Motore di Insight
Scopri cos'è un Motore di Insight: una piattaforma avanzata guidata dall’IA che migliora la ricerca e l’analisi dei dati comprendendo contesto e intento. Scopri...
12 min di lettura
AI
Insight Engine
+5

La Ricerca AI sfrutta il machine learning e gli embedding vettoriali per comprendere l’intento di ricerca e il contesto, fornendo risultati altamente pertinenti oltre le semplici corrispondenze di parole chiave.
La Ricerca AI utilizza il machine learning per comprendere il contesto e l’intento delle query di ricerca, trasformandole in vettori numerici per risultati più accurati. A differenza delle ricerche tradizionali basate su parole chiave, la Ricerca AI interpreta le relazioni semantiche, risultando efficace su diversi tipi di dati e lingue.
La Ricerca AI, spesso chiamata ricerca semantica o vettoriale, è una metodologia che sfrutta modelli di machine learning per comprendere l’intento e il significato contestuale delle query di ricerca. Diversamente dalla ricerca tradizionale basata su parole chiave, la ricerca AI trasforma dati e query in rappresentazioni numeriche note come vettori o embedding. Questo consente al motore di ricerca di comprendere le relazioni semantiche tra diversi dati, offrendo risultati più pertinenti e accurati anche quando le parole chiave esatte non sono presenti.
La Ricerca AI rappresenta una significativa evoluzione nelle tecnologie di ricerca. I motori di ricerca tradizionali si basano pesantemente sulla corrispondenza di parole chiave, dove la presenza di termini specifici sia nella query che nei documenti determina la pertinenza. La Ricerca AI, invece, utilizza modelli di machine learning per cogliere il contesto e il significato sottostante di query e dati.
Convertendo testo, immagini, audio e altri dati non strutturati in vettori ad alta dimensionalità, la Ricerca AI può misurare la similarità tra diversi contenuti. Questo approccio consente al motore di ricerca di fornire risultati contestualmente rilevanti, anche se non contengono esattamente le parole chiave utilizzate nella query.
Componenti chiave:
Al cuore della Ricerca AI c’è il concetto di embedding vettoriali. Gli embedding vettoriali sono rappresentazioni numeriche dei dati che ne catturano il significato semantico (testi, immagini o altri tipi di dati). Questi embedding collocano dati simili vicini nello spazio vettoriale multidimensionale.
Come funziona:
Esempio:
I motori di ricerca tradizionali basati su parole chiave operano abbinando i termini presenti nella query con i documenti che li contengono. Si basano su tecniche come indici invertiti e frequenza dei termini per ordinare i risultati.
Limitazioni della ricerca basata su parole chiave:
Vantaggi della Ricerca AI:
| Aspetto | Ricerca Basata su Parole Chiave | Ricerca AI (Semantica/Vettoriale) |
|---|---|---|
| Corrispondenza | Corrispondenze esatte | Similarità semantica |
| Consapevolezza del contesto | Limitata | Elevata |
| Gestione dei sinonimi | Richiede liste sinonimi manuali | Automatica tramite embedding |
| Errori ortografici | Può fallire senza ricerca fuzzy | Più tollerante grazie al contesto semantico |
| Comprensione dell’intento | Minima | Significativa |
La Ricerca Semantica è un’applicazione centrale della Ricerca AI che si focalizza sulla comprensione dell’intento dell’utente e del significato contestuale delle query.
Processo:
Tecniche chiave:
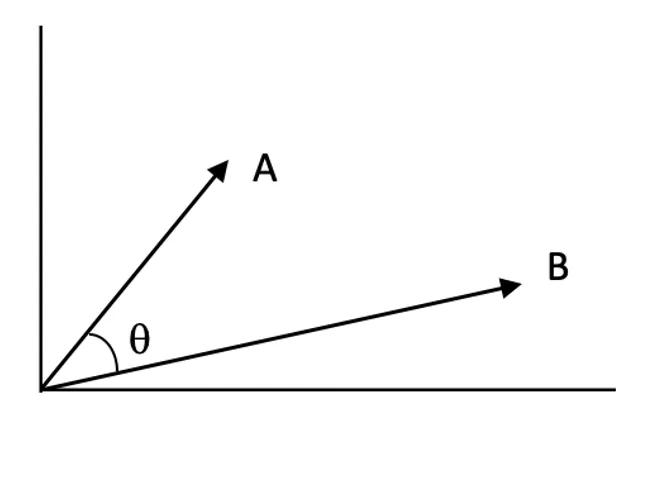
Punteggi di similarità:
I punteggi di similarità quantificano quanto due vettori siano correlati nello spazio vettoriale. Un punteggio più alto indica maggiore rilevanza tra la query e un documento.
Algoritmi Approximate Nearest Neighbor (ANN):
Trovare i vicini esatti in spazi ad alta dimensionalità è costoso dal punto di vista computazionale. Gli algoritmi ANN forniscono approssimazioni efficienti.
La Ricerca AI apre numerose applicazioni in vari settori grazie alla capacità di comprendere e interpretare i dati oltre la semplice corrispondenza di parole chiave.
Descrizione: La Ricerca Semantica migliora l’esperienza utente interpretando l’intento dietro le query e fornendo risultati contestualmente pertinenti.
Esempi:
Descrizione: Comprendendo preferenze e comportamento degli utenti, la Ricerca AI può suggerire contenuti o prodotti personalizzati.
Esempi:
Descrizione: La Ricerca AI consente ai sistemi di comprendere e rispondere alle query degli utenti con informazioni precise estratte dai documenti.
Esempi:
Descrizione: La Ricerca AI può indicizzare e ricercare tra dati non strutturati come immagini, audio e video convertendoli in embedding.
Esempi:
Integrare la Ricerca AI in automazione e chatbot ne potenzia notevolmente le capacità.
Benefici:
Fasi di implementazione:
Esempio d’uso:
Nonostante i numerosi vantaggi, la Ricerca AI comporta alcune sfide:
Strategie di mitigazione:
La ricerca semantica e vettoriale nell’AI si sono affermate come potenti alternative alle ricerche tradizionali basate su parole chiave e fuzzy, migliorando notevolmente la pertinenza e l’accuratezza dei risultati comprendendo il contesto e il significato delle query.
Quando si implementa una ricerca semantica, i dati testuali vengono convertiti in embedding vettoriali che catturano il significato semantico del testo. Questi embedding sono rappresentazioni numeriche ad alta dimensionalità. Per ricercare tra questi embedding in modo efficiente e trovare quelli più simili a una query, serve uno strumento ottimizzato per la ricerca di similarità in spazi ad alta dimensionalità.
FAISS fornisce gli algoritmi e le strutture dati necessari per svolgere questo compito in modo efficiente. Combinando embedding semantici e FAISS, è possibile creare un potente motore di ricerca semantica capace di gestire grandi dataset con bassa latenza.
L’implementazione della ricerca semantica con FAISS in Python richiede diversi passaggi:
Vediamo ogni passaggio nel dettaglio.
Prepara il tuo dataset (es. articoli, ticket di supporto, descrizioni di prodotti).
Esempio:
documents = [
"Come reimpostare la password sulla nostra piattaforma.",
"Risoluzione dei problemi di connettività di rete.",
"Guida all'installazione degli aggiornamenti software.",
"Best practice per backup e recupero dati.",
"Configurazione dell'autenticazione a due fattori per maggiore sicurezza."
]
Pulisci e formatta i dati testuali secondo necessità.
Converti i dati testuali in embedding vettoriali usando modelli Transformer pre-addestrati da librerie come Hugging Face (transformers o sentence-transformers).
Esempio:
from sentence_transformers import SentenceTransformer
import numpy as np
# Carica un modello pre-addestrato
model = SentenceTransformer('sentence-transformers/all-MiniLM-L6-v2')
# Genera gli embedding per tutti i documenti
embeddings = model.encode(documents, convert_to_tensor=False)
embeddings = np.array(embeddings).astype('float32')
float32 come richiesto da FAISS.Crea un indice FAISS per memorizzare gli embedding e abilitare ricerche efficienti per similarità.
Esempio:
import faiss
embedding_dim = embeddings.shape[1]
index = faiss.IndexFlatL2(embedding_dim)
index.add(embeddings)
IndexFlatL2 esegue una ricerca esaustiva usando la distanza L2 (euclidea).Converti la query dell’utente in un embedding e trova i vicini più prossimi.
Esempio:
query = "Come posso cambiare la password dell’account?"
query_embedding = model.encode([query], convert_to_tensor=False)
query_embedding = np.array(query_embedding).astype('float32')
k = 3
distances, indices = index.search(query_embedding, k)
Usa gli indici per visualizzare i documenti più pertinenti.
Esempio:
print("Risultati principali per la tua query:")
for idx in indices[0]:
print(documents[idx])
Output atteso:
Risultati principali per la tua query:
Come reimpostare la password sulla nostra piattaforma.
Configurazione dell'autenticazione a due fattori per maggiore sicurezza.
Best practice per backup e recupero dati.
FAISS offre diversi tipi di indici:
Utilizzo di un Inverted File Index (IndexIVFFlat):
nlist = 100
quantizer = faiss.IndexFlatL2(embedding_dim)
index = faiss.IndexIVFFlat(quantizer, embedding_dim, nlist, faiss.METRIC_L2)
index.train(embeddings)
index.add(embeddings)
Normalizzazione e ricerca per prodotto scalare:
Usare la similarità coseno può essere più efficace per dati testuali
La Ricerca AI è una metodologia di ricerca moderna che utilizza il machine learning e gli embedding vettoriali per comprendere l’intento e il significato contestuale delle query, offrendo risultati più accurati e pertinenti rispetto alla ricerca tradizionale basata su parole chiave.
A differenza della ricerca basata su parole chiave, che si basa su corrispondenze esatte, la Ricerca AI interpreta le relazioni semantiche e l’intento dietro le query, risultando efficace per il linguaggio naturale e gli input ambigui.
Gli embedding vettoriali sono rappresentazioni numeriche di testo, immagini o altri tipi di dati che ne catturano il significato semantico, consentendo al motore di ricerca di misurare la similarità e il contesto tra diversi dati.
La Ricerca AI alimenta la ricerca semantica nell’e-commerce, raccomandazioni personalizzate nello streaming, sistemi di question answering nel supporto clienti, navigazione di dati non strutturati e recupero documentale in ricerca ed enterprise.
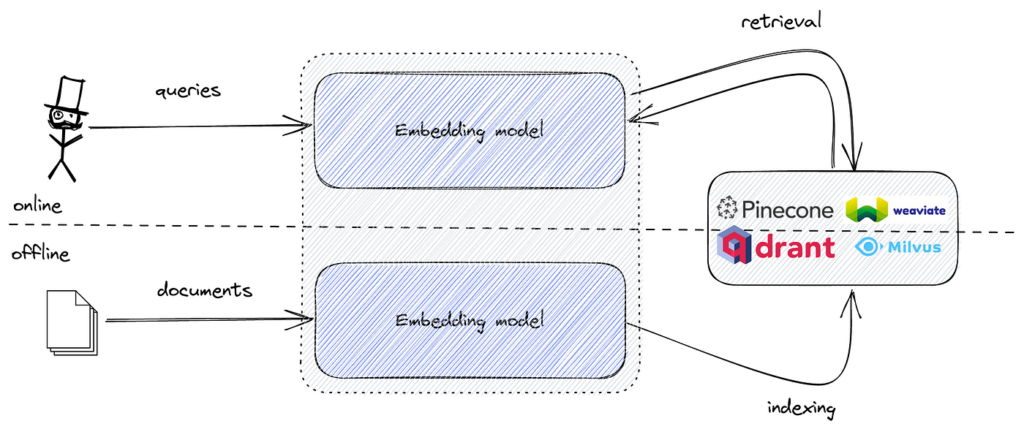
Strumenti popolari includono FAISS per la ricerca efficiente di similarità vettoriale e database vettoriali come Pinecone, Milvus, Qdrant, Weaviate, Elasticsearch e Pgvector per lo storage scalabile e il recupero degli embedding.
Integrando la Ricerca AI, chatbot e sistemi di automazione possono comprendere più a fondo le query degli utenti, recuperare risposte contestualmente pertinenti e fornire risposte dinamiche e personalizzate.
Le sfide includono elevati requisiti computazionali, complessità nell’interpretazione dei modelli, necessità di dati di alta qualità e la garanzia di privacy e sicurezza delle informazioni sensibili.
FAISS è una libreria open-source per la ricerca efficiente di similarità su embedding vettoriali ad alta dimensionalità, ampiamente usata per costruire motori di ricerca semantici in grado di gestire dataset di grandi dimensioni.
Scopri come la ricerca semantica potenziata dall’AI può trasformare il recupero delle informazioni, i chatbot e i flussi di lavoro di automazione.
Scopri cos'è un Motore di Insight: una piattaforma avanzata guidata dall’IA che migliora la ricerca e l’analisi dei dati comprendendo contesto e intento. Scopri...
Scopri cos'è Perplexity AI, come funziona e come si confronta con ChatGPT. Approfondisci la ricerca in tempo reale, le citazioni delle fonti e le funzionalità a...
Perplexity AI è un motore di ricerca avanzato basato sull'intelligenza artificiale e uno strumento conversazionale che sfrutta NLP e machine learning per fornir...
Consenso Cookie
Usiamo i cookie per migliorare la tua esperienza di navigazione e analizzare il nostro traffico. See our privacy policy.