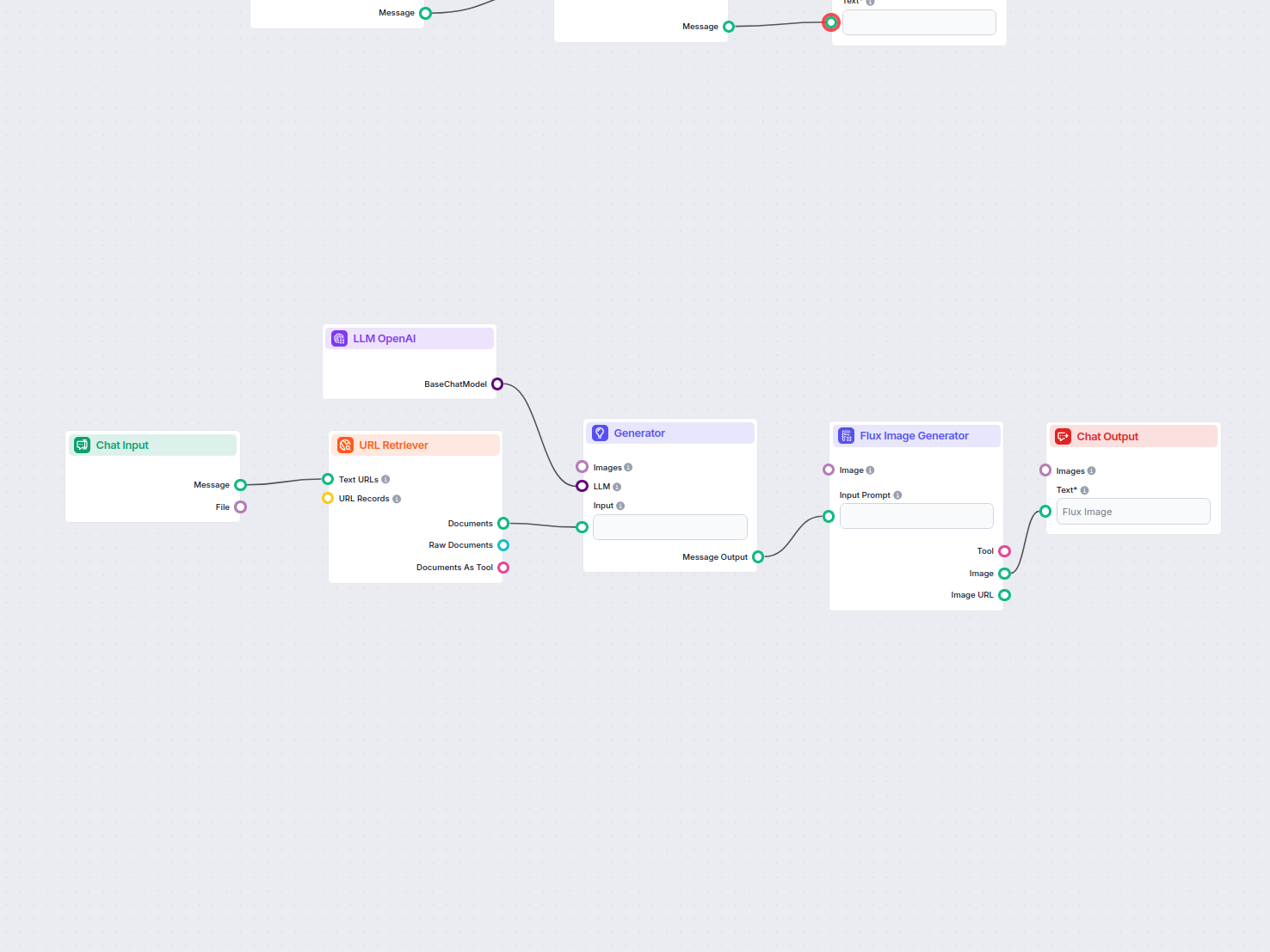
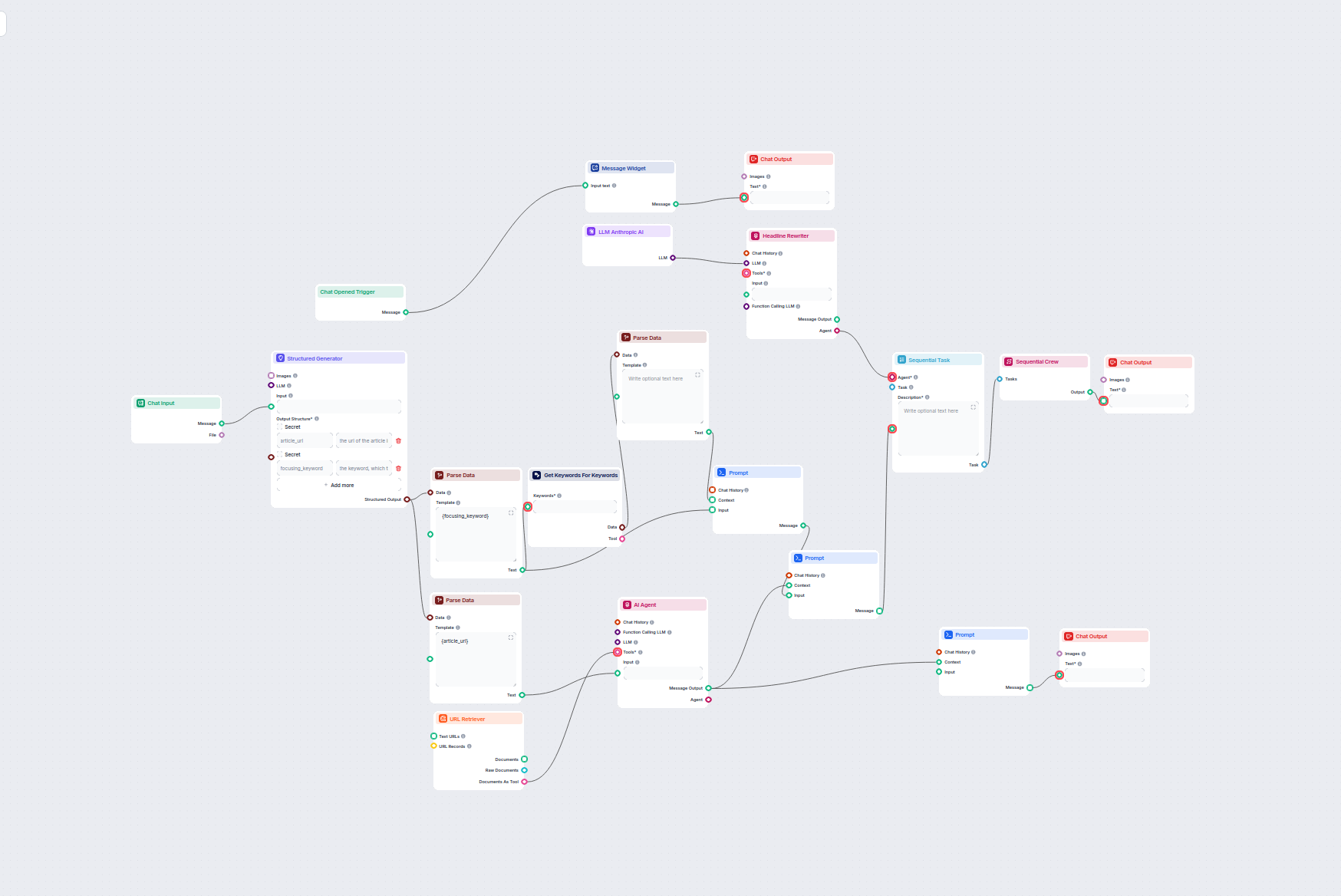
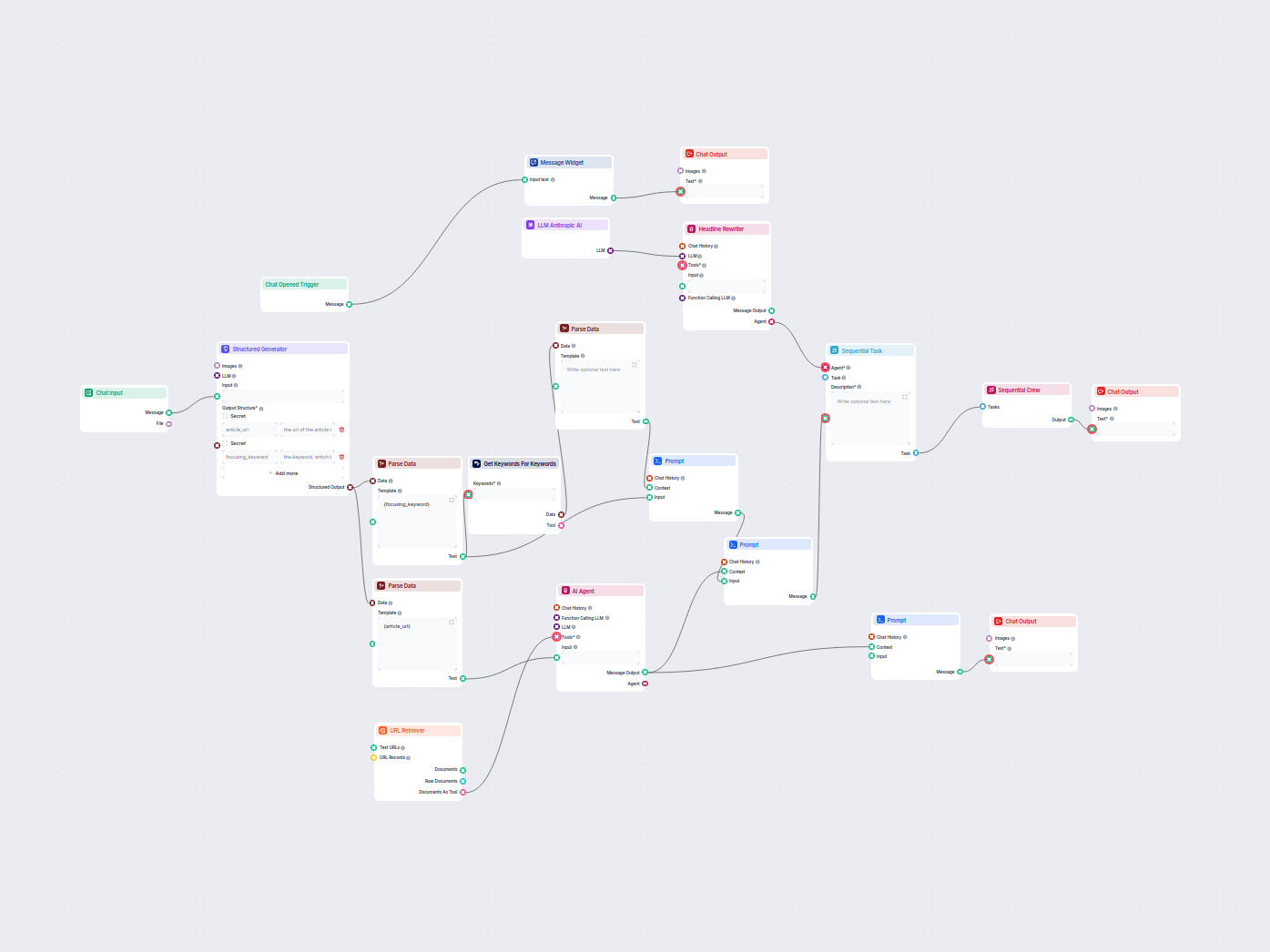
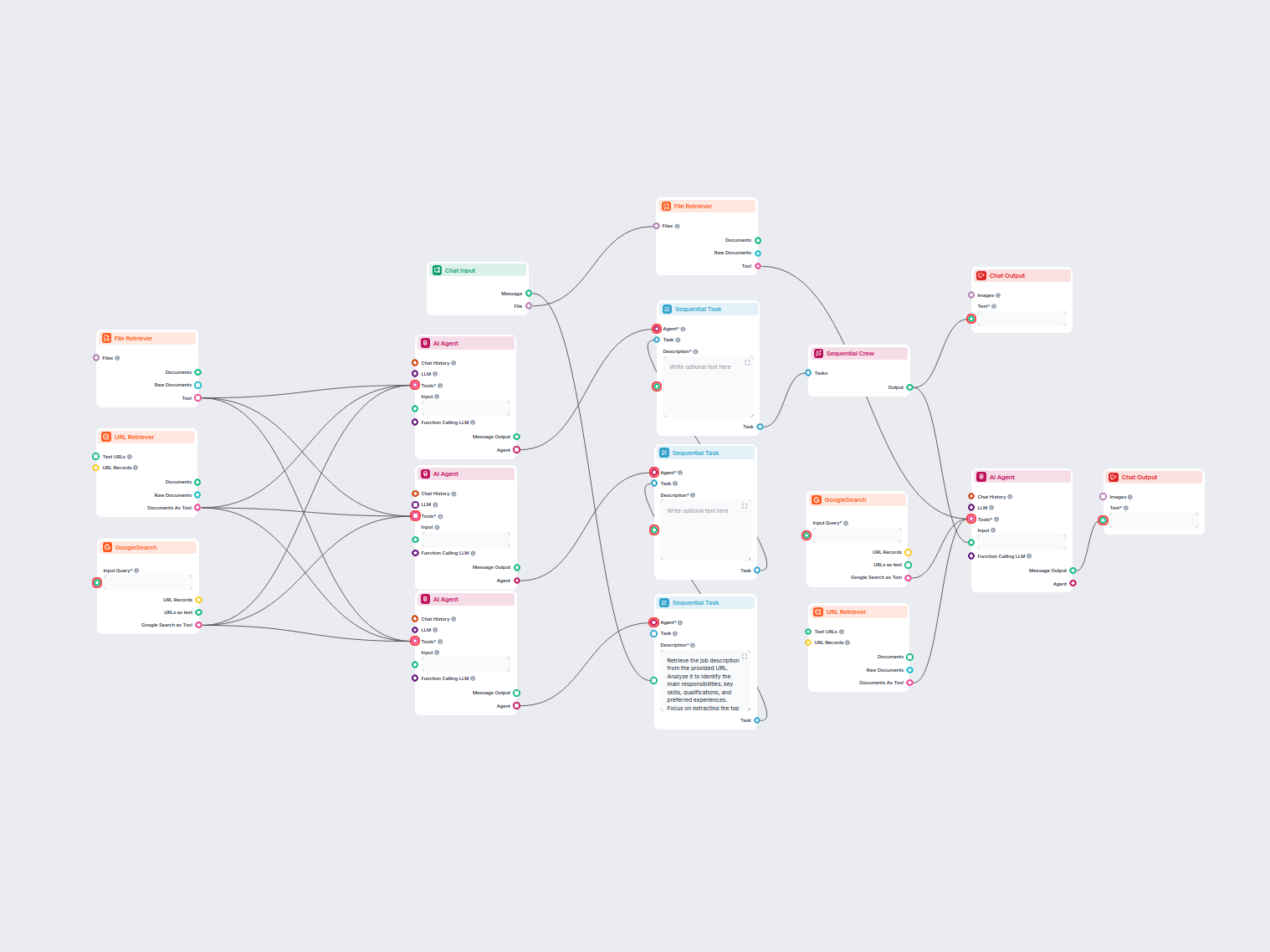
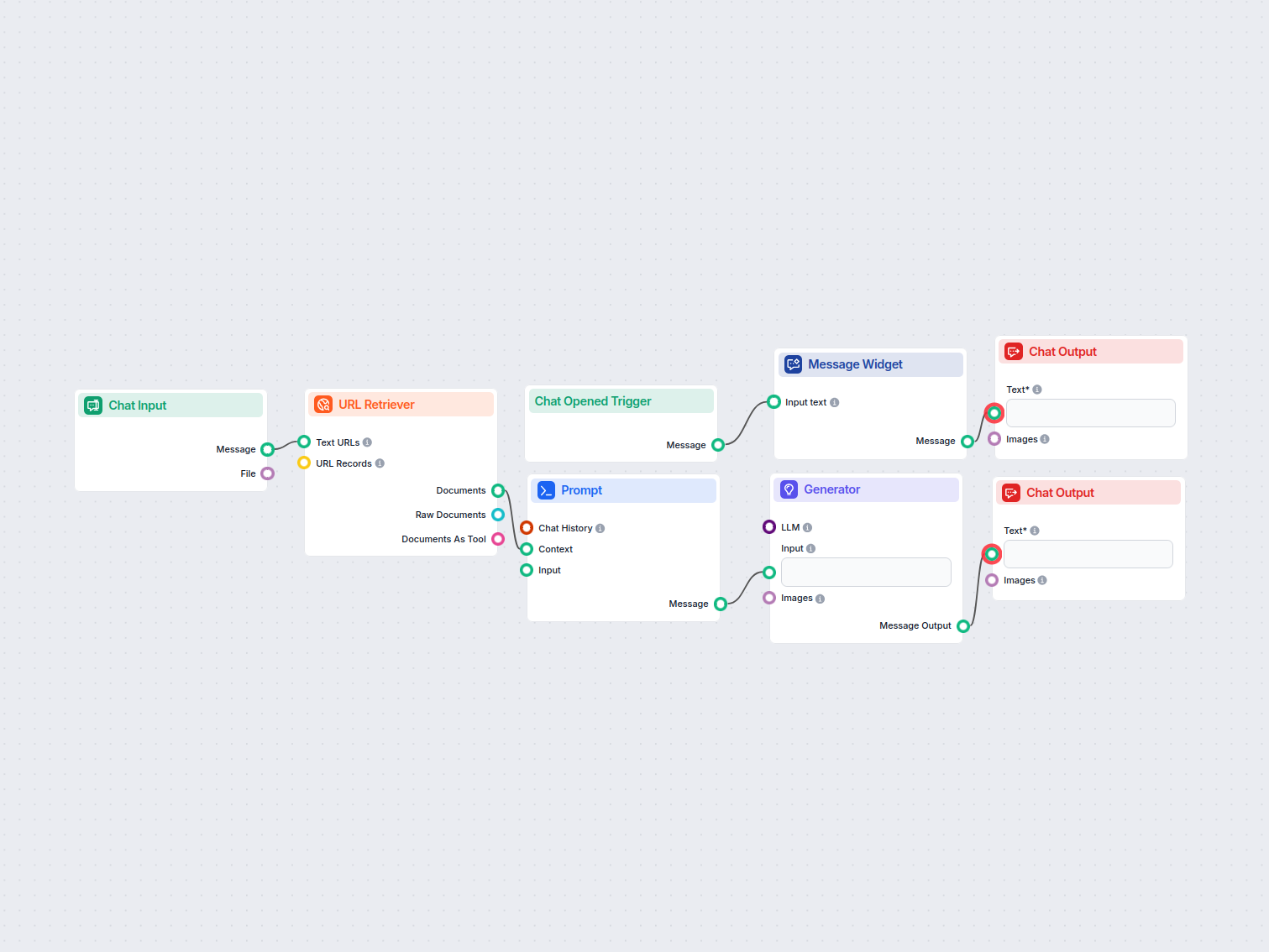
Generatore FAQ automatizzato da ricerca web
Questo workflow alimentato dall'IA genera risposte concise e di alta qualità alle domande delle FAQ per qualsiasi domanda, cercando sul web, estraendo contenuti...
3 min di lettura
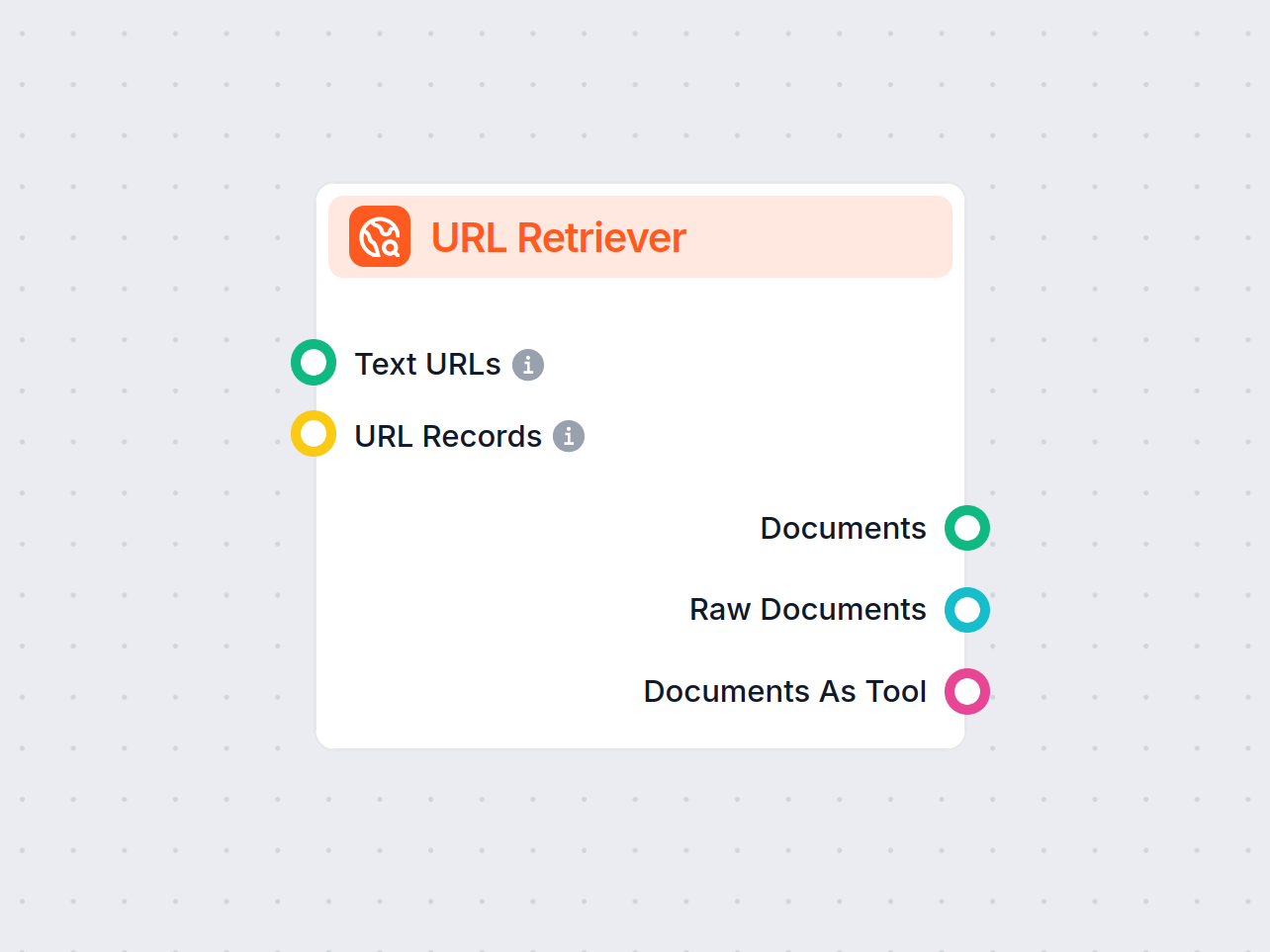
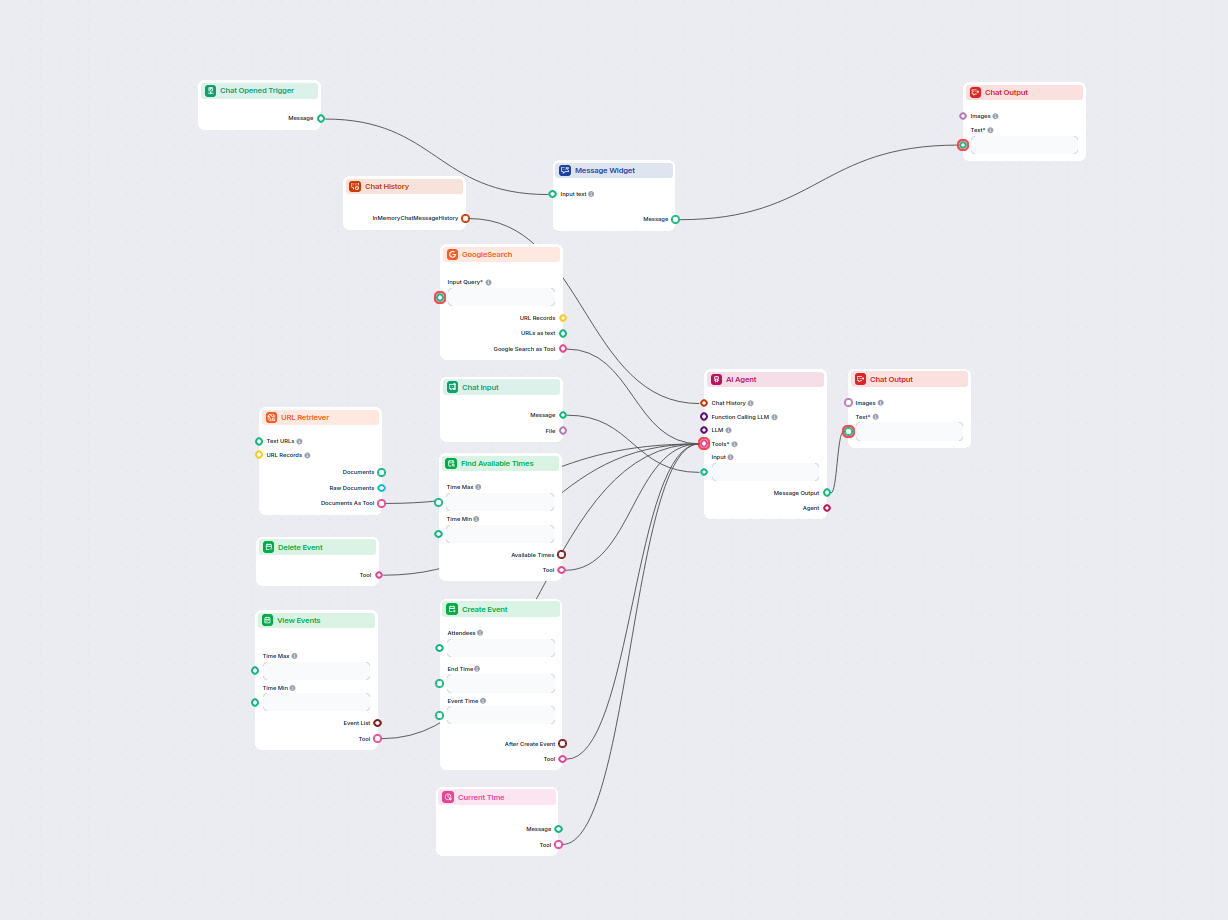
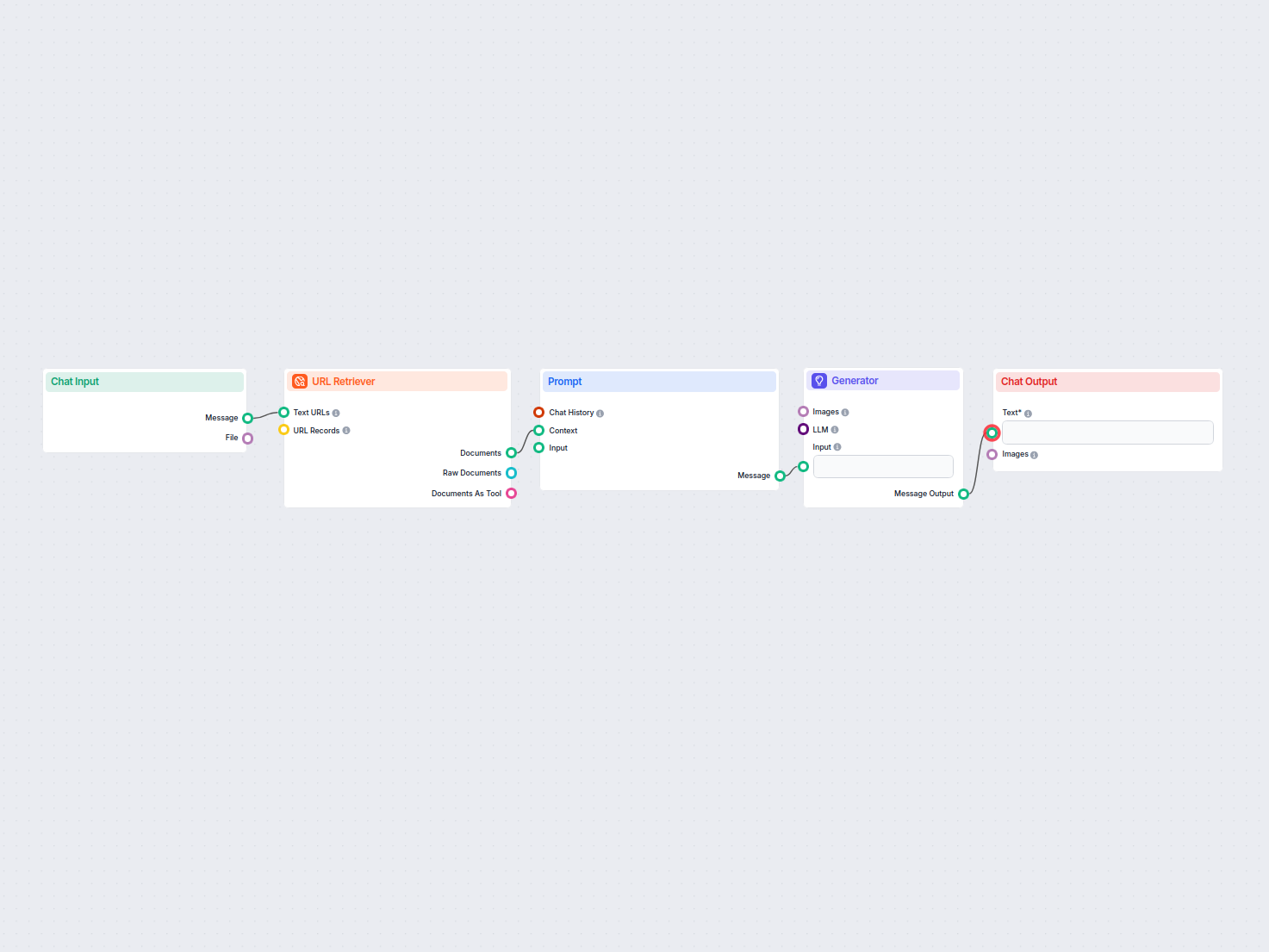
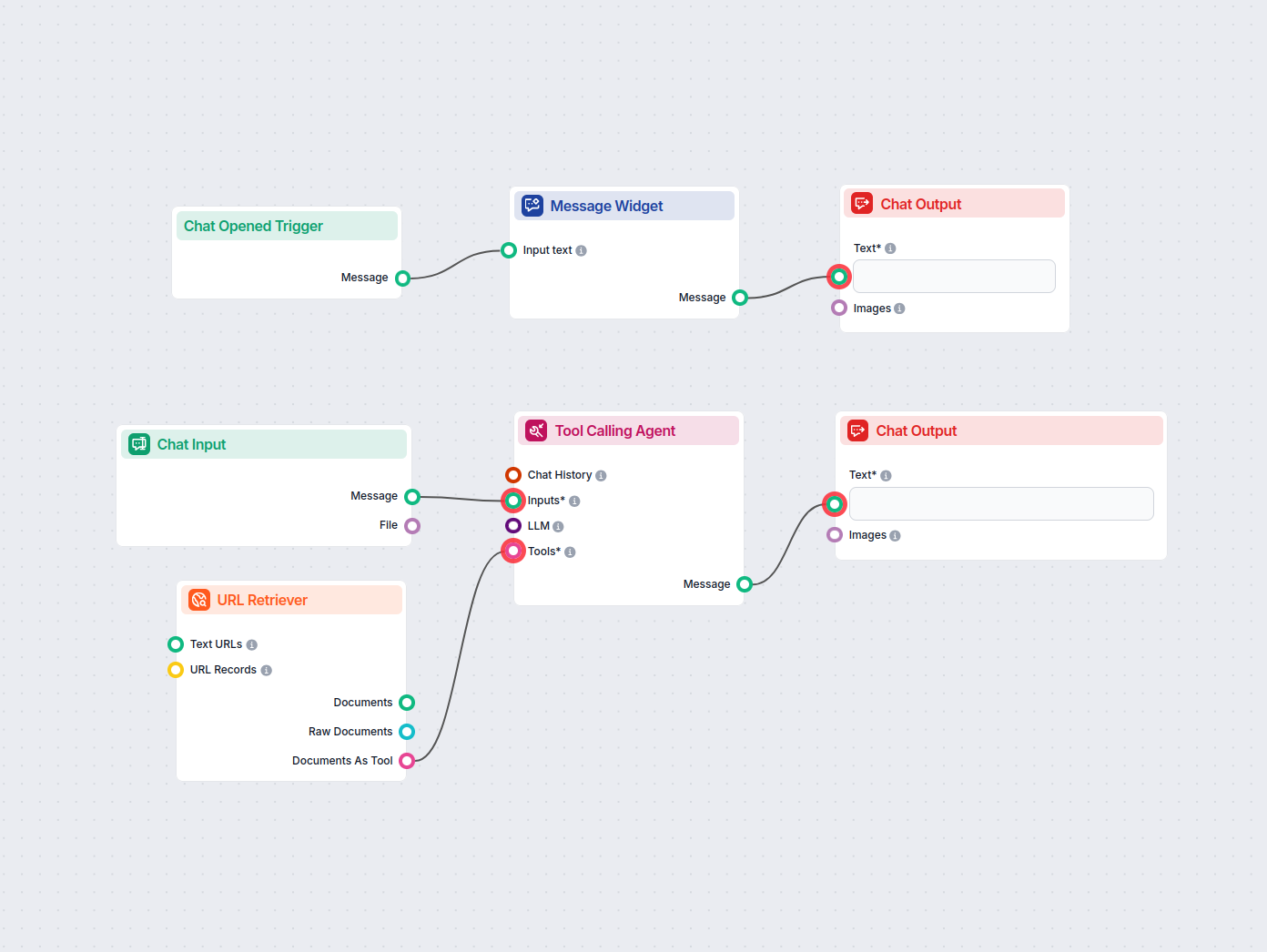
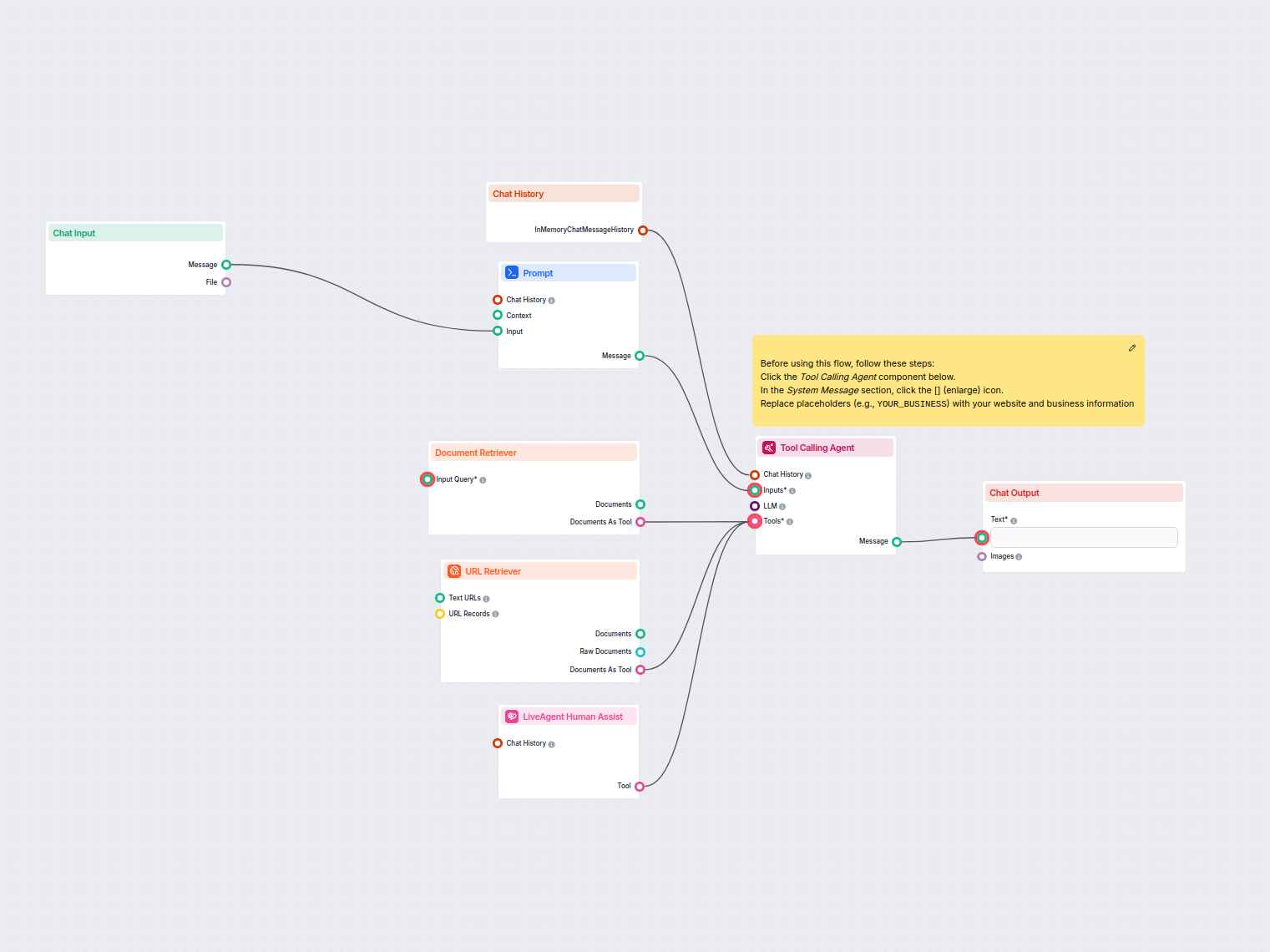
URL Retriever ti permette di recuperare e processare contenuti da link web, supportando OCR, estrazione di metadati e output flessibili per alimentare i flussi di lavoro AI.
Descrizione del componente
The URL Retriever is a versatile flow component designed to fetch and process web content from specified URLs, returning the information as structured documents. It serves as a bridge between external online content and your AI workflow, enabling you to integrate, analyze, or process web-based information efficiently.
This component retrieves the content of one or multiple URLs provided as input. It can extract the main text, metadata, and even process content from images using Optical Character Recognition (OCR). The retrieved data is then made available in various structured formats suitable for downstream AI tasks such as summarization, question answering, or knowledge extraction.
You can supply URLs to the component in two ways:
Text URLs:
MessageURL Records:
UrlRecord| Parameter | Type | Default | Description |
|---|---|---|---|
| Apply OCR | Boolean | false | If enabled, applies OCR to extract text from images in the document. |
| Cache TTL | Dropdown | 2 weeks | How long the content should be cached, with options from no cache up to 1 year. |
| From H1 if exists | Boolean | true | Begins extraction from the H1 tag if present, focusing on main content. |
| Load from pointer | Boolean | true | Loads content starting from the most relevant section based on your query. |
| Hide Resources | Boolean | false | Hides the retrieved resources from being output or displayed. |
| Max Tokens | Integer | 3000 | Sets the maximum number of tokens for the output text. |
| Skip Last Header | Boolean | true | Skips the last header during extraction for streamlined content. |
| Strategy | Dropdown | Include equal size from each documents | Determines how content is combined: concatenate fully or include equal parts from each document. |
| Export Content | Multi-select | All | Choose which HTML elements to export (H1-H6, Paragraph). |
| Include Metadata | Multi-select | Product | Specify which metadata fields to include (e.g., Product, Author, Website, etc.). |
| Verbose | Boolean | false | Enables detailed output for debugging or information purposes. |
| Tool Name | String | (empty) | Optionally assign a custom name to the tool for agent reference. |
| Tool Description | Multiline | (empty) | Provide a description to help agents understand the tool’s purpose. |
The URL Retriever provides its outputs in several formats, allowing flexible integration with various AI processes:
| Output Name | Type | Description |
|---|---|---|
| Documents | Message | The processed content from the URLs, ready for use in messaging-oriented workflows. |
| Raw Documents | Document | The raw, unprocessed document objects for advanced downstream processing. |
| Documents As Tool | Tool | The content packaged as a tool, enabling agent-based workflows to utilize the documents. |
| Feature | Description |
|---|---|
| Fetches URLs | Retrieves and processes web content from provided URLs. |
| OCR Support | Extracts text from images in documents if enabled. |
| Metadata Extraction | Optionally includes metadata such as author, product, or schema.org types. |
| Customizable Output | Select which HTML elements or metadata to export. |
| Caching | Configurable cache lifetimes for efficiency. |
| Multiple Output Types | Supports message, raw document, and tool outputs for workflow flexibility. |
The URL Retriever is a powerful and flexible bridge between web content and your AI workflows, offering granular control over content extraction and integration.
Per aiutarti a iniziare rapidamente, abbiamo preparato diversi modelli di flusso di esempio che mostrano come utilizzare efficacemente il componente URL Retriever. Questi modelli presentano diversi casi d'uso e best practice, rendendo più facile per te comprendere e implementare il componente nei tuoi progetti.
Questo workflow alimentato dall'IA genera risposte concise e di alta qualità alle domande delle FAQ per qualsiasi domanda, cercando sul web, estraendo contenuti...
Questo workflow alimentato dall'AI automatizza la generazione di lead outbound identificando le migliori aziende in una specifica nicchia e località, ricercando...
Genera automaticamente un'immagine in evidenza accattivante per qualsiasi articolo del blog analizzandone il contenuto. Basta fornire l'URL del blog e il workfl...
Questo workflow basato su AI trova le migliori parole chiave SEO per il tuo articolo di blog e riscrive automaticamente i titoli per mirare a quelle parole chia...
Ottimizza automaticamente i titoli e gli headline dei tuoi articoli per una parola chiave specifica o un cluster di keyword per migliorare le performance SEO. Q...
Questo workflow potenziato dall’AI semplifica il processo di personalizzazione del CV di un utente per adattarlo a una specifica offerta di lavoro. Analizzando ...
Questo workflow basato su AI automatizza la pianificazione delle riunioni tramite Google Calendar. Gli utenti interagiscono con un chatbot che trova orari dispo...
Questo workflow basato su IA migliora le descrizioni dei prodotti Shopify in base al nome del prodotto o all'URL fornito dall'utente. Sfrutta LLM, recupera cont...
Crea automaticamente una meta description coinvolgente e ottimizzata per la SEO per qualsiasi pagina web, PDF, video YouTube o link a documenti, analizzandone i...
Genera rapidamente riepiloghi concisi di qualsiasi pagina web semplicemente fornendo un URL. Questo workflow potenziato dall'AI recupera il contenuto dal link f...
Automatizza il supporto clienti in LiveAgent con un chatbot AI che risponde alle domande utilizzando la tua knowledge base interna, recupera documenti rilevanti...
Trasforma automaticamente il contenuto di qualsiasi URL fornito in un post conciso e coinvolgente adatto a X (Twitter), aiutando marketer e creator a rafforzare...
Mostrando 61 a 72 di 72 risultati
URL Retriever recupera e processa contenuti da link web specificati, rendendo testo e metadati da documenti online disponibili per il tuo flusso di lavoro o agente AI.
Sì, attivando l'opzione OCR, il componente può estrarre testo da documenti basati su immagini o PDF scansionati.
Restituisce documenti processati come messaggi di testo, oggetti documento grezzi, o come strumento per i flussi di lavoro degli agenti, a seconda della configurazione.
Puoi impostare per quanto tempo i contenuti recuperati vengono memorizzati in cache, riducendo i download ripetuti e velocizzando i tuoi flussi.
Sì, puoi specificare quali intestazioni, paragrafi o campi di metadati includere nell'output, permettendo un'estrazione mirata.
Assolutamente. URL Retriever è essenziale per qualsiasi automazione o chatbot che deve leggere, processare o riassumere contenuti web in tempo reale.
Potenzia i tuoi flussi di lavoro integrando contenuti web in tempo reale. Estrai, processa e utilizza dati dagli URL con facilità.
Integra i tuoi flussi di lavoro con Google Docs utilizzando il componente Google Docs Retriever: recupera facilmente il contenuto dei documenti da utilizzare in...
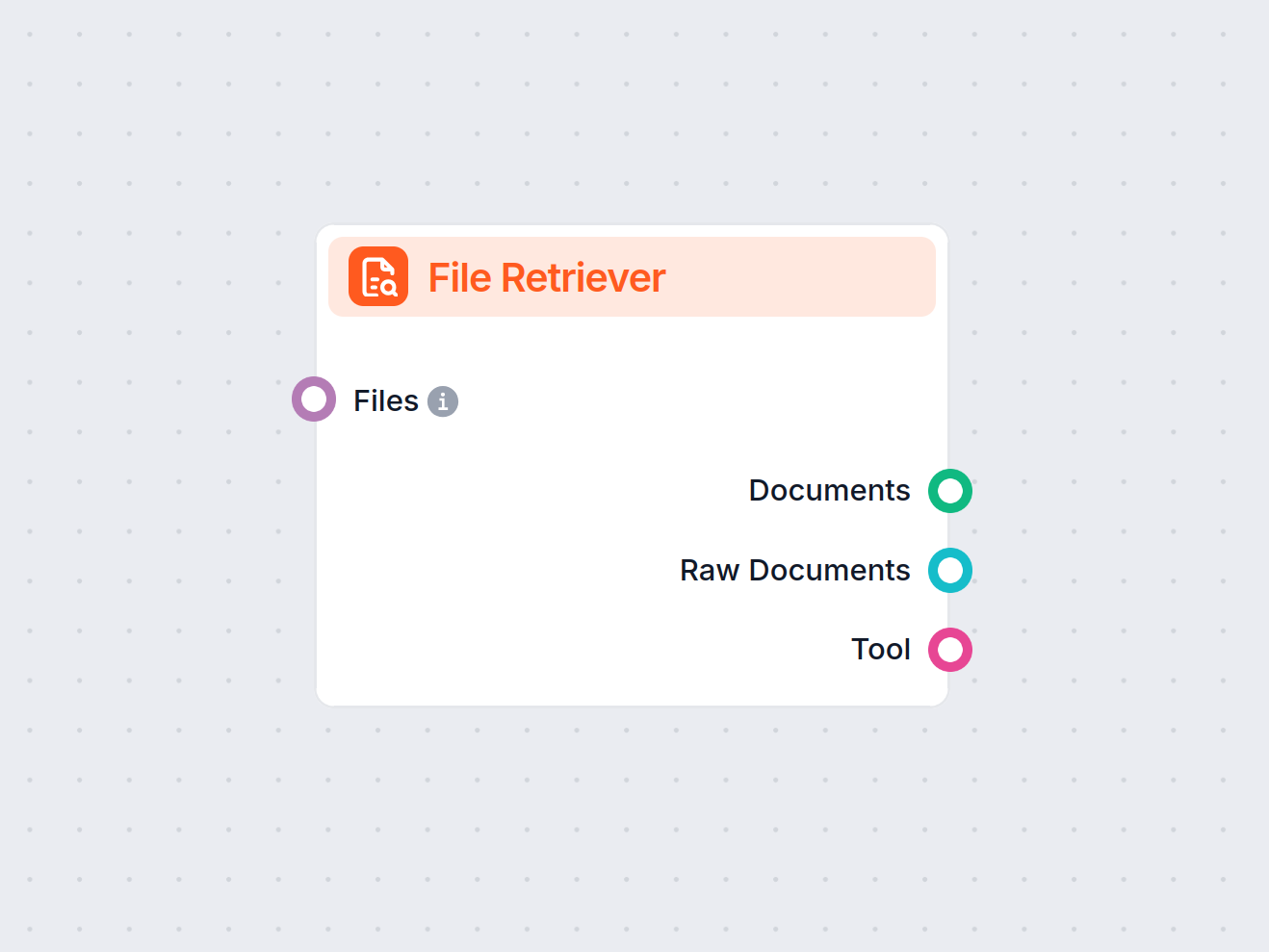
Il componente File Retriever in FlowHunt ti consente di inserire file nei tuoi flussi di lavoro e convertirli in documenti per ulteriori elaborazioni. Supporta ...
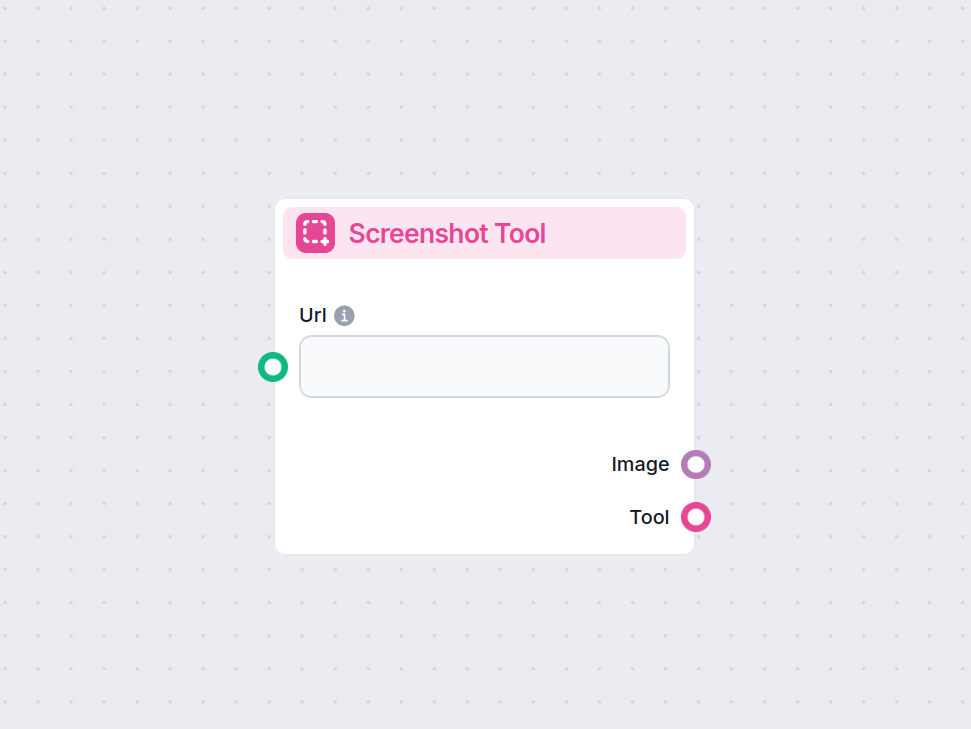
Cattura istantaneamente istantanee di siti web con il componente Strumento Screenshot. Automatizza facilmente la cattura di screenshot di qualsiasi URL all'inte...