci un ritardo tra l’interruzione e la decisione umana. Senza un checkpointer, lo stato dell’agente andrebbe perso durante questo intervallo e non sarebbe possibile riprendere correttamente il workflow.
LangChain offre diversi tipi di checkpointer. Per sviluppo e test, puoi usare un checkpointer in memoria:
Per sistemi in produzione, in genere si usa un checkpointer persistente che salva lo stato su database o filesystem, assicurando che le interruzioni possano essere riprese anche dopo un riavvio dell’applicazione. Il checkpointer mantiene un registro completo dello stato dell’agente a ogni step, inclusa la cronologia della conversazione, le chiamate agli strumenti e i risultati di tali chiamate. Quando un umano fornisce una decisione (approva, modifica o rifiuta), il middleware usa il checkpointer per recuperare lo stato salvato, applicare la decisione umana e riprendere il ciclo dell’agente da quel punto.
Applicazioni Reali e Casi d’Uso
Il middleware human-in-the-loop è applicabile a un’ampia varietà di scenari reali in cui agenti autonomi devono compiere azioni ma tali azioni richiedono supervisione umana. Nel settore finanziario, agenti che processano transazioni, approvano prestiti o gestiscono investimenti possono usare il middleware per garantire che decisioni di valore siano riviste da persone qualificate prima dell’esecuzione. In sanità, agenti che raccomandano trattamenti o accedono a cartelle cliniche possono usare il middleware per assicurare la conformità alle normative sulla privacy e ai protocolli clinici. Nei servizi legali, agenti che redigono comunicazioni o accedono a documenti riservati possono usarlo per mantenere la supervisione dell’avvocato. Nel customer service, agenti che emettono rimborsi, prendono impegni verso clienti o gestiscono escalation possono garantirsi che tali azioni siano in linea con le policy aziendali.
Oltre a queste applicazioni settoriali, il middleware human-in-the-loop è prezioso in qualsiasi scenario in cui il costo di un errore dell’agente sia significativo. Ciò include sistemi di moderazione dei contenuti, HR, supply chain. Il filo conduttore è che le azioni proposte dall’agente hanno conseguenze reali e abbastanza impattanti da giustificare una revisione umana prima dell’esecuzione.
Confronto con Approcci Alternativi
Vale la pena considerare come il middleware human-in-the-loop si confronta con approcci alternativi per aggiungere supervisione umana ai sistemi agenti. Un’alternativa è far revisionare agli umani tutte le azioni dell’agente dopo l’esecuzione, ma così si rischia che l’azione sia già irreversibile: l’email è stata inviata, il record cancellato, la transazione finanziaria già processata. Il middleware human-in-the-loop previene queste azioni irreversibili prima che accadano.
Un’altra alternativa è che gli umani eseguano manualmente tutti i compiti che l’agente potrebbe svolgere, ma così si perde il valore degli agenti stessi. Questi sono utili proprio perché automatizzano compiti ripetitivi, lasciando agli umani le decisioni di livello superiore. Il middleware human-in-the-loop trova il giusto equilibrio: lascia che l’agente gestisca il lavoro ordinario, ma ferma per revisione umana quando la posta in gioco è alta.
Un terzo approccio sono i guardrail o regole di validazione che impediscono agli agenti di compiere azioni inappropriate. Ad esempio, una regola che impedisce di inviare email fuori dall’organizzazione o di cancellare record senza conferma. Questi guardrail sono preziosi e dovrebbero essere usati insieme al middleware, ma hanno limiti: sono basati su regole e non possono prevedere tutte le situazioni inappropriate. Il giudizio umano è più flessibile e contestuale delle regole, ed è qui che il middleware human-in-the-loop si rivela indispensabile.
Best Practice per l’Implementazione di Workflow Human-in-the-Loop
Quando implementi il middleware human-in-the-loop nelle tue applicazioni, alcune best practice possono aiutarti ad assicurare che il sistema sia efficace ed efficiente. Primo, sii strategico su quali strumenti richiedono interruzione. Interrompere ogni chiamata creerebbe colli di bottiglia e rallenterebbe il workflow. Concentrati su strumenti costosi, rischiosi o con conseguenze significative in caso di errore. Le operazioni di sola lettura in genere non necessitano interruzione. Le operazioni di scrittura o che compiono azioni esterne sì.
Secondo, fornisci chiara contestualizzazione ai revisori umani. Quando si verifica un’interruzione, l’umano deve capire quale azione l’agente sta proponendo e perché. Assicurati che le descrizioni delle interruzioni siano chiare e diano il contesto rilevante. Se l’agente propone di inviare una mail, mostra il testo completo. Se propone di cancellare un record, mostra quale record e perché. Più contesto dai, più rapide e accurate saranno le decisioni.
Terzo, rendi il processo di approvazione il più fluido possibile. Gli umani approveranno più velocemente se il processo è semplice e non richiede navigazioni o inserimenti complessi. Fornisci pulsanti o opzioni chiare per approva, modifica e rifiuta. Se la modifica è consentita, rendi facile per l’umano cambiare i parametri rilevanti senza dover comprendere il codice sottostante.
Quarto, usa i feedback di rifiuto in modo strategico. Quando rifiuti un’azione proposta dall’agente, fornisci feedback chiaro sul perché era inappropriata e su cosa dovrebbe fare invece. Questo aiuta l’agente a migliorare nel tempo. Col tempo, ricevendo feedback sui propri suggerimenti, l’agente si calibrerà meglio sugli standard e la tolleranza al rischio della tua organizzazione.
Quinto, monitora e analizza i pattern di interruzione. Tieni traccia di quali strumenti vengono interrotti più spesso, quali decisioni sono più comuni (approva, modifica, rifiuta) e quanto dura il processo di approvazione. Questi dati aiutano a identificare colli di bottiglia, raffinare la configurazione e potenzialmente migliorare i prompt dell’agente o la logica di selezione degli strumenti.
Integrazione del Middleware con FlowHunt
Per le organizzazioni che vogliono implementare workflow human-in-the-loop su larga scala, FlowHunt offre una piattaforma completa che si integra perfettamente con le capacità middleware di LangChain. FlowHunt ti permette di creare, distribuire e gestire agenti AI con workflow di approvazione integrati, semplificando l’aggiunta della supervisione umana ai processi di automazione. Con FlowHunt puoi configurare quali strumenti richiedono approvazione, personalizzare l’interfaccia di approvazione e tracciare tutte le approvazioni e i rifiuti per esigenze di compliance e audit. La piattaforma gestisce la complessità dello stato, del checkpointing e dell’orchestrazione dei workflow, lasciandoti concentrare su agenti efficaci e policy di approvazione. L’integrazione con LangChain ti consente di sfruttare tutta la potenza del middleware human-in-the-loop, beneficiando di un’interfaccia intuitiva e affidabilità enterprise.
Conclusione
Il middleware human-in-the-loop rappresenta un ponte essenziale tra l’efficienza degli agenti AI autonomi e la necessità di supervisione umana nei sistemi di produzione. Implementando workflow di approvazione, funzionalità di modifica e meccanismi di feedback per i rifiuti, puoi costruire agenti potenti e sicuri. Il modello decisionale a tre vie—approva, modifica, rifiuta—offre flessibilità per gestire diversi tipi di supervisione, dalle operazioni a basso rischio approvabili rapidamente alle decisioni critiche che richiedono attenzione e modifiche. L’implementazione è semplice, richiedendo poche righe di codice da aggiungere ai tuoi agenti LangChain esistenti, ma l’impatto su affidabilità e sicurezza è enorme. Man mano che gli agenti AI diventano più capaci e vengono adottati in processi aziendali critici, il middleware human-in-the-loop diventerà componente fondamentale di un’AI responsabile. Che tu stia costruendo assistenti email, sistemi finanziari, applicazioni sanitarie o qualsiasi altro dominio in cui le azioni dell’agente hanno conseguenze reali, il middleware human-in-the-loop offre la struttura per garantire che il giudizio umano resti centrale nei tuoi workflow di automazione.
Domande frequenti
Il middleware human-in-the-loop è una componente che mette in pausa l'esecuzione dell'agente AI prima di eseguire strumenti specifici, permettendo agli umani di approvare, modificare o rifiutare l'azione proposta. Questo aggiunge un livello di sicurezza per operazioni costose o rischiose.
Usalo per operazioni ad alto rischio come invio di email, transazioni finanziarie, scritture su database o qualsiasi esecuzione di strumenti che richieda supervisione per la conformità o potrebbe avere conseguenze significative se eseguita in modo errato.
I tre tipi principali di risposta sono: Approvazione (esegue lo strumento come proposto), Modifica (modifica i parametri dello strumento prima dell'esecuzione) e Rifiuto (rifiuta l'esecuzione e invia un feedback al modello per la revisione).
Importa HumanInTheLoopMiddleware da langchain.agents.middleware, configurandolo con gli strumenti su cui vuoi interrompere, e passalo alla funzione di creazione dell'agente. Avrai anche bisogno di un checkpointer per mantenere lo stato tra le interruzioni.
Arshia è una AI Workflow Engineer presso FlowHunt. Con una formazione in informatica e una passione per l'IA, è specializzata nella creazione di workflow efficienti che integrano strumenti di intelligenza artificiale nelle attività quotidiane, migliorando produttività e creatività.
Arshia Kahani
AI Workflow Engineer
Automatizza in Sicurezza i tuoi Workflow AI con FlowHunt
Crea agenti intelligenti con workflow di approvazione integrati e supervisione umana. FlowHunt rende semplice implementare automazioni human-in-the-loop per i tuoi processi aziendali.
Costruire agenti AI estendibili: un’analisi approfondita dell’architettura middleware
Scopri come l’architettura middleware di LangChain 1.0 rivoluziona lo sviluppo di agenti, permettendo agli sviluppatori di creare deep agent potenti ed estendib...
Human-in-the-Loop (HITL) è un approccio all'intelligenza artificiale e al machine learning che integra l'esperienza umana nella formazione, regolazione e applic...
Perché i Migliori Ingegneri Stanno Abbandonando i Server MCP: 3 Alternative Provate per Agenti AI Efficienti
Scopri perché i migliori ingegneri stanno abbandonando i server MCP ed esplora tre alternative comprovate—approcci basati su CLI, strumenti basati su script ed ...
18 min di lettura
AI Agents
MCP
+3
Consenso Cookie Usiamo i cookie per migliorare la tua esperienza di navigazione e analizzare il nostro traffico. See our privacy policy.