
Come Testare un Chatbot AI
Scopri strategie complete per il testing dei chatbot AI, inclusi test funzionali, prestazionali, di sicurezza e usabilità. Approfondisci le best practice, gli s...
13 min di lettura
Scopri i metodi completi per misurare l’accuratezza di un chatbot AI per helpdesk nel 2025. Esplora precisione, recall, punteggi F1, metriche di soddisfazione utente e tecniche avanzate di valutazione con FlowHunt.
Misura l’accuratezza di un chatbot AI per helpdesk utilizzando molteplici metriche come calcoli di precisione e recall, matrici di confusione, punteggi di soddisfazione utente, tassi di risoluzione e metodi avanzati di valutazione basati su LLM. FlowHunt offre strumenti completi per la valutazione automatica dell’accuratezza e il monitoraggio delle prestazioni.
Misurare l’accuratezza di un chatbot AI per helpdesk è essenziale per garantire risposte affidabili e utili alle richieste dei clienti. A differenza delle semplici attività di classificazione, l’accuratezza di un chatbot comprende molteplici dimensioni che devono essere valutate insieme per avere un quadro completo delle prestazioni. Il processo prevede l’analisi della capacità del chatbot di comprendere le domande degli utenti, fornire informazioni corrette, risolvere efficacemente i problemi e mantenere alta la soddisfazione dell’utente durante le interazioni. Una strategia di misurazione accurata combina metriche quantitative con feedback qualitativi per individuare punti di forza e aree di miglioramento.
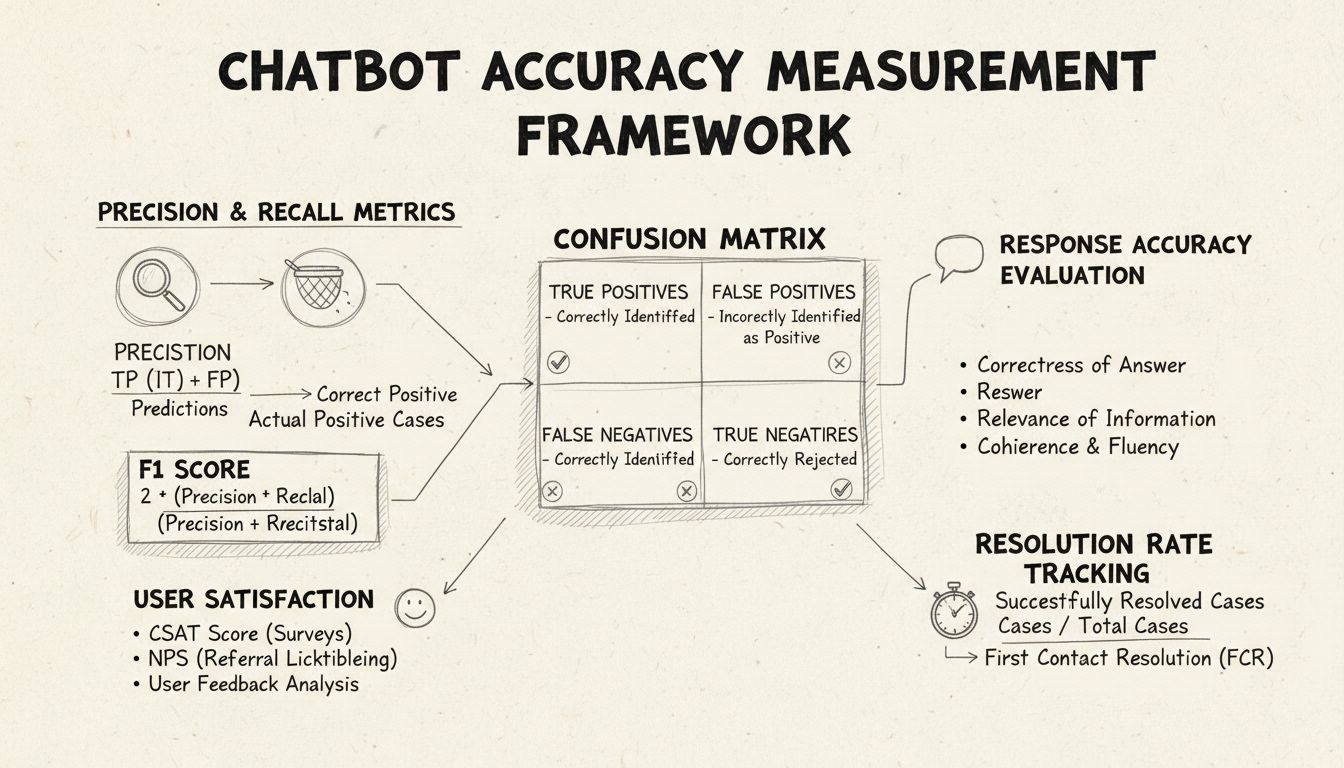
La precisione e il recall sono metriche fondamentali derivate dalla matrice di confusione che misurano diversi aspetti delle prestazioni di un chatbot. La precisione rappresenta la proporzione di risposte corrette rispetto a tutte le risposte fornite dal chatbot, calcolata con la formula: Precisione = Veri Positivi / (Veri Positivi + Falsi Positivi). Questa metrica risponde alla domanda: “Quando il chatbot fornisce una risposta, quanto spesso è corretta?” Un punteggio di precisione elevato indica che il chatbot raramente fornisce informazioni errate, aspetto critico per mantenere la fiducia degli utenti negli helpdesk.
Il recall, noto anche come sensibilità, misura la proporzione di risposte corrette rispetto a tutte quelle che il chatbot avrebbe dovuto fornire, utilizzando la formula: Recall = Veri Positivi / (Veri Positivi + Falsi Negativi). Questa metrica valuta se il chatbot identifica e risponde con successo a tutte le reali problematiche dei clienti. Negli helpdesk, un recall elevato garantisce che i clienti ricevano assistenza per i loro problemi, invece di sentirsi dire che il chatbot non può aiutare quando in realtà potrebbe. Esiste un naturale compromesso tra precisione e recall: ottimizzare una spesso riduce l’altra, richiedendo un attento bilanciamento in base alle priorità aziendali specifiche.
Il punteggio F1 fornisce una metrica unica che bilancia precisione e recall, calcolata come media armonica: F1 = 2 × (Precisione × Recall) / (Precisione + Recall). Questa metrica è particolarmente preziosa quando serve un indicatore sintetico delle prestazioni o in presenza di dataset sbilanciati dove una classe prevale nettamente sulle altre. Ad esempio, se il tuo chatbot gestisce 1.000 richieste di routine ma solo 50 escalation complesse, il punteggio F1 impedisce che la metrica sia distorta dalla classe maggioritaria. Il punteggio F1 va da 0 a 1, dove 1 rappresenta precisione e recall perfetti, risultando intuitivo per gli stakeholder che desiderano una visione immediata delle prestazioni complessive del chatbot.
La matrice di confusione è uno strumento fondamentale che suddivide le prestazioni del chatbot in quattro categorie: Veri Positivi (risposte corrette a domande valide), Veri Negativi (corretta rifiuto di rispondere a domande fuori ambito), Falsi Positivi (risposte errate fornite) e Falsi Negativi (occasioni perse per aiutare). Questa matrice rivela pattern specifici nei fallimenti del chatbot, consentendo miglioramenti mirati. Ad esempio, se la matrice mostra molti falsi negativi sulle richieste di fatturazione, puoi individuare che i dati di addestramento del chatbot sono carenti in quell’ambito e necessitano potenziamento.
| Metrica | Definizione | Calcolo | Impatto sul Business |
|---|---|---|---|
| Veri Positivi (TP) | Risposte corrette a domande valide | Conteggio diretto | Costruisce fiducia nel cliente |
| Veri Negativi (TN) | Corretto rifiuto di domande fuori ambito | Conteggio diretto | Previene la disinformazione |
| Falsi Positivi (FP) | Risposte errate fornite | Conteggio diretto | Danneggia la credibilità |
| Falsi Negativi (FN) | Occasioni perse per aiutare | Conteggio diretto | Riduce la soddisfazione |
| Precisione | Qualità delle previsioni positive | TP / (TP + FP) | Metrica di affidabilità |
| Recall | Copertura dei positivi reali | TP / (TP + FN) | Metrica di completezza |
| Accuratezza | Correttezza complessiva | (TP + TN) / Totale | Prestazione generale |
L’accuratezza della risposta misura quanto spesso il chatbot fornisce informazioni fattualmente corrette e direttamente pertinenti alla domanda dell’utente. Questo va oltre il semplice pattern matching e valuta se il contenuto è accurato, aggiornato e appropriato al contesto. I processi di revisione manuale prevedono che valutatori umani esaminino un campione casuale di conversazioni, confrontando le risposte del chatbot con una knowledge base predefinita di risposte corrette. Metodi di confronto automatico possono essere implementati usando tecniche di elaborazione del linguaggio naturale per confrontare le risposte con quelle attese memorizzate nel sistema, anche se richiedono un’attenta calibrazione per evitare falsi negativi quando il chatbot fornisce risposte corrette ma con parole diverse rispetto a quelle di riferimento.
La rilevanza della risposta valuta se la risposta del chatbot affronta effettivamente ciò che l’utente ha chiesto, anche se non è perfettamente corretta. Questa dimensione coglie situazioni in cui il chatbot fornisce informazioni utili che, pur non essendo la risposta esatta, indirizzano la conversazione verso la risoluzione. Metodi NLP come la similarità coseno possono misurare la somiglianza semantica tra la domanda dell’utente e la risposta del chatbot, fornendo uno score di rilevanza automatizzato. Meccanismi di feedback degli utenti, come i voti positivo/negativo dopo ogni interazione, offrono una valutazione diretta della rilevanza da parte di chi conta di più: i clienti. Questi segnali di feedback dovrebbero essere continuamente raccolti e analizzati per identificare i pattern di domande che il chatbot gestisce bene rispetto a quelle gestite male.
Il Customer Satisfaction Score (CSAT) misura la soddisfazione dell’utente nelle interazioni con il chatbot tramite sondaggi diretti, di solito con una scala da 1 a 5 o semplici valutazioni di gradimento. Dopo ogni interazione, agli utenti viene chiesto di valutare la loro soddisfazione, fornendo un feedback immediato sull’adeguatezza del chatbot rispetto alle loro esigenze. CSAT superiori all’80% indicano generalmente ottime prestazioni, mentre valori inferiori al 60% segnalano problemi importanti da approfondire. Il vantaggio del CSAT è la sua semplicità e immediatezza—gli utenti dichiarano esplicitamente se sono soddisfatti—ma può essere influenzato anche da fattori diversi dall’accuratezza, come la complessità del problema o le aspettative dell’utente.
Il Net Promoter Score misura la probabilità che gli utenti raccomandino il chatbot ad altri, calcolata chiedendo “Quanto è probabile che raccomandi questo chatbot a un collega?” su una scala da 0 a 10. I rispondenti che danno 9-10 sono promotori, 7-8 sono passivi e 0-6 sono detrattori. NPS = (Promotori - Detrattori) / Totale Rispondenti × 100. Questa metrica è fortemente correlata alla fidelizzazione a lungo termine e fornisce indicazioni sulla capacità del chatbot di generare esperienze positive che gli utenti vogliono condividere. Un NPS superiore a 50 è considerato eccellente, mentre valori negativi indicano problemi seri di performance.
L’analisi del sentimento esamina il tono emotivo dei messaggi degli utenti prima e dopo le interazioni con il chatbot per valutare la soddisfazione. Tecniche NLP avanzate classificano i messaggi come positivi, neutri o negativi, rivelando se gli utenti diventano più soddisfatti o frustrati durante la conversazione. Uno spostamento positivo del sentimento indica che il chatbot ha risolto con successo le preoccupazioni, mentre toni negativi suggeriscono che il chatbot ha frustrato gli utenti o non ha soddisfatto le loro esigenze. Questa metrica coglie dimensioni emotive che le metriche tradizionali non rilevano, offrendo un contesto prezioso per comprendere la qualità dell’esperienza utente.
La Risoluzione al Primo Contatto misura la percentuale di problematiche risolte dal chatbot senza necessità di escalation a un operatore umano. Questa metrica impatta direttamente su efficienza operativa e soddisfazione del cliente, che preferisce risolvere i problemi subito invece di essere trasferito. Tassi FCR superiori al 70% indicano prestazioni robuste, mentre valori inferiori al 50% suggeriscono che il chatbot non ha conoscenze o capacità sufficienti per gestire le richieste più comuni. Monitorare l’FCR per categoria di problema rivela quali tipologie il chatbot gestisce bene e quali invece richiedono l’intervento umano, guidando il potenziamento della knowledge base e della formazione.
Il tasso di escalation misura la frequenza con cui il chatbot passa le conversazioni agli operatori umani, mentre la frequenza dei fallback indica quante volte il chatbot ricorre a risposte generiche come “Non ho capito” o “Per favore, riformula la domanda”. Tassi di escalation elevati (oltre il 30%) segnalano che il chatbot manca di conoscenze o sicurezza in molti scenari, mentre tassi elevati di fallback suggeriscono una scarsa capacità di riconoscimento degli intenti o dati di addestramento insufficienti. Queste metriche individuano lacune specifiche che possono essere colmate tramite espansione della knowledge base, riaddestramento del modello o miglioramento delle componenti di comprensione del linguaggio naturale.
Il tempo di risposta misura la rapidità con cui il chatbot replica ai messaggi dell’utente, di solito in millisecondi o secondi. Gli utenti si aspettano risposte quasi istantanee; ritardi superiori a 3-5 secondi incidono negativamente sulla soddisfazione. Il tempo di gestione misura la durata totale dalla richiesta iniziale dell’utente fino alla risoluzione o escalazione, offrendo indicazioni sull’efficienza del chatbot. Tempi di gestione brevi indicano che il chatbot comprende e risolve rapidamente i problemi, mentre tempi lunghi suggeriscono necessità di chiarimenti multipli o difficoltà con domande complesse. Queste metriche andrebbero monitorate separatamente per categoria di problema, dato che problematiche tecniche complesse richiedono naturalmente tempi di gestione maggiori rispetto alle semplici FAQ.
LLM As a Judge rappresenta un approccio di valutazione sofisticato in cui un large language model valuta la qualità delle risposte generate da un altro sistema AI. Questa metodologia è particolarmente efficace per valutare contemporaneamente più dimensioni della qualità delle risposte del chatbot, come accuratezza, rilevanza, coerenza, fluidità, sicurezza, completezza e tono. Studi dimostrano che i giudici LLM possono raggiungere fino all’85% di allineamento con le valutazioni umane, rendendoli un’alternativa scalabile alla revisione manuale. L’approccio prevede la definizione di criteri di valutazione specifici, la creazione di prompt dettagliati per il giudice con esempi, la fornitura sia della domanda originale sia della risposta del chatbot e la ricezione di punteggi strutturati o feedback dettagliati.
Il processo LLM As a Judge impiega generalmente due modalità: valutazione di singole risposte, dove il giudice assegna un punteggio utilizzando valutazione senza riferimento (referenceless) o confronto con una risposta attesa (reference-based); e confronto a coppie (pairwise), dove il giudice valuta due risposte per individuare la migliore. Questa flessibilità consente di valutare sia le prestazioni assolute che le differenze relative tra versioni o configurazioni diverse del chatbot. La piattaforma FlowHunt supporta implementazioni di LLM As a Judge tramite la sua interfaccia drag-and-drop, integrazione con i principali LLM come ChatGPT e Claude, e toolkit CLI per reporting avanzato e valutazioni automatizzate.
Oltre ai calcoli di accuratezza di base, un’analisi dettagliata della matrice di confusione rivela pattern specifici nei fallimenti del chatbot. Analizzando quali tipologie di richieste producono falsi positivi rispetto ai falsi negativi si possono individuare debolezze sistematiche. Ad esempio, se la matrice mostra che il chatbot classifica frequentemente le domande di fatturazione come richieste di supporto tecnico, emerge uno sbilanciamento nei dati di addestramento o un problema di riconoscimento degli intenti specifico per il dominio di fatturazione. Creare matrici di confusione separate per categoria di problema consente miglioramenti mirati invece che semplici riaddestramenti generici.
L’A/B testing confronta diverse versioni del chatbot per determinare quale ottiene risultati migliori sulle metriche chiave. Può riguardare template di risposta, configurazioni della knowledge base o modelli linguistici sottostanti. Instradando casualmente parte del traffico su ciascuna versione e confrontando metriche come FCR, CSAT e accuratezza delle risposte, è possibile prendere decisioni basate sui dati rispetto alle migliorie da implementare. L’A/B testing dovrebbe durare abbastanza da cogliere la naturale variazione delle richieste degli utenti e garantire la significatività statistica dei risultati.
FlowHunt offre una piattaforma integrata per costruire, distribuire e valutare chatbot AI per helpdesk con avanzate capacità di misurazione dell’accuratezza. Il visual builder della piattaforma permette anche agli utenti non tecnici di creare flussi chatbot sofisticati, mentre i suoi componenti AI si integrano con i principali modelli linguistici come ChatGPT e Claude. Il toolkit di valutazione di FlowHunt consente di implementare la metodologia LLM As a Judge, permettendo di definire criteri personalizzati e valutare automaticamente le prestazioni del chatbot su tutto il dataset conversazionale.
Per implementare una misurazione completa con FlowHunt, inizia definendo i criteri di valutazione in linea con gli obiettivi di business—che si tratti di accuratezza, velocità, soddisfazione utente o tassi di risoluzione. Configura l’LLM giudicante della piattaforma con prompt dettagliati che specifichino come valutare le risposte, includendo esempi concreti di risposte di qualità e di risposte scadenti. Carica il tuo dataset conversazionale o collegati al traffico live, quindi lancia le valutazioni per generare report dettagliati che mostrano le prestazioni su tutte le metriche. La dashboard di FlowHunt fornisce visibilità in tempo reale sulle prestazioni del chatbot, consentendo di individuare rapidamente problemi e validare miglioramenti.
Stabilisci una misurazione di base prima di implementare miglioramenti, così da avere un punto di riferimento per valutare l’impatto dei cambiamenti. Raccogli misurazioni in modo continuo e non solo periodico, permettendo di individuare tempestivamente cali di performance dovuti a data drift o decadimento del modello. Implementa feedback loop in cui le valutazioni e correzioni degli utenti vengono automaticamente reintrodotte nel processo di training, migliorando costantemente l’accuratezza del chatbot. Segmenta le metriche per categoria di problema, tipologia di utente e periodo temporale, così da individuare aree specifiche che richiedono attenzione invece di affidarti solo alle statistiche aggregate.
Assicurati che il dataset di valutazione rappresenti reali richieste degli utenti e risposte attese, evitando casi di test artificiali che non riflettono l’utilizzo reale. Valida regolarmente le metriche automatiche confrontandole con valutazioni umane su un campione di conversazioni, così da mantenere calibrato il sistema di misurazione sulla reale qualità. Documenta chiaramente la metodologia e le definizioni delle metriche, garantendo valutazioni consistenti nel tempo e una comunicazione chiara dei risultati agli stakeholder. Infine, stabilisci target di performance per ogni metrica in linea con gli obiettivi di business, creando responsabilità per il miglioramento continuo e obiettivi chiari per le attività di ottimizzazione.
La piattaforma avanzata di automazione AI FlowHunt ti aiuta a creare, distribuire e valutare chatbot helpdesk ad alte prestazioni con strumenti integrati di misurazione dell’accuratezza e capacità di valutazione basate su LLM.
Scopri strategie complete per il testing dei chatbot AI, inclusi test funzionali, prestazionali, di sicurezza e usabilità. Approfondisci le best practice, gli s...
Scopri i metodi comprovati per verificare l’autenticità dei chatbot AI nel 2025. Approfondisci le tecniche di verifica tecnica, i controlli di sicurezza e le mi...

Una guida completa all'utilizzo dei Large Language Model come giudici per la valutazione di agenti e chatbot IA. Scopri la metodologia LLM come Giudice, le migl...
Consenso Cookie
Usiamo i cookie per migliorare la tua esperienza di navigazione e analizzare il nostro traffico. See our privacy policy.