
Databricks MCPサーバー
Databricks MCPサーバーは、AIアシスタントとDatabricks環境を接続し、Unity Catalogのメタデータやデータ資産の自律的な探索・理解・操作を可能にします。エージェントはデータを発見し、SQLクエリを構築し、手動操作なしで複雑な分析ワークフローを自動化できます。...
1 分で読める
AI
MCP Server
+5
FlowHunt内のDatabricks MCPサーバーを利用して、AIエージェントをDatabricksに接続し、自動SQL・ジョブ監視・ワークフロー管理を実現します。
FlowHuntは、お客様の内部システムとAIツールの間に追加のセキュリティレイヤーを提供し、MCPサーバーからアクセス可能なツールをきめ細かく制御できます。私たちのインフラストラクチャーでホストされているMCPサーバーは、FlowHuntのチャットボットや、ChatGPT、Claude、さまざまなAIエディターなどの人気のAIプラットフォームとシームレスに統合できます。
Databricks MCP(Model Context Protocol)サーバーは、AIアシスタントとDatabricksプラットフォームを接続するための特化ツールであり、自然言語インターフェースを通じてDatabricksリソースをシームレスに操作できます。このサーバーは大規模言語モデル(LLM)とDatabricks APIの間の橋渡しとして機能し、LLMがSQLクエリの実行、ジョブの一覧取得、ジョブステータスの取得、詳細情報の取得を可能にします。これらの機能をMCPプロトコル経由で公開することで、開発者やAIエージェントはデータワークフローの自動化、Databricksジョブの管理、データベース操作の効率化を実現し、データ駆動型開発環境での生産性を向上させます。
リポジトリ内にプロンプトテンプレートは記載されていません。
リポジトリ内に明示的なリソースはありません。
最新のヒント、トレンド、お得な情報を無料で入手。
pip install -r requirements.txtで依存パッケージをインストールします。.envファイルを作成します。{
"mcpServers": {
"databricks": {
"command": "python",
"args": ["main.py"]
}
}
}
APIキーのセキュリティ例:
{
"mcpServers": {
"databricks": {
"command": "python",
"args": ["main.py"],
"env": {
"DATABRICKS_HOST": "${DATABRICKS_HOST}",
"DATABRICKS_TOKEN": "${DATABRICKS_TOKEN}",
"DATABRICKS_HTTP_PATH": "${DATABRICKS_HTTP_PATH}"
}
}
}
}
.envファイルを用意します。{
"mcpServers": {
"databricks": {
"command": "python",
"args": ["main.py"]
}
}
}
.envを作成します。{
"mcpServers": {
"databricks": {
"command": "python",
"args": ["main.py"]
}
}
}
.envを設定します。{
"mcpServers": {
"databricks": {
"command": "python",
"args": ["main.py"]
}
}
}
注意: 上記の設定例のように、APIキーやシークレットは必ず環境変数で安全に管理してください。
FlowHuntでのMCP利用
MCPサーバーをFlowHuntワークフローに統合するには、まずMCPコンポーネントをフローに追加し、AIエージェントに接続します。

MCPコンポーネントをクリックし、構成パネルを開きます。システムMCP設定セクションにて、次のJSON形式でMCPサーバー情報を入力してください。
{
"databricks": {
"transport": "streamable_http",
"url": "https://yourmcpserver.example/pathtothemcp/url"
}
}
設定が完了すると、AIエージェントはこのMCPをツールとして利用でき、すべての機能にアクセス可能になります。なお、“databricks” をご自身のMCPサーバー名に、URLもご自身のMCPサーバーURLに変更してください。
| セクション | 利用可否 | 詳細・備考 |
|---|---|---|
| 概要 | ✅ | |
| プロンプト一覧 | ⛔ | リポジトリにプロンプトテンプレートなし |
| リソース一覧 | ⛔ | 明示的なリソース定義なし |
| ツール一覧 | ✅ | 4つのツール: run_sql_query, list_jobs, get_job_status, get_job_details |
| APIキーのセキュリティ | ✅ | .envや設定JSONで環境変数として管理 |
| サンプリングサポート(評価時は重要度低) | ⛔ | 記載なし |
| Rootsサポート | ⛔ | 記載なし |
コア機能(ツール、セットアップやセキュリティガイド)は利用可能ですが、リソースやプロンプトテンプレートが未整備のため、Databricks API統合には有効ながら一部MCPプリミティブが不足しています。MCPエコシステム全体での完成度・有用性は10点中6点と評価します。
| ライセンス有無 | ⛔ (見つからず) |
|---|---|
| ツールが1つ以上ある | ✅ |
| フォーク数 | 13 |
| スター数 | 33 |
Databricks MCPサーバーは、AIアシスタントとDatabricks間の橋渡しを行い、SQL実行やジョブ管理などのDatabricks機能をMCPプロトコル経由で自動化ワークフローに提供します。
SQLクエリの実行、すべてのジョブの一覧取得、ジョブステータスの取得、特定のDatabricksジョブの詳細情報取得をサポートしています。
常に環境変数を利用してください。たとえば`.env`ファイルに記載するか、MCPサーバー設定で環境変数として構成し、機密情報をハードコーディングしないようにします。
はい、MCPコンポーネントをフローに追加し、Databricks MCPサーバーの詳細で構成すれば、AIエージェントはすべての対応Databricks機能にアクセスできます。
利用可能なツール、セットアップガイド、セキュリティサポートを基にしていますが、リソースやプロンプトテンプレートが不足しているため、MCPエコシステムでの完成度は10点中6点です。
SQLクエリの自動化、ジョブの監視、Databricksリソースの管理を会話型AIインターフェースから直接実行。FlowHuntフローにDatabricks MCPサーバーを統合し、生産性を次のレベルへ。
Databricks MCPサーバーは、AIアシスタントとDatabricks環境を接続し、Unity Catalogのメタデータやデータ資産の自律的な探索・理解・操作を可能にします。エージェントはデータを発見し、SQLクエリを構築し、手動操作なしで複雑な分析ワークフローを自動化できます。...
Databricks Genie MCPサーバーは、Genie APIを通じてDatabricks環境と大規模言語モデルを連携させ、会話型データ探索、自動SQL生成、ワークスペースのメタデータ取得を標準化されたModel Context Protocol(MCP)ツールで実現します。...
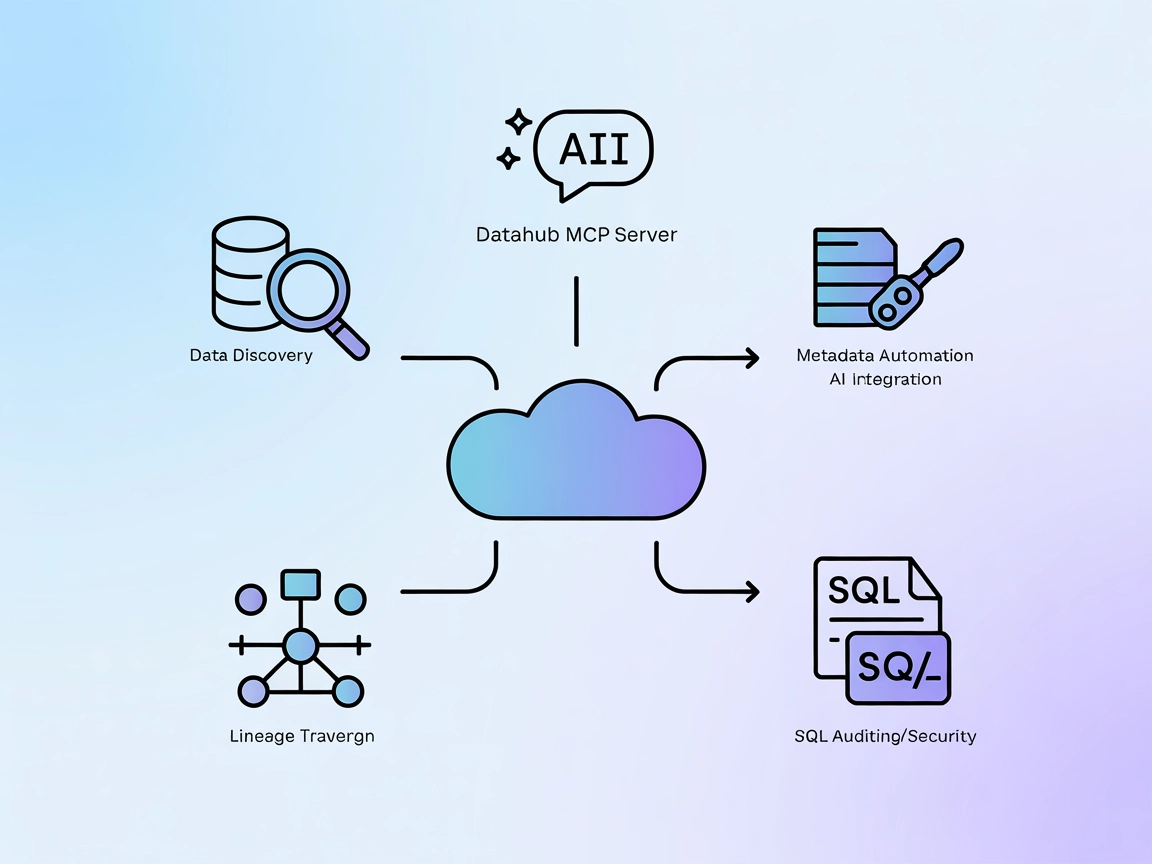
DataHub MCPサーバーは、FlowHuntのAIエージェントとDataHubメタデータプラットフォームを橋渡しし、高度なデータ探索、リネージ分析、自動メタデータ取得、AI駆動ワークフローとのシームレスな統合を実現します。...
クッキーの同意
閲覧体験を向上させ、トラフィックを分析するためにクッキーを使用します。 See our privacy policy.